ミライトデザイン Advent Calendar 2023 の15日目の記事です。
今年も懲りずにお邪魔しています。
14日目は @FrozenVoice さんの VR 勤務についての記事でした。
数年前までは想像していなかったような新しい働き方を感じられました。
@FrozenVoice さんは常に新しいガジェットを試していく姿勢が本当にすごいなって思います。
今回は、DB のパーティショニングについての記事になります。
自分はパーティショニングを使用した事例にはそこまで遭遇していないのですが、一度めちゃめちゃ助けられたことがあるので、紹介させていただければと思います。
環境
MySQL 8.2.0
PostgreSQL 16.1
パーティショニングとは?
「パーティション(partition)」は、区画・分割・仕切りを意味する英単語です。
DBの場合のパーティショニングとは、 論理的には一つの大きなテーブルであるものを、物理的により小さな部品に分割すること を指します。
例えば、大量のログが蓄積する logs テーブルが存在するとします。
このテーブルを月毎のパーティーションとして分割したイメージ図が下記のものです。
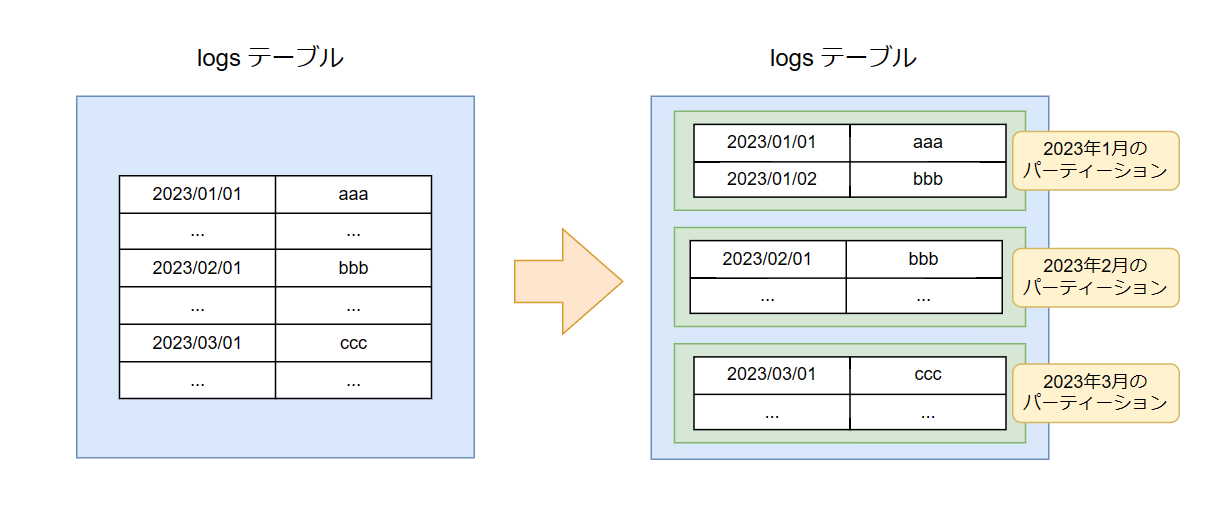
実際にMySQLでパーティショニングされたテーブルを見てみましょう。
下記は月ごとにパーティショニングしたテーブルの例となります。
SHOW CREATE TABLE logs\G
*************************** 1. row ***************************
Table: logs
Create Table: CREATE TABLE `logs` (
`id` bigint DEFAULT NULL,
`access_date` date NOT NULL,
`log` text
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
/*!50500 PARTITION BY RANGE COLUMNS(access_date)
(PARTITION p0 VALUES LESS THAN ('2023-01-01') ENGINE = InnoDB,
PARTITION p1 VALUES LESS THAN ('2023-02-01') ENGINE = InnoDB,
PARTITION p2 VALUES LESS THAN ('2023-03-01') ENGINE = InnoDB,
PARTITION p3 VALUES LESS THAN (MAXVALUE) ENGINE = InnoDB) */
まずは PARTITION p0やPARTITION p1に分割されており、日付で分けられているのが何となくイメージいただければ大丈夫です。
例をシンプルにするためにテーブルに Primary Key を設定していませんが、MySQL の場合はパーティーションに指定するカラムは Primary Key などの一意キーに含まれるカラムを指定する必要があります。
通常のテーブルと同様、普通に SELECT もできますが
SELECT * FROM logs LIMIT 5;
+------+-------------+--------------+
| id | access_date | log |
+------+-------------+--------------+
| 3 | 2023-01-03 | log-00000004 |
| 9 | 2023-01-13 | log-00000010 |
| 10 | 2023-01-02 | log-00000011 |
| 14 | 2023-01-12 | log-00000015 |
| 15 | 2023-01-08 | log-00000016 |
+------+-------------+--------------+
パーティーションを指定して SELECT することもできます。
SELECT * FROM logs PARTITION (p2) LIMIT 5;
+------+-------------+--------------+
| id | access_date | log |
+------+-------------+--------------+
| 13 | 2023-02-26 | log-00000014 |
| 19 | 2023-02-10 | log-00000020 |
| 21 | 2023-02-05 | log-00000022 |
| 26 | 2023-02-12 | log-00000027 |
| 30 | 2023-02-26 | log-00000031 |
+------+-------------+--------------+
パーティショニングの種類
「何を基準にしてパーティショニングするか」についてはDBごとにいろいろな種類があるのですが、 MySQL, PostgreSQL では下記のようなパーティショニング方法があります。
範囲パーティショニング
あるカラムの値の範囲を指定してパーティショニングをする方法です。
最初の例で挙げた、logs テーブルを月毎に分割したのは範囲パーティショニングになります。
他にも、例えば商品の売上テーブルを商品カテゴリー毎に1~100, 101~200 ... と分割する、といったケースも考えられます。
例として、MySQL, PostgreSQL で日付を基準にパーティショニングをする方法をそれぞれ見てみましょう。
CREATE TABLE logs (
`id` bigint,
`access_date` date NOT NULL,
`log` text
) PARTITION BY RANGE COLUMNS(access_date) ( -- access_date の値で範囲パーティショニングを指定
PARTITION p0 VALUES LESS THAN ('2023-01-01'), -- p0 は '2023-01-01' 以前のデータを格納
PARTITION p1 VALUES LESS THAN ('2023-02-01'), -- p1 は '2023-01-01'~'2023-01-31'のデータを格納
PARTITION p2 VALUES LESS THAN ('2023-03-01'), -- p2 は '2023-02-01'~'2023-02-28'のデータを格
PARTITION p3 VALUES LESS THAN MAXVALUE -- p3 は '2023-03-01'以降のデータを格納
);
CREATE TABLE logs (
id bigint,
access_date date NOT NULL,
log text
) PARTITION BY RANGE (access_date);
CREATE TABLE p1 PARTITION OF logs FOR VALUES FROM ('2023-01-01') TO ('2023-02-01');
CREATE TABLE p2 PARTITION OF logs FOR VALUES FROM ('2023-02-01') TO ('2023-03-01');
CREATE TABLE p3 PARTITION OF logs FOR VALUES FROM ('2023-03-01') TO ('2023-04-01');
CREATE TABLE p4 PARTITION OF logs FOR VALUES FROM ('2023-04-01') TO ('2023-05-01');
それぞれ文法は異なりますが、何となく雰囲気は似ていますね。
PostgreSQL のほうは FROM と TO に同じ値が設定されていて境界値がどちらのパーティーションに入るのか一瞬混乱しますが、TO は境界値を 含みません 。
例えば2023-02-01のレコードは p2 に格納されることになります。
リストパーティショニング
あるカラムの値のリストを指定してパーティショニングをする方法です。
範囲パーティショニングと似ていますが、直接値のリストを指定します。
例えば、都道府県ごとに分割するために[北海道], [青森県, 岩手県, 秋田県 ...], [栃木県, 茨城県, 群馬県 ...] と都道府県リストを指定する、というケースはリストパーティショニングになります。
こちらも例として、MySQL, PostgreSQL で都道府県を基準にパーティショニングをする方法をそれぞれ見てみましょう。
CREATE TABLE users (
`id` bigint,
`name` varchar(255) NOT NULL,
`prefecture` varchar(4) NOT NULL
) PARTITION BY LIST COLUMNS(prefecture) (
PARTITION p0 VALUES IN ('北海道'),
PARTITION p1 VALUES IN ('青森県', '岩手県', '秋田県'),
PARTITION p2 VALUES IN ('栃木県', '茨城県', '群馬県')
);
CREATE TABLE users (
id bigint,
name varchar(255) NOT NULL,
prefecture varchar(4) NOT NULL
) PARTITION BY LIST (prefecture );
CREATE TABLE users_p0 PARTITION OF users FOR VALUES IN ('北海道');
CREATE TABLE users_p1 PARTITION OF users FOR VALUES IN ('青森県', '岩手県', '秋田県');
CREATE TABLE users_p2 PARTITION OF users FOR VALUES IN ('栃木県', '茨城県', '群馬県');
値のリストを直接指定する必要があるので、取りうる値が増える場合は注意が必要そうです。
ハッシュパーティショニング
ハッシュパーティショニングは範囲・リストパーティショニングに比べて若干毛色が異なります。
指定したカラムのハッシュ値を計算し、その値を元に指定したパーティション数に分けて割り振る方式となります。
計算されたハッシュ値が均等に分散されるため、データを分散したりランダムアクセスが予想される場合などに効果を発揮するとされています。
例として、従業員テーブルを店舗IDのハッシュ値によって4分割するケースを見てみましょう。
下記はMySQLでのパーティショニング作成となります。
-- MySQL
CREATE TABLE employees (
id INT NOT NULL,
name VARCHAR(255),
store_id INT
)
PARTITION BY HASH(store_id) -- store_id の HASH値
PARTITIONS 4; -- いくつパーティション数を用意するかを指定
正直、自分はハッシュパーティショニングが必要なケースに遭遇したことがないので、もし経験者の方がいたらお話うかがってみたいです。
MySQLには他にも KEY パーティショニングや COLUMN パーティショニングなど、いろいろなパーティショニングがあるので、興味がある人は調べてみてください。
パーティショニングをすると何が嬉しいの?
パーティショニングによってデータを分割するイメージが何となくできたでしょうか。
ただ、そもそもパーティショニングをすることによってどんなメリットがあるのでしょうか。
いくつか見ていきましょう。
検索条件が一部パーティションに集中する場合、パフォーマンス向上が期待できる
WHERE で一部のパーティーションだけ検索すればよい条件が指定された場合、不要なパーティーションを検索対象から除外し、パフォーマンスが向上することがあります。
例として、先ほどの logs テーブルの実行計画を見てみましょう。
まず、条件なしで検索した場合の実行計画は次のようになります。
EXPLAIN SELECT * FROM logs;
+----+-------------+-------+-------------+------+---------------+------+---------+------+-------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------------+-------------+------+---------------+------+---------+------+-------+----------+-------+
| 1 | SIMPLE | logs | p0,p1,p2,p3 | ALL | NULL | NULL | NULL | NULL | 10000 | 100.00 | NULL |
+----+-------------+-------+-------------+------+---------------+------+---------+------+-------+----------+-------+
ここで注目してほしいのは partitions 列で、p0~p3までが指定されています。
では、次に検索条件に日付を指定してみましょう。
EXPLAIN SELECT * FROM logs WHERE access_date BETWEEN '2023-01-20' AND '2023-02-10';
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | logs | p1,p2 | ALL | NULL | NULL | NULL | NULL | 4807 | 11.11 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
先ほどと異なり、partitions 列で、p1, p2のみが指定されています。
今回の検索条件で検索が不要な p0, p3 は初めから検索対象外となっていることになります。
一致しないパーティションを除外するこの機能は、 パーティションプルーニング と呼ばれます。
例えば「大量の売上明細データがあるが、月単位でしか参照しない」というようなケースの場合、パーティショニングによる恩恵は大きいのかなと思います。
パーティーションごとの一括登録・削除を高速で行える
個人的には、一括削除の恩恵が非常に大きいと感じています。
ぶっちゃけ、この話がしたくてこの記事を書いています。
下記の記事でも紹介されているように、そもそもDBでデータを削除する場合はデータがすぐに削除されないため、大量削除を繰り返していると性能が著しく劣化します。
パーティーショニングしている場合、個々のパーティションをDROPすることができるので、TRUNCATE などと同じように高速に、かつ指定したパーティショニングだけ削除を行えます。
例えば「月毎の大量の売上データを取り込み直したい」「〇カ月経過したログを削除したい」といった要望の時に大活躍します。
一括削除をやってみよう
それでは例として、MySQLで先ほどの logs テーブルに大量のデータを登録し、指定した月のデータを一括削除してみましょう。
対象となるテーブルはこちらです。
SHOW CREATE TABLE logs\G
*************************** 1. row ***************************
Table: logs
Create Table: CREATE TABLE `logs` (
`id` bigint DEFAULT NULL,
`access_date` date NOT NULL,
`log` text
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
/*!50500 PARTITION BY RANGE COLUMNS(access_date)
(PARTITION p0 VALUES LESS THAN ('2023-01-01') ENGINE = InnoDB,
PARTITION p1 VALUES LESS THAN ('2023-02-01') ENGINE = InnoDB,
PARTITION p2 VALUES LESS THAN ('2023-03-01') ENGINE = InnoDB,
PARTITION p3 VALUES LESS THAN (MAXVALUE) ENGINE = InnoDB) */
大量データの登録処理はこちら
CREATE TABLE numbers (`no` int DEFAULT NULL);
INSERT INTO numbers VALUES (1), (2), (3), (4), (5), (6), (7), (8), (9), (10);
INSERT INTO logs
SELECT
@rownum,
'2023-04-30' - INTERVAL FLOOR(RAND() * 120) DAY,
CONCAT('log-', LPAD(@rownum := @rownum + 1, 8, '0'))
FROM
numbers AS s1,
numbers AS s2,
numbers AS s3,
numbers AS s4,
numbers AS s5,
numbers AS s6,
numbers AS s7,
(SELECT @rownum := 0) AS v
;
データとしては 2023年1月~4月のレコードがランダムに1000万件登録された状態で検証します。
ここから2023年1月分のデータを削除するとしましょう。
まずは普通に DELETE 文で削除してみます。
DELETE FROM logs WHERE access_date BETWEEN '2023-01-01' AND '2023-01-31';
Query OK, 2333558 rows affected (13.32 sec)
速度としては遅すぎはしないが早くもない、といったところでしょうか。
それでは2023年2月のデータが格納されている、PARTITION p2をまるっと削除してみましょう。
ALTER TABLE logs DROP PARTITION p1;
Query OK, 0 rows affected (0.08 sec)
-- 件数は確かに減っている
select count(*) from logs\G
*************************** 1. row ***************************
count(*): 7665870
、、、何が起きたかわからないくらい一瞬で終わりました。
データ数を数えると、確かにレコードが削除されていることがわかります。
ALTER TABLE なのでトランザクション内に含められないなどの問題はありますが、大量DELETEによる問題を回避できるのは嬉しいところです。
注意点として、パーティション自体も削除されているため、もし再度削除したパーティションに対してデータを登録したい場合はパーティションの追加 or 再構成が必要になります。
-- 追加 ※ただし MySQL の範囲パーティーションは後ろにしか追加できないため、
-- 今回の例のように前のパーティーションを削除して再作成したい場合は下記の再構成を使用する必要がある
ALTER TABLE logs ADD PARTITION (
PARTITION p1 VALUES LESS THAN ('2023-02-01')
);
-- 再構成 この例では残っているパーティーションを2つに分割している
ALTER TABLE logs REORGANIZE PARTITION p2 (
PARTITION p1 VALUES LESS THAN ('2023-02-01'),
PARTITION p2 VALUES LESS THAN ('2023-03-01')
);
おわりに
パーティショニングについてご紹介してきましたが、いかがだったでしょうか。
パーティショニングを必要とするケースは自分の経験ではそこまで多くありませんでしたが、一部のケースでものすごい力を発揮してくれたりするので、頭の片隅に留めておくといいことあるかもしれません。
明日は @hirodragon さんの記事になります。
自分も毎年楽しみにしているので、ご期待ください。
参考サイト