PyTorch を使って、ゼロから作る感情分析
はじめに
はじめまして。私は大学院生です。
この記事では、scikit-learn や Transformers を使わずに、PyTorch のみで感情分析を行います。(主に、研究室の後輩向けに書いていますので、極力簡素化しています。そのため、普段使うことが多い Transformers の Tokenizer やモデルとは大きく異なります。ご了承ください。)
この記事が、「PyTorch と自然言語処理の学習に役立った」と思っていただけるように書かさせていただきます。
より簡素化できる案などがあればコメントをしていただけると幸いです。
類似記事もありますので、是非こちらもご覧になってください。
事前準備
用語解説
基本的な用語はこちらで解説しています。
環境
データセット
実験コード
ライブラリのインポート
import re
from collections import Counter
import pandas as pd
import matplotlib.pyplot as plt
from tqdm import tqdm
import torch
from torch import nn, optim
from torch.utils.data import DataLoader, TensorDataset
デバイスの設定
Google Colab では、「ランタイム」 -> 「ランタイムのタイプを変更」 -> 「T4 GPU」 に設定してください。
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
上記の設定ができていると、print(device) の出力は、device(type='cuda') になるはずです。
データセットのロード
今回使用するデータセットは、SST-2 1 を使用します。
splits = {'train': 'data/train-00000-of-00001.parquet', 'validation': 'data/validation-00000-of-00001.parquet'}
train_df = pd.read_parquet("hf://datasets/stanfordnlp/sst2/" + splits["train"])
val_df = pd.read_parquet("hf://datasets/stanfordnlp/sst2/" + splits["validation"])
学習データからラベル数を取得します。
num_classes = train_df['label'].nunique()
データセットの分析
head() メソッドを使うことで、先頭 5 行を見ることができます。
train_df.head()
tail() メソッドを使うことで、末尾 5 行を見ることができます。
train_df.tail()
describe() メソッドを使うことで、記述統計量を見ることができます。
train_df.describe()
学習データのラベルの割合を以下で確認することができます。確認する意図としては、ラベルに偏りがある場合、ダウンサンプリング(あるいはアップサンプリング)が必要になるからです。
train_df['label'].value_counts(normalize=True)
単語の出現頻度を可視化します。ただし、上位 50 件のみを表示します。
all_words = []
for sentence in train_df["sentence"]:
words = re.findall(r'\b\w+\b', sentence.lower())
all_words.extend(words)
word_counts = Counter(all_words)
top_50_words = word_counts.most_common(50)
words, counts = zip(*top_50_words)
plt.figure(figsize=(12, 8))
plt.bar(words, counts)
plt.xticks(rotation=45)
plt.xlabel("Words")
plt.ylabel("Frequency")
plt.show()

テキストの長さを可視化します。
train_df["text-length"] = train_df["sentence"].apply(lambda x: len(x.split()))
train_df["text-length"].hist(bins=50)
plt.xlabel("text length")
plt.ylabel("count")
plt.show()

トークナイザの作成
スペースで単語を区切り、各単語を辞書に登録していきます。この方法は、単語ベーストークナイゼーション (Word-based Tokenization) といい、単純で理解しやすいです。しかし、語彙空間が大きくなりやすく、未知語 (Out of Vocabulary: OOV) が発生しやすいです。
この時、辞書の作成には学習データのみを用います。理由としては、この辞書の作成に検証データやテストデータを含めると、再現性の確保という点で問題があるからです。また、検証データやテストデータを使わないことで、バイアスの防止も行なっています。
input_ids_list = []
words_dict = {}
reversed_words_dict = {}
index = 1
for text in train_df["sentence"]:
words = text.split()
for word in words:
if word not in words_dict:
words_dict[word] = index
reversed_words_dict[words_dict[word]] = word
index += 1
input_ids = [words_dict[word] for word in words]
input_ids_list.append(input_ids)
検証データやテストデータの中には、学習データには出現しなかった単語が含まれている可能性があります。そのため、未知の単語用の ID を一つだけ用意します。
unknown_token_id = len(words_dict) + 1
vocab_size = unknown_token_id + 1
辞書を元に tokenize_sentence を使って、単語を ID に変換します。この時に、未知の単語には、unknown_token_id が与えられます。
def tokenize_sentence(sentence, words_dict):
return [words_dict.get(word, unknown_token_id) for word in sentence.split()]
input_ids_list_train = [torch.tensor(tokenize_sentence(text, words_dict)) for text in train_df["sentence"]]
labels_tensor_train = torch.tensor(train_df['label'].values)
input_ids_list_val = [torch.tensor(tokenize_sentence(text, words_dict)) for text in val_df["sentence"]]
labels_tensor_val = torch.tensor(val_df['label'].values)
pad_sequence() は、異なる長さの文を 1 つのテンソルにまとめるための関数です。この関数を使うことで短い文の後ろに 0 を詰める(パディングする)ことができ、長さを揃えることができます。
訓練データと検証データをデータローダを用いて、ミニバッチ学習を行うための準備します。訓練用のデータローダには、シャッフルを適応させておきます。シャッフルを行うことで、エポック毎で異なるバッチが作られます。これにより、勾配の多様性を生み、より安定して収束することが期待できます。
train_dataset = TensorDataset(nn.utils.rnn.pad_sequence(input_ids_list_train, batch_first=True), labels_tensor_train)
val_dataset = TensorDataset(nn.utils.rnn.pad_sequence(input_ids_list_val, batch_first=True), labels_tensor_val)
train_dataloader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_dataloader = DataLoader(val_dataset, batch_size=32)
input_ids_list_train から元の文章を生成してみます。
id = 0
' '.join([reversed_words_dict[token_id.item()] for token_id in input_ids_list_train[id]])
同様に、input_ids_list_val から元の文章を生成してみます。ただし、検証データには未知語が含まれている可能性がありますので、未知語は <UNK> と表示させます。
id = 0
' '.join([reversed_words_dict.get(token_id.item(), '<UNK>') for token_id in input_ids_list_val[id]])
モデルの定義
-
vocab_size:語彙サイズを表し、埋め込み (embedding) 層の入力サイズに対応します。モデルが何種類の単語を認識できるかを指定します。 -
embedding_dim:埋め込み次元数で、各単語が埋め込みベクトルに変換される際の次元数を指定します。 -
output_dim:最終的な出力の次元で、クラス数に合わせます。
nn.Embedding は、単語をベクトル表現(埋め込み)に変換する層です。この層を通すと、入力の各単語が埋め込み行列に基づき数値ベクトルに変換されます。
nn.Linear は、全結合層で、入力ベクトルと重み行列を掛け合わせて出力ベクトルを得る層です。
self.embedding(x) は、単語テンソル x を 埋め込み層に渡し、各単語を埋め込みベクトルに変換します。サイズは、入力が [batch_size, max_seq_len]、出力が、[batch_size, max_seq_len, embedding_dim] となります。
x.mean(x) は、埋め込みベクトルの平均を取っています。具体的には、max_seq_len の次元で平均を計算し、文全体を 1 つのベクトルに要約します。この処理により、出力は [batch_size, embedding_dim] の形になります。これは、各シーケンスが 1 つのベクトルとして表現されることを意味し、シーケンスの長さを考慮せずに全体的な意味を捉えることができます。
self.fc(x) は、平均化された埋め込みベクトル x を全結合層 (fc) に渡し、最終的な出力クラスのスコアを生成します。出力 x は [batch_size, output_dim] となり、各行が 1 つのサンプルの予測スコアを示します。
class MODEL(nn.Module):
def __init__(self, vocab_size, embedding_dim, output_dim):
super(MODEL, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.fc = nn.Linear(embedding_dim, output_dim)
def forward(self, x):
x = self.embedding(x)
x = x.mean(dim=1)
x = self.fc(x)
return x
model = MODEL(vocab_size=vocab_size, embedding_dim=100, output_dim=num_classes).to(device)
モデルの確認は、以下のコードで見ることができます。
model
モデルの学習可能なパタメータ数の確認は以下のコードで見ることができます。if p.requires_grad の部分は、学習可能かどうかを判定するために入れています。
sum(p.numel() for p in model.parameters() if p.requires_grad)
損失関数と最適化関数の定義
損失関数は、「交差エントロピ誤差」を使います。最適化関数は、Adam 2 を使います。
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-5)
評価指標の定義
予測結果と正解ラベルが正しいか判定する関数です。
\mathrm{正解率} = \frac{\mathrm{真陽性} + \mathrm{真陰性}}{\mathrm{真陽性} + \mathrm{偽陽性} + \mathrm{真陰性} + \mathrm{偽陰性}}
def calculate_accuracy(preds, labels):
_, predicted = torch.max(preds, 1)
correct = (predicted==labels).float()
accuracy = correct.sum() / len(correct)
return accuracy.item()
学習ループ
学習ループです。loss.backward() が誤差逆伝播法を行なっています。評価時の torch.no_grad() は勾配計算をしない設定にしています。これをすることで、メモリの使用量の削減につながります。
result_df = pd.DataFrame(columns=["Train Loss", "Train Acc", "Val Loss", "Val Acc"])
num_epochs = 300
for epoch in tqdm(range(num_epochs)):
model.train()
train_loss = 0
train_accuracy = 0
for batch in train_dataloader:
inputs, labels = batch
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
train_loss += loss.item()
train_accuracy += calculate_accuracy(outputs, labels)
avg_train_loss = train_loss / len(train_dataloader)
avg_accuracy = train_accuracy / len(train_dataloader)
result_df.loc[epoch, "Train Loss"] = avg_train_loss
result_df.loc[epoch, "Train Acc"] = avg_accuracy
print(f'Epoch {epoch+1}/{num_epochs}, Train Loss: {avg_train_loss:.4f}, Train Accuracy: {avg_accuracy:.4f}')
model.eval()
val_loss = 0
val_accuracy = 0
with torch.no_grad():
for batch in val_dataloader:
inputs, labels = batch
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
val_loss += loss.item()
val_accuracy += calculate_accuracy(outputs, labels)
avg_val_accuracy = val_accuracy / len(val_dataloader)
avg_val_loss = val_loss / len(val_dataloader)
val_accuracy = val_accuracy / len(val_dataloader)
result_df.loc[epoch, "Val Loss"] = avg_val_loss
result_df.loc[epoch, "Val Acc"] = val_accuracy
print(f'Epoch {epoch+1}/{num_epochs}, Val Loss: {avg_val_loss:.4f}, Val Accuracy: {val_accuracy:.4f}')
損失と精度の可視化
plt.plot(result_df["Train Loss"], label="Train Loss")
plt.plot(result_df["Val Loss"], label="Val Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.legend()
plt.show()

plt.plot(result_df["Train Acc"], label="Train Accuracy")
plt.plot(result_df["Val Acc"], label="Val Accuracy")
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
plt.legend()
plt.show()
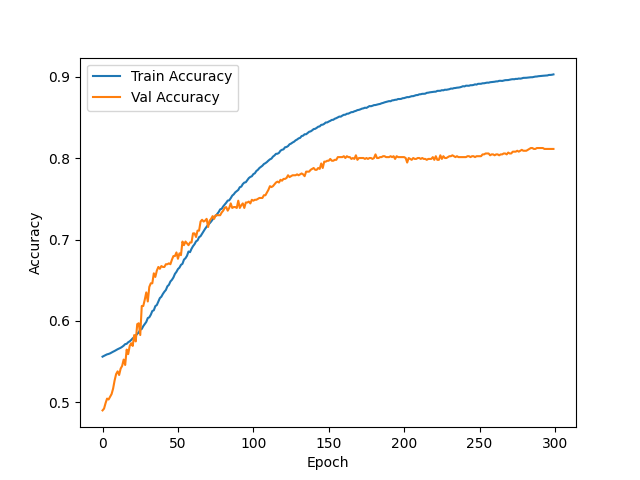
精度をより高めるための案
- データ前処理
- テキストの正規化
- 大小文字の統一
- 句読点や特殊文字の除去
- ストップワード(「a」、「and」や「I」など )の除去
- テキストの正規化
- データの増強
- トークナイザの作成戦略の変更
- サブワードトークナイゼーション (Subword Tokenization)
- BPE (Byte-Pair Encoding) 5
- WordPiece 6
- SentencePiece 7
- サブワードトークナイゼーション (Subword Tokenization)
- モデルの工夫
- ハイパーパラメータの最適化
- スケジューラ (scheduler) の導入
- バッチサイズや学習率の調整
- 正則化の導入
評価指標の追加
- 適合率 (Precision)
- 再現率 (Recall)
- F 値 (F1-Score)
- ROC-AUC
- PR-AUC
- 混同行列 (Confusion Matrix)
おわりに
この記事では、scikit-learn や Transformers を使わずに、PyTorch のみで感情分析を行いました。
この記事が、「PyTorch と自然言語処理の学習に役立った」と思っていただけたら幸いです。
参考文献
-
Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D. Manning, Andrew Y. Ng, and Christopher Potts. Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, 2013. ↩
-
Diederik P. Kingma and Jimmy Ba. Adam: A Method for Stochastic Optimization. In 3rd International Conference on Learning Representations, 2015. ↩
-
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics, 2019. ↩
-
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. J. Mach. Learn. Res., 2020. ↩
-
Rico Sennrich, Barry Haddow and Alexandra Birch. Neural Machine Translation of Rare Words with Subword Units. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, 2016. ↩
-
Mike Schuster and Kaisuke Nakajima. Japanese and Korean voice search. In 2012 IEEE International Conference on Acoustics, 2012. ↩
-
Taku Kudo and John Richardson. SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, 2018. ↩
-
Nitish Srivastava, Geoffrey E. Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. Dropout: a simple way to prevent neural networks from overfitting. J. Mach. Learn. Res., 2014. ↩