私の過去の記事
PythonとYoutube APIを使って任意のチャンネルのライブリストの時刻を取得した①
https://qiita.com/Octpascal/items/a4630bb47d9a3eda6297
から進化させたものです。APIの有効化などを詳しく記しました。
目的
推しの配信のYouTubeのチャンネル動画一覧を取得したい。取得情報は、
- タイトル
- URL
- State(配信予定/配信中/ストリーミングアーカイブ/動画投稿)
- ストリーミング開始時間/動画投稿時間
- ストリーミング終了時間/(動画投稿時間+動画の長さ)
とする。
これらの情報をCSVにて保存する。
Youtube APIの利用開始
Youtube Data API V3を使います。
https://developers.google.com/youtube/v3/getting-started
Google Cloud Platformにログイン
まず、任意のGoogleアカウントでGoogle Cloud Platformにログインします。
利用規約に同意して続行。
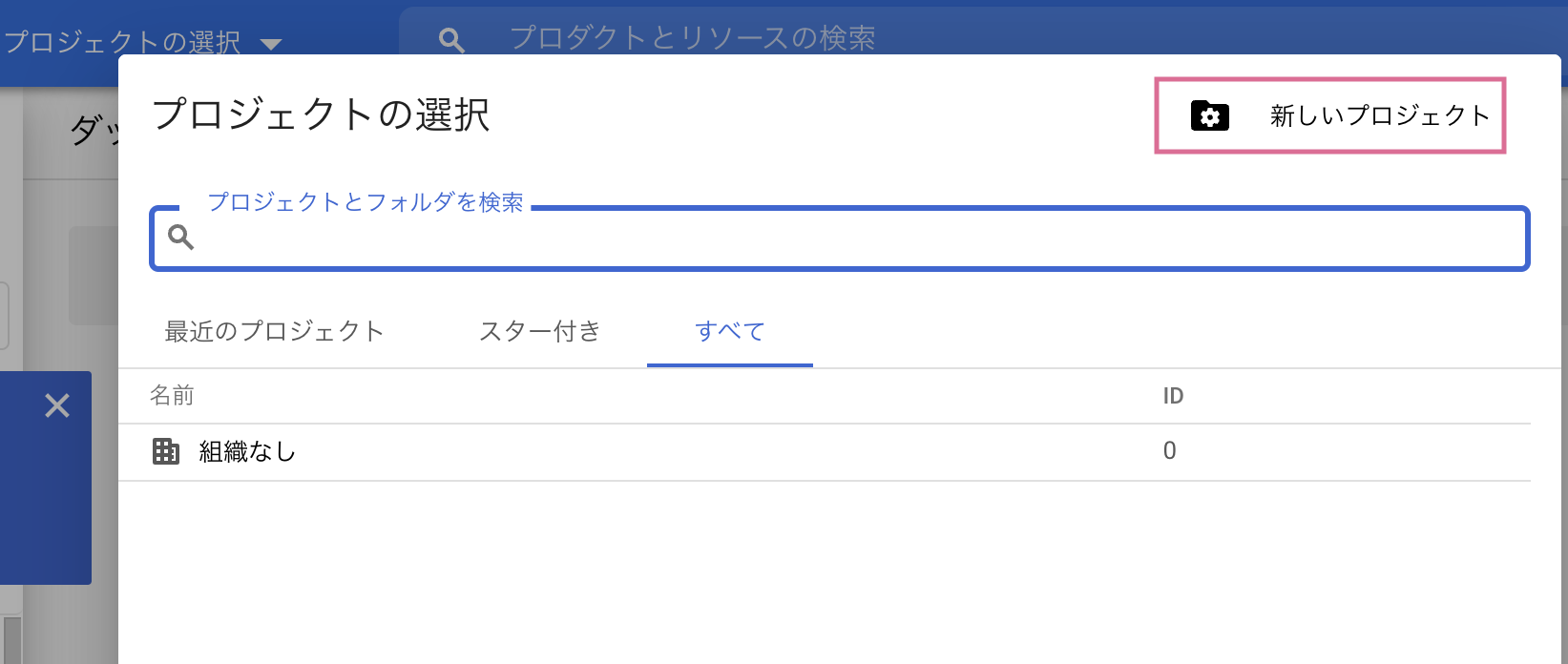
新しいプロジェクトの作成
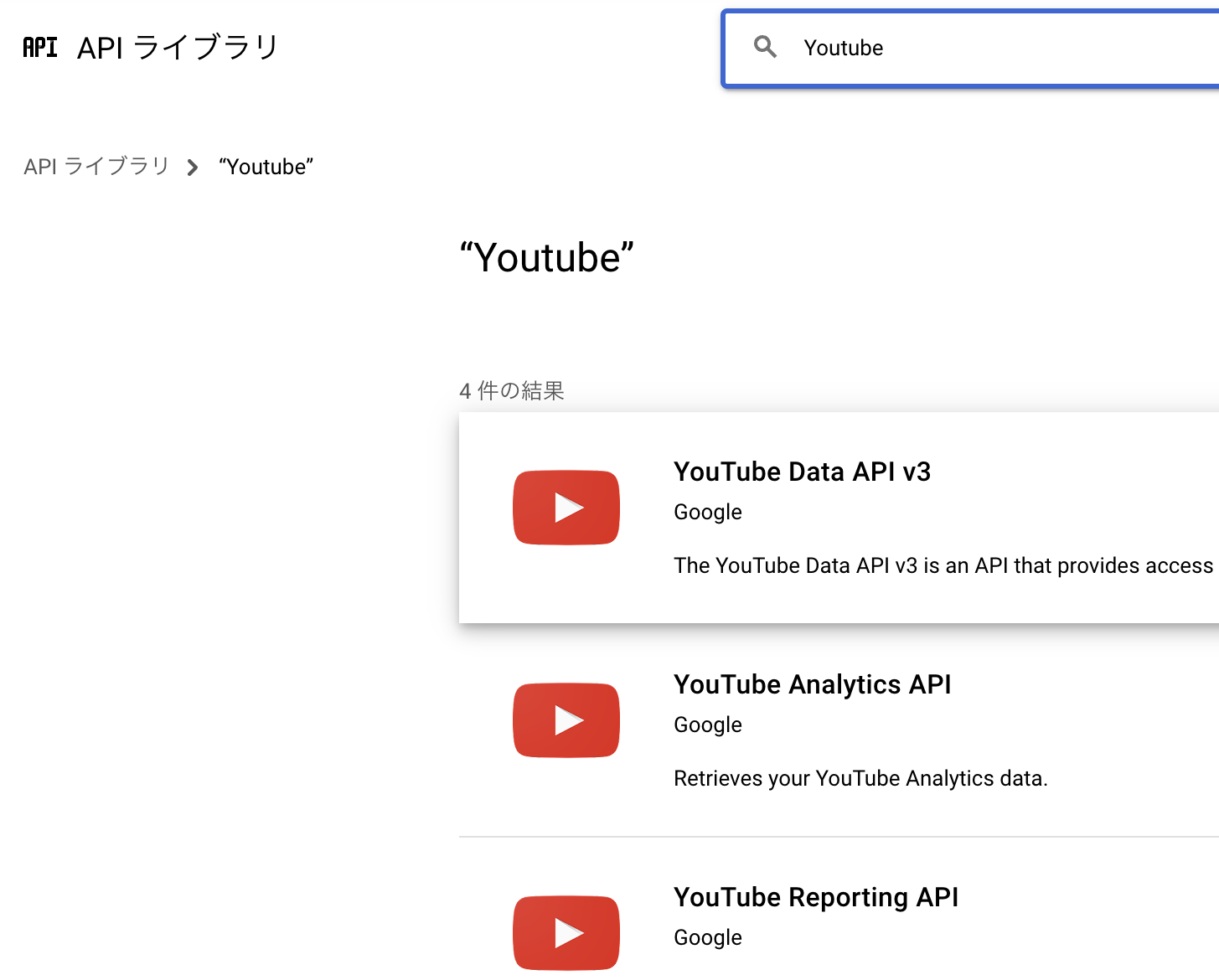
APIライブラリからYoutube Data API v3を有効化する
APIの概要から、認証を取得する
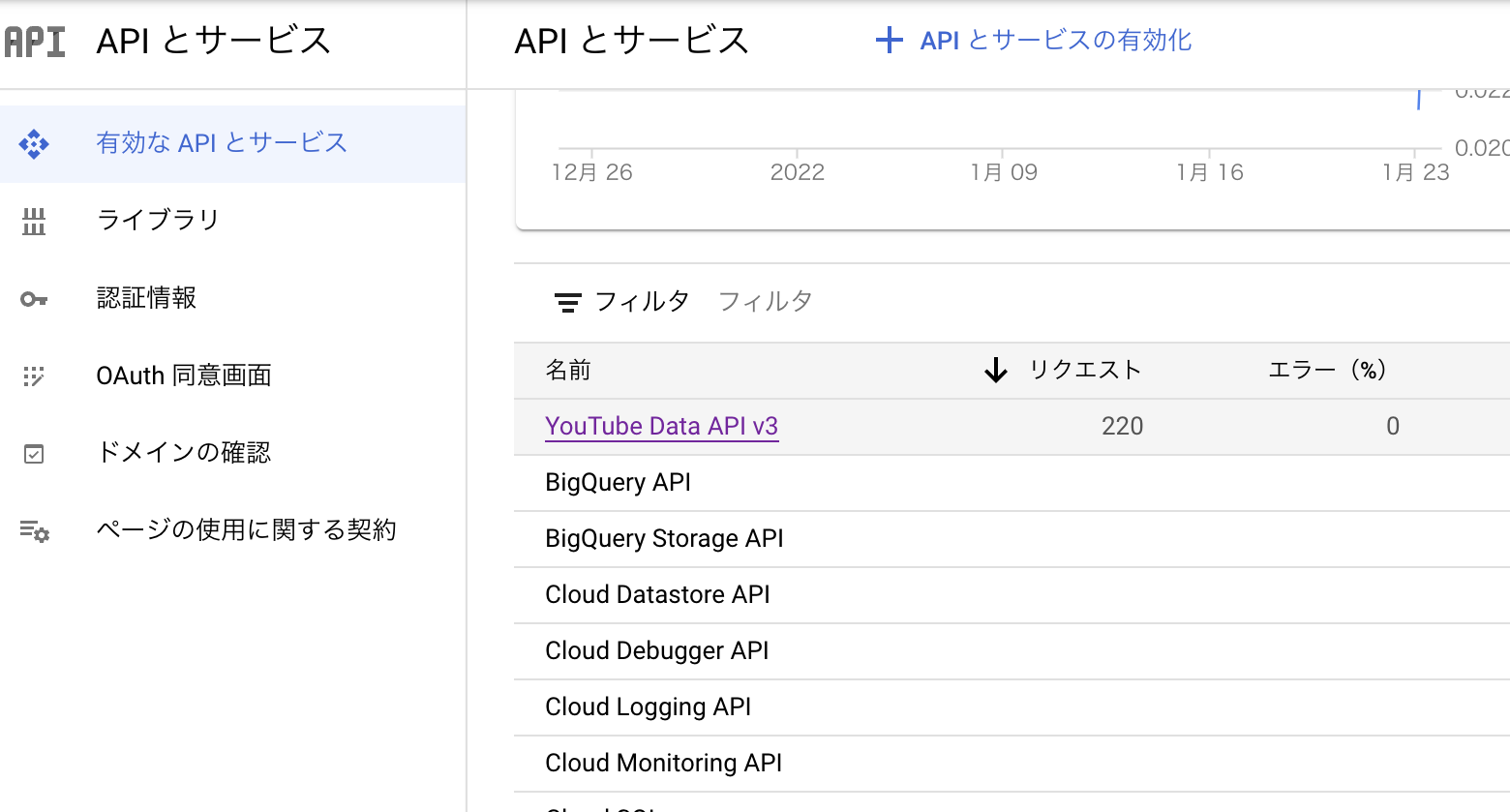
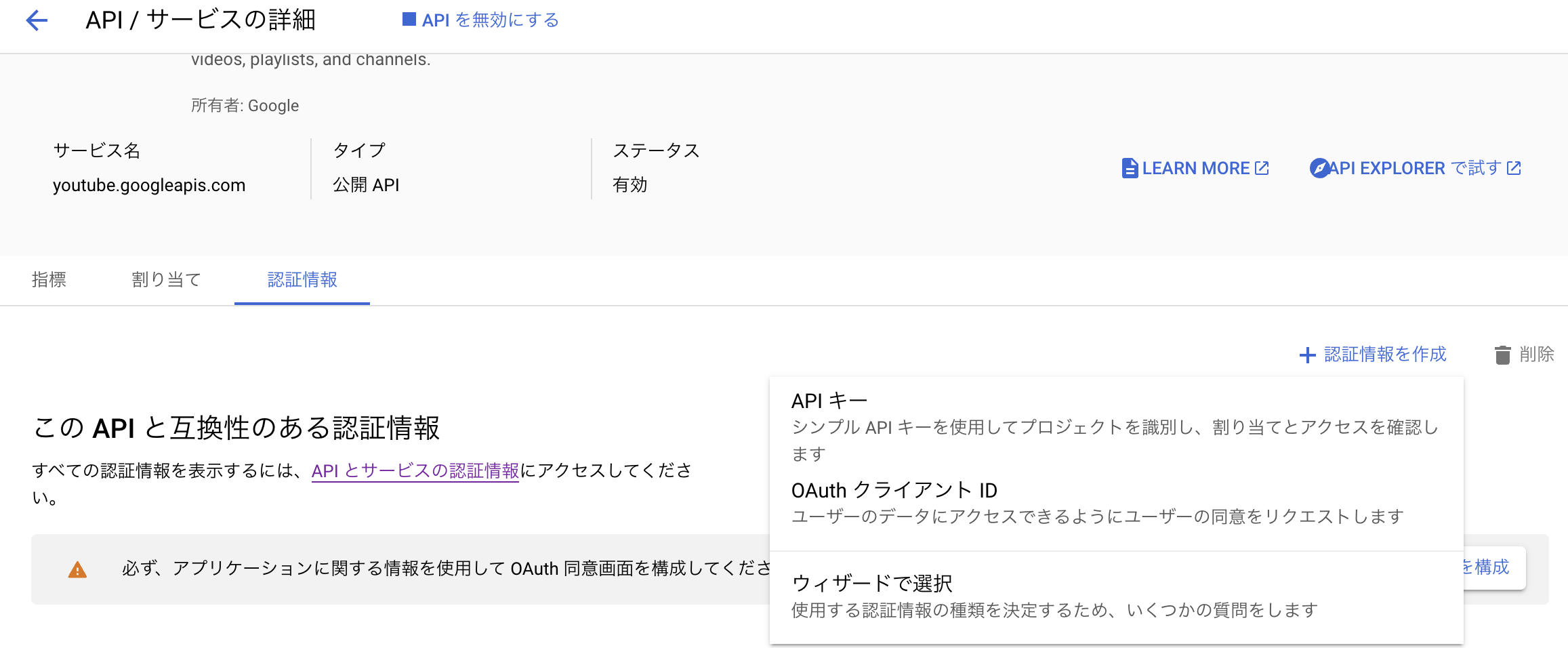
このとき、「OAuthクライアント認証」ではなく「APIキー」を選択します。
OAuth認証は、公開情報(動画検索、アップロード日、動画の長さ)を取得するにおいて、必要はありません。
APIの使い方
ライブラリの取得
GoogleのAPIを叩くためのライブラリです。
基本的に、これを用います。
pip install --upgrade google-api-python-client
各種APIの試し方
https://developers.google.com/youtube/v3/docs/videos/list
例えばこのページのようなAPIリファレンスから試すことができます。(ページ下部もしくはページ右の「試してみる」から)
この試行では、自分のAPIではなく、Googleの用意したAPIキーを利用して、動作を試すことができます。
(このとき、Google OAuth 2.0のチェックを外してください)
Pythonコード
必要なライブラリ
上記のGoogleが提供しているライブラリの他
- datetime
- isodate
- pandas
- urlparse
を用意します。他に
- pprint
のライブラリがあると、APIから返されたlistの確認が楽になります。
動画リストを取得するコード
import datetime
import isodate
import requests
import pprint
from apiclient.discovery import build
import pandas as pd
from urllib.parse import urlparse
YOUTUBE_API_KEY = '~~~YourAPIKey~~~'
youtube = build('youtube', 'v3', developerKey=YOUTUBE_API_KEY)
class youtube_list_csv:
def __init__(self):
# APIから帰ってくる時間が標準時であるため、時差用の変数を用意
self.JST = datetime.timedelta(hours=9)
# 過去のCSVからpandas.Dataframeを用意、ない場合新しいものを用意
try:
self.csvData = pd.read_csv('videos_csv.csv', comment='*')
except:
colname = ['id','channel','title','url','state','start','end']
self.csvData = pd.DataFrame(index=[], columns=colname)
# Youtube search APIにおいて、いちどのリクエストでいくつ取得するか
self.NumList = 5
def timetrans(self, strtime):
'''
日時のフォーマットがグリニッジ標準時かつisoformatの文字列で返されるため、
日本時間のdate型に直して返します
'''
stime = datetime.datetime.fromisoformat(strtime[:-1]) + self.JST
return stime.replace(microsecond=0)
def videolength(self, video_id):
Cdetail = youtube.videos().list(
part='contentDetails',
id=video_id
).execute()
duration = Cdetail['items'][0]['contentDetails']['duration']
return isodate.parse_duration(duration)
def YouTubelist(self, nPT, channel):
'''
Youtube Data API の searchを使い動画のリストを取得する。
チャンネルIDを入力することで、そのチャンネルの動画を同時に`self.NumList'個取得する。
ここから必要とするデータ{id, channel, title, url, state, start, end}を取得し返す。
ここで、
id: str
動画ID
channel: str
チャンネルID
title: str
動画タイトル
url: str
動画URL,
state: str
動画の状態[upcoming: ライブ配信予定, live: ライブ配信中, archive: ライブ配信アーカイブ, uploaded: 動画アップロード]
start: str
動画開始時刻(%Y/%m/%d %H:%M:%Sの表記)
end: str
動画終了時刻
の辞書型データをlistにして(len(list) = self.NumList)返す。
同時に、nextPageTokenを返す。
これは、同じ条件で続きを検索するにおいて、この続きを返すための値である。
Parameters
----------
nPT: str
NextPageToken
channel: str
channel ID
Returns
----------
RnPT: str
NextPageToken
csvdata: list
{id, channel, title, url, state, start, end}
'''
# search APIによって動画リストを取得
search_response = youtube.search().list(
channelId=channel,
part='snippet',
maxResults=self.NumList,
order='date',
type='video',
pageToken=nPT
).execute()
try:
RnPT = search_response['nextPageToken']
except:
RnPT = None
print('NextPageToken:', RnPT)
# 上記取得リストから動画IDを抽出
video_ids = []
items = search_response['items']
for item in items :
video_ids.append(item['id']['videoId'])
# videos APIによってライブストリーミングの詳細を取得
details = youtube.videos().list(
part='liveStreamingDetails',
id=video_ids
).execute()
detailitems = details['items']
csvdata = []
for item, detail in zip(items, detailitems):
title = item['snippet']['title']
video_id = item['id']['videoId']
# ここから動画の開始時刻と終了時刻を取得する。
# これがライブストリーミングアーカイブの場合、'liveBroadcastContent'にストリーミングの開始時間・終了時間が保存されている。
state = item['snippet']['liveBroadcastContent']
if state == 'upcoming':
# 配信予定の動画, start=配信開始予定時刻, end=配信開始時刻+1時間
starttime = self.timetrans(detail['liveStreamingDetails']['scheduledStartTime'])
endtime = starttime + datetime.timedelta(hours=1)
elif state == 'live':
# 配信中の動画, start=配信開始時刻, end=現在時刻+1時間
starttime = self.timetrans(detail['liveStreamingDetails']['actualStartTime'])
endtime = datetime.datetime.now().replace(microsecond=0) + datetime.timedelta(hours=1)
else:
try:
# 配信アーカイブ, start=配信開始時刻, end=配信終了時刻
starttime = self.timetrans(detail['liveStreamingDetails']['actualStartTime'])
endtime = self.timetrans(detail['liveStreamingDetails']['actualEndTime'])
state = 'archive'
except:
# アップロード動画, start=アップロード時刻, end=動画の長さを取得する関数 videolengthからアップロード時刻+長さ
starttime = self.timetrans(item['snippet']['publishTime'])
endtime = starttime + self.videolength(video_id)
state = 'uploaded'
print(starttime, '->', endtime, title, video_id, state)
csvdata.append(
{
'id': video_id,
'channel': channel,
'title': title,
'url': 'https://www.youtube.com/watch?v='+video_id,
'state': state,
'start': starttime.strftime('%Y/%m/%d %H:%M:%S'),
'end': endtime.strftime('%Y/%m/%d %H:%M:%S'),
}
)
return RnPT, csvdata
def csv_append(self, dataFrame):
'''
取得したdict型のlistをDataframeに追記する。
'''
new_pd = pd.DataFrame(dataFrame)
old_csv = self.csvData
# エラーのカウント数。追記しようとしたデータがすでに含まれている時 +1
Ecount = 0
for i in range(len(dataFrame)):
# new_pd から動画idを取得
nvid = new_pd.loc[i,'id']
# 動画idが既存のCSVにあるか確認
if not (old_csv['id']==nvid).any() :
# ないとき、新データを追記
old_csv = pd.concat([old_csv.T, new_pd.loc[i]],axis=1).T
else:
# あるとき、タイトル, start, end を追記
cindex = old_csv.query('id == @nvid').index
old_csv.loc[cindex, 'title'] = new_pd.loc[i, 'title']
old_csv.loc[cindex, 'url'] = new_pd.loc[i, 'url']
old_csv.loc[cindex, 'state'] = new_pd.loc[i, 'state']
old_csv.loc[cindex, 'start'] = new_pd.loc[i, 'start']
old_csv.loc[cindex, 'end'] = new_pd.loc[i, 'end']
Ecount += 1
old_csv = old_csv.reset_index(drop=True)
self.csvData = old_csv
return Ecount
def csv_all_append(self, startToken, maxCount, channelID):
'''
指定したチャンネルIDの動画リストを取得し、CSVに追記する。
startToken から始まり、maxCountになるもしくは、取得した動画が20以上既存のCSVにあったときに停止する。
このとき、動画の取得は同時に`self.NumList'件ずつ行われるので注意。
Parameters
----------
startToken: str
nextPageToken
maxCount: int
いちどに取得→追記するデータの数
channelID: str
動画リストを取得するチャンネルID
'''
Token = startToken
count = 0
Ecount = 0
while True:
try:
Token, getData = self.YouTubelist(Token, channelID)
except Exception as e:
# 動画の取得でエラーが発声した時
print('Error', e.args, '\nnextPageToken:', Token)
break
Ecount += self.csv_append(getData)
if Ecount > 20:
# すでにデータに含まれるデータを追記しようとした回数をカウントし、閾値を超えた時
print('All items was resistered')
break
if not Token :
# すべての動画を取得した時
print('End of Token')
break
count += self.NumList
if maxCount <= count:
# maxCountでいちどに取得する上限を設定しておく、それを超えた時
print('Reach max count')
break
print("Count:", count*self.NumList)
print('Ecount:', Ecount)
return Token
def csv_tmp_append(self, video_list):
'''
指定したチャンネルID以外の動画をCSVに追加したい時,
URLを指定してその動画を追加する
Parameters
----------
video_list: list
YoutubeのビデオIDのリスト
'''
videoList = youtube.videos().list(
part='liveStreamingDetails,snippet,contentDetails',
id=video_list
).execute()
videoitems = videoList['items']
csvdata = []
for item in videoitems:
title = item['snippet']['title']
video_id = item['id']
channel = item['snippet']['channelId']
state = item['snippet']['liveBroadcastContent']
if state == 'upcoming':
starttime = self.timetrans(item['liveStreamingDetails']['scheduledStartTime'])
endtime = starttime + datetime.timedelta(hours=1)
elif state == 'live':
starttime = self.timetrans(item['liveStreamingDetails']['actualStartTime'])
endtime = datetime.datetime.now().replace(microsecond=0) + datetime.timedelta(hours=1)
else:
try:
starttime = self.timetrans(item['liveStreamingDetails']['actualStartTime'])
endtime = self.timetrans(item['liveStreamingDetails']['actualEndTime'])
state = 'archive'
except:
starttime = self.timetrans(item['snippet']['publishedAt'])
endtime = starttime + isodate.parse_duration(item['contentDetails']['duration'])
state = 'uploaded'
print(starttime, '->', endtime, title, video_id, state)
if endtime.second != 0:
endtime += datetime.timedelta(minutes=1)
csvdata.append(
{
'id': video_id,
'channel': channel,
'title': title,
'url': 'https://www.youtube.com/watch?v='+video_id,
'state': state,
'start': starttime.strftime('%Y/%m/%d %H:%M:%S'),
'end': endtime.strftime('%Y/%m/%d %H:%M:%S'),
}
)
self.csv_append(csvdata)
try:
RnPT = videoList['nextPageToken']
except :
RnPT = None
return RnPT
def save_csv(self):
self.csvData.to_csv('videos_csv.csv',index=False)
#このCSVの保存時刻を追記
with open('videos_csv.csv', mode='a') as f:
f.write('* {}'.format(datetime.datetime.now().strftime('%Y/%m/%d %H:%M:%S')))
def sort_csv(self):
self.csvData = self.csvData.sort_values('start', ascending=False).reset_index(drop=True)
def url_to_id(url_list):
'''
関数csv_tmp_appendの利用に動画IDのリストが必要だが、
YoutubeのURL→動画IDに変換する関数
'''
vid_list = []
for i in url_list:
vid_list.append(urlparse(i).query[2:])
return vid_list
if __name__ == "__main__":
YLC = youtube_list_csv()
# test_NPT, test_LIST = YLC.YouTubelist(None, '~~~ChannelID~~~')
# print(test_NPT)
# pprint.pprint(test_LIST)
YLC.csv_all_append(None,120,'~~~ChannelID~~~')
YLC.save_csv()
print('Save Channel\n')
with open('outer_collabo.txt', 'r') as f:
Other_list = f.read().split()
if len(Other_list) != 0:
videoList = url_to_id(Other_list)
YLC.csv_tmp_append(videoList)
YLC.save_csv()
print('Save Other\n')
YLC.sort_csv()
YLC.save_csv()
コーディング中につまづいた点
searchで取得した情報では['snippet']['publishTime']に動画投稿時間が格納されていますが、
videosで取得した情報では['snippet']['publishedAt']に動画投稿時間が格納されています。
エラーメッセージ
The request cannot be completed because you have exceeded your <a href="/youtube/v3/getting-started#quota">quota</a>.
というエラーが返されることがあります。
APIは24時間に使えるquotaという制限があり、これを超えると上のエラーが返されます。
ただし、久々にAPIキーを使った時、その日なにもしていなくても上記のエラーが返されることがありました。
そのときは、新しいプロジェクトを作ってください。
CSVのコメントについて
上のコードyoutube_list_csv.pyにおいて、関数save_csvでCSVファイルにコメントアウトを追加しています。
この保存されたCSVをpandasで読み込む時、pd.read_csv('videos_csv.csv', comment='*')でコメントにする文字を指定していますが、
コメントアウト以外の「動画タイトル」などにこの記号が使われている場合、その行の以降の文字がコメントアウト扱いになってしまいます。
文字を変えるか、適切な文字がないときはコメントアウトを追記することをやめることを推奨します。
おまけ?
せっかくできたCSVを使って、推しのデビュー以来の総配信時間を計算してみました。
import pandas as pd
import datetime
csvData = pd.read_csv('videos_csv.csv', comment='*')
csvData = csvData.drop(csvData.index[(csvData['state'] == 'upcoming') | (csvData['state'] == 'live')])
def Duration_time(Drow):
start_dt = datetime.datetime.strptime(Drow.start, '%Y/%m/%d %H:%M:%S')
end_dt = datetime.datetime.strptime(Drow.end, '%Y/%m/%d %H:%M:%S')
return end_dt - start_dt
csvData['duration'] = csvData.apply(Duration_time, axis=1)
csvData = csvData.sort_values('start', ascending=False).reset_index(drop=True)
sum_dur = datetime.timedelta()
for dur in csvData['duration']:
sum_dur += dur
def get_h_m_s(td):
m, s = divmod(td.seconds, 60)
h, m = divmod(m, 60)
h += td.days*24
return h, m, s
sum_h, sum_m, sum_s = get_h_m_s(sum_dur)
print(sum_h, '時間', sum_m, '分', sum_s, '秒')
285 時間 28 分 32 秒でした。すごいね!
今後の改良点
関数csv_tmp_append内の、開始時間、終了時間を取得する場面において、関数YouTubelistと共通運用できるようにしたいです。