元記事:https://www.octoparse.jp/blog/web-scraping-using-python/
価格監視、ビジネス分析などのデータ関連プロジェクトを実施する場合、常にWebサイトからデータをエクセルに記録する必要があります。ただし、データを1行ずつコピペするのは時代遅れになり、Webスクレイピングにおけるニーズが高まっています。この記事では、Webデータを自動収集する方法、つまりPythonでWebスクレイピングを行う方法を説明します。
ステップ0:はじめに
Webスクレイピングとは、Webサイトからデータを取得するのに役立つ技術です。Pythonなどのプログラミング言語以外に、APIまたはOctoparseのようなスクレイピングツールもWebスクレイピングを行うことができます。
AirbnbやTwitterなどの大規模サイトの場合、サイトにある情報をできるだけ広く共有するために、API を通してデータにプログラムレベルでアクセスし、企業、開発者、利用者に提供します。APIはApplication Programming Interfacesの略で、2つのアプリケーションが互いに通信できるソフトウェアビルディングブロックです。ほとんどの人にとって、APIはデータを取得するための最も適したアプローチです。
ただし、全てのサイトはAPIサービスを提供するわけではありません。APIを提供しても、取得できるデータが必要なものではない場合もあります。したがって、Pythonを活用してWebクローラーを自作することは、強力で柔軟なソリューションになります。
では、なぜPythonが選ばれた言語なのでしょうか?
**柔軟性:**私たちが知っているように、Webサイトはよく更新されます。コンテンツだけでなく、Web構造も頻繁に変更されます。Pythonは動的に入力可能で生産性が高いため、使いやすい言語です。したがって、はコードを簡単に変更し、Webサイトの更新速度に追いつくことができます。
**強力:**Pythonには、有用で成熟したライブラリがたくさんあります。例えば、Requests、BeautifulSoupは、URLを取得し、Webページから情報を引き出すのに役立ちます。Seleniumは、Webクローラーが人間のブラウジング動作を真似できるようにすることで、一部のスクレイピング防止手法を回避するのに役立ちます。さらに、re、numpy、およびpandasを使用して、データのクリーンアップと処理を行うことができます。
それでは、PythonによるWebスクレイピングの旅を始めましょう!
ステップ1:Pythonライブラリをインポートする
このチュートリアルでは、Yelpからレビューをスクレイピングする方法を示します。BeautifulSoupとRequestsの2つのライブラリを使用します。これらの2つのライブラリは、PythonでWebクローラーを構築する際に一般的に使用されます。最初のステップは、この2つのライブラリをPythonにインポートして、これらのライブラリの関数を使用できるようにすることです。

ステップ2:WebページからHTMLを抽出する
https://www.yelp.com/biz/milk-and-cream-cereal-bar-new-york?osq=Ice+Cream からレビューを抽出しようとします。まず、URLという変数にURLを保存します。次に、このWebページのコンテンツにアクセスし、Requestsでurlopen()関数を使用して、HTMLを「ourUrl」に保存できます。

それで、BeautifulSoupを使ってWebページを解析します。

このWebサイトの生のHTMLである「Soup」ができたので、prettify()と呼ばれる関数を使用して生データを消去し、それを印刷して「Soup」のHTMLのネスト構造を確認できます。
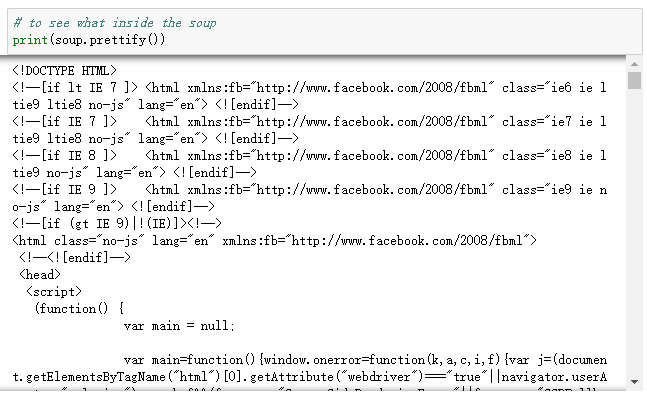
ステップ3:レビューを見つけて抽出する
次に、このWebページでレビューのHTMLを見つけて抽出し、保存します。Webページの各要素には、唯一のHTML「ID」があります。IDを確認するには、Webページでそれらを検査する必要があります。
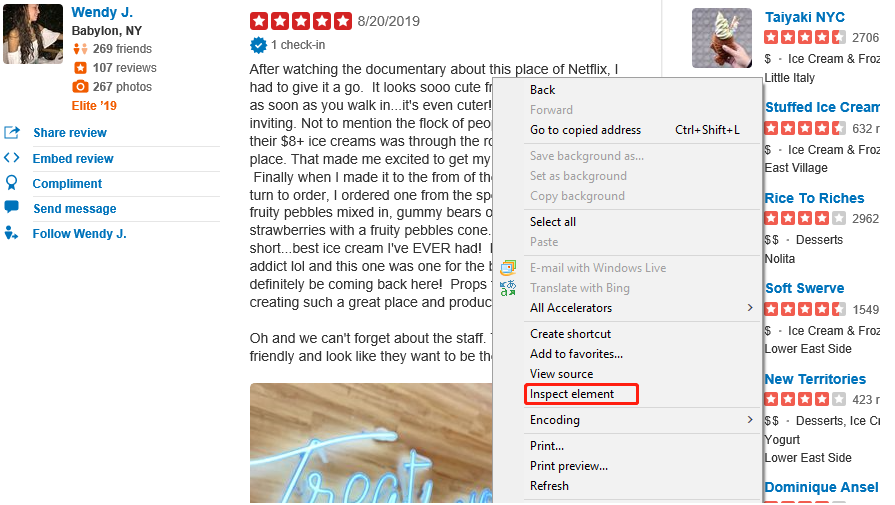
「Inspect element(要素の検証)](「Inspect(検証))をクリックすると、レビューのHTMLが表示されます。

この場合、レビューは「p」というタグの下にあります。そのため、まずfind_all()という関数を使って、これらのレビューの親ノードを見つけます。そして、ループ内の親ノードの下にタグ「p」を持つすべての要素を見つけます。すべての「p」要素を見つけたら、それらを「review」という空のリストに保存します。
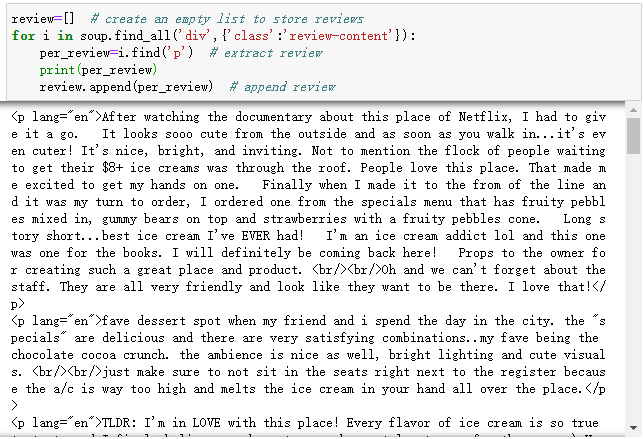
これで、そのページからすべてのレビューを取得できます。いくつのレビューを抽出したか見てみましょう。

ステップ4:レビューを処理する
各レビューの最初に<p lang = 'en'>、レビューの途中に<br/>、およびレビューの終わりに</ p>などの役に立たないテキストがまだあることに注意する必要があります。
<br/>は改行を表します。レビューに改行を入れる必要はありませんので、削除する必要があります。また、<p lang = 'en'>と</ p>はHTMLの始まりと終わりであり、これらも削除する必要があります。
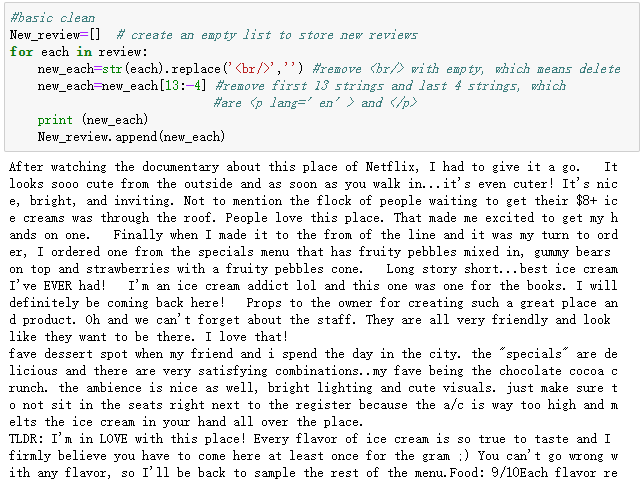
最後に、20行未満のコードですべてレビューをきれいに取得しました。
まとめ
以上はYelpから20件のレビューを収集するデモです。しかし、実際には、他の多くの状況に直面する必要があるかもしれません。例えば、他のページに移動してこのショップの残りのレビューを抽出するには、ページネーションなどの手順が必要になります。または、レビュアー名、レビュアーの場所、レビュー時間などのその他の情報も収集する必要があります。
上記の操作を実装してより多くのデータを取得するには、Seleniumや正規表現などの関数とライブラリをさらに学習しなければなりません。Webスクレイピングの課題を掘り下げるのにより多くの時間を費やすことは興味深いでしょう。
ただし、Webスクレイピングを行う簡単な方法を探している場合は、Octoparseのようなスクレイピングツールが一番いいソリューションになるかもしれません。Octoparseは、コードを各必要なく、Webサイトから情報を簡単に取得できる強力なWebスクレイピングツールです。Webスクレイピングをマスターして、Webデータの取得を自動化にしましょう!