目標
・AWS ElastiCache(Memcached)(※)を利用してRDSへのクエリをキャッシングするシステムを構築すること。
・キャッシングの方式はキャッシュ戦略(説明後述)に沿って構築を行う。
※ElastiCacheに関する基本・詳細情報は以下記事を参照
AWS キャッシュ活用 ElastiCache
はじめに
これまでの記事でEC2⇔RDS、及びEC2⇔ElastiCacheの接続を構築したので、
今度はElastiCacheを利用してRDSへのクエリをキャッシングさせるプログラムをほぼポートフォリオ的なノリで書いてみました。
言語はRubyを利用しました。
実務で経験したことのない実装ですので、何か変なとこあったらコメントください笑
キャッシュ戦略(※)とは
ElastiCacheをキャッシュ利用する際のAWSが推奨するベストプラクティスのこと。
以下2つの方式に分かれ、システムのユースケースに沿った戦略を選択する必要がある。
今回は遅延読み込みを利用した実装を行う。
・遅延読み込み
データ読み込み時にキャッシュを参照し、ヒットしなかった場合にのみデータソースへアクセスし必要なデータを取得してキャッシュに書き込む方式
⇒キャッシュのメモリ使用量を抑えることが可能だが、キャッシュデータが古い可能がある(キャッシュミス時にしかキャッシュを書き換えないため)
・書き込みスルー
データ書き込み時に毎回キャッシュにも書き込みを行う方式
⇒キャッシュのメモリ使用量は多くなってしまうが、常に最新のキャッシュデータを取得可能
※より詳しくはAWSドキュメント参照
キャッシュ戦略
https://docs.aws.amazon.com/ja_jp/AmazonElastiCache/latest/mem-ug/Strategies.html
前提
・EC2とRDS(MySQL)間の接続が確立されていること(※1)。
・EC2とElactiCache(Memcached)間の接続が確立されていること(※2)。
※1 以下記事で構築済み
【RDS】EC2とRDS(MySQL)間の接続を確立する
※2 以下記事で構築済み
【AWS ElastiCache】AWS ElastiCache(Memcached)を構築し、EC2から接続
システム環境
・EC2
OS(AMI) : Amazon Linux 2 AMI (HVM), SSD Volume Type
ソフトウェア: Rubyを利用した自作プログラム
・RDS
エンジン: MySQL
・ElastiChache
エンジン: Memcached
完成フロー
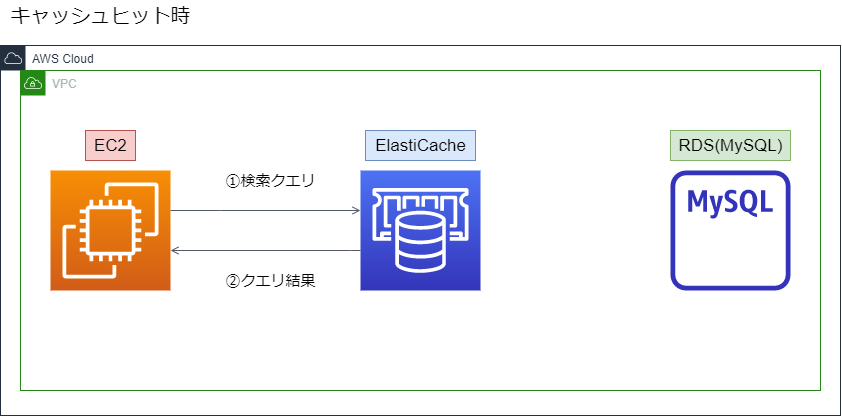
キャッシュヒット時は以下のフロー
①EC2から検索クエリを投げる
②ElaElastiCacheがクエリ結果を返し、通信終了
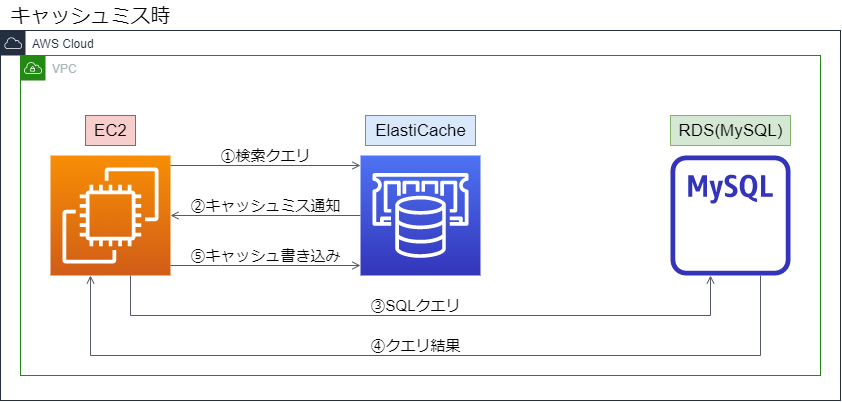
キャッシュミス時は以下のフロー
①EC2から検索クエリを投げる
②ElastiCacheからキャッシュミスが返る
③RDSへSQLクエリを発行
④RDSからSQLクエリ結果が返ってくる
⑤取得したクエリ結果をElastiCacheに書き込む
作業の流れ
| 項番 | タイトル |
|---|---|
| 1 | デプロイ |
| 2 | 動作検証 |
手順
1.デプロイ
①EC2にOSログイン
②Ruby実行環境をインストール
$ sudo yum install ruby
③Ruby用Memocacheクライアントのgem(Rubyのライブラリ)をインストール(※)
※参考にしたサイト
16.6.3.7 Ruby での MySQL と memcached の使用
$ gem install Ruby-MemCache
③Mysqlクライアントのgemをインストール(※)
Mysqlクライアントgemを利用する際に必要となるライブラリをインストール
(以下はEC2のAmazon Linux 2を利用した際の手順です。他のディストリビューションでは必要なライブラリが異なる可能性があります。)
※一部参考にした記事
AWS Cloud9のEC2上にmysql2のgemを導入する
$ sudo yum -y install ruby-devel
sudo yum groupinstall "Development Tools"
sudo yum install mysql-devel
Mysqlクライアントgemインストール
gem install mysql2
④自作Rubyスクリプト(※)をEC2に配備
<Elasticache_endpoint>、<rds_endpoint>、<db_login_user>、<db_login_password>、<db_name>は適宜書き換え
ファイル名: rds_cache.rb
# **********************************************************************************
# 機能概要: AWS ElastiCache(Memcached)を利用して、RDSへのクエリ結果をキャッシングする
# 機能詳細: ElastiCacheにクエリを発行し、キャッシュが存在する場合にはそのバリューを返す。
# キャッシュが存在しない場合、データソースであるRDS(MySQL)にアクセスし結果表示後、ElastiCacheにキャッシュ保存する。
# スクリプト用法: ruby <スクリプトパス> "<検索SQLクエリ>"
# **********************************************************************************
unless ARGV.size() == 1
puts "The number of arguments is incorrect."
exit
end
# パッケージ
require 'base64'
require 'memcache'
require 'mysql2'
# 変数
sql_query = ARGV[0] # 実行SQLクエリ
cache_host = "<Elasticache_endpoint>" # Elasticacheエンドポイント
cache_port = 11211 # Elasticacheポート番号
db_host = "<rds_endpoint>" # RDSエンドポイント
db_user = "<db_login_user>" # DBログインユーザ
db_password = "<db_login_password>" # DBパスワード
db_name = "<db_name>" # データベース名
# SQLクエリ(空白除去、小文字変換)をBase64でエンコード(キャッシュのキーとして利用する)
encoded_query = Base64.encode64(sql_query.gsub(" ", "").downcase)
# MemCache、Mysql接続用インスタンス作成
memc_connect = MemCache::new "#{cache_host}:#{cache_port}"
db_connect = Mysql2::Client.new(host: db_host, username: db_user, password: db_password, database: db_name)
# Elacacheからキャッシュを取得
cache_outcome = memc_connect[encoded_query]
if !cache_outcome[0].nil?
puts "Cache HIT!"
puts "[Query results from cache]"
puts cache_outcome[0]
else
puts "Cache MISS"
puts "[Query results from datasource]"
# キャッシュミスした場合、データベースへSQLクエリ発行
sql_outcome = db_connect.query(sql_query)
cache_val = ""
for row in sql_outcome do
puts "--------------------"
cache_val = cache_val + "--------------------\n"
for key, value in row do
puts "#{key} => #{value}"
cache_val = cache_val + "#{key} => #{value}\n"
end
end
# Elasticacheにバリューをセット
memc_connect[encoded_query] = cache_val
end
※実装方針は以下
・SQLクエリを引数としてスクリプト実行
・引数として指定したSQLクエリを空白除去・小文字変換後、Base64によってエンコードし、Elasticacheのキーとしてキャッシュ検索・保存に利用する。
・キャッシュヒットした場合は、結果を出力しスクリプト終了
・キャッシュミスした場合は、RDS(データソース)にアクセスしSQLクエリを実行し結果を出力。最後にその結果をElasticacheに保存。
2.動作検証
検証用DBデータ
+----+-----------+
| id | Name |
+----+-----------+
| 1 | Ryosuke |
| 2 | Tomoharu |
| 3 | ryosuke |
| 4 | shunsuke |
| 5 | sato |
| 6 | sato |
| 7 | ryOsuke |
| 8 | Kawashima |
| 9 | tomoharu |
| 10 | RYOSUKE |
+----+-----------+
実行SQLクエリ及びその結果期待値
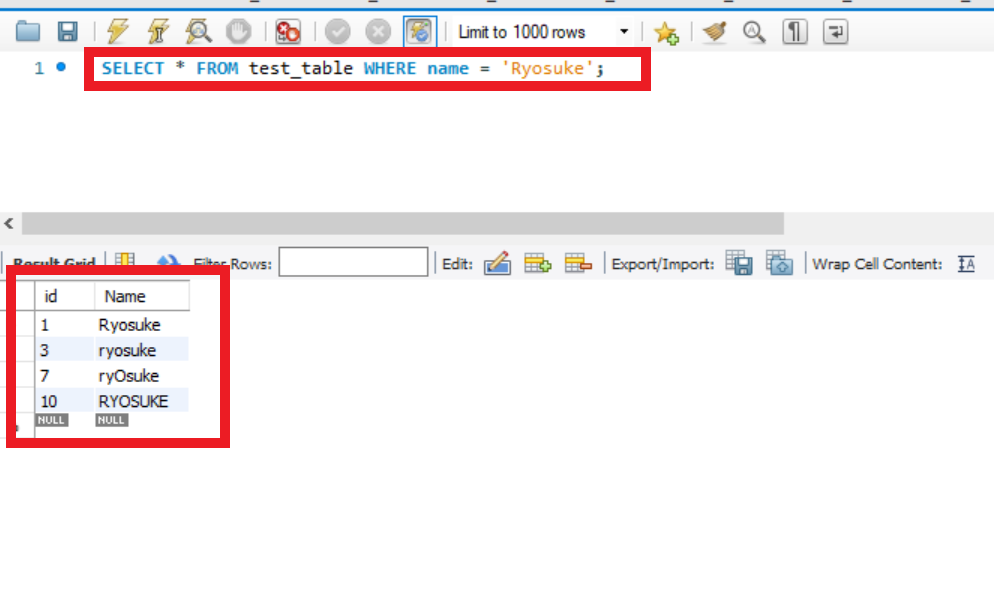
①クエリ初回実行(キャッシュミスパターン)
Cache MISSメッセージが出力され、データソース(RDS)からクエリ結果が適切に表示されているためOK
$ ruby rds_cache.rb "SELECT * FROM test_table WHERE name = 'Ryosuke';"
Cache MISS
[Query results from datasource]
--------------------
id => 1
Name => Ryosuke
--------------------
id => 3
Name => ryosuke
--------------------
id => 7
Name => ryOsuke
--------------------
id => 10
Name => RYOSUKE
②クエリ再実行(キャッシュヒットパターン1)
Cache HIT!が出力され、Elasticacheから適切なクエリ結果が返ってきているためOK
[ec2-user@ip-172-31-34-150 ~]$ ruby rds_cache.rb "SELECT * FROM test_table WHERE name = 'Ryosuke';"
Cache HIT!
[Query results from cache]
--------------------
id => 1
Name => Ryosuke
--------------------
id => 3
Name => ryosuke
--------------------
id => 7
Name => ryOsuke
--------------------
id => 10
Name => RYOSUKE
③小文字化かつスペースをいじったクエリを再実行(キャッシュヒットパターン2)
[ec2-user@ip-172-31-34-150 ~]$ ruby rds_cache.rb "select * from test_table where name = 'Ryosuke';"
Cache HIT!
[Query results from cache]
--------------------
id => 1
Name => Ryosuke
--------------------
id => 3
Name => ryosuke
--------------------
id => 7
Name => ryOsuke
--------------------
id => 10
Name => RYOSUKE
所感
本来はキャッシュを利用してクエリのレスポンスを高速化させたり、データベース負荷を下げることがこのシステムの目的なのですが、
データ数が少なすぎて性能面でのメリットは確認できていないのがなんとも言えない感じです…笑
いずれ時間あったらそこらへんも軽く確認出来たらとは思ってはいます。