わたし、公式ドキュメントわかんないです。
MLStudio classicでモデル作成やデプロイは何回かしてきてます。
今回、再学習させてみたいなと思って公式ドキュメントを読んでみたのですがよくわかんなくてあっちっこっち行ったり来たり。
どうにかできるようになったので忘れないように記事にします。
また、初めて使う人向けに書いてるつもりなので細かいことは省いているのでゆるしてください。
大まかな流れ
- 学習実験を作る
- 予測実験を作る
- 予測実験のデプロイ
- 再学習をデプロイ
- 再学習を行う
- 再学習結果を予測実験に反映する
- 反映したかをテストする
です。
動作環境
途中でPythonを使うので環境とimportしたものを書いておきます。
- python3.7
- blobStorage
| 名前 |
|---|
| urllib |
| azure-storage-blob |
利用するデータについて
それではまず今回使うデータです。
再学習できたのかどうかが知りたいので単調すぎるデータを使います。
下に学習用データ、テスト用データ、リモデル用データを書いておきます。
id,target
1,1
2,1
3,1
4,1
5,1
id,target
1,0
2,0
3,0
4,0
5,0
作成したモデルではどんな数を入れても必ず1が返ってくるモデルを期待します。
なのでテストデータを入れてもすべて1で返ってくるはずです。
すべてが0であると学習することで0が返ってくることを期待します。
モデルとしていいモデルでは全くないので、あくまでテスト用として使います。
学習実験を作成しましょう
それではモデルを作成します。
MLStudioにログインしたら、EXPERIMENTSを選択して画面下のNEWをクリックしましょう
そしたらBlank Experimentをクリックしましょう。
これで予測モデルの作成準備ができました。
では実際にモデルを作っていきます。
この検索窓から必要なブロックを検索して追加していくだけです。
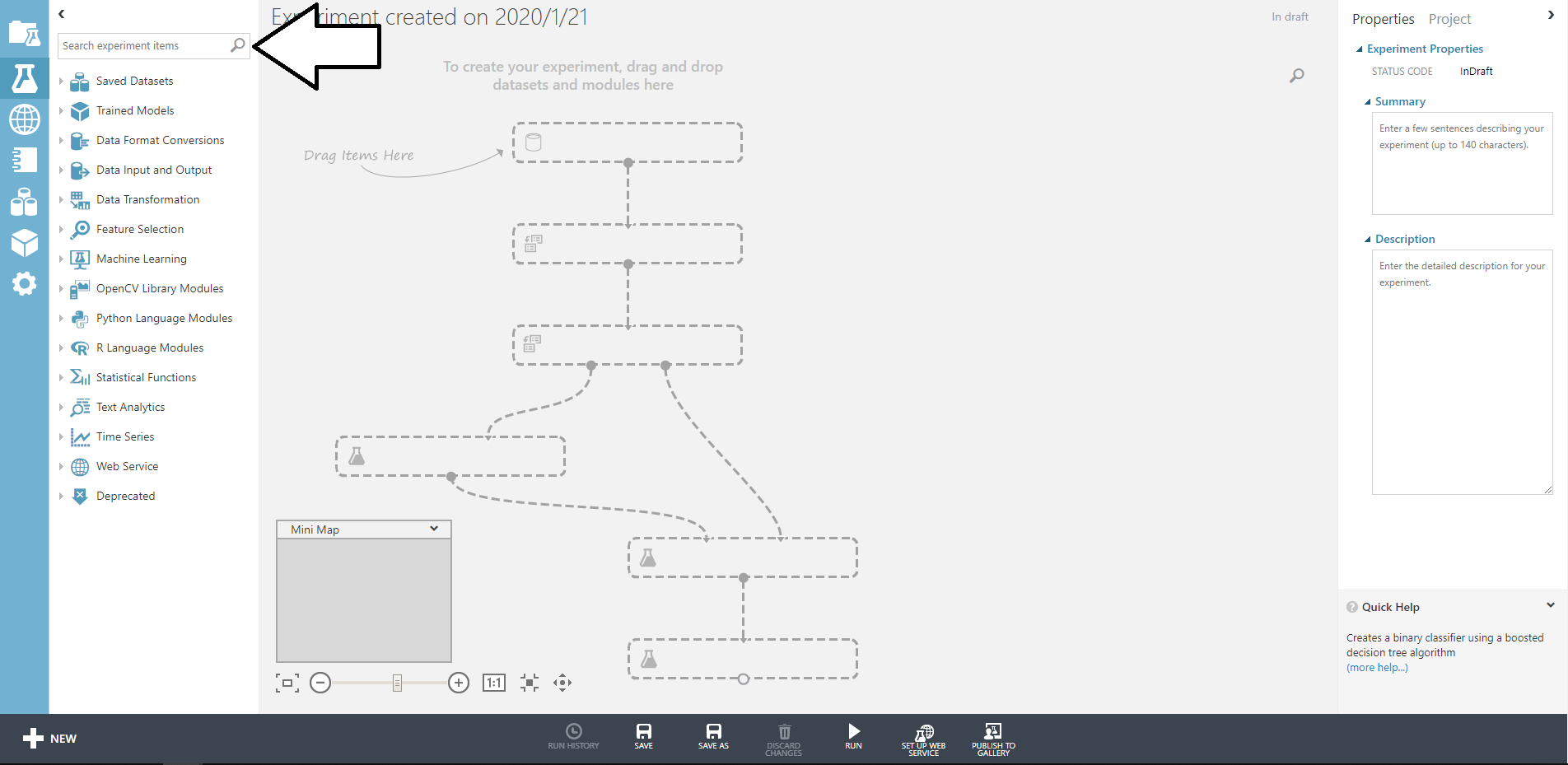
今回は二項(一応)なのでtwo classで検索してできたたボックスを配置します。今回はTwo-Class Boosted Decision Treeを利用しました。
そのほかのブロックも同様に検索して画像のように配置しましょう。
次に各ブロックの設定をしていきます。ブロックをクリックすると
ページ右側に設定項目が出てきます。
アルゴリズムブロックではパラメータの設定ができます。今回はそのままでいいでしょう。
続いてimport Dataです。ここでは学習に用いるデータの指定をします。
自身のblobユーザー名、Key、ファイルパスを記述しましょう。
今回のデータはフォーマットはcsvなのですが、ファイルにはヘッダーがあるため、File has header rowにチェックを入れましょう。
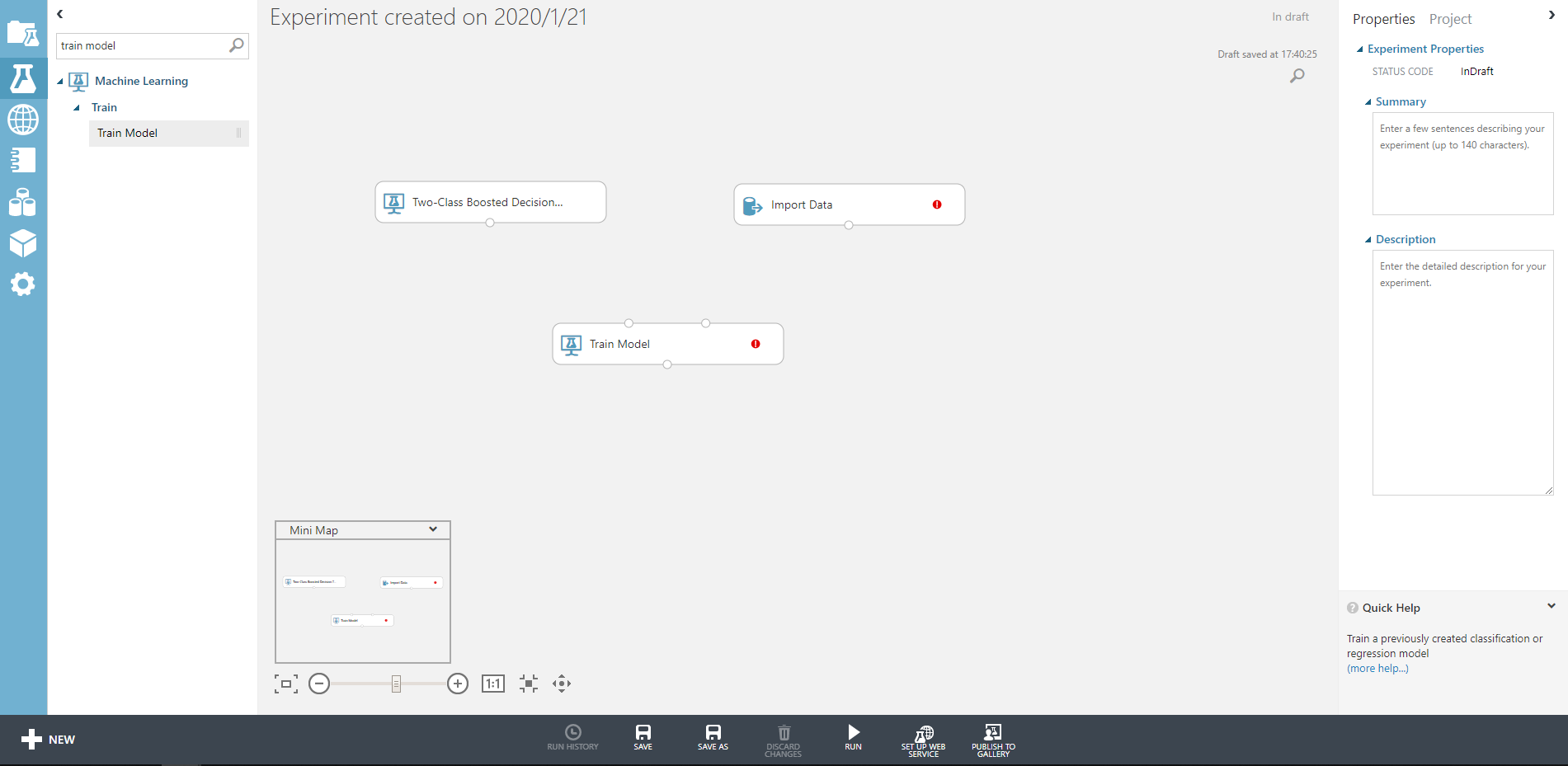
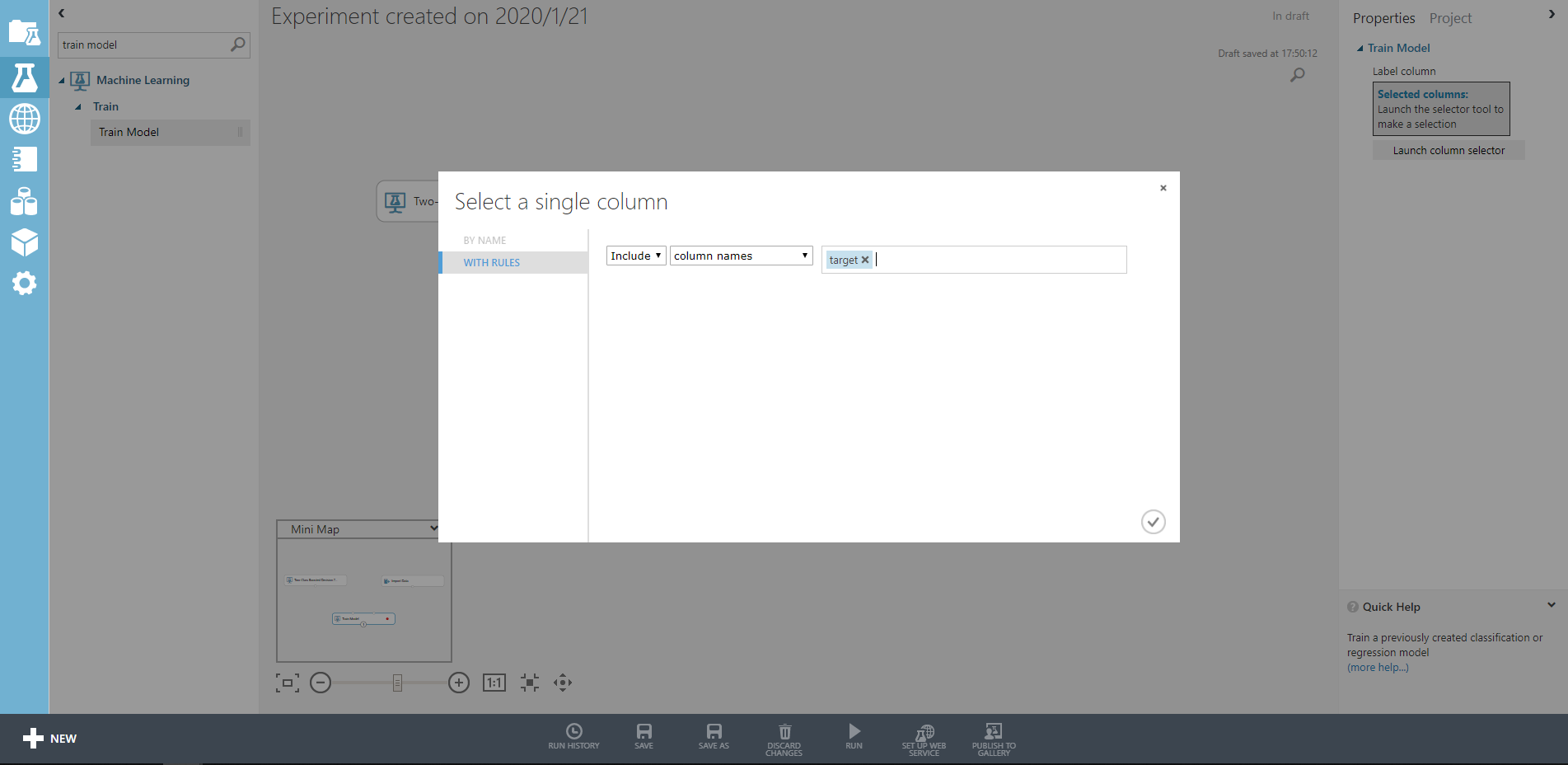
最後にTrain Modelです。こちらでは学習するターゲットのカラム名を指定してあげます。
今回はtargetを学習したいので、Launch column selectorでtargetを記入してあげます。
ここまで終わったなら、ブロック同士を線でつないでみましょう。
Train Modelは左右反対には線でつなげないので気をつけましょう。
下のように配置できたら画面下部のRUNをクリックして実行してみましょう。
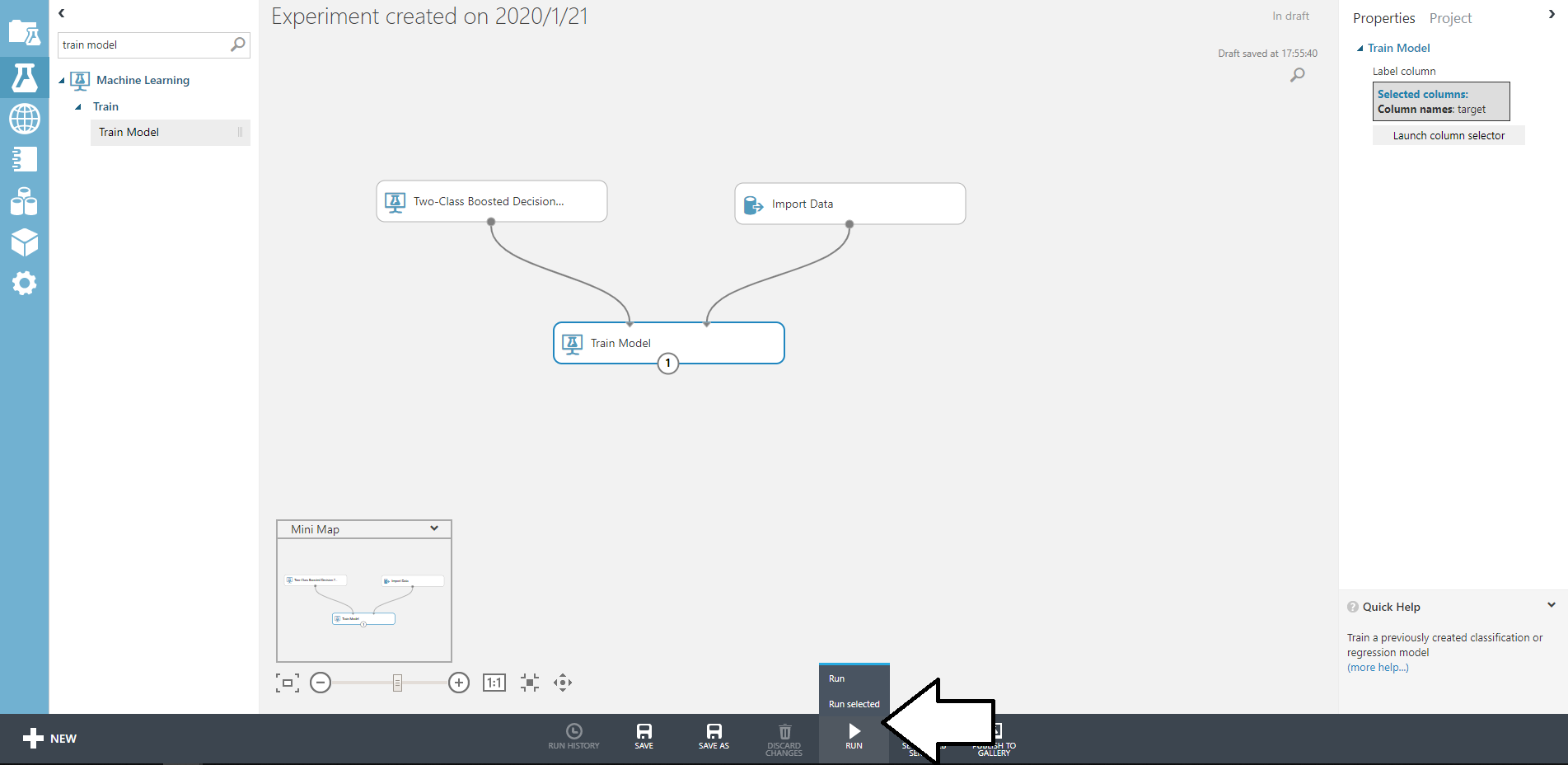
ボックスすべてにチェックマークがついたら完了です。
途中で止まってしまった場合、どこかに間違いがあるはずです。
blobのファイル名が違ったりするかもしれないですね(体験談)
全部にチェックが付いたらモデルの完成です!
予測実験を作る
さてさて、では先ほど作ったモデルを使ってデータを投げると答えを返してくれるものを作りましょう。
先ほどのRUNの隣にあるSET UP WEB SERVICEからPredictiv web Serviceをクリックしましょう。
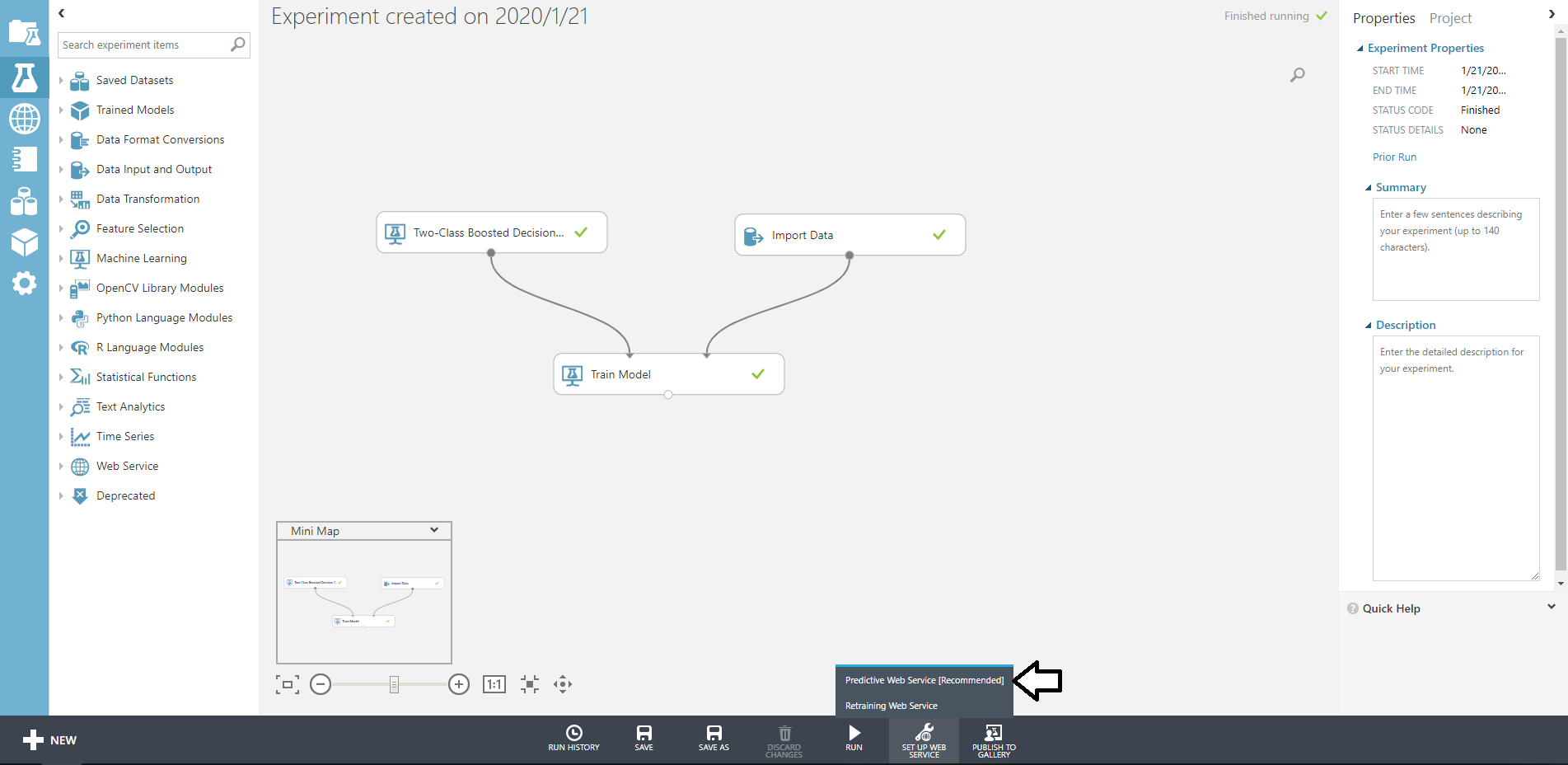
するとボックスがうようよ動いて下のようになります。
検索窓からExport Dataを持ってきて、blobのユーザー名などを書きます。
ここで書いたパスにテスト結果が出力されることになります。
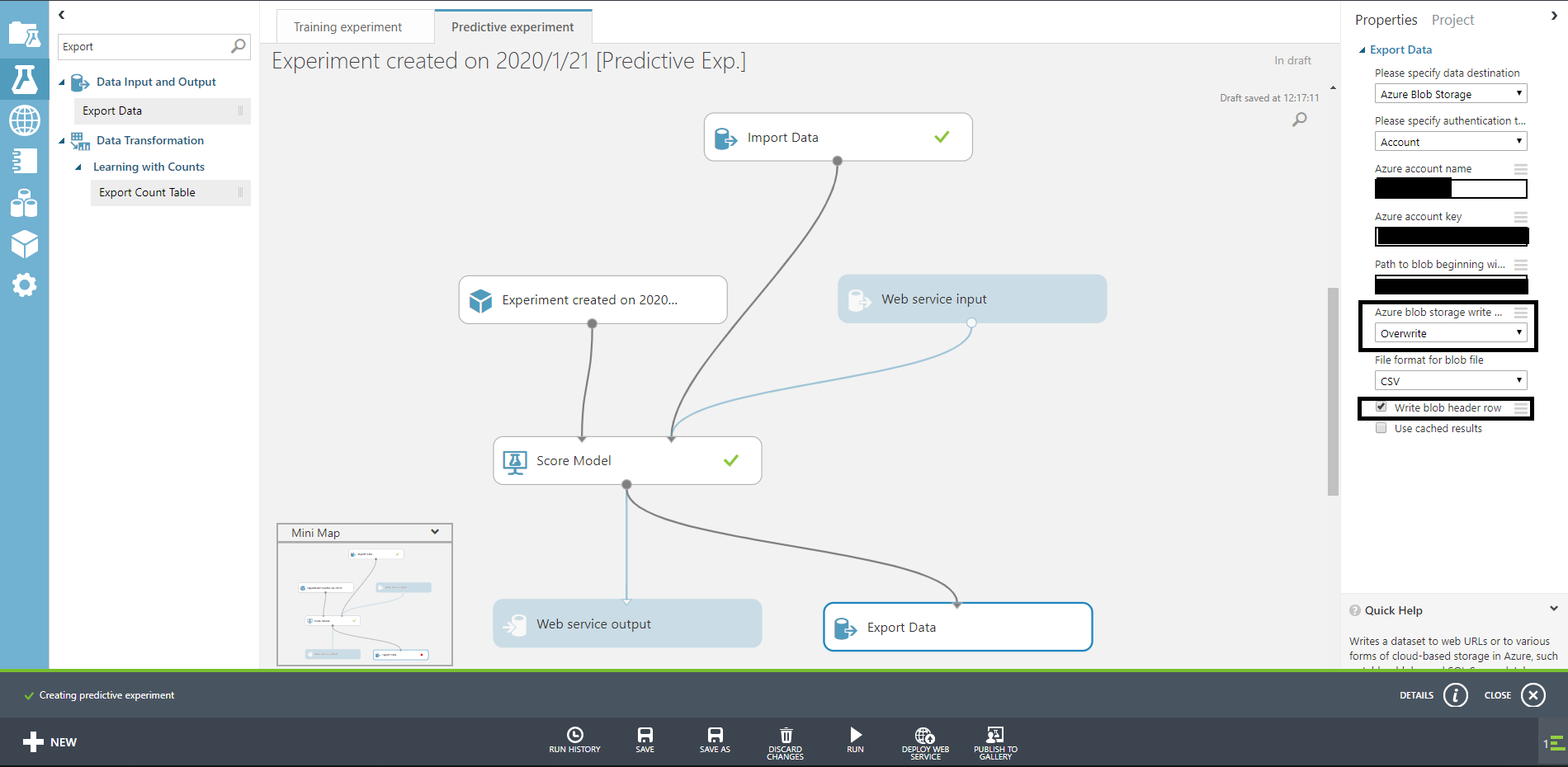
もう一度RUNしてみましょう。
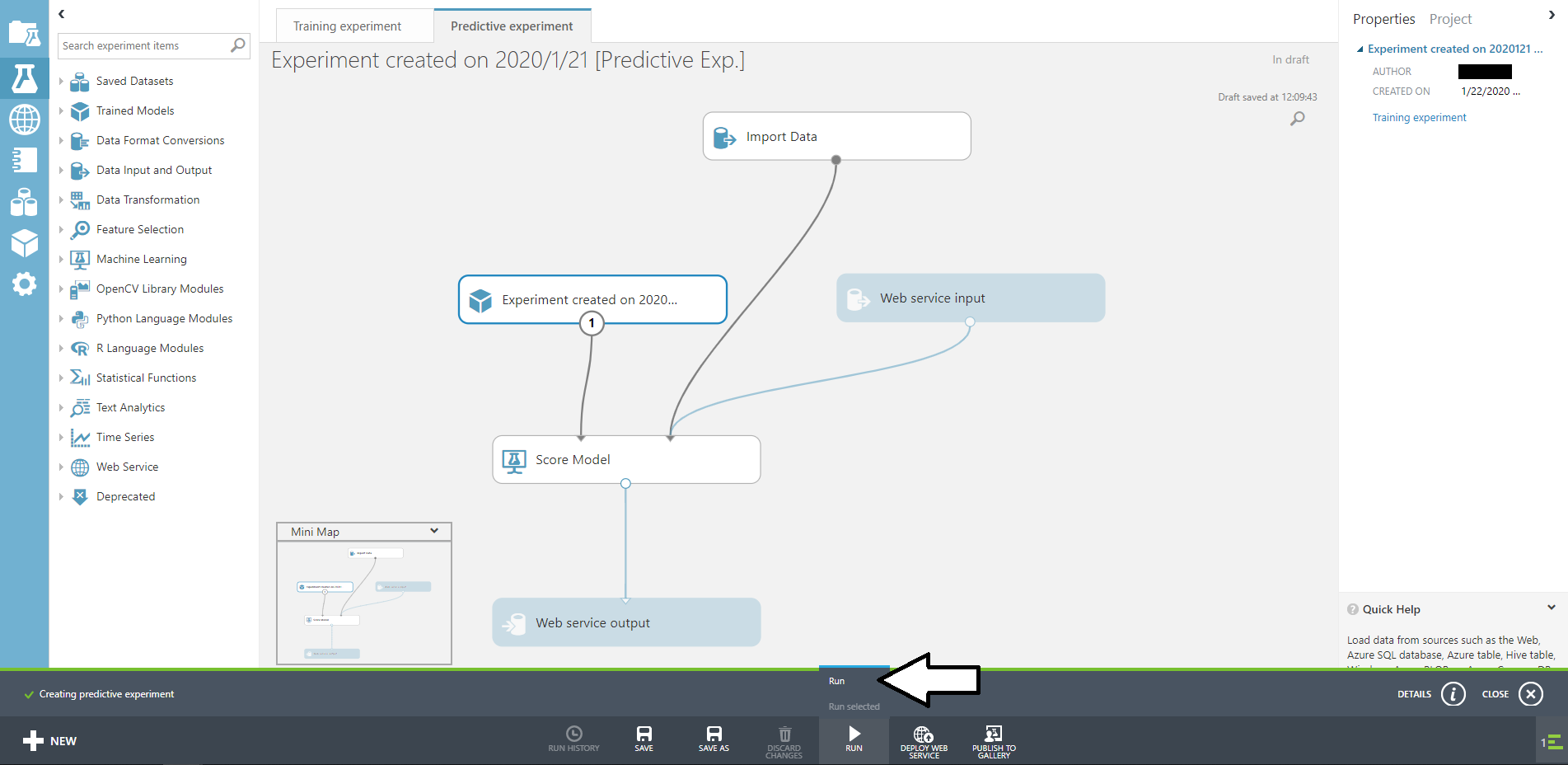
先ほどのようにチェックが付いたのなら完了です。
完了したならDEPLOY WEB SERVICEをクリックしましょう。
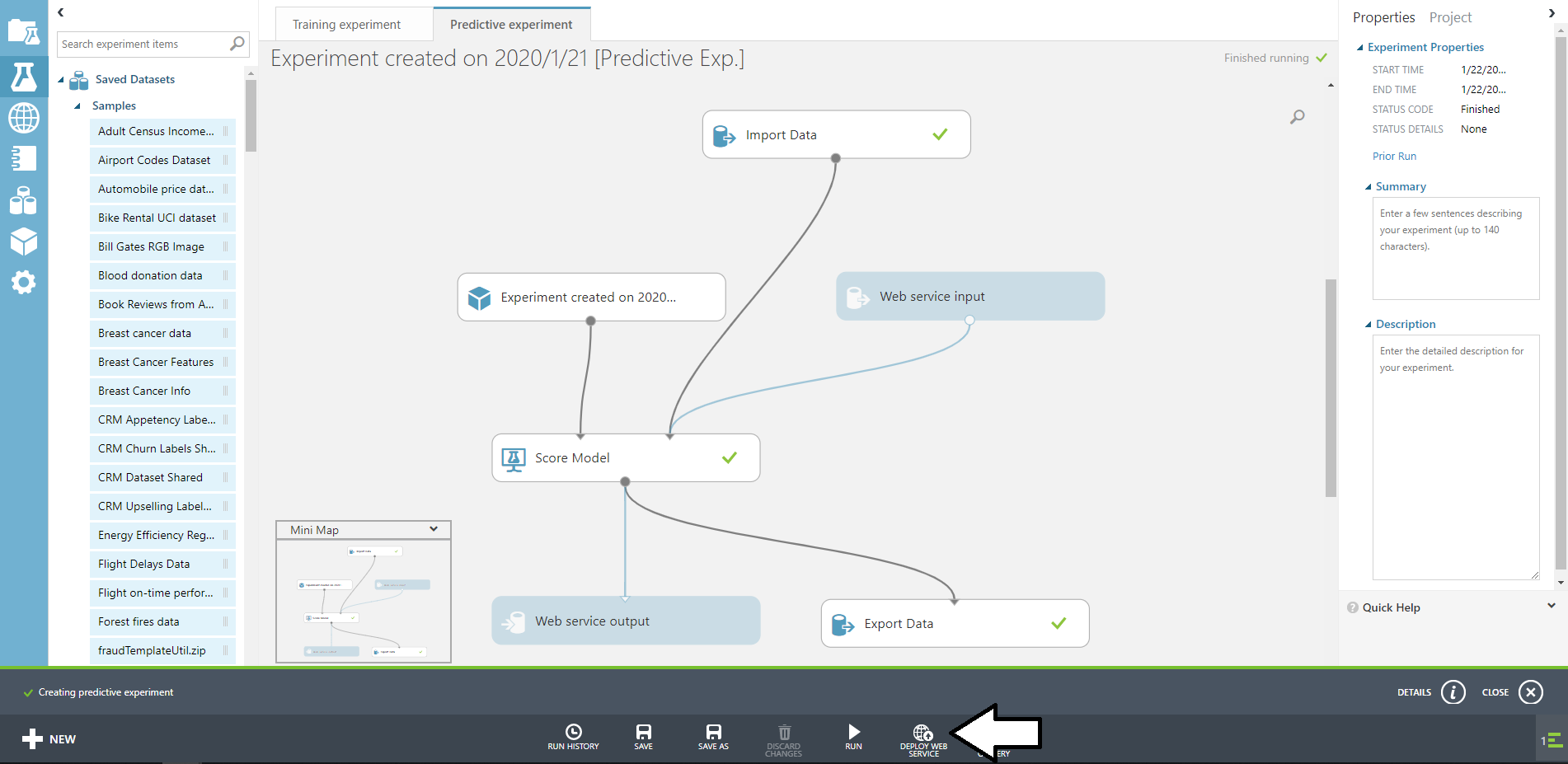
しばらくすると画面が変わり、APIKEYなどが表示されます。
REQUEST/RESPONSEをクリックするとAPIが表示されるので、それを利用すると予測することができます。
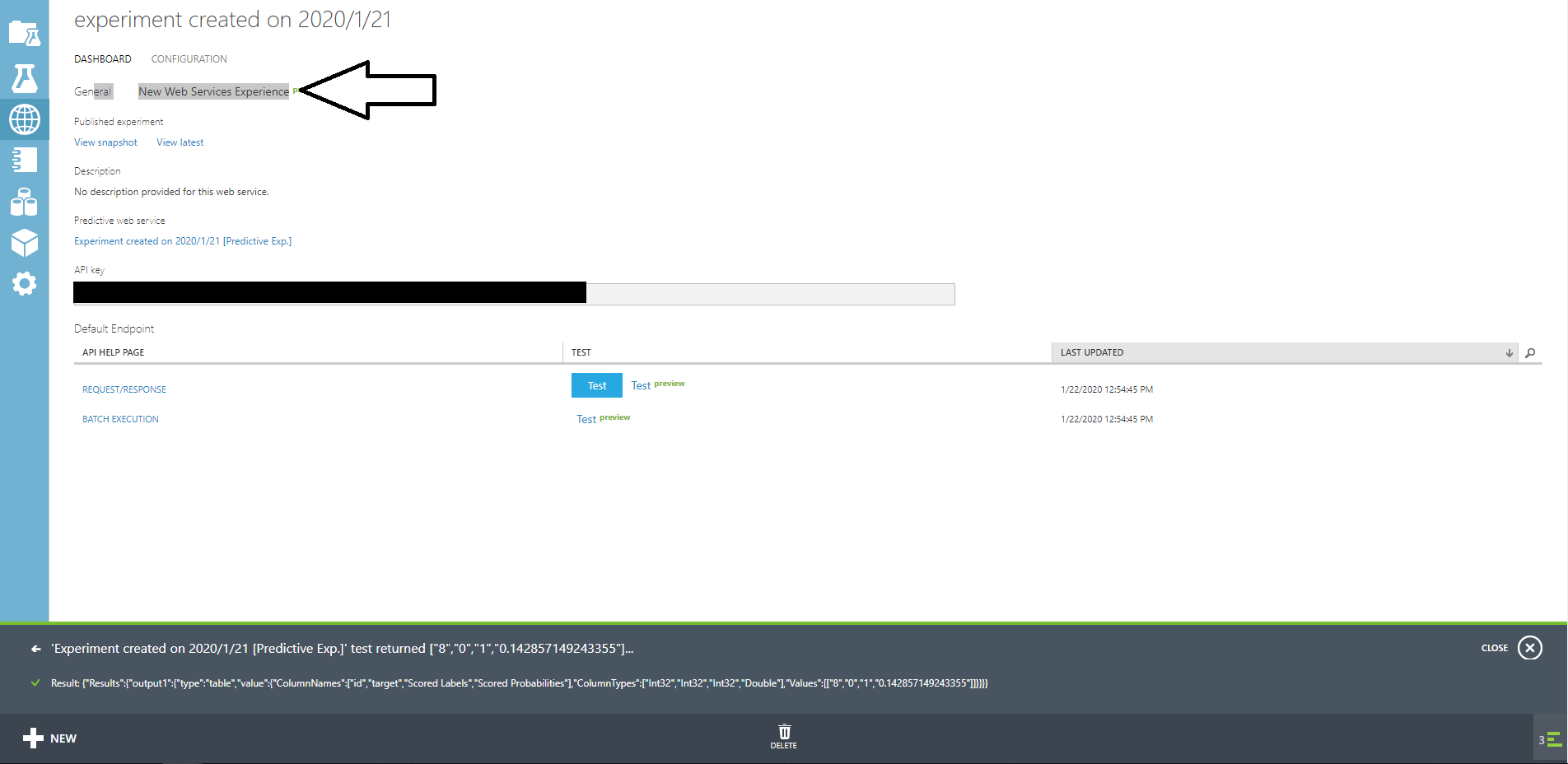
このページで簡単なテストをすることもできます。
じっさにに青色のTESTボタンをクリックしてidに3、targetに1を入れて実験してみましょう。
しばらくするとページ下部に結果が返ってきます。
カラム名、カラムの型、値がリストで返ってきます。
Result: {"Results":{"output1":{"type":"table","value":{"ColumnNames":["id","target","Scored Labels","Scored Probabilities"],"ColumnTypes":["Int32","Int32","Int32","Double"],"Values":[["3","1","1","0.142857149243355"]]}}}}
Scored Labelsが結果なので、この場合は1が返ってきてるので期待通りです。
再学習をデプロイするよ
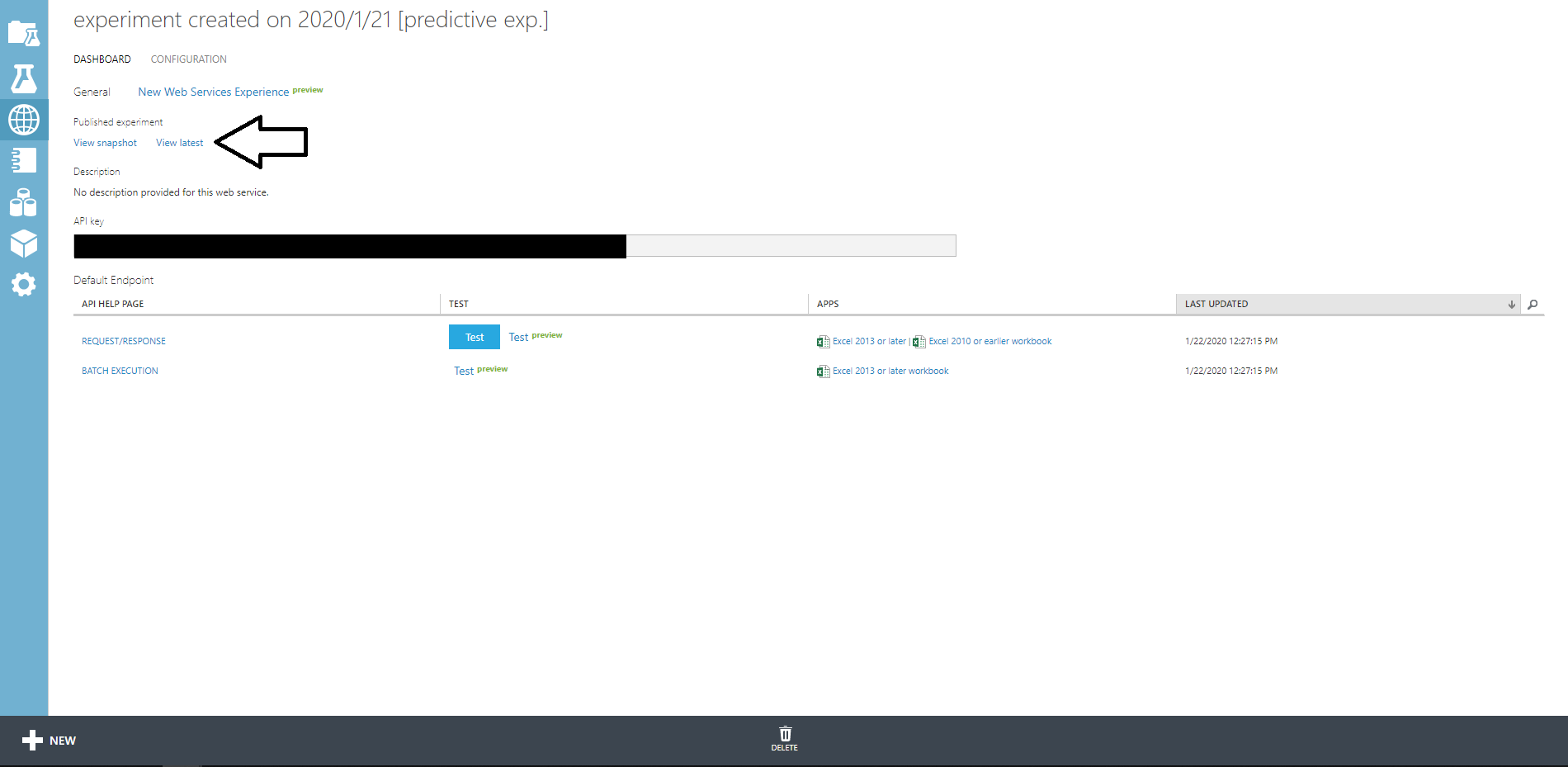
ではView latestをクリックして先ほどの画面に戻りましょう。
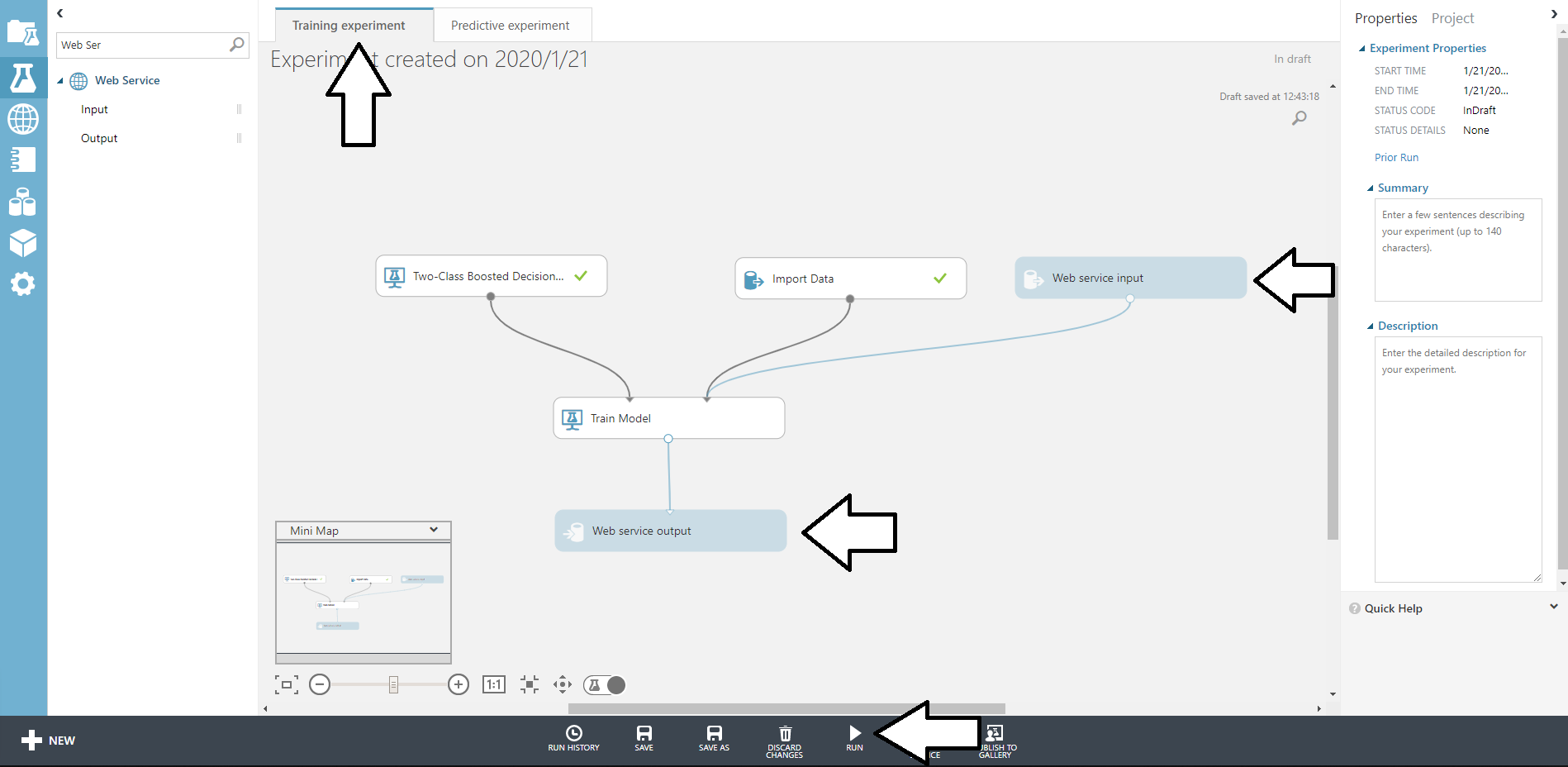
そしたらTraining expeprimentタブに移動して、Web service inputおよびWeb service outputを追加してRUNします。
そしたら下のSET UP WEB SERVICEからDeploy Web Serviceをクリックしましょう。
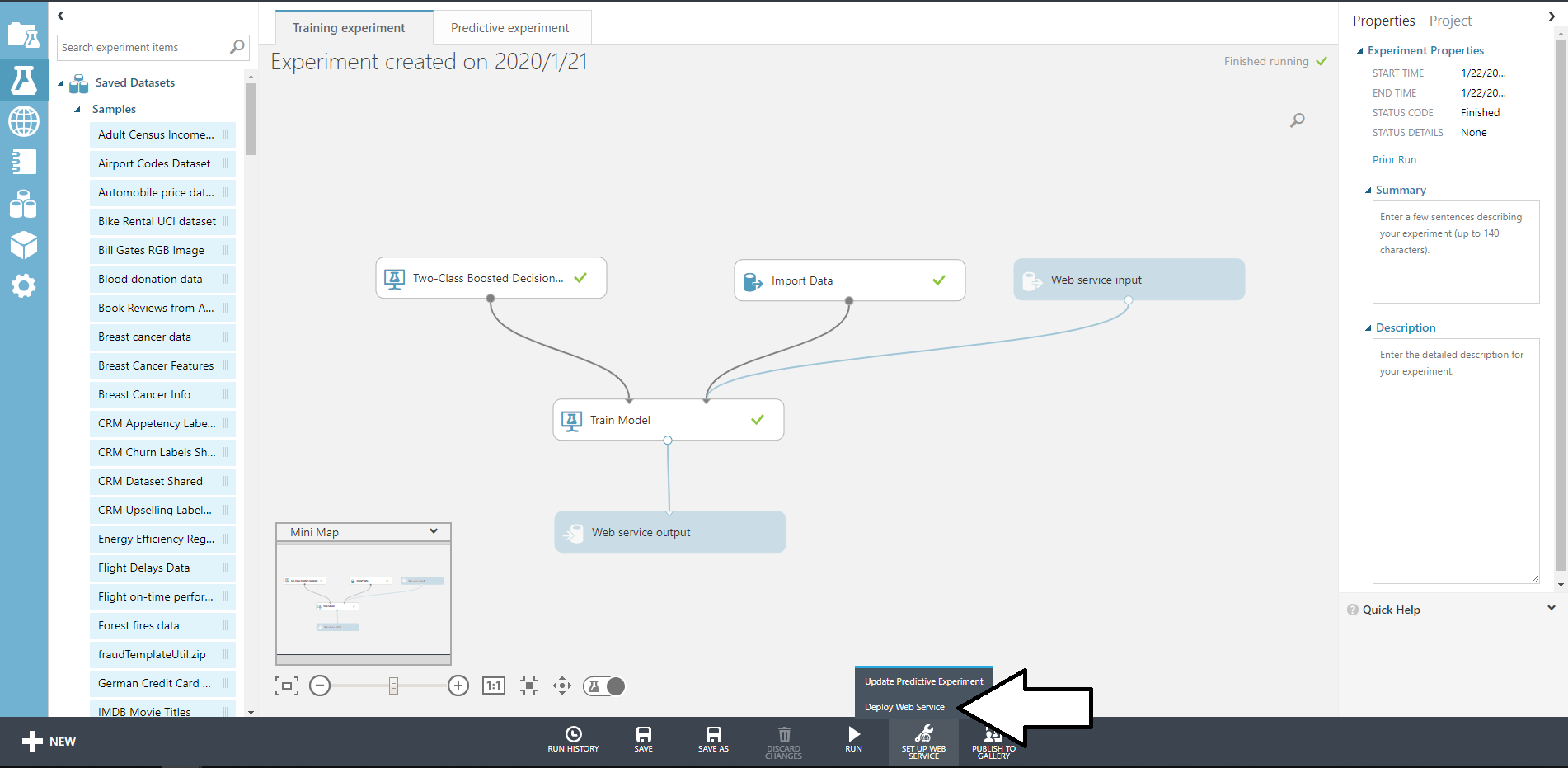
これでデプロイは完了です。
APIKeyとAPIのURLは以降で必要になってきます。
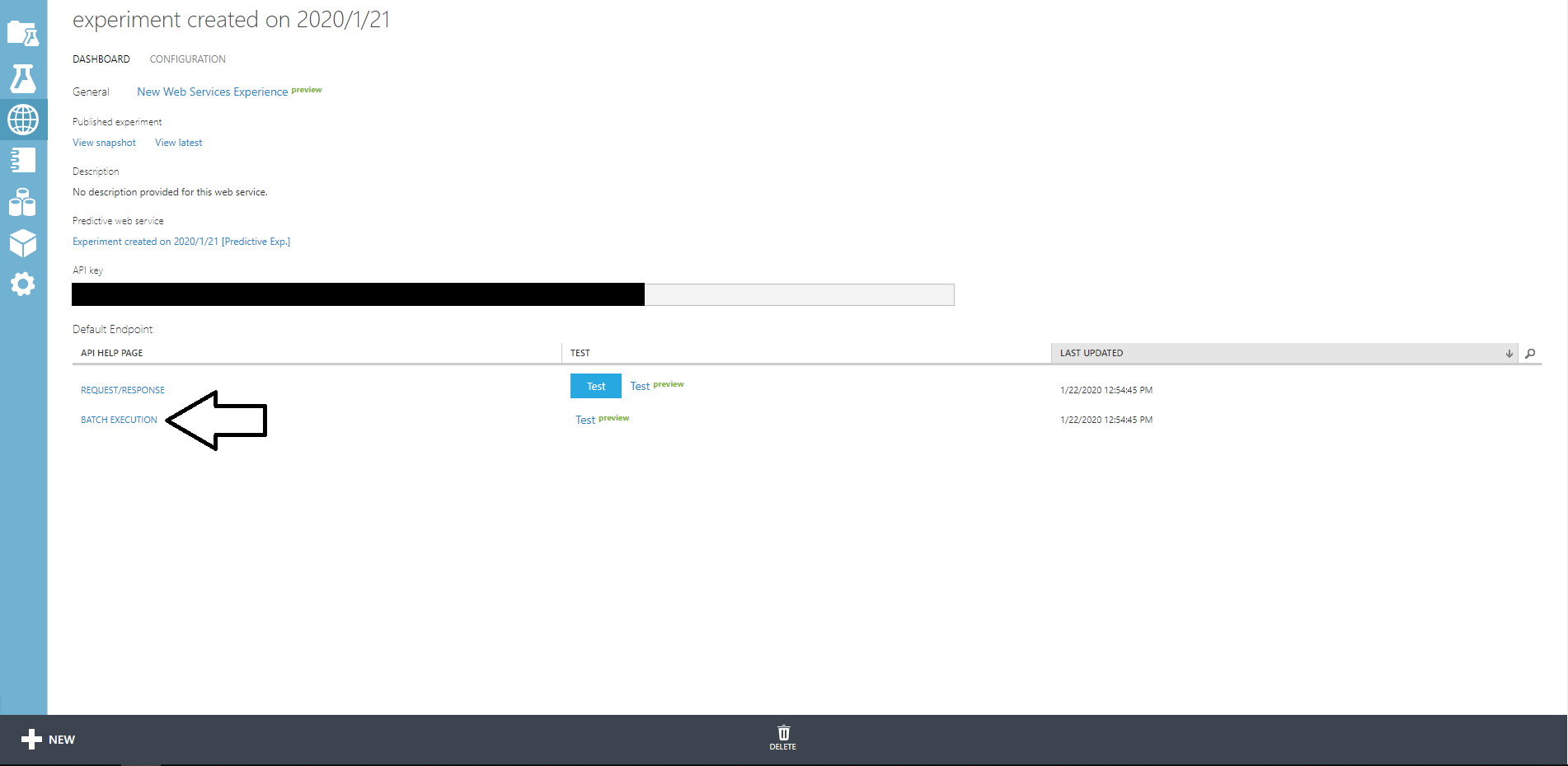
APIKeyは画面に映っているものです。URLはBATCH EXECTIONをクリックすると出てきます。
利用するAPIのURLは?api-version…より前、つまりjobで終わるURLを使います。
私はここでつまずいた。
再学習してみよう!
それでは再学習してみます。
再学習自体はpythonで行いました。C#とかもサンプルであるのですが、ところどころ変えないと動かないかもしれないです。
(python3.7ではそうでした。)
まず、実際に使うプログラムです。
# python 3.7 なのでurllib2を変更
import urllib
import urllib.request
import json
import time
from azure.storage.blob import *
def printHttpError(httpError):
print(f"The request failed with status code: {str(httpError.code)}")
print(json.loads(httpError.read()))
return
def processResults(result):
results = result["Results"]
for outputName in results:
result_blob_location = results[outputName]
sas_token = result_blob_location["SasBlobToken"]
base_url = result_blob_location["BaseLocation"]
relative_url = result_blob_location["RelativeLocation"]
print(f"The results for {outputName} are available at the following Azure Storage location:")
print(f"BaseLocation: {base_url}")
print(f"RelativeLocation: {relative_url}")
print(f"SasBlobToken: {sas_token}")
return
def uploadFileToBlob(input_file, input_blob_name, storage_container_name, storage_account_name, storage_account_key):
#BlobServiceってのがないっぽいので変更
blob_service = BlockBlobService(account_name=storage_account_name, account_key=storage_account_key)
print("Uploading the input to blob storage...")
blob_service.create_blob_from_path(storage_container_name, input_blob_name, input_file)
def invokeBatchExecutionService():
storage_account_name = "blobのユーザー名"
storage_account_key = "blobのキー"
storage_container_name = "blobのコンテナ名"
connection_string = f"DefaultEndpointsProtocol=https;AccountName={storage_account_name};AccountKey={storage_account_key}"
api_key = "再学習のAPIKey"
url = "APIのURL"
uploadFileToBlob("アップロードするファイルパス",
"アップロードした後のファイルパス",
storage_container_name, storage_account_name, storage_account_key)
payload = {
"Inputs": {
"input1": {
"ConnectionString": connection_string,
"RelativeLocation": f"/{storage_container_name}/リモデル対象のblobのファイルパス"
},
},
"Outputs": {
"output1": {
"ConnectionString": connection_string,
"RelativeLocation": f"/{storage_container_name}/リモデル結果のblobのファイルパス.ilearner"
},
},
"GlobalParameters": {
}
}
body = str.encode(json.dumps(payload))
headers = { "Content-Type":"application/json", "Authorization":("Bearer " + api_key)}
print("Submitting the job...")
req = urllib.request.Request(url + "?api-version=2.0", body, headers)
response = urllib.request.urlopen(req)
result = response.read()
job_id = result[1:-1]
# job_idがstrじゃないよって怒られたので変換する
job_id=job_id.decode('utf-8')
print(f"Job ID: {job_id}")
print("Starting the job...")
headers = {"Authorization":("Bearer " + api_key)}
req = urllib.request.Request(f"{url}/{job_id}/start?api-version=2.0", headers=headers, method="POST")
response = urllib.request.urlopen(req)
url2 = url + "/" + job_id + "?api-version=2.0"
while True:
print("Checking the job status...")
req = urllib.request.Request(url2, headers = { "Authorization":("Bearer " + api_key) })
response = urllib.request.urlopen(req)
result = json.loads(response.read())
status = result["StatusCode"]
if (status == 0 or status == "NotStarted"):
print(f"Job: {job_id} not yet started...")
elif (status == 1 or status == "Running"):
print(f"Job: {job_id} running...")
elif (status == 2 or status == "Failed"):
print(f"Job: {job_id} failed!")
print("Error details: " + result["Details"])
break
elif (status == 3 or status == "Cancelled"):
print(f"Job: {job_id} cancelled!")
break
elif (status == 4 or status == "Finished"):
print(f"Job: {job_id} finished!")
processResults(result)
break
time.sleep(1) # wait one second
return
invokeBatchExecutionService()
ほとんどサンプル通りなのですが、一部変更しています。(コメントで書いてます。)
URLやKey、PATHなどは各々の環境に合わせて書き換えてくださいね。
そしたらデータを用意して実行してみましょう。
>python remodel.py
Uploading the input to blob storage...
Submitting the job...
Job ID: ID
Starting the job...
Checking the job status...
JobID not yet started...
Checking the job status...
JobID running...
Checking the job status...
JobID running...
Checking the job status...
JobID running...
Checking the job status...
JobID running...
Checking the job status...
JobID running...
Checking the job status...
JobID running...
Checking the job status...
JobID running...
Checking the job status...
JobID finished!
The results for output1 are available at the following Azure Storage location:
BaseLocation: URL
RelativeLocation: PATH
SasBlobToken: KEY
上記のように結果が返ってくるはずです。
下の三つは以降で利用します。
再学習の反映
さて、リモデルの実行はしましたが、まだ反映はされていません。
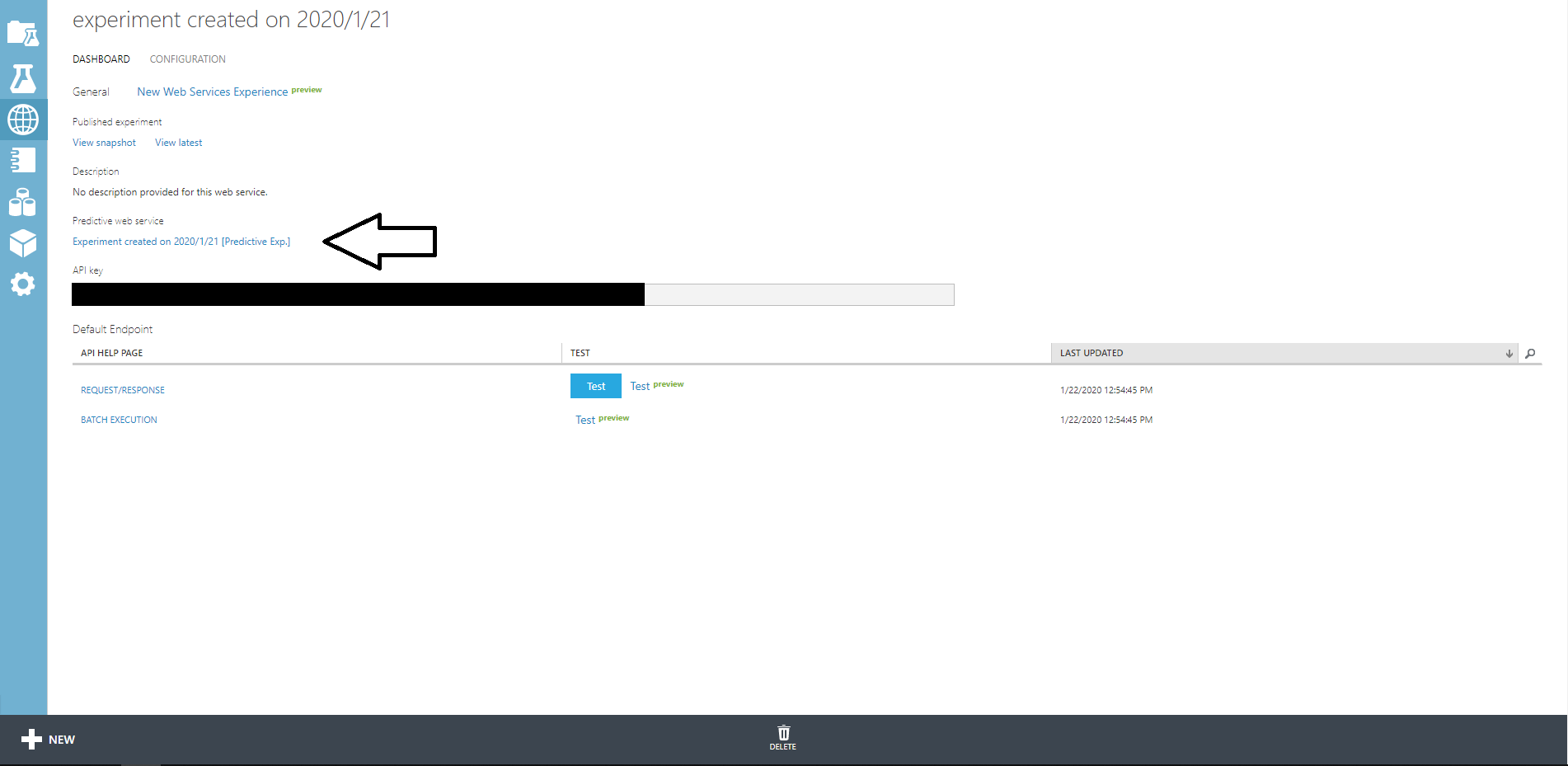
この画面からNew Web Services Experienceを開いてください。
この時ページ上部のモデル名の後ろに[predictive exp.]がついていない場合はExperiment created on … [Predictive Exp.]をクリックして移動しましょう。
既存のものを上書きしてもいいと思いますがたいていは残しておくと思います。
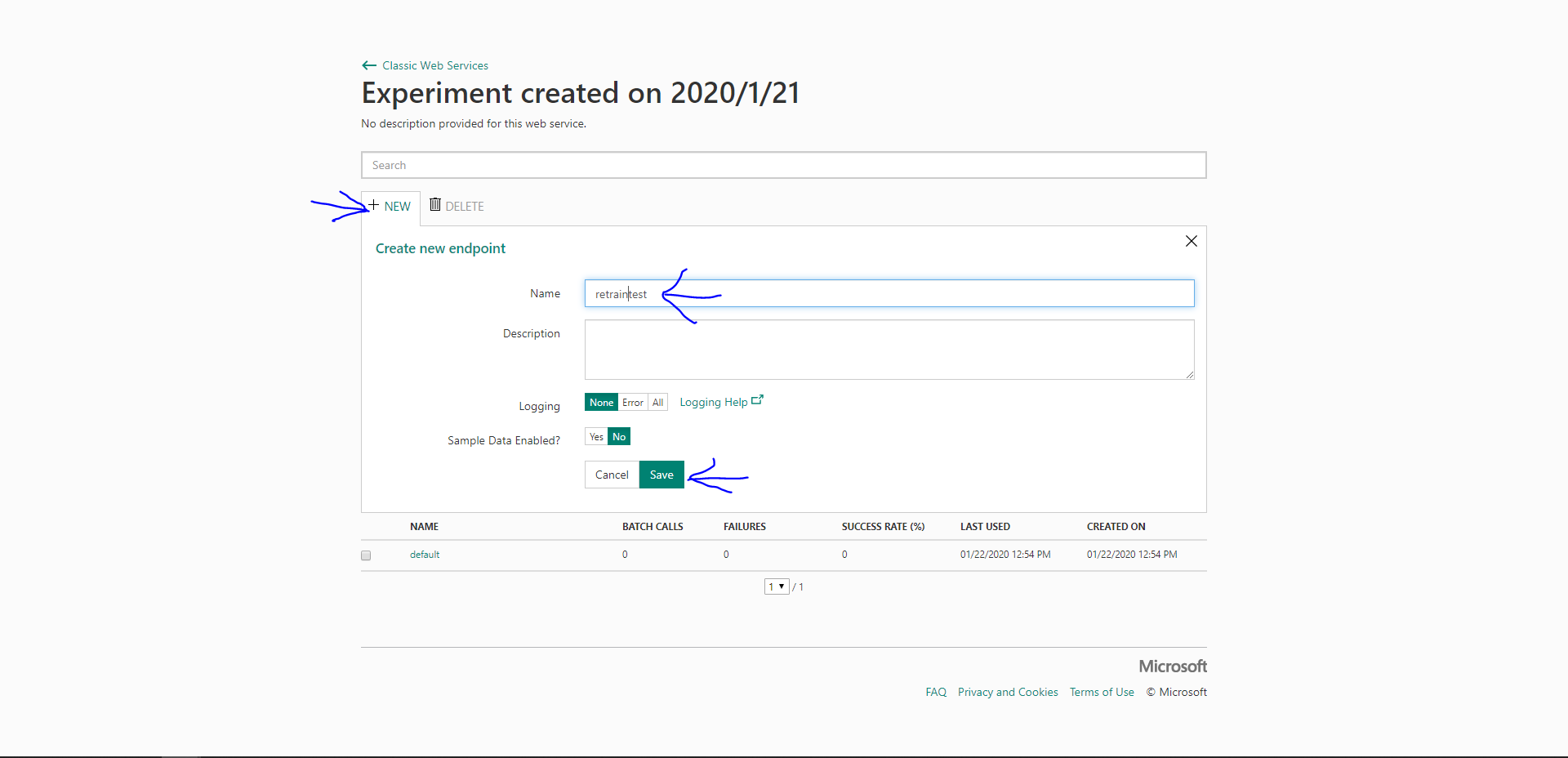
なので新しいエンドポイントを作成します。
この画面から左ボタンを押して…
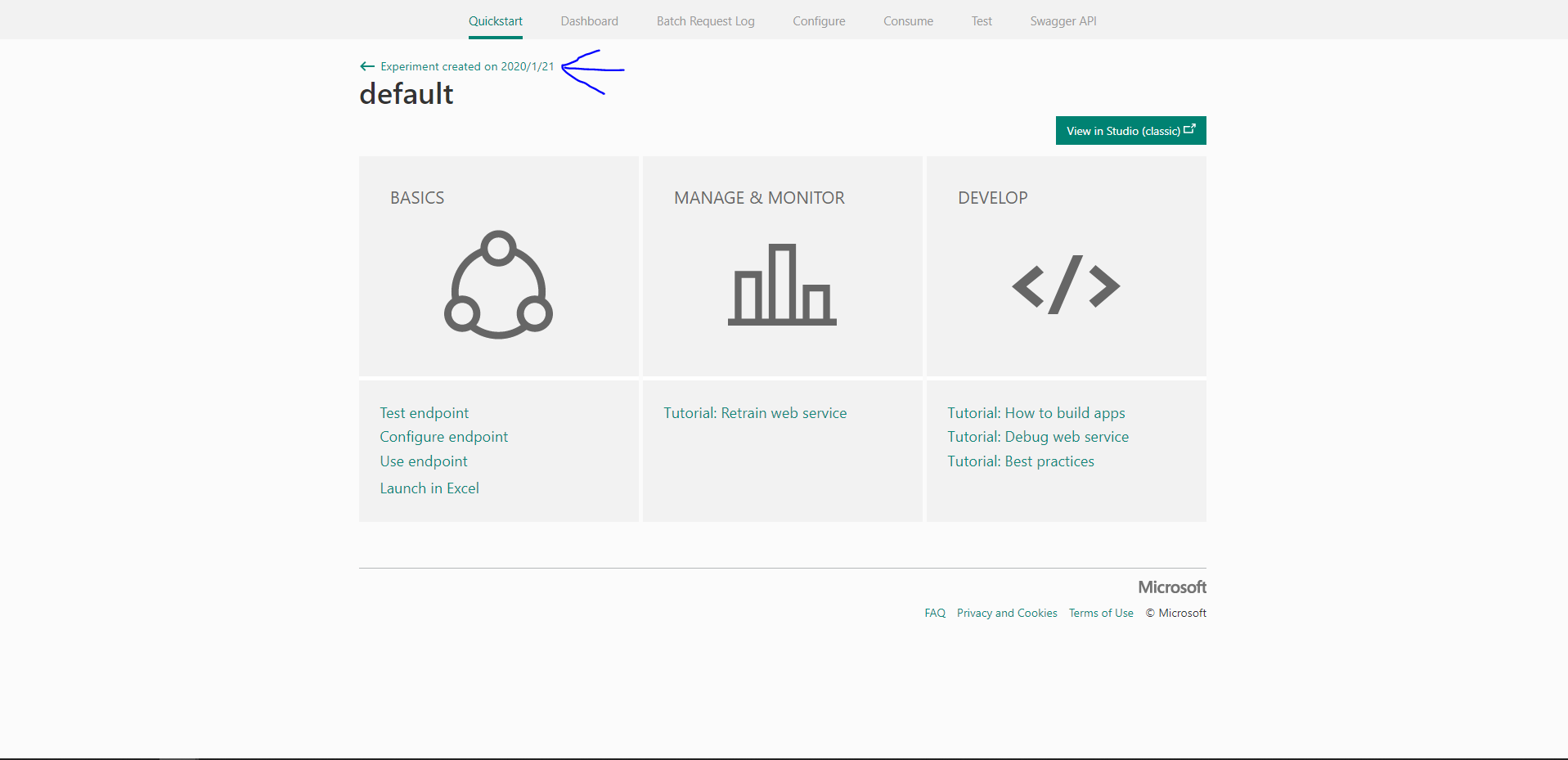
(矢印が雑になったのは気にたら負けです。)
+NEWをクリックしてエンドポイントに利用する名前を付けて保存します。
作成されたエンドポイント名をクリックすると先ほどのような画面に移動するのでConsumeタブを開きましょう。
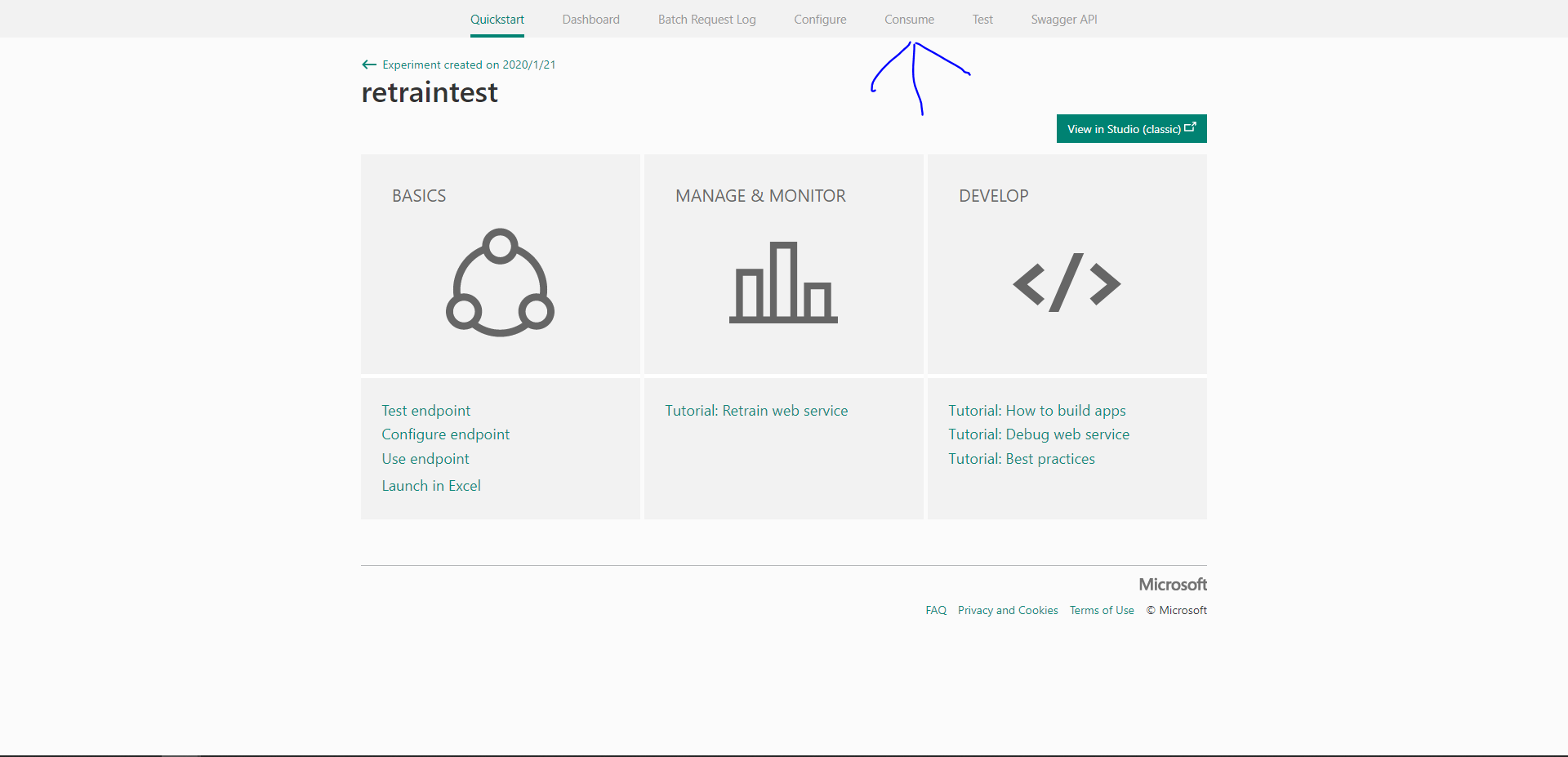
開くといろんなKEYやらURLが出てきます。
今回利用するのはPrimary KeyとPatchです。
これらを使って以下のコードを実行します。
import urllib
import urllib.request
import json
data = {
"Resources": [
{
"Name": "モデルの名前",
"Location":
{
"BaseLocation": "結果のURL",
"RelativeLocation": "結果のPATH",
"SasBlobToken": "結果のKEY"
}
}
]
}
body = str.encode(json.dumps(data))
url = "Patchの値"
api_key = "PrimaryKeyの値" # Replace this with the API key for the web service
headers = {'Content-Type':'application/json', 'Authorization':('Bearer '+ api_key)}
req = urllib.request.Request(url, body, headers)
req.get_method = lambda: 'PATCH'
response = urllib.request.urlopen(req)
result = response.read()
print(result)
こんな感じです。
先ほどのページのPatchの下にあるAPIhelpを開くとサンプルがあるので、大体はその通りに書くといいと思います。
では、実行してみましょう。
b''が返ってきます。
なるほど?
でもこれでいいみたいです。
最後にこれをデプロイします。
デプロイ手順は
再学習できたかな?
ページ上部のTestタブを開いてテストしてみましょう。
もしかするとリロードが必要かもしれないです。
id=3,target=1です。
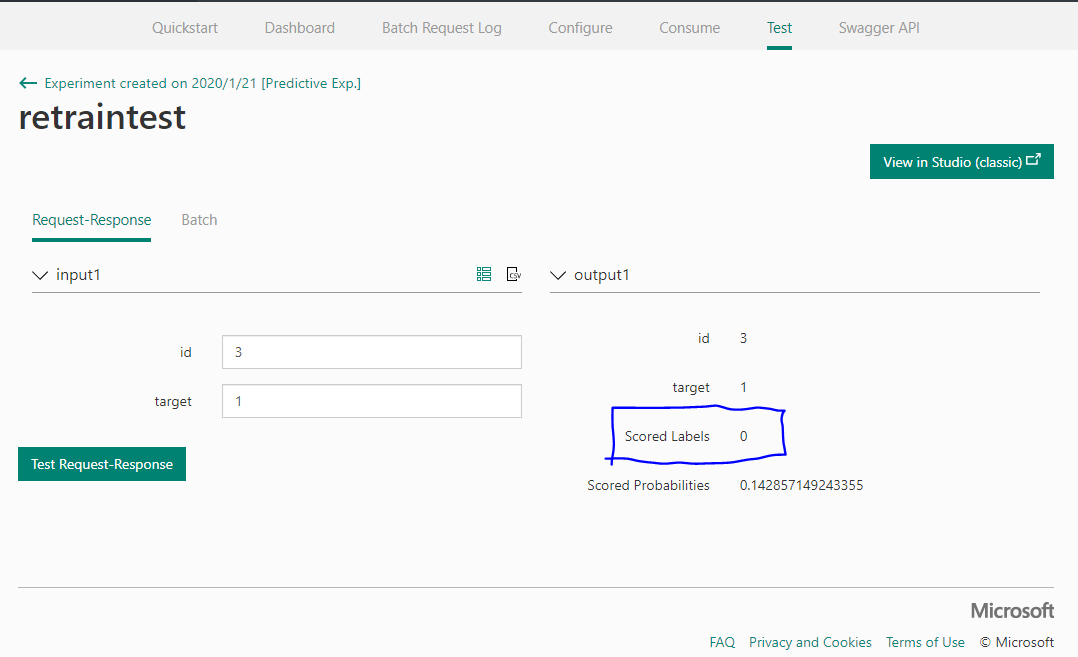
ちゃんと0になってるみたいです。
よかった…
まとめ
どうにか再学習したモデルをデプロイすることができました。
皆さんも利用しているモデルの精度が下がってきたかな?と思ったら、再学習して、モデルを継続利用しましょう!