はじめに
前回、ローカルLLMでのマルチエージェント構築に向けた検討メモを書きましたが、今回はその第一歩として、実際に手を動かして Gemma 2 2B をローカルで動かすところまでをやってみました。
ただし今回の記事はゲーミングPCではなく、低スペックPC(GPUなし・CPUのみ・RAM 8GB) という、かなり制約のある環境での挑戦です。理由は単純で、「制約の厳しい環境でどこまでできるかを練習してみたかった」からです。将来的には複数の特化ローカルAIをオーケストレーターが束ねる構成を考えていますが、今回はその前段階、Gemmaを動かす・触ってみるところに焦点を当てた記録です。
同じように非力な環境で試そうとしている人の参考になればと思い、つまずいたポイントやセキュリティ面の確認も含めて残しておきます。
構築はゲーミングPCで行っています。
想定で作っています。

検証環境
GPUがない・メモリも8GBしかない、という環境なので、今回は ファインチューニングは選択肢から除外し、後続のステップでは LoRA を使った軽量な学習方式を採用する前提で進めています。
| 項目 | スペック |
|---|---|
| OS | Windows 11 |
| CPU | 指定なし(GPUは使わずCPUのみで実行) |
| GPU | なし(今回は意図的に不使用) |
| メモリ | 8GB |
| Python | venvによる仮想環境 |
構築手順
■ Step 1: Hugging Face アカウント登録・トークン発行
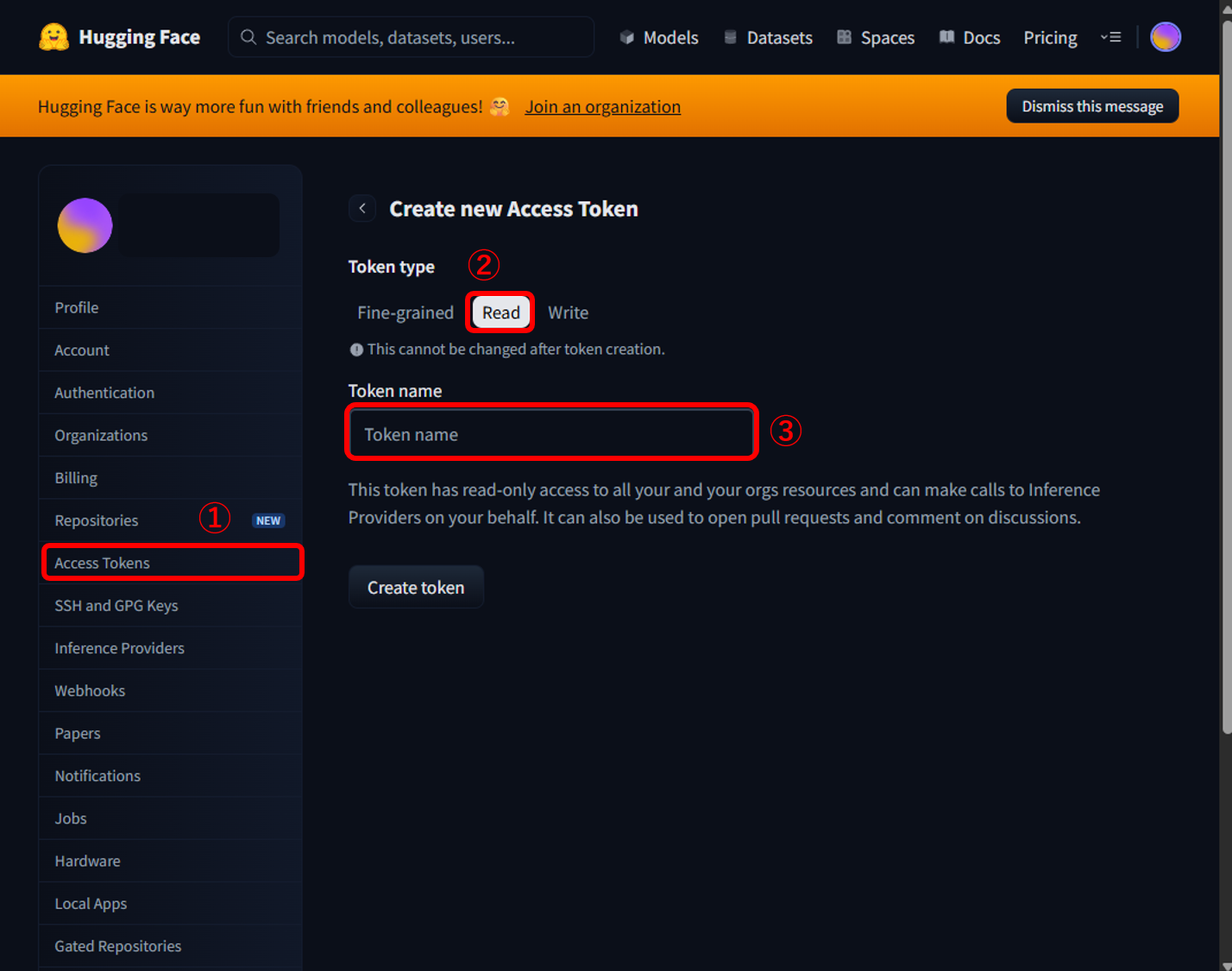
まずは Hugging Face でアカウントを作成し、Settings → Access Tokens(①) から read権限のトークン(②)を発行しました。Token nameはHugging Face上で管理する際の名前になるので、任意の名前を付けました(③)。
今回はモデルのダウンロード・読み込みのみを行うので、書き込み権限は不要です。read権限のみで十分でした。
■ Step 2: Python仮想環境(venv)の作成・パッケージインストール
プロジェクトを作る任意のフォルダを作成&移動して、フォルダ直下に venv という名前で仮想環境を作成&有効化します。
python -m venv venv
.\venv\Scripts\activate
CPUオンリー環境なので、torchはCPU版を明示的に指定してインストールします。
※ CUDA関連の不要な巨大ファイルを避けるため
pip install torch --index-url https://download.pytorch.org/whl/cpu
pip install transformers accelerate peft datasets huggingface_hub sentencepiece protobuf
| パッケージ | 役割 |
|---|---|
| torch | 学習・推論エンジン本体(CPU版) |
| transformers | Gemma 2 の読み込み・推論 |
| accelerate | デバイス管理・メモリ最適化 |
| peft | LoRAによる軽量ファインチューニング(次回使用予定) |
| datasets | 学習データの読み込み・前処理(次回使用予定) |
| huggingface_hub | HFログイン・モデルダウンロード |
| sentencepiece / protobuf | Gemmaのトークナイザーに必要 |
■ Step 3: Hugging Face CLIでのログイン認証
Hugging Faceに対してログイン認証をします。イメージは、GitのSSH接続みたいな感じです。この手順を踏まないとモデルをダウンロードできないみたいです。
hf auth login
ログイン方法を選択するプロンプトが出るので、「Paste an access token」を下ボタン&Enterで選択し、発行したread権限のhugging faceのトークンをコピペ貼り付けで認証。
(venv) $ hf auth login
? How would you like to log in? [Use arrows, Enter to confirm]
Log in with your browser
> Paste an access token
(venv) $ hf auth login
? How would you like to log in? Paste an access token
Enter your token (input will not be visible):
Token is valid (permission: read).
Login successful.
Hugging Faceのログイン認証に関しての余談
以前は huggingface-cli login というコマンドでしたが、現在は非推奨になっており、hf コマンドに統合されていました。
Hugging Faceのログイン認証に関しての余談
Log in with your browserはかなり広い範囲の権限を付与されるので、間違って認証してしまった場合は、以下を実行してください。
① hugging face内のアカウント>Setting>Connected Applications>External Apps内のHugging FaceをRevokeする。
② $ hf auth logoutをする。
③ $ hf auth login してPaste an access tokenを選択。
④ tokenを記入する
■ Step 4: Gemma利用規約への同意
GemmaはGoogleが管理する gatedモデルのため、トークンを持っていても利用規約への同意がないとダウンロードできません。
-
https://huggingface.co/google/gemma-2-2bにアクセスする - 「You need to agree to share your contact information to access this model」 というバッジ(またはその下のボタン)が表示されているのでクリック。
- 規約同意のためにKaggle経由の認証フローに飛ばされる。
- Hugging Faceアカウントでの連携確認画面が表示される(求められる権限はメールアドレスの閲覧のみで、支払い情報は一切要求されない)
- Googleの「Gemma Access Request」ページで、認証方法として「Verify via Hugging Face」を選択
- Gemma利用規約のページが表示されるので、内容を確認してチェックを入れ、Acceptをクリック
- 同意が完了すると、①のページに戻り、モデルページに以下のような表示が出る。

補足
商用利用については規約上禁止されていません。ただし「Prohibited Use Policy」という悪用禁止事項(スパム・詐欺的コンテンツ生成など)には従う必要があり、派生モデルを配布する場合は同じ規約を引き継がせる義務があります。
■ Step 5: 動作確認スクリプトの実行
本格的な学習に入る前に、まずはモデルが正しく読み込めるかを確認しました。
以下のプログラムをプロジェクトフォルダ内に作成し、仮想環境で実行します。
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_name = "google/gemma-2-2b"
print("トークナイザーを読み込み中...")
tokenizer = AutoTokenizer.from_pretrained(model_name)
print("モデルを読み込み中...")
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
device_map="cpu",
)
print("読み込み完了!簡単な生成テストをします。")
inputs = tokenizer("こんにちは、今日の天気は", return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=20)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
実行結果は以下の通りです。
(venv) $ python D:\01.開発\12GenerativeAI\NewsAgent\test_load.py
トークナイザーを読み込み中...
config.json: 100%|████████████████████████████████████████████████████| 818/818 [00:00<?, ?B/s]
tokenizer_config.json: 100%|██████████████████████████████████████████| 46.4k/46.4k [00:00<00:00, 46.4MB/s]
tokenizer.json: 100%|█████████████████████████████████████████████████| 17.5M/17.5M [00:01<00:00, 8.97MB/s]
special_tokens_map.json: 100%|████████████████████████████████████████| 636/636 [00:00<00:00, 633kB/s]
モデルを読み込み中...(初回は約5GBのダウンロードが発生します。数分かかることがあります)
model.safetensors.index.json: 100%|███████████████████████████████████| 24.2k/24.2k [00:00<00:00, 24.1MB/s]
Fetching 3 files: 100%|███████████████████████████████████████████████| 3/3 [08:26<00:00, 168.95s/it]
Download complete: 100%|██████████████████████████████████████████████| 10.5G/10.5G [08:26<00:00, 20.6MB/s]
Loading weights: 100%|████████████████████████████████████████████████| 288/288 [00:00<00:00, 596.88it/s]
generation_config.json: 100%|█████████████████████████████████████████| 168/168 [00:00<00:00, 168kB/s]
読み込み完了!簡単な生成テストをします。
こんにちは、今日の天気は曇りです。
今日は、お休みです。
今日は、お休みです。
今日は
メモ
ダウンロードは約10.5GB・8分半ほどかかった。Hugging Face上の元ファイルはfloat32形式のため大きめで、torch_dtype=torch.bfloat16 を指定して読み込んでおり、実メモリ使用量は約4〜5GB程度に収まっていた。RAM8GBでもギリギリ動く範囲。
ダウンロードしたファイルはローカルキャッシュ(C:\Users\(ユーザー名)\.cache\huggingface\hub)に保存されるため、2回目以降は再ダウンロード不要で一瞬で読み込めまる。
生成結果が同じ文を繰り返してしまっていますが、これはバグではなく仕様通りの挙動。google/gemma-2-2b は ベースモデル(指示追従の訓練をしていない素のモデル)であり、かつ generate() に繰り返し抑制の設定をしていないため、起きやすい現象。チャット的な応答を期待するなら gemma-2-2b-it(instruction-tunedモデル)を使うか、繰り返し抑制パラメータ(repetition_penaltyなど)を追加する必要。
注意点メモ
| 事象 | 原因 | 対処 |
|---|---|---|
huggingface-cli login が動かない |
コマンドが hf auth login に統合され、旧コマンドは非推奨化 |
hf auth login を使う |
torch_dtype is deprecated 警告 |
transformersの仕様変更で dtype 引数に統一される予定 |
動作には影響なし。今後は dtype= 表記に置き換え予定 |
| ダウンロードが10.5GBと大きい | 元ファイルがfloat32形式で保存されているため | 読み込み時に bfloat16 を指定すれば実メモリ使用量は抑えられる |
| 生成結果が同じ文の繰り返しになる | ベースモデル+繰り返し抑制なしの組み合わせ | instruction-tunedモデルの使用、または repetition_penalty 等の追加で改善可能 |
セキュリティ・コストについて確認したこと
ローカルでLLMを動かすにあたって、「お金が発生しないか」「データが外部に漏れていないか」は事前に確認しておきたいポイントだったので、ここにも残しておきます。
費用面: Hugging Faceアカウント登録、Kaggleでのライセンス同意、pip経由のライブラリインストール、Gemma本体のダウンロードまで、すべて無料の範囲で完結します。課金が発生するのは「クラウドの有料GPUインスタンスを契約する」など、明示的な申し込みを伴う操作をした場合のみです。
通信面: モデルのダウンロードやログイン認証時には当然サーバーとの通信が発生しますが、実際の生成処理(model.generate())自体はローカルのCPU上で完結しており、入力したテキストが外部送信されることはありません。ただし huggingface_hub ライブラリには匿名の利用状況テレメトリ送信機能が含まれているため、完全に通信を絞りたい場合は以下の環境変数を設定すると無効化できます。
$env:HF_HUB_DISABLE_TELEMETRY = "1"
次回TODO
ここまででGemma 2 2Bの動作確認ができたので、次はいよいよ LoRAを使ったファインチューニングに進みます。学習データには、無料・ライセンスが明確・容量も練習用に十分小さい databricks-dolly-15k データセットを使う予定です。タスクの方向性自体はまだ未定ですが、将来的なオーケストレーター構成に組み込むことを見据えて、まずは汎用的な指示応答の練習からスタートする計画です。