はじめに
Python in Excel はExcelでPythonのコードを実行することができます。
VBAと違い、セル内にコードを記述します。
せっかくExcelを使うので、セル内にゴリゴリコードを書くのではなく、PowerQueryを活用した機械学習をやってみました。
やること
Python in Excel を用いて機械学習をする。
Kaggleの「Titanic - Machine Learning from Disaster」を用いて、回答を提出する。
(https://www.kaggle.com/competitions/titanic/)
データの前処理にPowerQueryを活用し、Pythonのコードをあまり書かずに実現する。
※注
投稿者はPython in Excelで初めて機械学習に触れたレベルですので、機械学習の解説はありません。とりあえず提出できることを目標にしています。
回答提出までの流れ
・訓練データをPowerQueryで整形して取り込む
・機械学習モデルを作成する
・テストデータをPowerQueryで取り込み、提出用のファイルを作成する
データ取り込み
まずはPowerQueryでデータを取り込み、seabornで可視化してデータを分析します。
取り込み
- 訓練データ(train.csv)をダウンロードする
- データの取得の「テキストまたはCSVから」で訓練データを取り込む
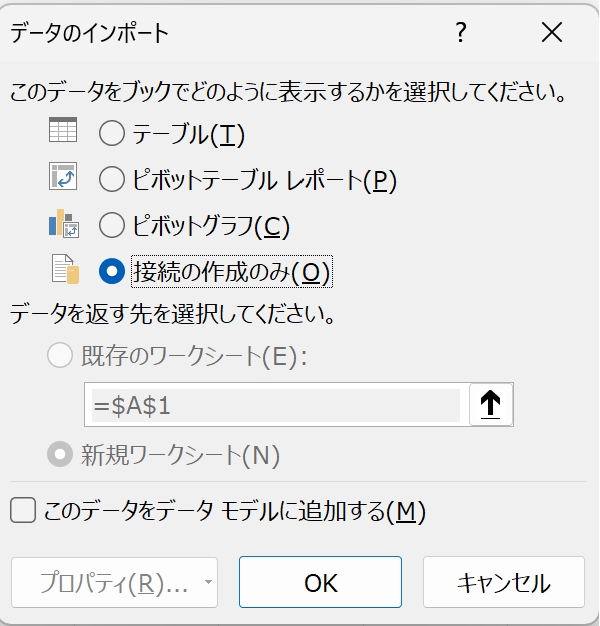
「読み込み先」を選択し、「接続の作成のみ」にする

欠損値を確認
PowerQuery上で、フィルタから欠損値を確認します。Age、Embarkedに欠損値(null)があるようです。もしAgeやEmbarkedを機械学習に使用する場合は、何らかの方法で補完する必要があります。

Excelのシートに取り込む
セル内で
=PY(
と入力すると、数式バーが緑色の"PY"に代わり、Pythonの入力モードになります。
ここでPythonのコードを入力し、「Ctrl+Enter」でコミットします。

in_data = xl("train")
と入力して、PowerQueryのデータを取得します。
セルの表示は下記のようになります。
データの中身を表示することもできます。
数式バーからPython出力を「Excelの値」に変更することでデータの中身が表示されます。
テーブルの中身が表示されます。

seabornで可視化
では取り込んだ訓練データをグラフなどで表示します。
seabornを使います。seabornは初めからsnsとしてimportされていますので、先ほどのコードに1行追加することでグラフを表示することができます。
in_data = xl("train")
sns.barplot(x='Age', y='Survived' , data=in_data)
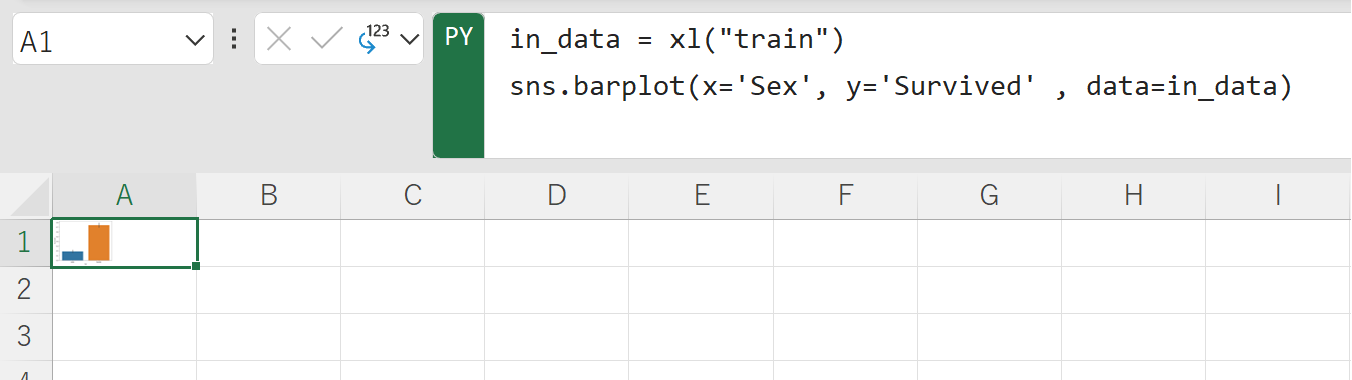
グラフが小さいので、セルの大きさを調整します。

計算順序はA1→B1→C1…→A2→B2→C2…→A3→…と進みます。
次は隣のB1セルに違うグラフを書いてみます。A1セルで「in_data」は定義済みのため、改めて定義する必要はありません。
sns.barplot(x='Pclass', y='Survived' , data=in_data)

ヒートマップも描いてみます。
cor = in_data[[ 'Survived','Age','Pclass','Fare']].corr()
sns.heatmap(cor, cmap= sns.color_palette('coolwarm', 10), annot=True,fmt='.2f', vmin = -1, vmax = 1)

データを可視化して特徴を掴み、データを整形していきます。
訓練データをPowerQueryで整形する
文字を数値に
Sexはmale、femaleと文字列になっています。
機械学習のために男性=0、女性=1と数値に変更します。
PowerQueryの値の置換で変換します。
ちなみに「female」を1に変換するより先に、「male」を0に変換すると「female」が「fe0」になるので注意してください。
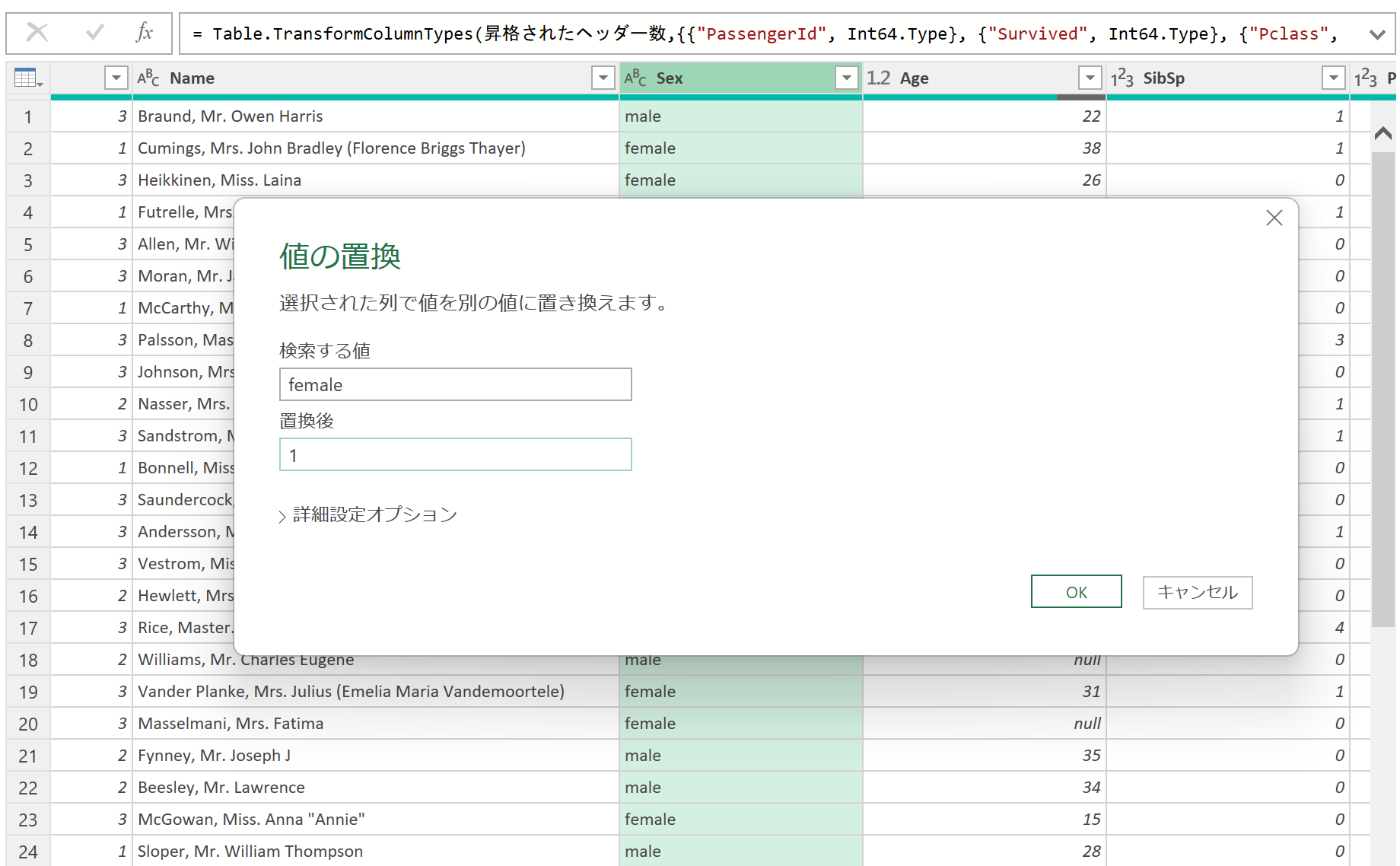
同じようにEmbarkedのC=0、S=1、Q=2に置換します。
2つの項目を足す
SibSpは兄弟、配偶者の数、Parchは親、子供の数です。
この2つを足して、新しい項目「Family」を作成します。
カスタム列から新しい列名を「Family」、カスタム列の式を[SibSp]+[Parch]に設定します。
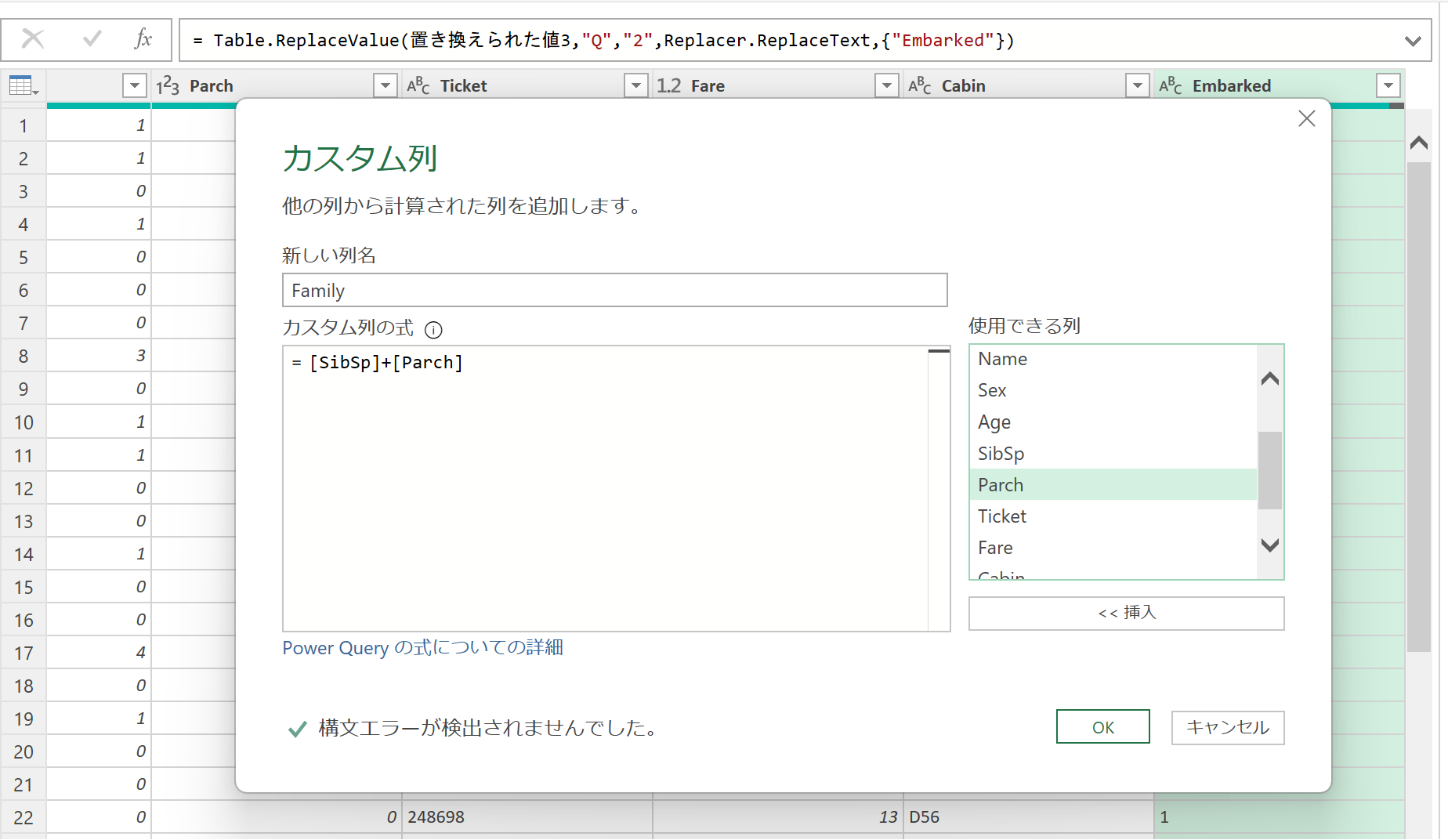
条件分岐
Family=0の時は単独での乗船となり、生存率に影響がありそうです。
Family=0の時に1となる新しい列「IsAlone」を作成します。
条件列の追加から作成します。

欠損値の処理
Ageに欠損値があるままだと正しく機械学習できません。
カスタム列Age2を作成し、AgeがnullならAgeの平均値を返すようにします。
if [Age] = null then List.Average(削除された列[Age]) else [Age]
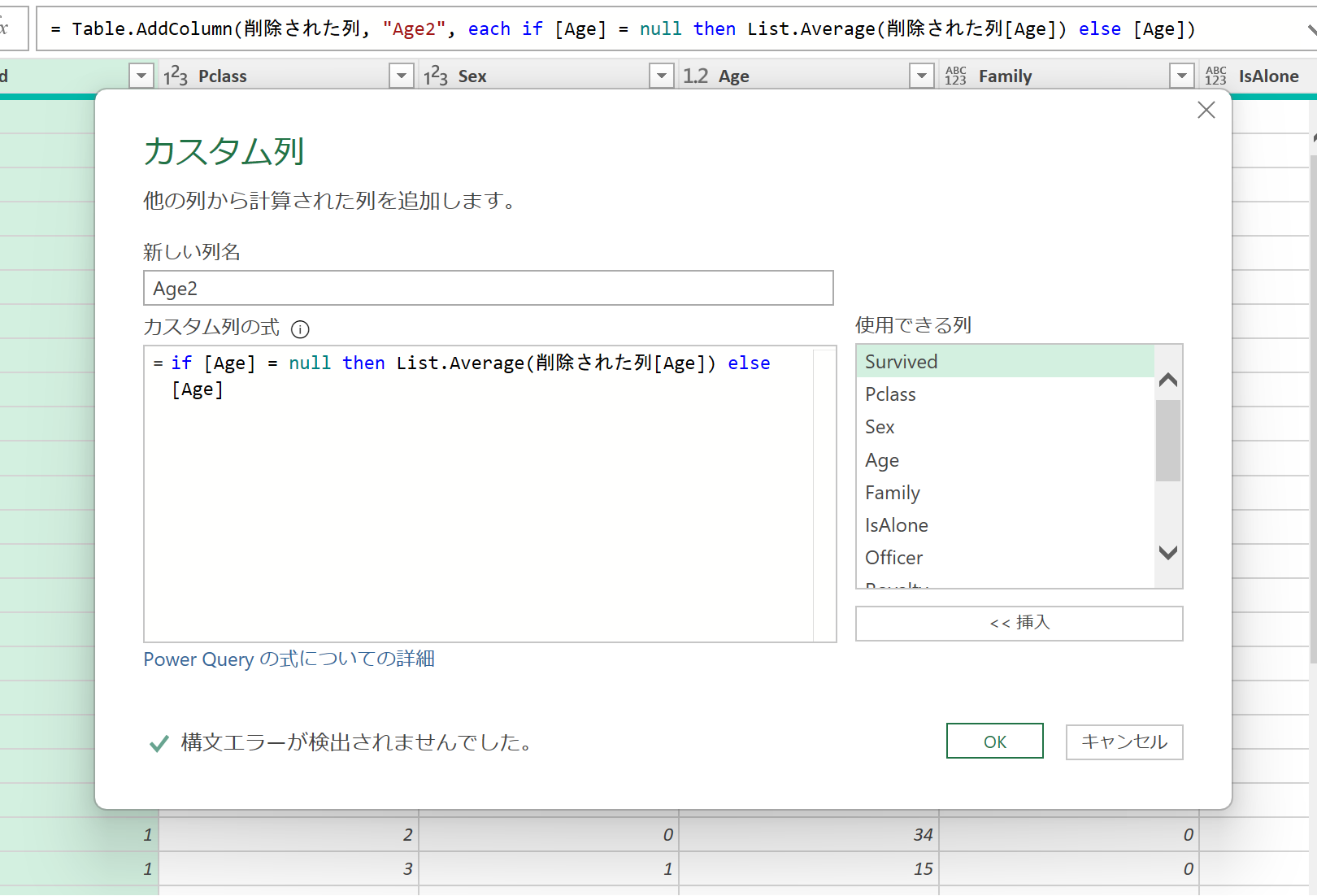
名前に特定の文字が含まれているか
Nameに特定の文字が含まれているかどうかで、人物の属性を分けます。
Officer:"Rev""Dr""Major""Capt""Col"のどれかが含まれている
Royalty:"Jonkheer""Don""Sir""the Countess""Dona""Lady"のどれかが含まれている
Mr:"Mr."が含まれている
Master:"Master"が含まれている
Miss:"Mlle""Miss"のどれかが含まれている
Mrs:"Mme""Ms""Mrs"のどれかが含まれている
Master:"Master"が含まれている
条件列の追加から下記のように作成します。
図はOfficerの項目です。
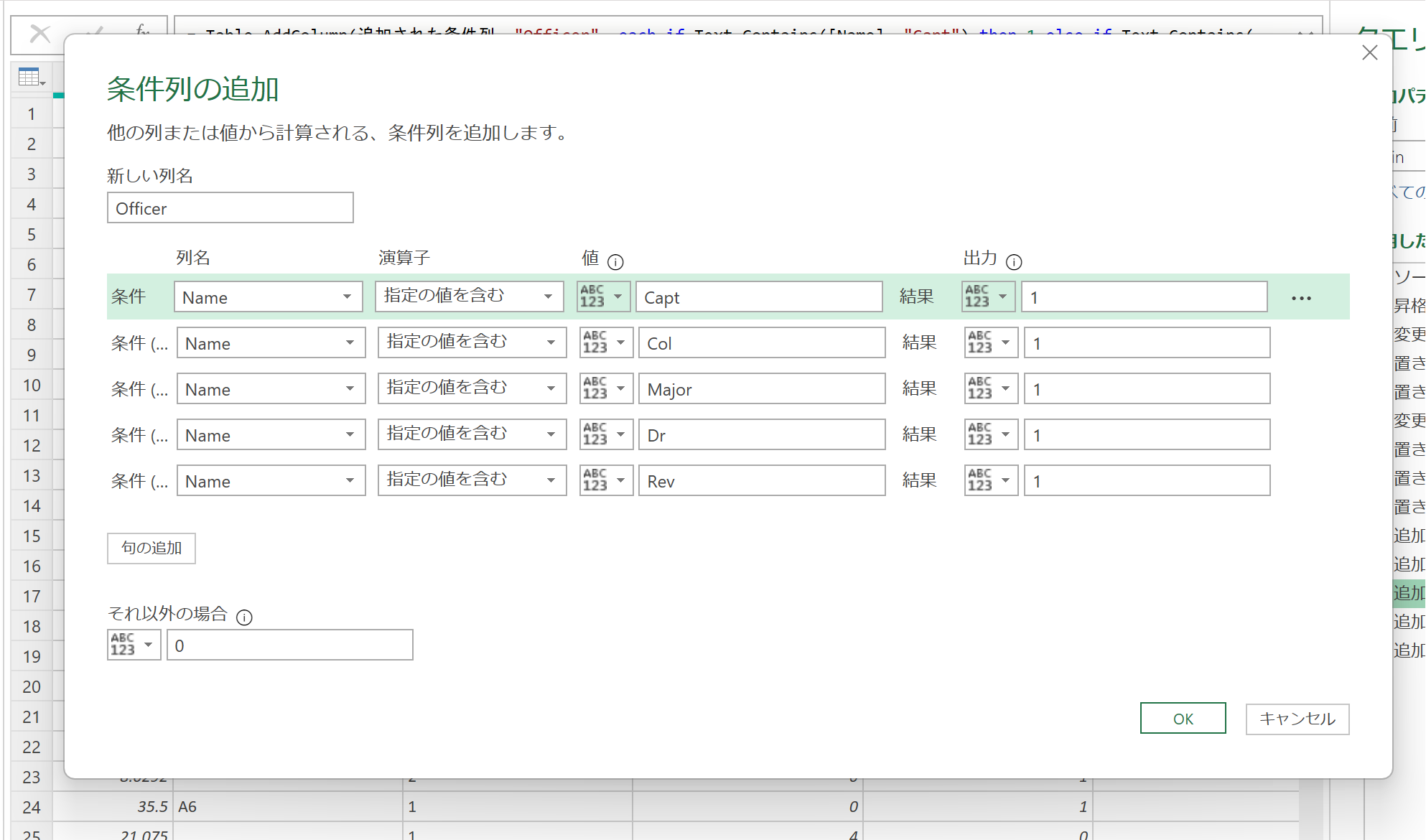
年齢を4つのカテゴリに分ける
年齢をそのまま使うのではなく、4つのカテゴリに分けて学習に使用します。
年齢順に4分割して階層を作成し、下位25%、25%~50%、50%~75%、75%以上の4つのカテゴリに分類します。
1.行数の変数を作成する
詳細エディターに、行数を入れる変数「row_count」を定義します。
row_count = Table.RowCount(変更された型),
こんな感じで途中(4行目)に入れときます。

2.Age列を昇順に並び替える
PowerQueryのホームタブの並び替えで並び替える
3.インデックス列を追加する
4.インデックス列 ÷ row_count からどのカテゴリに属するか判定する
項目Age3を作成し、下位25%なら0、25%~50%なら1、50%~75%なら2、75%以上なら3にします。
if [インデックス]/row_count < 0.25 then 0 else if [インデックス]/row_count < 0.5 then 1 else if [インデックス]/row_count < 0.75 then 2 else 3
不要な列を削除する
Survived、Pclass、Sex、Family、IsAlone、Officer、Royalty、Master、Mrs、Miss、Mr、Age3以外の列は不要なので削除します。
機械学習モデルを作成する
セルA2にPythonコードを書いていきます。
X_allはSurvived列を除いたテーブル、y_allはSurvied列のみのテーブルです。
訓練データの1/3を予測精度テストに用います。
from sklearn.model_selection import train_test_split
X_all = xl("train").drop(columns='Survived')
y_all = xl("train")['Survived']
X_train, X_test, y_train, y_test = train_test_split(X_all, y_all, test_size=0.33, random_state=0)
これで訓練データを学習用のデータと精度確認用のデータに分割できました。
さらにA3セルに予測精度を確認するコードを記述します。
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
RF=RandomForestClassifier()
RF.fit(X_train, y_train)
y_true, y_pred = y_test, RF.predict(X_test)
classification_report(y_true, y_pred)
セルにレポートが表示されます。
accuracyが82%なので、まあまあの予測精度がありそうです。

テストデータをPowerQueryで取り込み、提出用のファイルを作成する
テストデータをPowerQueryで取り込み、訓練データの取り込みと同じ加工をする必要があります。訓練データと同様に接続のみで作成し、詳細エディターでCSV取り込みの行(1行目)より後を訓練データからコピペすればOKです。
コピペしたら2点修正します。
1 .テストデータにはSurvived列が無いので、Survived列のヘッダを作る部分を削除します
変更された型 = Table.TransformColumnTypes(昇格されたヘッダー数,{{"PassengerId", Int64.Type}, {"Survived", Int64.Type}, {"Pclass", Int64.Type}...
「{"Survived", Int64.Type},」を削除します。
2 .Kaggleに提出するデータを作成するのでPassengerId列を削除せずに残しておきます
Kaggleに提出するデータはPassengerIdとSurvived列が必要なので、PassengerIdを残します。
閉じてExcelのシートに戻ります。
新しいシートを作成し、A1セルに入力します。
PassengerId列は予測には不要であるため、初めにPassengerIdを除外して予測し、予測した結果に改めてPassengerId列を結合します。
X_test = xl("test").drop(columns='PassengerId')
y_pred = RF.predict(X_test)
my_solution = pd.DataFrame({'PassengerId':xl("test")['PassengerId'],'Survived':y_pred})
タイタニックの生存者予想ができました。

あとはこれをCSVに保存して、Kaggleに投稿すればOKです。

スコアは0.77511でした。accuracyが82%あったのでもう少し良いスコアが出るのかと思いましたが、簡単にはいかないようです。
感想
データの前処理をPowerQueryでやりましたので、予測に必要なPythonのコードは10行ほどで済みました。
Python in Excelについて、「セルの中にコードを書くのがやりづらい」「Pythonで処理してCSVでExcelにデータ渡した方が効率が良い」といった意見を見ました。
Pythonでコードが書くことができる人向けというよりは、私のように普段はExcelしか使っていないような人がセルに数行のコードをチマチマ書いて、よりリッチな可視化や分析をしていくと便利かと思います。