概要
pytorch v0.10.0 からMVDRが実装されたので、Pytorch-lightningを使用してMVDRを用いた音声強調に挑戦した
以下に使用したgithubのリンクを掲載する
https://github.com/Nushigawa03/MVDR
目次
- データセットについて
- 全体構成
- 結果
- 感想
- 参考
データセットについて
L3DASは、アンビソニックマイクで3D録音された音声データからなるデータセットとなっている
このデータセットは以下のリンクからダウンロードできる
https://zenodo.org/record/4642005
このデータセットはTask1とTask2から構成されていて、今回はTask1を使用した
Task1では、音声強調のための学習データとして3D録音された4chの雑音入り音声、教師データとして雑音なしのモノラル(1ch)音声が用意されている
今回は簡単のために評価データのL3DAS_Task1_dev(2.6 GB)を、さらに学習データと評価データに分割して使用した
このデータセットの学習データにはAフォーマットとBフォーマットの2種類のフォーマットが用意されている
Aフォーマットは、アンビソニックマイクの4つのマイクで録音した無加工の音声で、Bフォーマットは、360度どこに音声が広がっているかを明示的に処理したデータである
今回は無加工の音声信号を処理するために、Aフォーマットを用いた
全体構成
全体構成は次の4つからなる
- ノイズ付きスピーチを短時間フーリエ変換でスペクトグラムに変換する
- それをMaskGeneratorに渡しスピーチ用のマスクとノイズ用のマスクを生成する
- 元のスペクトグラムと2つのマスクをMVDRに渡しノイズを除去したスペクトグラムを生成する
- スペクトグラムを逆短時間フーリエ変換で元に戻すことでノイズを除去した音声を生成する
MaskGeneratorについて、スピーチとノイズに分離したいので2つのマスクを生成する
MaskGeneratorはスペクトグラム[バッチサイズ, 周波数, 時間]を入力とし、分離数と同じ数のマスク[バッチサイズ, 分離数, 周波数, 時間]を返す
MVDRはスペクトグラム,スピーチマスク,ノイズマスク[バッチサイズ, 周波数, 時間]を入力とし、ノイズが除去されたスペクトグラム[バッチサイズ, 周波数, 時間]を返す
class MVDRBeamformer(pl.LightningModule):
def __init__(self,
n_fft=1024,
kernel_size=3,
num_feats=16,
num_hidden=64,
num_layers=2,
num_stacks=4,
msk_activate="sigmoid",
batch_size=1,
):
self.maskgeneretor=torchaudio.models.conv_tasnet.MaskGenerator(
input_dim=n_fft//2 +1,
num_sources=2,
kernel_size=kernel_size,
num_feats=num_feats,
num_hidden=num_hidden,
num_layers=num_layers,
num_stacks=num_stacks,
msk_activate=msk_activate)
self.mvdr = torchaudio.transforms.MVDR(
ref_channel=0,
solution="stv_evd",
multi_mask=True
)
self.stft = torchaudio.transforms.Spectrogram(
n_fft=n_fft,
hop_length=n_fft//4,
power=None,
)
self.istft = torchaudio.transforms.InverseSpectrogram(
n_fft=n_fft,
hop_length=n_fft//4,
)
def forward(self, x):
spec = self.stft(x)
mask = self.maskgeneretor(spec.abs())
stft_est = self.mvdr(spec, mask[:,0], mask[:,1])
est = self.istft(stft_est, length=x.shape[-1])
return est
結果
このニューラルネットワークを学習させ、学習過程は以下のようにLossが減少していることが確認できた
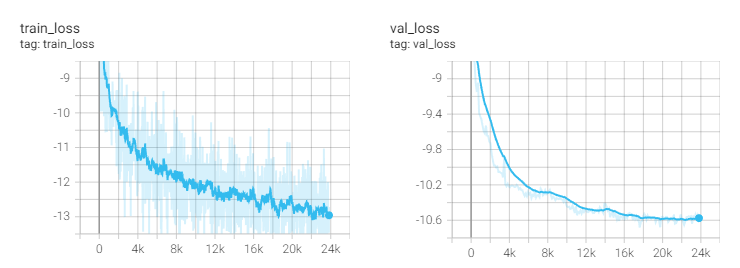
学習後のモデルで試しにL3DAS(ノイズ付きの4ch音声)の84-121550-0000_A.wavを入力すると、ある程度ノイズが除去された音声が出力された→出力結果
強調前後のスペクトグラムは以下のようになり、ノイズが減少していることがわかる
(左が元の音声で、右がノイズ除去後の音声)

感想
パラメータを適当に設定したまま変更せず学習を進めたので思うような結果は出なかった
データセットにあるアンビソニックのAやBの意味がわからなかったので少し行き詰まった
Pytorch-lightningは宣言するだけであとはいい感じに取り繕ってくれるのですごい
本来colabでの公開を予定していたが断念することとなってしまった
今後はマシンパワーとデータサイズを上げて大規模に学習し直すつもりだ
(この記事は研究室インターンで取り組みました:https://kojima-r.github.io/kojima/)
参考
https://github.com/pytorch/audio/issues/2001
https://www.hark.jp/document/2.4.0/hark-document-ja/subsec-MVDR.html
https://tech.jxpress.net/entry/2021/11/17/112214
https://qiita.com/ground0state/items/c1d705ca2ee329cdfae4
https://qiita.com/niusounds/items/81170304c1e9c7c6af2a