SFTTrainer を使って、簡単に CausalLM をファインチューニングをしよう
はじめに
はじめまして。現在、私は大学院生(修士課程)です。
この記事では、TRL というライブラリを使って、簡単に Causal Language Model (CausalLM) をファインチューニングしようと思います。
この記事が「CausalLM の勉強を始めました」や「コードを書くのが楽になった」などの貢献ができるように書かせていただきます。
類似記事もありますので、是非こちらもご覧になってください。
環境構築
Python バージョン
- Python >= 3.0.0
ライブラリ
datasets
peft
torch>=2.0.0
transformers
trl
使用するモデルとデータセット
モデル
今回使用するモデルは、rinna GPT を使用します。
データセット
今回使用するデータセットは、SciQ 1 を日本語に翻訳したデータセットを使用します。
コード
ライブラリのインポート
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, DataCollatorForLanguageModeling
from datasets import load_dataset
from peft import LoraConfig
from trl import DataCollatorForCompletionOnlyLM, SFTConfig, SFTTrainer
トークナイザとモデル
ロード
cuda が使えれば、cuda の方にモデルをロードします。
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained("rinna/japanese-gpt2-xsmall")
model = AutoModelForCausalLM.from_pretrained("rinna/japanese-gpt2-xsmall").to(device)
モデルの構造を確認します。
model
LoRA の設定
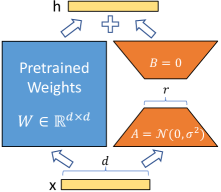
LoRA 2 を適応したモデルの入出力は、以下の式で表せます。ここで、$W_0 \in \mathbb{R}^{d \times k}$ は凍結された事前学習済み重み行列、$B \in \mathbb{R}^{d \times r}$、$A \in \mathbb{R}^{r \times k}$とし、$r \ll \min(d, k)$です。初期化方法は、$B$ を零行列に従い初期化し、$A$ を正規分布に従い初期化します。
h = W_0 x + \Delta W x = W_0 x + B A x
LoRA を適応したとき、学習可能なパラメータ数の割合は、以下の式のように表せます。
\frac{d \times r + r \times k}{d \times k + d \times r + r \times k} = \frac{r (d + k)}{d k + r (d + k)}
LoRA を使うことで、ファインチューニングの時のコストを大幅に削減することができます。
この記事では、モデルサイズが $43.7 \mathrm{M}$ のモデルを使っているので、あまり恩恵は感じられないかもしれません。
数 $\mathrm{B}$ 程度のモデルでは、LoRA の恩恵を受けられると思います。
今回は、全ての線形層に LoRA を適応したいため、target_modules="all-linear" としました。
peft_config = LoraConfig(
peft_type="LORA",
task_type="CAUSAL_LM",
r=8,
target_modules="all-linear",
lora_alpha=8,
lora_dropout=0.0
)
データセット
ロード
train_dataset = load_dataset("izumi-lab/sciq-ja-mbartm2m", split="train")
eval_dataset = load_dataset("izumi-lab/sciq-ja-mbartm2m", split="validation")
学習に使用するフォーマットの作成とデータコレーター
formatting_func に、学習の時に使うプロンプトを書きます。
def formatting_func(example):
output_texts = [
f"# 問題: {example['question'][i]}\n#ヒント: {example['support'][i]}\n# 答え: {example['correct_answer'][i]}" for i in range(len(example))
]
return output_texts
data_collator = DataCollatorForCompletionOnlyLM(
response_template=tokenizer.encode("# 答え: ", add_special_tokens=False),
instruction_template=tokenizer.encode("# 問題: ", add_special_tokens=False),
tokenizer=tokenizer
)
LLaMA 2 のようないくつかのトークナイザでは、他とは異なるトークン化戦略のため、上記のような書き方の data_collator では学習ができません。
LLaMA 2 のようないくつかのトークナイザの場合は、以下のようなコードに変更して下さい。
data_collator = DataCollatorForCompletionOnlyLM(
response_template=tokenizer.encode("\n# 答え: ", add_special_tokens=False)[2:],
instruction_template=tokenizer.encode("# 問題: ", add_special_tokens=False),
tokenizer=tokenizer
)
あるいは、Transformers の DataCollatorForLanguageModeling を使って、以下のようなコードに変更して下さい。
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False,
return_tensors="pt"
)
学習
設定
SFTConfig は、Transformers の TrainingArguments を継承しています。
今回は、基本的なパラメータのみをここに書いていますが、より細かく設定したい人は、調べてみて下さい。
最適化関数は、AdamW 3 がデフォルトで設定されています。
-
output_dir:チェックポイントなどの保存先のパス -
evaluation_strategy:評価戦略 -
per_device_train_batch_size:訓練時のバッチサイズ -
per_device_eval_batch_size:評価時のバッチサイズ -
learning_rate:初期の学習率 -
num_train_epochs:エポック数 -
lr_scheduler_type:スケジューラーのタイプ -
warmup_ratio:学習率を $0$ からlearning_rateで指定した値までの線形ウォームアップの割合 -
logging_strategy:ロギング戦略 -
save_strategy:保存戦略 -
report_to:結果やログを記録する外部サービス
TensorBoard や WandB などの設定ができていれば、損失などの記録を確認することができます。
args = SFTConfig(
output_dir="./outputs",
evaluation_strategy="epoch",
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
learning_rate=5e-5,
num_train_epochs=3.0,
lr_scheduler_type="linear",
warmup_ratio=0.0,
logging_strategy="epoch",
save_strategy="epoch",
report_to="all"
)
Trainer の用意
trainer = SFTTrainer(
model=model,
args=args,
data_collator=data_collator,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
tokenizer=tokenizer,
peft_config=peft_config,
formatting_func=formatting_func
)
Trainer の確認
この時点で、LoRA 2 を適応済みです。
trainer.model
trainer.model.print_trainable_parameters()
学習の設定は、SFTConfig で指定した値以外はデフォルトに設定されています。
trainer.args
データセットは、formatting_func で指定したフォーマットに従い、トークン化されています。
trainer.tokenizer.decode(trainer.train_dataset[0]["input_ids"])
学習開始
trainer.train()
推論
学習済みのモデルをロード
outputs/checkpoint-xxx の xxx は、outputs フォルダ内の存在する整数に書き換えて下さい。
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained("outputs/checkpoint-xxx")
model = AutoModelForCausalLM.from_pretrained("outputs/checkpoint-xxx").to(device)
評価用のデータセット
test_dataset = load_dataset("izumi-lab/sciq-ja-mbartm2m", split="test")
生成
with torch.no_grad():
id = 0
input_text = f"# 問題: {test_dataset['question'][id]}\n#ヒント: {test_dataset['support'][id]}\n# 答え: "
tokenized_input_text = tokenizer(input_text, return_tensors="pt").to(model.device)
tokenized_output_text_list = model.generate(**tokenized_input_text, max_new_tokens=128)
output_text_list = [
tokenizer.decode(tokenized_output_text, skip_special_tokens=True) for tokenized_output_text in tokenized_output_text_list
]
print(output_text_list)
おわりに
この記事では、ファインチューニングを簡単にできるようにしました。また、学習したモデルを使って、推論をするため方法について書きました。
この記事が CausalLM を学習・研究する人に貢献できたら、幸いです。
参考文献
-
Johannes Welbl, Nelson F. Liu and Matt Gardner. Crowdsourcing Multiple Choice Science Questions. In Proceedings of the 3rd Workshop on Noisy User-generated Text, 2017. ↩
-
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang and Weizhu Chen. LoRA: Low-Rank Adaptation of Large Language Models. In The Tenth International Conference on Learning Representations, 2022. ↩ ↩2
-
Ilya Loshchilov and Frank Hutter. Decoupled Weight Decay Regularization. In 7th International Conference on Learning Representations, 2019. ↩