目次
1. 概要
2. 背景と課題
3. 課題の構造化
4. 解決方針
5. 独自モデルを構築した理由
6. 技術選定
7. データと前処理
8. モデル設計
9. 学習と評価
10. 結果と効果
11. 振り返り
概要
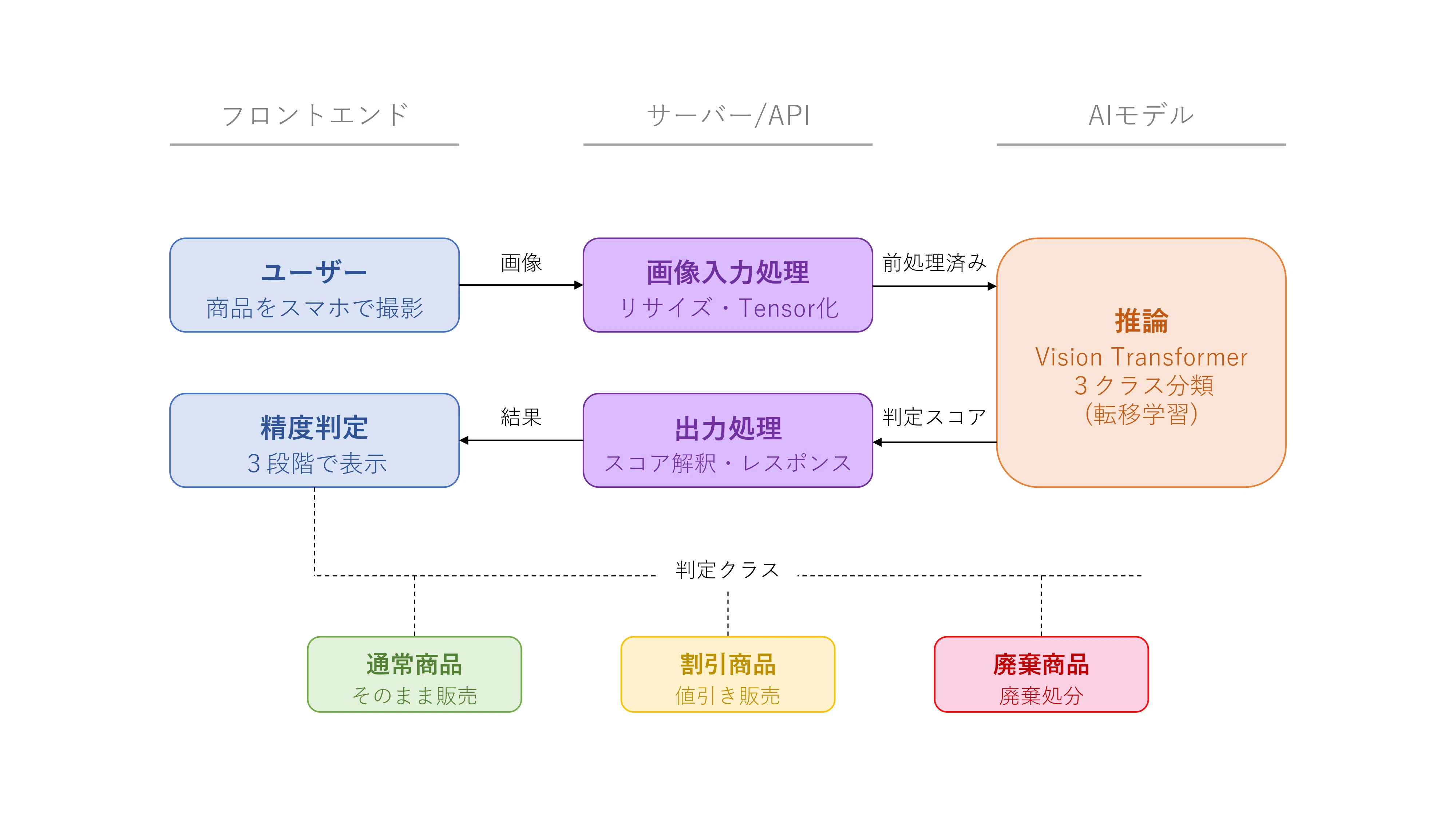
本プロジェクトでは、スーパーにおける青果商品の品質判断を支援するために、商品をスマホで撮影するだけで「通常商品・割引商品・廃棄商品」を分類するWebアプリを開発しました。
従来、従業員の主観に依存していた品質判断を、画像処理を用いることで標準化し、実際の店舗導入を通じて業務改善を実現しました。
また、本プロジェクトでは要件整理から設計、開発、導入まで一貫して担当し、実際の店舗への導入まで至りました。
背景と課題
私が学生の頃に勤務していたスーパーでは、野菜や果物といった消費期限の記載がない商品について、「割引商品とするか」「廃棄商品とするか」の明確な基準が存在していませんでした。
その結果、以下のような問題を抱えていました。
- 判断の属人化:「まだ売れる」か「廃棄する」かの基準が従業員ごとに異なる
- 現場の不和:判断の違いによる従業員間のトラブル
- 教育コスト:新人スタッフが基準を習得するまでに多大な時間を要する
このように、現場のオペレーションにおいて 「判断の標準化」が重要な課題となっていました。
課題の構造化
課題を分析した結果、問題は「個人の感覚」という暗黙知が共有されていない点にあると整理しました。
- 表面的な問題:判断のバラつき、作業効率の低下
- 根本的な問題:視覚情報を客観的な数値や基準に落とし込む仕組みの欠如
つまり、「見た目」という曖昧な情報を客観的に評価できていないことが本質的な問題であると考えました。
このため、画像情報をもとに客観的な判断を行う仕組みの構築が必要であると結論づけました。
解決方針
課題解決にあたり、以下のアプローチを比較検討しました。
- マニュアル整備
→ 判断基準の形式化は可能だが、例外対応が難しい - 教育の強化
→ 属人性が残り、スケーラビリティに欠ける - AIによる画像判定
→ 判断の標準化・自動化が可能
これらを踏まえ、本プロジェクトではAIによる画像分類を採用しました。
これにより、属人性を排除し、誰でも同じ基準で判断できる仕組みの実現を目指しました。
独自モデルを構築した理由
本プロジェクトでは、外部APIや汎用的なモデルではなく、独自の画像分類モデルを構築しました。
その理由は以下の通りです。
まず、本タスクは「青果の状態判定」という特定ドメインに依存しており、一般的な画像認識モデルでは十分な精度を得られない可能性がありました。
そのため、実際の店舗データを用いた最適化が必要であると判断しました。
また、実際の運用を前提とした場合、外部APIの利用はコストやレスポンスの観点で制約となります。
特に店舗での利用では、低コストかつ高速に動作するシステムが求められます。
さらに、本アプリケーションでは現場での納得感も重要です。
複雑なブラックボックスモデルではなく、比較的構造が理解しやすいモデルを採用することで、判断結果への信頼性向上を図りました。
これらの理由から、独自モデルの構築を選択しました。
技術選定
PyTorchを採用した理由
深層学習フレームワークにはPyTorchを採用しました。
主な理由は以下の通りです。
- モデル構造の記述が柔軟で、複雑な構成にも対応可能
- 損失関数や最適化アルゴリズムが豊富
- 実装がシンプルでデバッグしやすく、開発効率が高い
FastAPIを採用した理由
Web APIの構築にはFastAPIを採用しました。
- 軽量で高速なAPI構築が可能
- Pythonとの親和性が高く、機械学習モデルとの統合が容易
- 非同期処理に対応しており、推論APIとして適している
データと前処理
本プロジェクトでは、実際に店舗の売り場に並んでいた青果商品を撮影し、独自にデータセットを構築しました。
通常商品・割引商品・廃棄商品の3クラスに対し、各50枚(計150枚)という小規模なデータからスタートしたため、以下のアプローチを取りました。
正解データの信頼性担保
モデルの精度を左右するのはデータの質です。
開発者が独断でラベル付け(アノテーション)を行うと、現場の実態と乖離するリスクがありました。
そこで、店舗責任者である店長立ち会いのもと、1枚ずつ画像を確認しながら分類を実施しました。
これにより、現場の運用ルールに基づいた「正解」を定義し、アプリの判断基準に対する信頼性を根本から担保しました。
データ拡張による汎化性能の向上
限られたデータ数でモデルを堅牢にするため、以下の手法でデータセットを疑似的に拡張しました。
- 水平反転・回転:商品の置かれ方や撮影角度に左右されない識別能力を付与
- 色調変化:店舗内の照明条件や撮影端末による色の見え方の違いをカバー
技術的な前処理プロセス
モデルへの入力前に、計算効率と学習効率を最適化する処理を組み込みました。
- リサイズ(224×224 px):特徴量を維持しつつ、計算コストを最小限に抑制
- Tensorへの変換:PyTorchでのGPU計算および勾配計算に最適化
- 正規化:事前学習済みモデルの統計量に合わせて入力データの分布を調整することで、学習の収束を早めました
モデル設計
モデルには、事前学習済みのVision Transformer(ViT)を採用しました。
- 既存の重みを活用し、特徴抽出部分は固定
- 最終層のみを3クラス分類用に再構築
- 転移学習により少量データでも高精度化を図る
この設計により、限られたデータ環境でも効率的に学習を行うことができました。
学習と評価
学習は15エポックで実施しました。
訓練損失・検証損失ともに収束傾向が確認され、モデルが適切に学習できていることを確認しました。
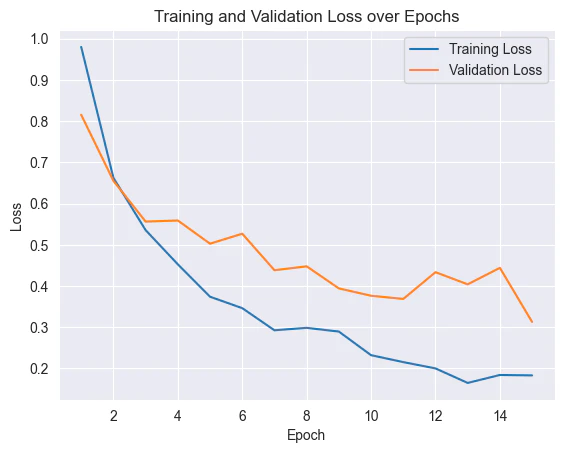
最終的な評価結果は以下の通りです。
テストデータにおける分類精度:約93.3%
一部のエポックでは検証損失の増加も見られたため、軽微な過学習の兆候があると考えられますが、全体としては実用に耐えうる精度を達成しました。
結果と効果
開発したWebアプリを実際に店舗に試験導入した結果、以下の効果を確認できました。
- トラブルの解消:「AIによる判定」という客観的な根拠ができたことで、スタッフ間の主観による衝突がなくなりました
- 作業時間の短縮:判別に迷う時間が削減され、特に新人スタッフの作業がスムーズになりました
- 店舗への貢献:現場の課題をAIで解決し、実際の業務フローの一部として認められました
振り返り
本プロジェクトを通じて、単に「コードを書く」だけでなく、現場の声を聞き「何を解決すべきか」を定義する重要性を学びました。
今後は、季節による野菜の見た目の変化への対応や、他カテゴリの商品への横展開など、より広範なデータドリブンな改善に取り組んでいきたいと考えています。