PDFデータ
世の中の人はPDFが大好きなようで、嫌い嫌いと言っていても扱わざるを得ません。しかし、それに何時間もかけるのはちょっと・・・と思うのが人の常です。PDFの表データをしかないというケースもありますが、そのような際に便利なtabula-pyという超便利なライブラリがあったのでメモしておきます。
https://github.com/chezou/tabula-py
tabulaにかんして
tabulaはPDFの表を抽出するためのJavaのライブラリです。tabula-pyはそのラッパとなっております。そのため、利用するためにはJavaのインストールが必要です。
Javaをインストールした後、下のようにするとPythonのライブラリが利用できます。
$ pip install tabula-py
利用方法
利用方法は簡単で、read_pdf関数を用いるとPDFファイルにある表が読み込めます。事例には厚生労働省の新型コロナウイルス陽性者数(チャーター便帰国者を除く)とPCR検査実施人数を用います。
from tabula import read_pdf
df = read_pdf("https://www.mhlw.go.jp/content/10906000/000618483.pdf")
表の読み込み結果は下のように表示されます。
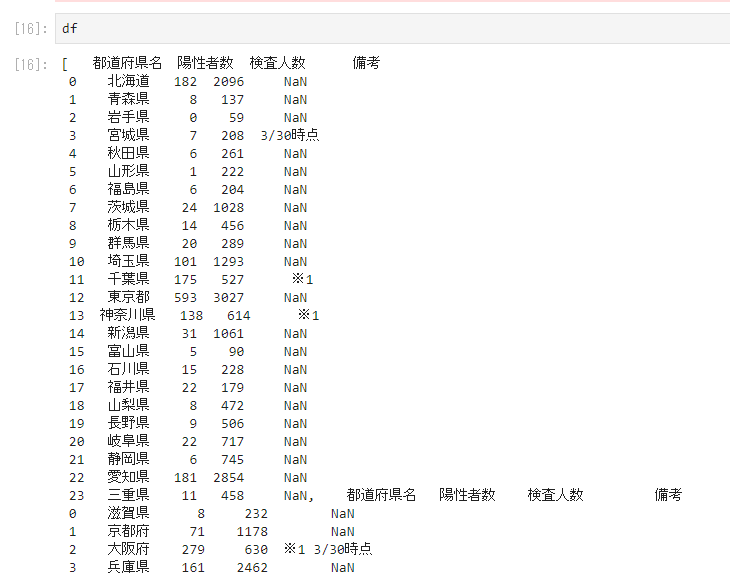
複数表があるため上のようになります。次に取得する表を指定します。
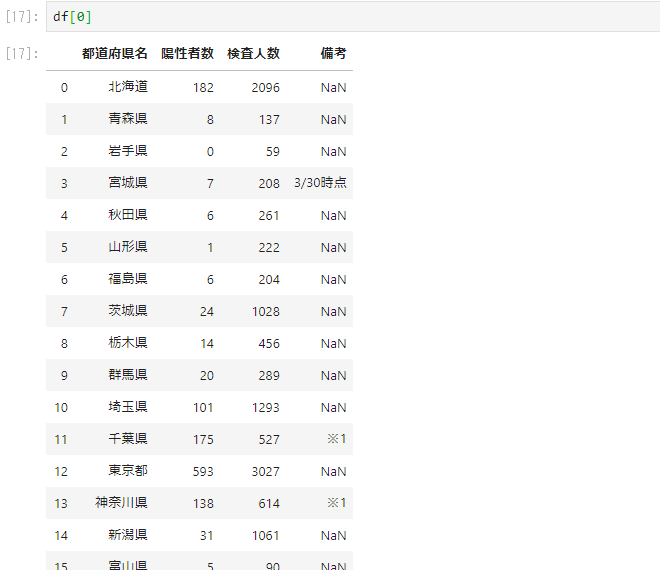
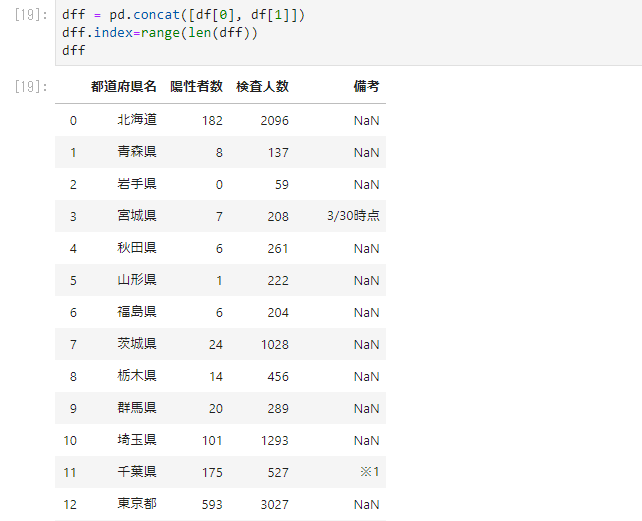
上を見るとわかりますが、表はpandasのデータテーブルの形になっています。超便利ですね。このPDFファイルでは2列にデータが分かれているため、表をがっちゃんこする必要があります。この際もデータテーブルなのでpandasのconcat関数を用いることができます。
データフレームであるため、可視化も容易です。
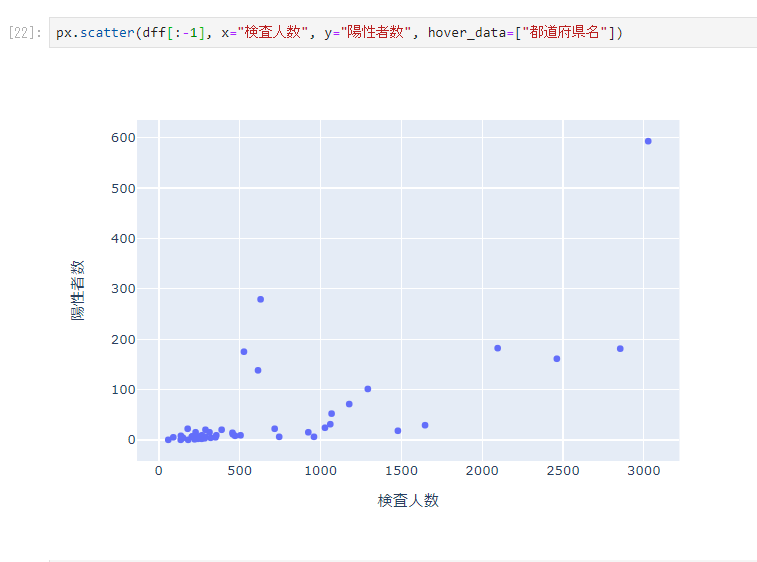
という感じで、tabula-pyを使うことで、PDFの表データも簡単に取れますね!