1.はじめに
どうも、趣味でデータ分析している猫背なエンジニアです。
最近、政治的にうんぬんかんぬんで株価も大荒れですが、そんな中で私はトヨタ株を全売却しました。
結果としては5万円ほどの含み損(配当金はおいしかった)でした。
まあ、いまから延びる株だったかもしれませんが、最近は投資信託メインでやっていたので、最近のトヨタ株は全部売ってもあまり痛くないな~という思いで売りました。
トヨタ株自体は2年前の急に跳ね上がった時期に買ったもので、個人的にはタイミングをミスったと思っています(笑)
購入直後暴落で結構な苦虫。
そんなこともあったのですが、投資信託とは別で個別株は個別株で短期的に投資するスタイルが最近はいいのかもと2年眺めて思いました。
少額で確実に上がる株を購入できる方法を見つけるという考えのもとです。
今回はその思想を確実性にするためにアルゴを構築して、二度とトヨタの失敗をしないようにコードを組んでいきたいと思って、記録していきます。一攫千金なんかできたら、おいしいご飯とかLet's Noteの最新機種買いたいです(笑)

2. システム全体の概要
■ 概要
こちらの記事で開発したものを参考&改良を加えたものを作成するというイメージで大丈夫です。前回の記事に関しては、ユーザ(筆者)が決めた投資信託4種をつらつらと分析して自動投稿していました。
今回作成するシステムは東証リスト内すべてを対象に分析します。重要なのでもう一度いいます。
東証リスト内すべてです。
ぜーんぶまとめてトレンド分析して一攫千金を狙います。
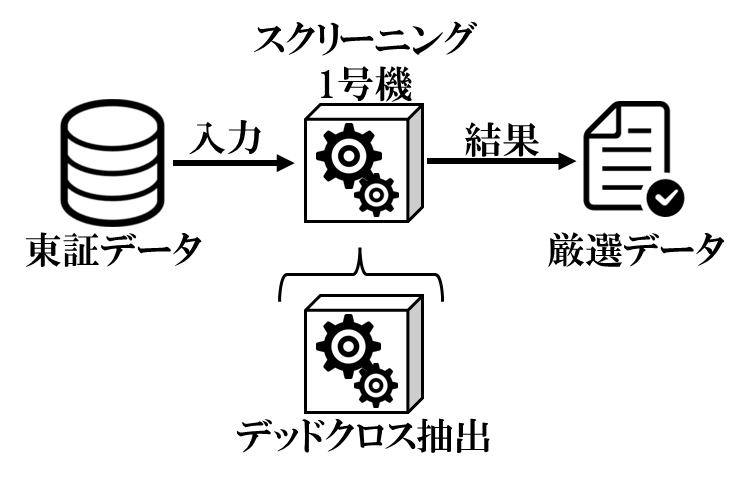
■ システム構成
今回は、データ収集とゴールデンクロスとデッドクロス判定、デッドクロスのみを抽出するアルゴを紹介します。
1号機の記載、デッドクロスのみ抽出する理由も記載できればと思います。
3. データ収集
■ 銘柄情報を変換(銘柄コード&銘柄名 抽出)
暫定処置としてローカルに東証記載の銘柄をハンドコーディングで集めています。後々、ハンドコーディングせずとも自動で銘柄番号を取得して更新してくれるものも作りたいと思っています。辞書型として銘柄コードに変換するコードを以下に記載します。
finance_csv_path = f"D:/01.開発/05KK/finance_TSE/TSE_20250723.csv"
save_finance_path = f"D:/01.開発/05KK/finance_TSE/tickers_code.py"
# 銘柄辞書を作成(コードをkey, 銘柄名をvalueにする)
def get_tse_CodeAndName():
stocks_dict = {}
reader = pd.read_csv(finance_csv_path, encoding='utf-8').reset_index()
print(reader.columns)
for _, row in reader.iterrows():
code = str(row['コード']).strip()
name = str(row['銘柄名']).strip()
stocks_dict[code] = name
# 辞書をJSONで保存
with open(save_finance_path, mode='w', encoding='utf-8') as file:
file.write("stock_dict = ")
json.dump(stocks_dict, file, ensure_ascii=False, indent=4)
print(f"銘柄辞書を保存しました: {save_finance_path}")
ちなみにTSE_20250723.csvはこんな感じになっています

■ 株価データ取得・保存
TSE_20250723.csvをコードと銘柄名だけ抽出したJSON形式の辞書を用いて、全ての株価データを取得。
今回は大規模なダウンロードを実施するため、yfinanceのdownload変数を使用。取得期間は1年で1日間隔でDate,Close,High,Low,Open,Volumeのデータをそれぞれ収集。
ファイル名称ルールは銘柄コード_銘柄名_stock.csvで統一。
def download_agriculture_stocks(period="1y", interval="1d"):
# ループして yfinance で取得
for code, name in Finance_code.stock_dict.items():
ticker = f"{code}.T" # yfinance 用のティッカーを作成
print(f"{name} ({ticker}) の株価データ取得中...")
data = yf.download(ticker, period=period, interval=interval)
if data.empty:
print(f"❌ 取得失敗: {name} ({ticker})")
elif ticker == "":
print(f"⚠️ 非上場: {name} は非上場のため取得不可")
else:
print(f"✅ データ取得成功: {name} ({ticker})")
print(data.head())
csv_path = f"D:/01.開発/05KK/finance_TSE/finance_stock_data/{code}_{name}_stock.csv"
if isinstance(data.columns, pd.MultiIndex):
data.columns = [col[0] for col in data.columns]
data.to_csv(csv_path)
print(f"保存完了: {csv_path}")
DL後のcsv群はこんな感じ👍

4. スクリーニング1号機
■ スクリーニング1号機とは
古典的な(昔から使われている)スクリーニングロジック用の箱を用意しました。それを概要図のスクリーニング1号機と称して作っています。ここにさまざまな古典的なスクリーニングロジックを組んでいきたいと思います。
その第一弾として私が愛し続けている方法「ゴールドクロス/デッドクロス」を入れました。
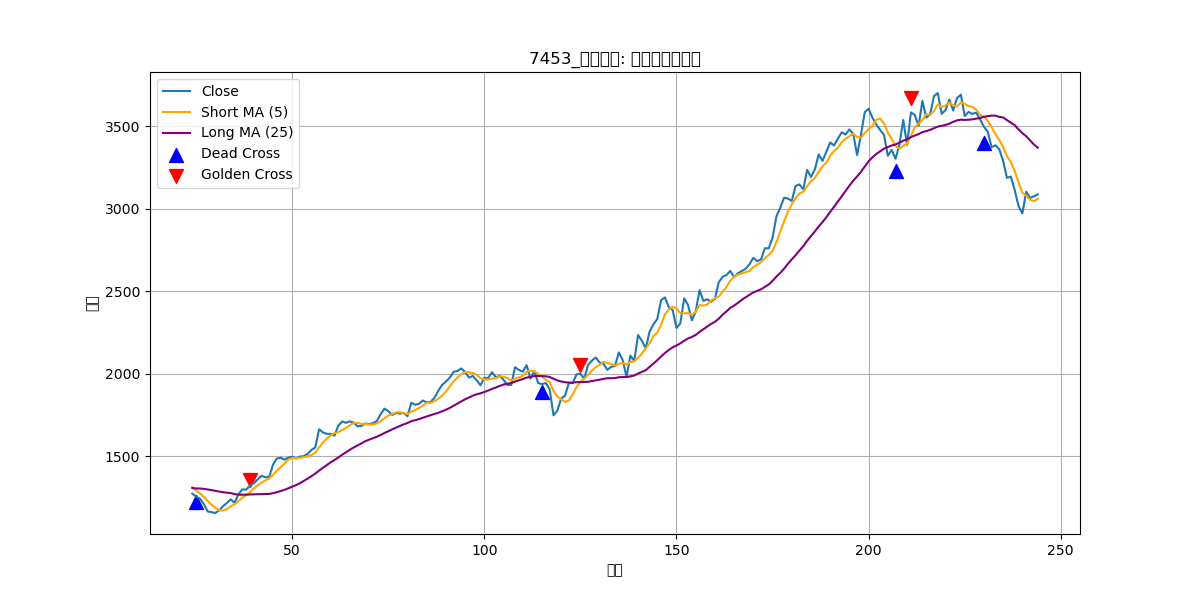
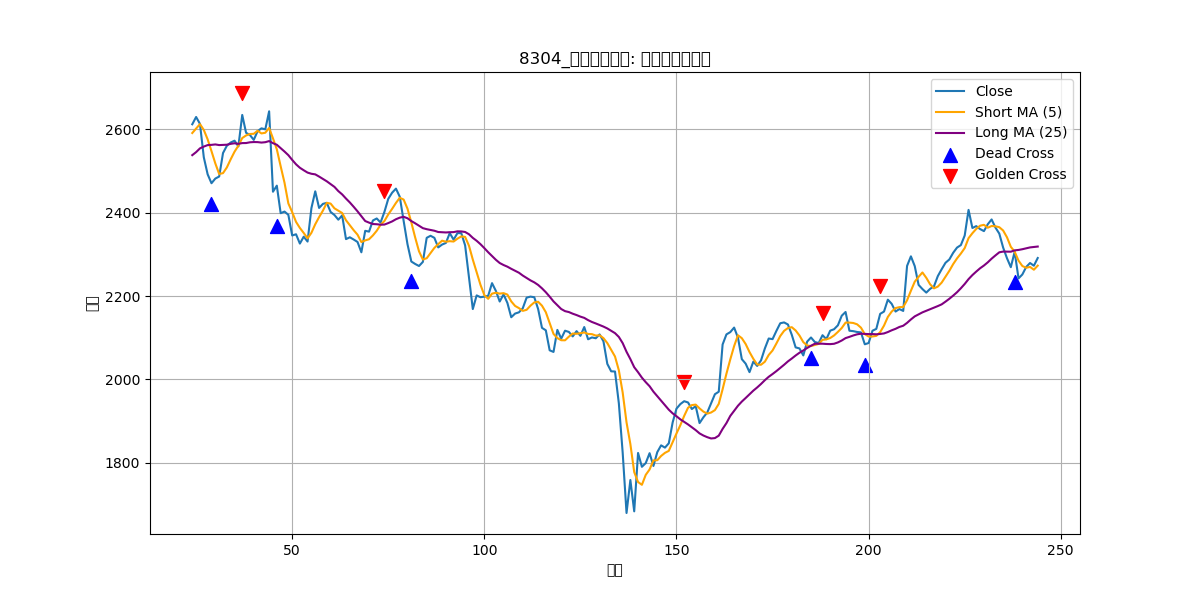
■ ゴールドクロス/デッドクロス判定
テクニカル分析の一つですが、基本的にゴールドクロスとデッドクロスの関係上、ゴールドクロスは売り時でデッドクロスは買い時と理解しています(理解は人それぞれ)。その分析の仕組みを用いて、デッドクロス...つまりは一番安い時を見越して知らせてもらうようにしました。その前処理のフラグフェーズです。
def is_cross_signal(df):
df['Close'] = pd.to_numeric(df['Close'], errors='coerce')
df['High'] = pd.to_numeric(df['High'], errors='coerce')
df['Low'] = pd.to_numeric(df['Low'], errors='coerce')
df['Short_MA'] = df['Close'].rolling(window=5).mean()
df['Long_MA'] = df['Close'].rolling(window=25).mean()
df['Golden_Cross'] = (df['Short_MA'] > df['Long_MA']) & (df['Short_MA'].shift(1) <= df['Long_MA'].shift(1))
df['Dead_Cross'] = (df['Short_MA'] < df['Long_MA']) & (df['Short_MA'].shift(1) >= df['Long_MA'].shift(1))
df['golden_cross_marker'] = np.where(df['Golden_Cross'], df['High'] * 1.02, np.nan)
df['dead_cross_marker'] = np.where(df['Dead_Cross'], df['Low'] * 0.98, np.nan)
return df
■ デッドクロス抽出アルゴ
先ほど説明したデッドクロスだけを抽出するフェーズになります。このふるいかけをすることで上がるものだけを抽出することができます。
def screen_stocks(data_dir):
results = []
for file in os.listdir(data_dir):
if file.endswith('_stock.csv'):
path = os.path.join(data_dir, file)
df = pd.read_csv(path)
df = is_cross_signal(df)
df = df.dropna(subset=['Close', 'Short_MA', 'Long_MA'])
if len(df) == 0:
continue
name = file.replace('_stock.csv', '')
# デッドクロスフラグ管理
dead_cross_flag = False
for idx, row in df.iterrows():
if row['Dead_Cross']:
dead_cross_flag = True
if row['Golden_Cross']:
dead_cross_flag = False
if dead_cross_flag:
results.append((name, "デッドクロス中", df))
return results
5.とりあえず結果をみてみる
■ 正常結果
抽出したものを画像にして買い増し推奨フォルダ(仮称)に入ったものを紹介します。
※表示バグは現在調節中。
■ 日本製鐵 (5905)

■ 良品計画 (7453)
■ あおぞら銀行 (8304)
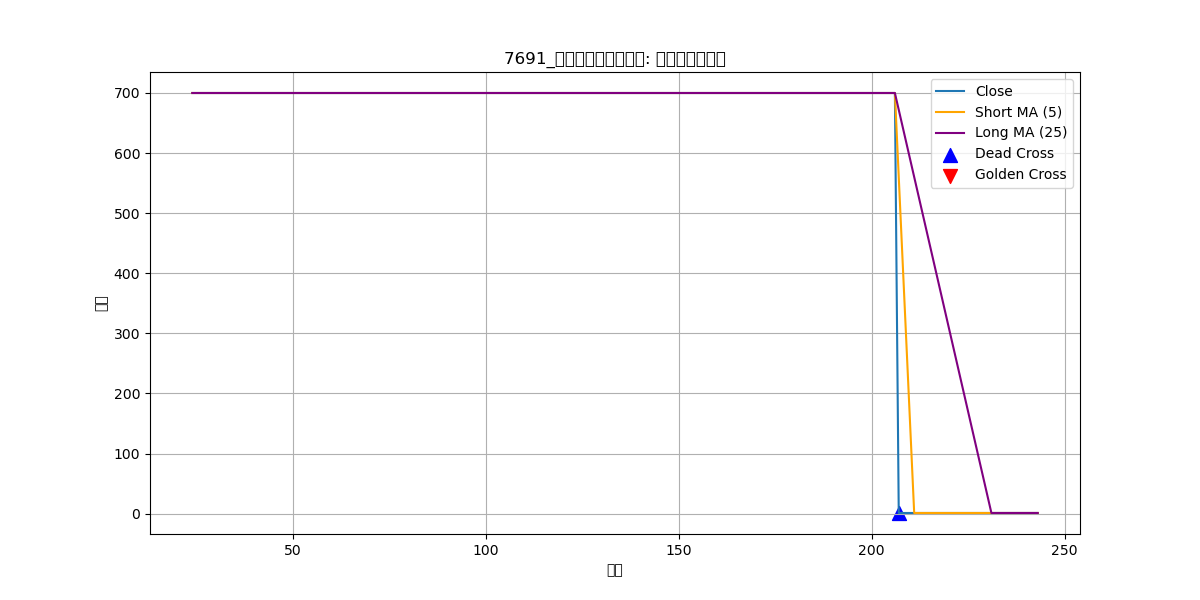
■ 例外結果
このほかにも1295個の銘柄が抽出されていました。さすがに有象無象に抽出されすぎて上場廃止されたものも含まれていました。例えばc channelとか。さすがにこれはスクリーニング失敗ですね(笑)
■ c channel (7691)
6.おわりに
今回はこの記事の派生版として新たに東証全スクリーニング版のプロジェクトを開始しました。その中で、未完成ながらスタートアップとしてのスクリーニングマシーンを組み立てることができたのは大きな一歩と思いました。
今後の目標としては、少額投資でもしっかりリターンが返ってくるアルゴを組み立てていきたいと思います。
また、このシステムの名前を...
KK_FinancialEater(FE:ファイナンシャルイーター)
とでもしましょうか。
全てのファイナンシャルデータを食らうもの。なんてね(笑)
参考文献
■ スクリーニング関連記事として
■ 派生元