序
全文検索やログ管理で使われるElasticSearch(以下、ES)には、http経由で主にJSONを用いてアクセスする。
ここでは、覚えやすく、可読性が高く実用的なhttpクライアントであるhttpieを用いて、人気の入門チュートリアル「はじめてのElasticsearch」をなぞらせていただく。
付記① : ESクライアントの主な選択肢:
- Kibana
- Elastic社が提供するES向け公式クライアント(ブラウザベース)
- コマンドライン向けのhttp クライアントツール
- curl : 言わずとしれたhttpクライアント
- httpie : curlより簡潔な記述ができるhttpクライアント
- 各言語向けライブラリ
-
公式クライアント
- Java/.NET/php/ruby/perl/python/groovy
-
コミュニティ提供クライアント
- 様々な言語向けに提供されている。
-
公式クライアント
統計機能などさまざまな機能を持つKibanaは、第一選択肢だろう。ただし、ブラウザを介するがゆえのもっさり感はある。他方、各言語向けのライブラリは、プロジェクトによって使用言語が変わりうること情報が言語別に分散してしまうことから、普段使いのESクライアントからは外しておいた方が無難(もちろん、例えば、ESをpyhton経由でしか使わないといった決めがある場合には、python経由でESにアクセスすることを原則にしても良いだろうけど)。
付記② : Elasticsearch(ES)の導入
「はじめてのElasticsearch」では、brewでのインストール方法が紹介されている。ここでは、dockerを用いて、ESを導入する。
公式に従いローカルでESを走らせるのは、dockerの場合2行だけ。
docker pull docker.elastic.co/elasticsearch/elasticsearch:6.6.1
docker run -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" docker.elastic.co/elasticsearch/elasticsearch:6.6.1
これで、ディフォルトの9200番ポートでelasticsearchが立ち上がる。
付記③ : httpie
Pythonベースのhttpクライアントであるhttpieは、brewやpipで簡単に導入できる。コマンドラインからJSONを発行しやすいhttpieは、elsaticsearchとの相性がとても良いのだ。
webにまとまった情報が転がっていないので、ここでローカルでのお試し記録を書いておこうかと。
httpie経由でElasticsearchにアクセスする利点
①curlよりも簡潔に書け、応答が見やすい。
httpクライアントhttpieでのgetは簡単だ。
http localhost:9200
同じくhttpクライアントのcurlでは以下のように書くのがお作法。
curl -XGET 'localhost:9200/?pretty'
「?pretty」は、ESに人に見やすいようレスポンスを返すお願い(オプション)なのだけれど、イケてるhttpクライアントであるhttpieではhttpクライアント側でよしなに体裁を整えてくれる。
こんな感じ:
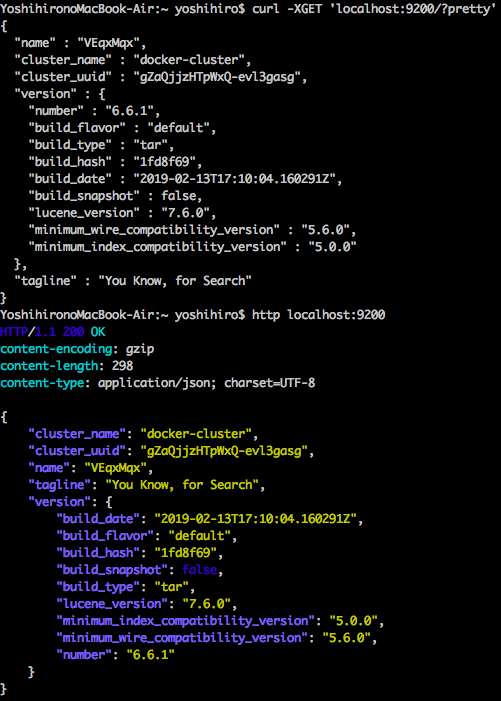
どちらがprettyかはさておき、見やすいのはhttpieのほうだろう。httpレスポンスなどの情報もきちんと表示される。
② JSONを投げるのが簡単
さて、ESへの一般的なアクセス手段、JSONだ。
httpieでは、ヒアストリング<<<を使用して、JSONなどの文字列を投げることができる。
ESへの全件検索は以下のように書く。
http GET localhost:9200/_search <<< '
{
"query": {
"match_all": {}
}
}'
ESを起動した直後では、何もありませんよ、との応答となる。
HTTP/1.1 200 OK
content-encoding: gzip
content-length: 119
content-type: application/json; charset=UTF-8
{
"_shards": {
"failed": 0,
"skipped": 0,
"successful": 0,
"total": 0
},
"hits": {
"hits": [],
"max_score": 0.0,
"total": 0
},
"timed_out": false,
"took": 0
}
httpieで、CRUDオペレーション
以下、入門チュートリアル「はじめてのElasticsearch」の、Kibana経由でのCRUDオペレーション(RESTful API)の前半部をなぞっていくので、ESがはじめての方は、適宜参照のほどを。
IDを指定したドキュメント作成(PUT)
# +--- Index name
# | +--- Type name
# | | +--- Document ID
# | | |
# V V V
http PUT localhost:9200/library/books/1 <<< '
{
"title": "ノルウェイの森",
"name": {
"first": "Haruki",
"last": "Murakami"
},
"publish_date": "1987-09-04T00:00:00+0900",
"price": 19.95
}'
実行結果
HTTP/1.1 201 Created
Location: /library/books/1
Warning: 299 Elasticsearch-6.6.1-1fd8f69 "the default number of shards will change from [5] to [1] in 7.0.0; if you wish to continue using the default of [5] shards, you must manage this on the create index request or with an index template" "Sun, 24 Feb 2019 09:26:10 GMT"
content-encoding: gzip
content-length: 143
content-type: application/json; charset=UTF-8
{
"_id": "1",
"_index": "library",
"_primary_term": 1,
"_seq_no": 0,
"_shards": {
"failed": 0,
"successful": 1,
"total": 2
},
"_type": "books",
"_version": 1,
"result": "created"
}
IDを指定したドキュメントの取得(GET)
以下の通り。
$ http GET localhost:9200/library/books/1
HTTP/1.1 200 OK
content-encoding: gzip
content-length: 241
content-type: application/json; charset=UTF-8
{
"_id": "1",
"_index": "library",
"_primary_term": 1,
"_seq_no": 0,
"_source": {
"name": {
"first": "Haruki",
"last": "Murakami"
},
"price": 19.95,
"publish_date": "1987-09-04T00:00:00+0900",
"title": "ノルウェイの森"
},
"_type": "books",
"_version": 1,
"found": true
}
ドキュメントIDを指定しないドキュメント作成(POST)
http POST localhost:9200/library/books/ <<< '
{
"title": "海辺のカフカ",
"name": {
"first": "Haruki",
"last": "Murakami"
},
"publish_date": "2002-09-12T00:00:00+0900",
"price": 19.95
}'
実行結果
HTTP/1.1 201 Created
Location: /library/books/RK_ZHmkBlnRFkn__2WSn
content-encoding: gzip
content-length: 165
content-type: application/json; charset=UTF-8
{
"_id": "RK_ZHmkBlnRFkn__2WSn",
"_index": "library",
"_primary_term": 1,
"_seq_no": 1,
"_shards": {
"failed": 0,
"successful": 1,
"total": 2
},
"_type": "books",
"_version": 1,
"result": "created"
}
ドキュメントの部分的な更新(POST)
http POST localhost:9200/library/books/1/_update <<< '
{
"doc": {
"price": "壱万円"
}
}'
実行結果
HTTP/1.1 400 Bad Request
content-encoding: gzip
content-length: 197
content-type: application/json; charset=UTF-8
{
"error": {
"caused_by": {
"reason": "For input string: \"壱万円\"",
"type": "number_format_exception"
},
"reason": "failed to parse field [price] of type [float]",
"root_cause": [
{
"reason": "failed to parse field [price] of type [float]",
"type": "mapper_parsing_exception"
}
],
"type": "mapper_parsing_exception"
},
"status": 400
}
おっと、インデックスタイプなどを指定していないのだが、エラーがでてしまった(...わざとらしい)。正しいpriceの書き方は皆さんにお任せ。
それでは、と、ドキュメントに新たな項目を追加してみる。
http POST localhost:9200/library/books/1/_update <<< '
{
"doc": {
"price_jpy": "壱万円"
}
}'
実行結果。今度はうまく行った。項目追加の際は型が自由なんだね。
HTTP/1.1 200 OK
content-encoding: gzip
content-length: 142
content-type: application/json; charset=UTF-8
{
"_id": "1",
"_index": "library",
"_primary_term": 1,
"_seq_no": 1,
"_shards": {
"failed": 0,
"successful": 1,
"total": 2
},
"_type": "books",
"_version": 2,
"result": "updated"
}
ドキュメントの削除(DELETE)
さよなら、「ノルウェイの森」。
$ http DELETE localhost:9200/library/books/1
HTTP/1.1 200 OK
content-encoding: gzip
content-length: 144
content-type: application/json; charset=UTF-8
{
"_id": "1",
"_index": "library",
"_primary_term": 1,
"_seq_no": 2,
"_shards": {
"failed": 0,
"successful": 1,
"total": 2
},
"_type": "books",
"_version": 3,
"result": "deleted"
}
次いで、libralyインデックスも削除。
$ http DELETE localhost:9200/library
HTTP/1.1 200 OK
content-encoding: gzip
content-length: 47
content-type: application/json; charset=UTF-8
{
"acknowledged": true
}
httpieで、bulkインサートや検索など。
bulkインサート
文書を5件挿入するbulkインサートを行う。
http POST localhost:9200/library/books/_bulk <<< '
{"index": {"_id": 1}}
{"title": "The quick brown fox", "price": 5}
{"index": {"_id": 2}}
{"title": "The quick brown fox jumps over the lazy dog", "price": 15}
{"index": {"_id": 3}}
{"title": "The quick brown fox jumps over the quick dog", "price": 8}
{"index": {"_id": 4}}
{"title": "Brown fox and brown dog", "price": 2}
{"index": {"_id": 5}}
{"title": "Lazy dog", "price": 9}
'
bulkインサートで用いられるは、JSONではないことに注意。ES向けhttpクライアントの中には、bulkインサートを不得意とするものもあるのだが、httpieはただの文字列を投入しているだけだからお構いなし。httpieをうまく使えば、ESに多量の文書を投入するシェル芸ができそうだ。
全件取得(GET _search)
以下、localhostは省略する。
結果の方は長くなっちゃうね。
$ http GET :9200/library/books/_search
HTTP/1.1 200 OK
content-encoding: gzip
content-length: 274
content-type: application/json; charset=UTF-8
{
"_shards": {
"failed": 0,
"skipped": 0,
"successful": 5,
"total": 5
},
"hits": {
"hits": [
{
"_id": "5",
"_index": "library",
"_score": 1.0,
"_source": {
"price": 9,
"title": "Lazy dog"
},
"_type": "books"
},
{
"_id": "2",
"_index": "library",
"_score": 1.0,
"_source": {
"price": 15,
"title": "The quick brown fox jumps over the lazy dog"
},
"_type": "books"
},
{
"_id": "4",
"_index": "library",
"_score": 1.0,
"_source": {
"price": 2,
"title": "Brown fox and brown dog"
},
"_type": "books"
},
{
"_id": "1",
"_index": "library",
"_score": 1.0,
"_source": {
"price": 5,
"title": "The quick brown fox"
},
"_type": "books"
},
{
"_id": "3",
"_index": "library",
"_score": 1.0,
"_source": {
"price": 8,
"title": "The quick brown fox jumps over the quick dog"
},
"_type": "books"
}
],
"max_score": 1.0,
"total": 5
},
"timed_out": false,
"took": 77
}
OR検索
クエリ。GETも省略。
$ http :9200/library/books/_search <<<'
{
"query": {
"match": {
"title": "lazy jumps"
}
}
}
'
実行結果
HTTP/1.1 200 OK
content-encoding: gzip
content-length: 264
content-type: application/json; charset=UTF-8
{
"_shards": {
"failed": 0,
"skipped": 0,
"successful": 5,
"total": 5
},
"hits": {
"hits": [
{
"_id": "2",
"_index": "library",
"_score": 1.241217,
"_source": {
"price": 15,
"title": "The quick brown fox jumps over the lazy dog"
},
"_type": "books"
},
{
"_id": "5",
"_index": "library",
"_score": 0.2876821,
"_source": {
"price": 9,
"title": "Lazy dog"
},
"_type": "books"
},
{
"_id": "3",
"_index": "library",
"_score": 0.2876821,
"_source": {
"price": 8,
"title": "The quick brown fox jumps over the quick dog"
},
"_type": "books"
}
],
"max_score": 1.241217,
"total": 3
},
"timed_out": false,
"took": 13
}
lazyでクエリかけるとLazyもヒットする。
Elasticsearchを相手にする時のhttpieの使い方がだいたいわかったかなと思うのでこのあたりまで。