前回part4はこちら
今回やったこと (part4おさらい)
①データ取得をサーバサイドで実行し、最新の情報を非同期で反映できるようにする。
→ part4でやりました
②①で取得した販売情報データを地図にマッピングして、可視化する。フィルタ機能をつけて、分析しやすくする。それをどこかの環境にデプロイして、サービスとしてプレビュー版公開する。(自分でみてニヤニヤするだけ)
→ 今回はここを実装します
②フロントエンド作成
例によって、まずはやりたいことを雑なプロンプトでAIに投げるところからスタートします。
今回はpart4とは違い、実装とデプロイで少し試行錯誤がありました。
1. 2つの勘違い
(1)デプロイ環境の勘違い
(プロンプトにも記述している通り)当初私は手軽にAmplifyでHostingする想定でしたが、Amplifyは基本的に静的サイト向けで、Pythonで実行する動的アプリには不向きでした。代替案として、コンテナベースでPythonアプリを簡単にデプロイできる AWS App Runner が提案されたので、これを採用することにしました。
(2)フレームワークの勘違い
pythonで簡単に地図アプリを作るのであれば Streamlit でよいかと考えました。この考え自体は良かったのですが、いざ App Runner へデプロイする段階で、いくつかの壁に直面しました。
2. 判明した「ハマりポイント」
Streamlit × App Runner の組み合わせで進めた結果、2つの落とし穴がありました。
(1)App Runner 環境でのビルドエラー
App Runner の標準 Python ランタイム(Amazon Linux 2 ベース)環境で、最新のライブラリをそのままインストールしようとするとビルドエラーが頻発しました。
今回使ったライブラリ(pandas や pyarrow) の一部バージョンが、古いLinux環境向けのコンパイル済みバイナリ(Wheel)を提供しておらず、requirements.txt で、コンパイル不要な安定バージョンを明示的に指定するtry&errorを何度か行うことになりました。
(2)App Runner の WebSocket 非サポート問題
これが最大の山場でした。Streamlit はサーバーとの通信に WebSocket を使用しますが、App Runner が非サポートでデプロイは成功するが、ブラウザで開いても画面が遷移しない状態に陥りました。
開発者ツールでようやく WebSocket connection failed になっていることがわかったが、エラーシューティングの対話ではいっこうに解決せず、最終的にググってApp RunnerはWebSocket対応していないことに辿り着きました。
3. 最終構成
結果的にHTTP リクエスト/レスポンスで動作する Flask へ戻しました。
requirements.txt(依存ライブラリ)
ビルドエラーを回避するため、バージョンを固定しています。
flask
pandas==2.0.3
plotly==5.24.1
app.py
Flaskで受け取り、Plotlyで地図を描画してHTMLとして返すシンプルな構成です。
from flask import Flask, request, render_template_string
import pandas as pd
import plotly.express as px
import os
app = Flask(__name__)
CSV_FILE = 'suumo_bukken_mod_23_2025-12-06.csv'
# 簡易HTMLテンプレート
HTML_TEMPLATE = """ (中略)
"""
def load_data():
if os.path.exists(CSV_FILE):
return pd.read_csv(CSV_FILE)
return pd.DataFrame()
@app.route('/', methods=['GET'])
def index():
df = load_data()
if df.empty:
return "データ読み込みエラー"
# フィルタリング
min_p = int(request.args.get('min_price', 0))
max_p = int(request.args.get('max_price', 10000))
mask = (df['不動産単価(万/坪)'] >= min_p) & (df['不動産単価(万/坪)'] <= max_p)
df_filtered = df[mask]
# Plotlyによる地図描画
plot_html = ""
if not df_filtered.empty:
fig = px.scatter_mapbox(
df_filtered,
lat="緯度", lon="経度",
color="不動産単価(万/坪)", size="不動産単価(万/坪)",
hover_name="物件名",
color_continuous_scale=px.colors.sequential.Jet,
size_max=15, zoom=10, mapbox_style="carto-positron",
height=600
)
plot_html = fig.to_html(full_html=False, include_plotlyjs='cdn')
return render_template_string(HTML_TEMPLATE, plot_html=plot_html, min_price=min_p, max_price=max_p, count=len(df_filtered))
if __name__ == '__main__':
app.run(host='0.0.0.0', port=8080)
4. デプロイ
AWS App Runner コンソールからの設定手順です。 ソースコードリポジトリとしてGitHubを選択し、対象のブランチを指定します。 ランタイム設定は以下の通り設定しました。

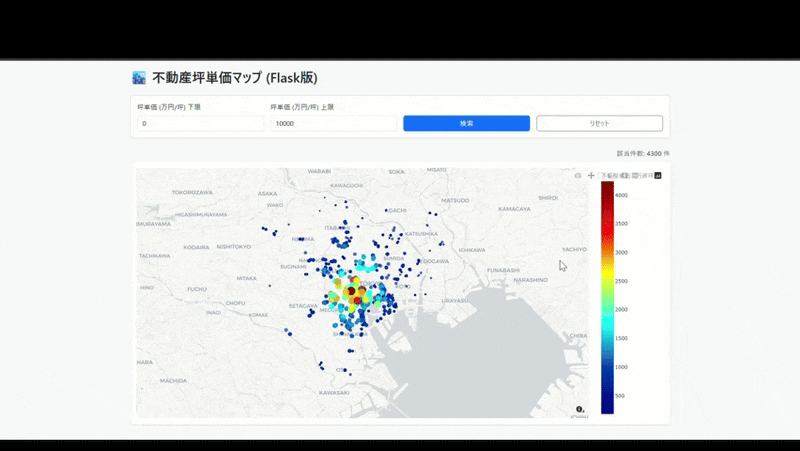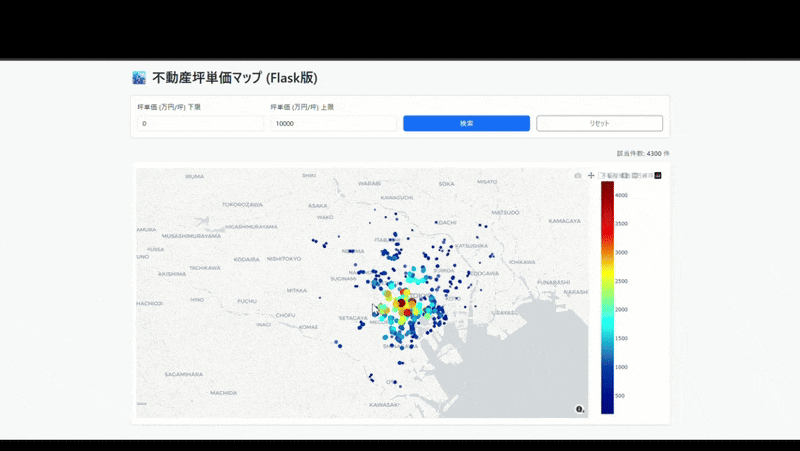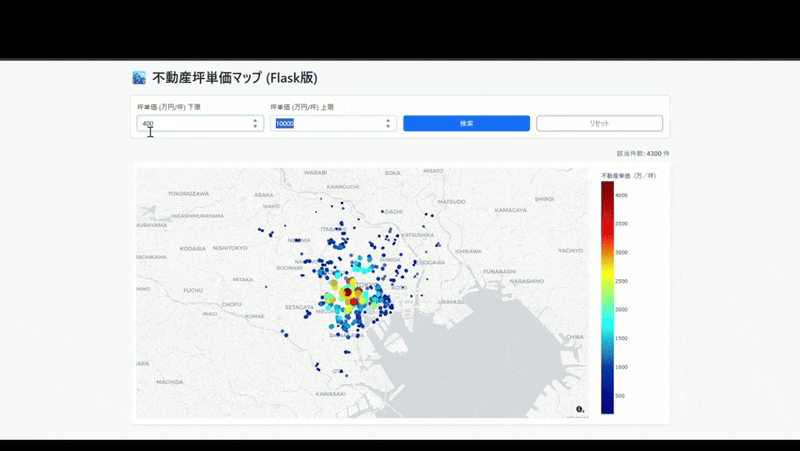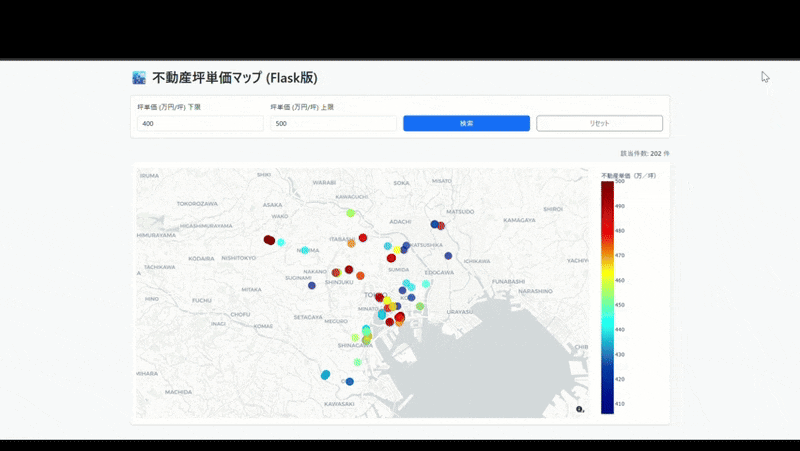
5. 最終出力
無事にデプロイが完了し、以下のようにブラウザ上で動作する地図アプリが完成しました。
6.GitHubリポジトリ
今回のコード一式はこちらで公開しています。
https://github.com/misonosuke/suumo-mapper
サンプルで1日分のデータを用意しているので、4.デプロイをすれば実際に操作してもらうことも可能です。
まとめ(おわりに)
一連の記事をご覧いただいた方はお気づきかと思いますが今回の開発、AIコードエディタは使用せずに、チャットAIでやってしまってます。
もちろんきちんとしたプロダクト開発しようとすると、コードの修正反映の手間や、複雑なバグシューティングにおける精度という点では、AIコードエディタを使わないとだと思います。
しかし、今回のようなとりあえず作ってみるMockや業務効率化のためのちょっとしたスクリプトを作るレベルであれば、チャットAIとの対話だけで十分完結できてしまえます。
「アプリケーションを開発し、インフラ環境を整備し、実際に動かしてみる」これだけの一連の作業が、対話プロンプトだけで形になる。一昔前とは隔世の感がありますし、2年前の状況からはさらに進化しているという所感です。
これからも、気が向いたらこうした実験的な開発ログを残していこうと思います。
今回はここまで。読んでいただきありがとうございました!