SQLアンチパターン の1〜8章をまとめました。
この本では以下の4つのパートに分かれており、
- データベース論理設計のアンチパターン(1〜8章)
- データベース物理設計のアンチパターン(9〜12章)
- クエリのアンチパターン(13〜18章)
- アプリケーション開発のアンチパターン(19〜25章)
この記事では「1. データベース論理設計のアンチパターン」について記述します。
目次
第1章-Jaywalking(信号無視)
第2章-Naive Trees(素朴な木)
第3章-ID Required(とりあえずID)
第4章-Keyless Entry(外部キー嫌い)
第5章-Entity-Attribute-Value(EAV エンティティ・アトリビュート・バリュー)
第6章-Polymorphic Associations(ポリモーフィック関連)
第7章-Multicolumn Attributes(複数列属性)
第8章-Metadata Tribbles(メタデータ大増殖)
補足
第1章-Jaywalking(信号無視)
1つの列にデータにカンマ(,)やスラッシュ(/)を使用して、複数の値を格納しているアンチパターンです。
例:アンケートなどの設問と選択肢を管理しているquestionsテーブルとchoicesテーブル
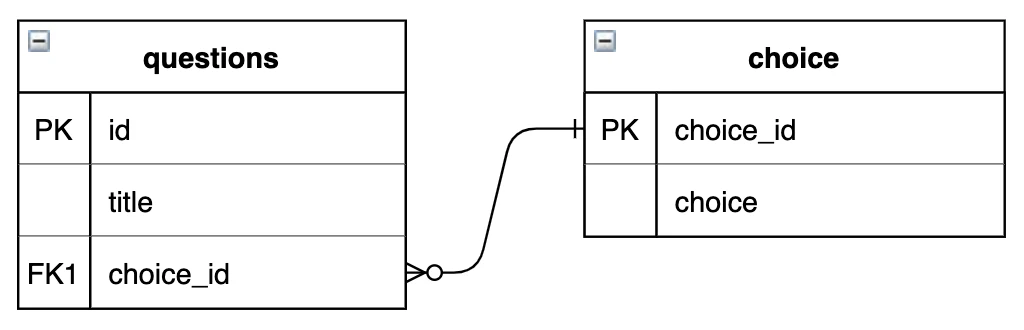
questionsテーブル
| id | title | choice_id |
|---|---|---|
| 1 | question1 | 1,2,3 |
| 2 | question2 | 2,4 |
| 3 | question3 | 5,6 |
choicesテーブル
| choice_id | choice |
|---|---|
| 1 | choice1 |
| 2 | choice2 |
| 3 | choice3 |
| 4 | choice4 |
| 5 | choice5 |
| 6 | choice6 |
デメリット
①検索や集約処理を行う際に面倒
パターンマッチや区切り文字の除去を行わなければならなくなり、メンテナンス性やパフォーマンスなどが悪化してしまいます。
questionsテーブルの「choice_id = 2」を持っている全ての行をパターンマッチで取得するには、
MySQLの場合、REGEXP関数を用いなければなりません。
SELECT * FROM questions WHERE choice_id REGEXP ('(^|,)', 2, '(,|$)');
また、パターンマッチはデータベース製品によって、書き方が異なってしまい、
データベース製品の以降や、新しく配属されたメンバーがこのことを知らずに他のデータベース製品のパターンマッチを記述してしまうなど、バグが生じる原因となってしまいます。
②不正な入力を許容してしまう可能性がある
「,」や「/」を入れることで、数値型ではなく文字列型で定義する必要があるため、不正な入力を許容してしまう可能性が出てきてしまいます。
また「,」や「/」が入っている場合、これらが区切り文字なのか、文字列の一部なのかが不明瞭です。
③リスト長さの上限しかデータが入らない
登録される文字列の長さによって、紐づけることができる個数の上限が変動してしまいます。
例えば「VARCHER(20)」で設定している場合、文字数が2文字の場合はカンマを含めると6つまで登録可能となりますが、3文字の場合は5つまでと変わってしまいます。
解決策:交差テーブルの作成
交差テーブルは「中間テーブル」や「関連テーブル」とも呼ばれていて、その名の通りテーブル間に新たなテーブルを作成することで、2つの参照先のテーブルを多対多の関係にします。
先程の例で交差テーブルを作成すると、以下のようになります。
 図:交差テーブルを作成した関係図
図:交差テーブルを作成した関係図
titlesテーブル
| title_id | title |
|---|---|
| 1 | question1 |
| 2 | question2 |
| 3 | question3 |
questionsテーブル
| id | title_id | choice_id |
|---|---|---|
| 1 | 1 | 1 |
| 2 | 1 | 2 |
| 3 | 1 | 3 |
| 4 | 2 | 2 |
| 5 | 2 | 4 |
| 6 | 3 | 5 |
| 7 | 3 | 6 |
choicesテーブル
| choice_id | choice |
|---|---|
| 1 | choice1 |
| 2 | choice2 |
| 3 | choice3 |
| 4 | choice4 |
| 5 | choice5 |
| 6 | choice6 |
このように設計することで、パターンマッチや区切り文字の除去を使用することなく検索が行えるようになります。
例えば、questionsテーブルの「choice_id = 2」を持っている全ての行を取得する場合、WHERE句を用いて簡潔に記述できます。
SELECT * FROM questions WHERE choice_id = 2;
さらに「,」や「/」を使用しないため、カラムが数値型として設定でき、不要な値の入力を防ぐことができるようになります。
また、交差テーブルの個別の行に格納されているため、リストの長さの制限も解消されます。
第2章-Naive Trees(素朴な木)
親子関係があるデータ設計でのアンチパターンです。
例:位置関係を表すlocationsテーブル
locationsテーブル
| id | parent_id | location |
|---|---|---|
| 1 | null | 地球 |
| 2 | 1 | 日本 |
| 3 | 1 | アメリカ |
| 4 | 2 | 東京 |
| 5 | 4 | 浅草 |
| 6 | 3 | ロサンゼルス |
| 7 | 3 | ワシントン |
 図:locationsテーブルの関係図
図:locationsテーブルの関係図
このように「parent_id」列を設けて直近の親のみを参照するようにしてツリー構造を設計すると、各項目がどのように紐付いているかが分かるようになります。
今回の例だと、id = 1に対して「parent_id = 2, 3」、id = 2に対して「parent_id = 4」、...と紐付いています。
このような、親のみに依存する設計は「隣接リスト」と呼ばれています。
デメリット
①ツリーの全体やサブツリーの取得が困難(補足1)
例えば、locationsテーブルの「id = 2(日本)」に紐付いているものを取得する場合は、JOIN句を使用します。
SELECT
c1.*,
c2.*
c3.*
FROM
locations c1
LEFT OUTER JOIN locations c2
ON c1.id = c2.parent_id
LEFT OUTER JOIN locations c3
ON c2.id = c3.parent_id
WHERE
c1.id = 2;
JOIN句を使用するため、取得できる階層が固定されてしまい、さらに階層を増やすためにはJOINで結合を増やす必要があります。
階層を指定しないためには、再帰クエリ(補足2)を使用する必要がありますが、データベースによっては使用できないものもあります。
(MySQLだと、8.0以降しか対応していません)
②非葉ノードを削除するには、子側から編集・削除しなければならない
例えばlocationsテーブルの「id = 4(東京)」を削除する場合は、紐付いている子ノードをから削除する必要があります。
「id = 4(東京)」から削除すると、データの不整合が起こってしまうためです。
UPDATE locations
SET (parent_id) =
(SELECT
c3.*
FROM
locations c1
LEFT OUTER JOIN locations c2
ON c1.id = c2.parent_id
LEFT OUTER JOIN locations c3
ON c2.id = c2.parent_id
WHERE
c1.id = 1 )
WHERE
c1.id = 2 ;
このように、非葉ノードを削除する前には、その子ノードのつなぎ直しを行う必要があります。
解決策:代替ツリーモデルの使用
代替ツリーモデルは3種類あります。
①経路列挙モデル
locationsテーブルの「parent_id」を以下のように変更します。
locationsテーブル
| id | parent_id | location |
|---|---|---|
| 1 | null | 地球 |
| 2 | 1/2 | 日本 |
| 3 | 1/2 | アメリカ |
| 4 | 1/2/4 | 東京 |
| 5 | 1/2/4/5 | 浅草 |
| 6 | 1/3/6 | ロサンゼルス |
| 7 | 1/3/7 | ワシントン |
このように「parent_id」に「/」区切りで経路を記述することで、親子関係を表現することができます。
直感的にも親子関係の全体像が見えやすくなりますが、 第1章-Jaywalking(信号無視) で記述したデメリットが出てきてしまいます。
②入れ子集合モデル
以下のルールで「left」列と「right」列のidをそれぞれ入れることで、関連付けを行います。
- 子
- 「left」より大きい
- 「right」より小さい
- 親
- 「left」より小さい
- 「right」より大きい
locationsテーブル
| id | left | right | location |
|---|---|---|---|
| 1 | 1 | 14 | 地球 |
| 2 | 2 | 7 | 日本 |
| 3 | 8 | 13 | アメリカ |
| 4 | 3 | 6 | 東京 |
| 5 | 4 | 5 | 浅草 |
| 6 | 9 | 10 | ロサンゼルス |
| 7 | 11 | 12 | ワシントン |
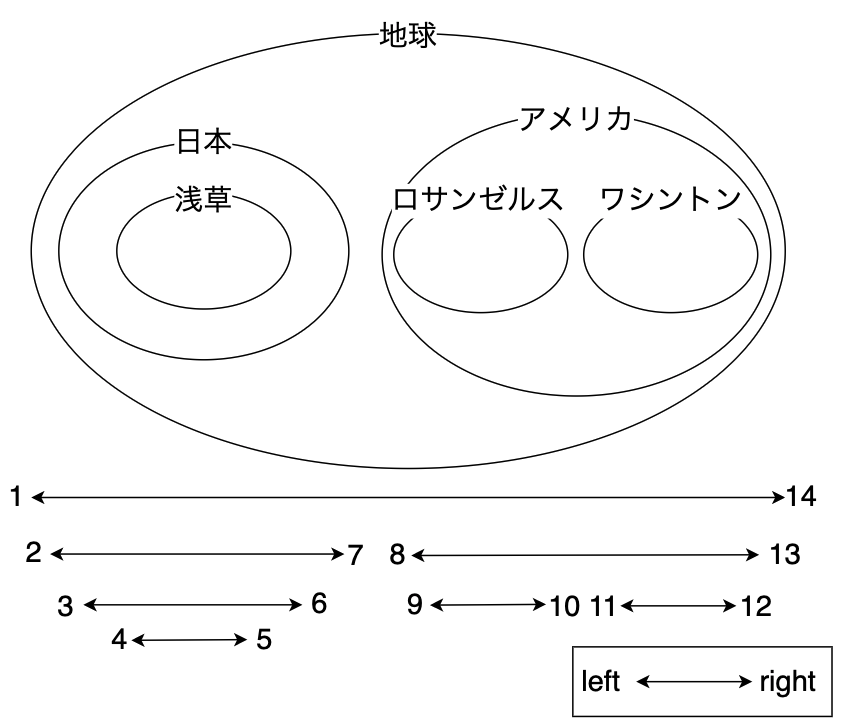 図:入れ子集合モデルでのlocationsテーブルの関係図
図:入れ子集合モデルでのlocationsテーブルの関係図
「left」列と「right」列の関係性を利用することで、ツリーの全体やサブツリーの取得が容易に行うことができます。
例えばlocationsテーブルの「id = 2(日本)」に紐付いているものを取得する場合は、
「id = 2」のleftより大きく、かつrightより小さいもの
を取得すれば良いとなります。
SELECT *
FROM locations
WHERE left >= 2
AND right <= 7;
ただし、データの更新や削除時に都度「left」列と「right」列の値の計算が必要になってしまうというデメリットがあります。
③閉包テーブルモデル
別テーブル(nodesテーブル)でノード同士の関係性を管理するようにします。
locationsテーブル
| id | location |
|---|---|
| 1 | 地球 |
| 2 | 日本 |
| 3 | アメリカ |
| 4 | 東京 |
| 5 | 浅草 |
| 6 | ロサンゼルス |
| 7 | ワシントン |
nodesテーブル
| parent_id | child_id |
|---|---|
| 1 | 1 |
| 1 | 2 |
| 1 | 3 |
| 1 | 4 |
| 1 | 5 |
| 1 | 6 |
| 1 | 7 |
| 2 | 2 |
| 2 | 4 |
| 2 | 5 |
| 3 | 3 |
| 3 | 6 |
| 3 | 7 |
| 4 | 4 |
| 4 | 5 |
| 5 | 5 |
| 6 | 6 |
| 7 | 7 |
このように設計することで、参照整合性が保証しやすくなります。
例えば、locationsテーブルの「id = 2(日本)」に紐付いているものを取得する場合は、JOIN句を使わずに記述できます。
SELECT l.*
FROM locations AS l
INNER JOIN nodes AS n ON l.id = n.parent_id
WHERE n.parent_id = 2;
また、locationsテーブルの「id = 2(日本)」を削除する場合、nodesテーブルの「parent_id = 2」を削除するだけで良いので、ノードの削除などを気にせずに書くことができます。
DELETE * FROM
WHERE parent_id = 2
第3章-ID Required(とりあえずID)
すべてのテーブルに主キーとして、「id」列を作るアンチパターンです。
例:アンケートなどの設問と選択肢を管理しているquestionsテーブルとchoicesテーブル
questionsテーブル
| id | title_id | choice_id |
|---|---|---|
| 1 | 1 | 1 |
| 2 | 1 | 2 |
| 3 | 2 | 3 |
titlesテーブル
| id | title |
|---|---|
| 1 | titile1 |
| 2 | title2 |
| 3 | title3 |
デメリット
①主キーが本来の役割を果たせていない
新しくquestionsテーブルにtitle_id=2, choice_id=4の値を追加しようとして、誤ったクエリを実行したとします。
INSERT INTO questions (title_id, choice_id) VALUES (2,3);
SELECT * FROM titles;
結果
questionsテーブル
| id | title_id | choice_id |
|---|---|---|
| 1 | 1 | 1 |
| 2 | 1 | 2 |
| 3 | 2 | 3 |
| 4 | 2 | 3 |
主キーの役割は、「テーブルのすべての行が一意であることを保証するもの」であるのに、「id」の値が異なっているのにも関わらず、同じ関連づけを持ったレコードが2件存在しています。
交差テーブル内への重複データの挿入を防ぐためには、テーブル作成時にid列以外の2列にUNIQUE制約を宣言する必要があります。
CREATE TABLE questions (
id INT PRIMARY KEY,
title_id INT UNSIGNED NOT NULL,
choice_id INT UNSIGNED NOT NULL,
UNIQUE KEY (title_id, choice_id),
FOREIGN KEY (title_id) REFERENCES titles (id),
FOREIGN KEY (choice_id) REFERENCES choices (id)
);
②JOINを使用する際にid列が複数存在するとUSING句が使えない
全てのテーブルで主キーを必ず「id」という名前で設定していると、従属テーブル側のtitlesテーブルの外部キー列には参照するquestionsテーブルの主キーと同じ名前は使えません。
そのため、USING句が使用できず、冗長な構文になってしまいます。
SELECT * FROM titles as t
INNER JOIN questions as q
ON t.id = q.title_id;
解決策:わかりやすい列名にする
主キーの名前は、主キーが識別する対象のエンティティを表すものにします。
多くのフレームワークではIDの規約を上書きして、別の名前を宣言することも可能です。
ただし、フレームワークによってはデフォルトで「ID」をプライマリーキーとして使用していることがあるため、状況に応じて設定すべきです(補足3)。
第4章-Keyless Entry(外部キー嫌い)
名前の通り、外部キーを設定しないアンチパターンです。
外部キー制約を省略することで、データーベース設計が単純化でき、柔軟性が高まり、実行速度が速くなるケースがあります。
例:本の情報とそれに対するレビューやレビュー評価を管理しているbooksテーブル、reviewsテーブル、review_statusテーブル
親テーブル1
booksテーブル
| book_id | title |
|---|---|
| 1 | SQL設計 |
| 2 | SQLアンチパターン |
| 3 | SQLクエリ入門 |
親テーブル2
review_statusテーブル
| reviw_status_id | review |
|---|---|
| 1 | とても良い |
| 2 | まあまあ良い |
| 3 | あんまり良くない |
子テーブル
reviewsテーブル
| book_id | reviw_status_id | comment |
|---|---|---|
| 1 | 1 | 最高でした。 |
| 2 | 2 | 現在4章まで読み進めました。 |
| 3 | 3 | 自分には難しかったです。 |
デメリット
①完璧なコードを前提にしている
参照整合性を保証するためのコードを書く責任が生じてしまいます。
外部キー制約を設定しなかった場合は変更前にSELECTを実行して、参照性が壊れないことを確認する必要があります。
例えば、「reviews」テーブルに行を追加する場合は、追加前に親テーブルの行の存在確認を行わなければなりません。
SELECT id FROM books WHERE id = 1;
INSERT INTO reviews (book_id, review) VAlUES (1, 'まあまあ');
②ミスを調べなければならない
ミスをしない前提になっているため、ミスを発見しなければいけません。
そのため、定期的にデータの管理をするクエリを実行する必要が出てきます。
SELECT b.book_id, b.review
FROM reviews b LEFT OUTER JOIN books s
ON b.book_id = s.id
WHERE s.id IS NULL;
③親の行を更新する前に子の行を更新すると、データの不整合が起こってしまう
親のbooksテーブルから「id = 3」のデータを削除すると、子のreviewsテーブルで「book_id = 3」を参照しているため、削除した場合にデータの不整合が起こってしまいます。
そのため小テーブルから削除する必要があります。
DELETE FROM reviews WHERE book_id = 3;
DELETE FROM books WHERE id = 3;
解決策
①参照整合性制約(外部キー制約)を宣言する
データベースへの登録時に外部キー制約による参照整性の強制することによって、上記のデメリットを防ぐことができます。
CREATE TABLE reviews (
id BIGINT UNSIGNED NOT NULL,
comment VARCHAR(20) NOT NULL DEFAULT 'NEW',
FOREIGN KEY (book_id) REFERENCES books(id),
FOREIGN KEY (reviw_status_id) REFERENCES review_status(id),
);
②カスケード更新を行う
カスケード更新を行うことで、親の行の更新や削除が可能になり、さらにその行を参照している子の行もデータベースが適切に処理してくれます。
CREATE TABLE reviews (
id BIGINT UNSIGNED NOT NULL,
comment VARCHAR(20) NOT NULL DEFAULT 'NEW',
FOREIGN KEY (book_id) REFERENCES books(id)
ON UPDATE CASCADE
ON DELETE RESTRICT,
FOREIGN KEY (reviw_status_id) REFERENCES review_status(id))
ON UPDATE CASCADE
ON DELETE SET DEFAULT
);
第5章-Entity-Attribute-Value(EAV エンティティ・アトリビュート・バリュー)
EAVでは、次のような項目を持たせたテーブルが設計されるアンチパターンです。
- Entity
- 親テーブルに対応する外部キー
- Attribute
- 各行ごとに格納したい属性名
- Value
- エンティティの属性の値
「Attribute」と「Value」のテーブルを子レコードとして大量に作成し、ある「Entity」が可変的に属性を持てるようにします。
このような設計にすることで、データベース構造を単純化することができるため、あとからいくらでも属性を柔軟に追加することが出来ます。
例えば、変更時にALTER文を実行する必要がなく、INSERT文で追加することができるようになります。
例:ECサイトの取扱い商品の詳細情報
products(Entity)テーブル
| product_id |
|---|
| 1 |
| 2 |
| 3 |
ProductAttribute(Attribute,Value)テーブル
| product_id | attr_name | attr_value |
|---|---|---|
| 1 | type | 食品 |
| 1 | name | 魚 |
| 1 | image | fish001.png |
| 1 | price | 500 |
| 1 | preservation_method | 冷蔵 |
| 2 | type | 食品 |
| 2 | name | お菓子 |
| 2 | price | 1000 |
| 2 | image | snack001.png |
| 2 | preservation | 常温 |
| 3 | type | 日用品 |
| 3 | name | 石鹸 |
| 3 | image | soap001.png |
| 3 | price | 300 |
| 3 | preservation_method | null |
デメリット
①データの取得が冗長化してしまう
例えば、「product_id = 1」の情報を取得する場合には行を再構築する必要があるため、構文が長くなってしまいます。
SELECT p.product_id,
p1.attr_value AS type,
p2.attr_value AS name,
p3.attr_value AS image,
p4.attr_value AS price,
p5.attr_value AS preservation_method
FROM ProductAttribute AS p
LEFT OUTER JOIN ProductAttribute AS p1
ON p.product_id = p1.product_id AND attr_name = 'type'
LEFT OUTER JOIN ProductAttribute AS p2
ON p.product_id = p1.product_id AND attr_name = 'name'
LEFT OUTER JOIN ProductAttribute AS p3
ON p.product_id = p1.product_id AND attr_name = 'image'
LEFT OUTER JOIN ProductAttribute AS p4
ON p.product_id = p1.product_id AND attr_name = 'price'
LEFT OUTER JOIN ProductAttribute AS p5
ON p.product_id = p1.product_id AND attr_name = 'preservation_method'
WHERE p.product_id = 1;
②属性ごとに必須・任意の設定ができない
例えばProductAttributeテーブルの「attr_name = image」のときに「attr_value = null」にしたい場合でも、個別にNULL制約をつけることができません。
attr_value列はNULL制約かNOT NULL制約のどちらかに統一することしかできません。
③SQLのデータ型を使えない
不正な入力を許容させないために、それぞれのデータ型を設定したくてもできません。
例では、「attr_name = name」は文字列型、「attr_name = price」は数値型と設定したいとなりますが、「attr_name」列に対して型付けを行う必要があるため、文字列型となってしまいます。
④外部制約キーを使用できない
デメリット③と同様に、「attr_name」のうちの1つの属性に対してに外部キーを設定してしまうと、全ての属性に外部キー制約がかかってしまうため使用できません。
解決策:サブタイプによるモデリングを行う
テーブルを分けて設計することで解消することができます。
データの継承の仕方などにいくつか種類があります。
①シングルテーブル継承
すべてのサブタイプを一つのテーブルに格納します。
ProductAttributeテーブル
| product_id | type | name | image | price | preservation_method |
|---|---|---|---|---|---|
| 1 | 食品 | 魚 | fish001.png | 500 | 冷蔵 |
| 2 | 食品 | お菓子 | 1000 | snack001.png | 常温 |
| 3 | 日用品 | 石鹸 | 300 | soap001.png | null |
ただし、このように設計すると列数が多くなってしまうデメリットが出てきます。
②具象テーブル継承
サブタイプごとにテーブルを作成して、それぞれ共通属性を持たせる方法です。
共通の属性が必要になった時には、全ての具象テーブルに追加する必要があります。
foodsテーブル
| product_id | name | image | price | preservation_method |
|---|---|---|---|---|
| 1 | 魚 | fish001.png | 500 | 冷蔵 |
| 2 | お菓子 | snack001.png | 1000 | 常温 |
daily_necessitiesテーブル
| product_id | name | image | price |
|---|---|---|---|
| 3 | 石鹸 | soap001.png | 300 |
ただし、複数の具象テーブルで検索するためにはUNIONなどを利用するなどの必要があり、処理が複雑になってしまいます。
③クラステーブル継承
オブジェクトの継承関係をクラスごとに1テーブルを用意することで表現します
(オブジェクト指向における継承を模倣しています)。
共通部でテーブルを作成して、サブタイプごとで固有の項目のみを設定します。
product_namesテーブル
| product_id | name |
|---|---|
| 1 | 魚 |
| 2 | お菓子 |
| 3 | 石鹸 |
foodsテーブル
| product_id | image | price | preservation_method |
|---|---|---|---|
| 1 | fish001.png | 500 | 冷蔵 |
| 2 | meet001.png | 1000 | 常温 |
daily_necessitiesテーブル
| product_id | image | price |
|---|---|---|
| 3 | soap001.png | 300 |
こちらのデメリットとしては、オブジェクト指向に慣れていなければ、少し扱いにくいことです。
④半構造化データ
共通項目などの明確な項目は個別列を作成して、JSON・XML等の形式で属性名・値を格納する方法です。
追加する項目が可能なため、拡張性が極めて高いという特徴があります。
ProductAttributeテーブル
| product_id | name | type | attribute |
|---|---|---|---|
| 1 | 魚 | 食品 | { image:image fish001.png, price:500,Preservation method:冷蔵} |
| 2 | お菓子 | 食品 | { image:image meet001.png, price:1000,Preservation method:常温} |
| 3 | 日用品 | 石鹸 | { image:image soap001.png, price:300} |
ただし、SQLが特定の属性にアクセスする手段がありません。
第6章-Polymorphic Associations(ポリモーフィック関連)
子テーブルが複数の親をテーブルを参照するアンチパターンです。
あるテーブルが複数のテーブルのいずれかに対して、自身:紐付き先=多:一で関連する場合のテーブル設計です。
例:管理者(admin_usersテーブル)とユーザー(usersテーブル)のそれぞれの操作履歴を管理しているlogsテーブル
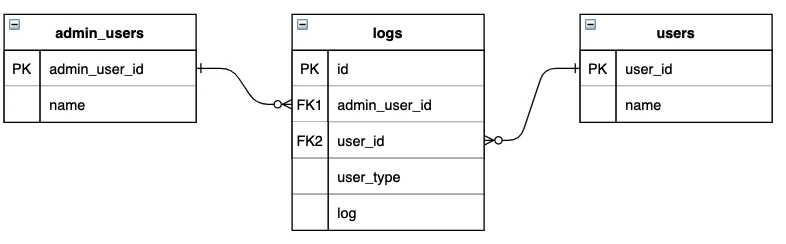
admin_users(親テーブル①)テーブル
| admin_user_id | name |
|---|---|
| 1 | 山田 |
| 2 | 佐藤 |
| 3 | 山下 |
users(親テーブル②)テーブル
| user_id | name |
|---|---|
| 1 | AAA |
| 2 | III |
| 3 | UUU |
logs(子テーブル)テーブル
| log_id | user_type | admin_user_id | user_id | log |
|---|---|---|---|---|
| 1 | admin_user | 2 | null | ユーザーの追加 |
| 2 | user | null | 1 | ログイン |
| 3 | user | null | 2 | 商品を購入 |
デメリット
①親テーブルの情報取得で問題が生じる
logsテーブルのあるusersテーブルまたは、admin_usersテーブルの情報を取得する場合は、両方の親テーブルを外部結合してクエリを実行する必要があります。
また、2つのテーブルの内の1つしかJOINされず、片方のフィールドにはNULLが入ってしまいます。
-- logsテーブルの「id = 2」を取得する場合
SELECT *
FROM logs AS l
LEFT OUTER JOIN admin_users AS a
ON a.admin_user_id = l.admin_user_id AND l.user_type = 'admin_user'
LEFT OUTER JOIN users AS u
ON u.user_id = l.user_id AND l.user_type = 'user'
WHERE l.log_id = 2;
②外部キーの宣言が出来ないため、 外部キー制約を定義できない
外部キー宣言は一つのテーブルのみ指定する必要がありますが、今回のパターンでは複数のテーブル(users,admin_users)を参照先にしているため、外部キー制約は保証できなくなってしまいます。
※ただし、フレームワークによっては(LaravelのEloquantなど)ポリモーフィック関連をサポートしています。そのような機能がある場合は上記の欠点が発生しないため、アンチパターンとはなり得ません。
解決策:別テーブルの作成
①交差テーブルの作成
対象テーブルごとにそれぞれ交差テーブルを作成する方法です。
今回の例の場合は、admin_usersテーブルとlogsテーブルの間にadmin_user_logsテーブルを、usersテーブルとlogsテーブルの間にuser_logsテーブルを追加します。
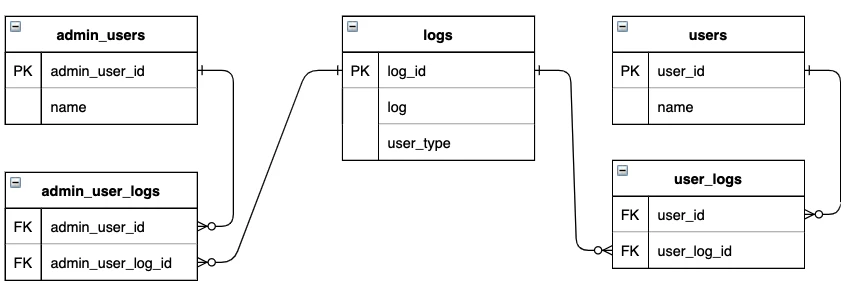
admin_user_logsテーブル
| admin_user_id | user_log_id |
|---|---|
| 1 | 2 |
user_logsテーブル
| user_id | user_log_id |
|---|---|
| 2 | 1 |
| 2 | 3 |
admin_usersテーブルとlogsテーブルの間に交差テーブルadmin_user_logs、usersテーブルとlogsテーブルの間にも交差テーブルuser_logsを作成します。
このように交差テーブルを作成することで、各親テーブル(admin_users、users)にも外部キーを定義することができるため、データの整合性を取ることができます。
また、共通の親テーブルで「parent_user_id = 2」を取得する場合は、USING句を使用できます。
SELECT *
FROM logs AS l
LEFT OUTER JOIN (
admin_user_logs INNER JOIN admin_users
USING(admin_user_id)
) USING (log_id)
LEFT OUTER JOIN (
FeatureComments INNER JOIN users
USING (user_id)
) USING (user_log_id)
WHERE l.log_id = 2;
②共通の親テーブルの作成
2つのユーザテーブルを束ねるparent_usersテーブルを作成します。

admin_usersテーブル
| id | parent_user_id | name |
|---|---|---|
| 1 | 1 | 山田 |
| 2 | 2 | 佐藤 |
| 3 | 3 | 山下 |
usersテーブル
| id | parent_user_id | name |
|---|---|---|
| 1 | 4 | AAA |
| 2 | 5 | III |
| 3 | 6 | UUU |
parent_usersテーブル
| parent_user_id |
|---|
| 1 |
| 2 |
| 3 |
| 4 |
| 5 |
| 6 |
logsテーブル
| id | parent_user_id | user_type | log |
|---|---|---|---|
| 1 | 4 | user | ログイン |
| 2 | 2 | admin_user | ユーザーの追加 |
| 3 | 6 | user | 商品を購入 |
基底テーブルを作ることで、外部キー制約を保証することが可能となります。
共通の親テーブルで「parent_user_id = 2」を取得する場合は、こちらもUSING句が使用できます。
SELECT *
FROM logs AS l
LEFT OUTER JOIN admin_users USING (parent_user_id)
LEFT OUTER JOIN users USING (parent_user_id)
WHERE l.parent_user_id = 2 ;
第7章-Multicolumn Attributes(複数列属性)
第1章-Jaywalking(信号無視)と同様に、1つのテーブルに複数の値を持つ属性の格納方法に関するアンチパターンです。
Jaywalkingとの違いは格納方法です。
- ジェイウォーク:「,」や「/」を用いて、1つの列に複数の値を格納
- マルチカラムアトリビュート:あらかじめ複数列用意し、値がない場合はNULLのままにする
例:ECサイトの取扱商品の画像を登録する場合
値が幾つになるかわからないためあらかじめ「image」列を複数作成しておき、値がある分だけ登録するようにするとします。
※他には、ユーザーの連絡先情報をテーブルに格納する場合に携帯番号、固定電話の有無、FAXの有無などにより不特定多数の同属の値が格納されることを想定すると、格納される値がいくつになるかがわからないため、あらかじめ複数「tel」列を作成しておき、値がある分だけ登録するといったケースで想定されます。
productsテーブル
| id | name | image1 | image2 | image3 | image4 |
|---|---|---|---|---|---|
| 1 | 牛肉 | meet001.png | meet002.png | meet003.png | meet004.png |
| 2 | マグロ | fish001.png | fish002.png | null | null |
| 3 | 豚肉 | meet005.png | meet001.png | null | null |
| 4 | サーモン | fish003.png | fish002.png | null | null |
デメリット
①値の検索が面倒
「image1」〜「image5」列に収納されている特定の値を検索する場合、どの列にも収納される可能性があります。
productsテーブルの「meet001.png」を持つ行を取得する場合は、方法は色々ありますが(補足4)、シンプルに行うとするとOR句を使用します。
SELECT * FROM products
WHERE image1 = 'meet001.png'
OR image2 = 'meet001.png'
OR image3 = 'meet001.png'
OR image4 = 'meet001.png'
OR image5 = 'meet001.png';
②値の追加と削除の前に確認が必要
値を追加する際には、「どのカラムが開いているか」を事前に確認する必要があります。
productsテーブルの「id = 2」に「fish004.png」を追加する場合、以下のようにSELECTで空いているimage列を確認してから、追加する必要があります。
SELECT * FROM products WHERE id = 2;
-- 上記SELECT文の結果よりimage3、image4がNULLであることが判明
UPDATE products SET image3 = 'fish004.png' WHERE id = 2;
また、上記の操作を行っている間(SELECT後、UPDATE前)に、別の開発者が更新する可能性も出てきます。
そのため値を更新する際にロックした状態で競合や上書きを防ぐ必要が出てきます。
③一意性の保証
複数ある列に重複した値は登録したくない場合でも防ぐことができません。
以下のように、同じ行の「image1」〜「image5」列に同じ値を登録できてしまいます。
INSERT INTO products (user_id, neme, image1, image2, image3, image4, image5)
VALUES (5, 'ホタテ', 'fish004.png', 'fish004.png', 'fish004.png', 'fish004.png', 'fish004.png');
④増加する値の処理
もし列を追加する場合、ALTER文を使用する必要があります。
ALTER文を実行するためには、テーブル全体をロックするなど、同時に他のクライアントから接続されていないことを保証する必要があります。
「image6」の列を追加する場合は、以下のようになります。
ALTER TABLE products ADD COLUMN iamge6 VARCHAR(20);
また、カラムの追加を行うと、今まで使用していたアプリケーション側のSQL文を編集しなければいけなくなります。
例えば、「meet001.png」の検索は以下のように書き換える必要があります。
SELECT * FROM products
WHERE image1 = 'meet001.png'
OR image2 = 'meet001.png'
OR image3 = 'meet001.png'
OR image4 = 'meet001.png'
OR image5 = 'meet001.png'
-- 以下のステートメントの追加が必要
OR image6 = 'meet001.png';
解決策:従属テーブルを作成
以下のように分けて同じ意味を持つ値は、1つの列に格納することで解決できます。
productsテーブル
| id | name |
|---|---|
| 1 | 牛肉 |
| 2 | マグロ |
| 3 | 豚肉 |
| 4 | サーモン |
imagesテーブル
| product_id | image |
|---|---|
| 1 | meet001.png |
| 1 | meet002.png |
| 1 | meet003.png |
| 1 | meet004.png |
| 2 | fish001.png |
| 2 | fish002.png |
| 3 | meet005.png |
| 3 | meet001.png |
| 4 | fish003.png |
| 4 | fish002.png |
このように設計することで、値の一意性も担保することができます。
加えて、タグが増加したとしてもカラムの上限による制限がないため、ALTER文を使用せずに追加することができます。
「meet001.png」の検索も、OR句を使用せずに以下のようなシンプルな構文で行えます。
SELECT * FROM images
INNER JOIN 'images' AS i USING (product_id)
WHERE i.image = 'meet001.png';
第8章-Metadata Tribbles(メタデータ大増殖)
行数の多いテーブルを複数のテーブルに分割したり、列を複数列に分割するアンチパターンです。
どのようなデータベースクエリでもデータの容量が増加してきた場合、パフォーマンスは低下してしまいます。
(当たり前ですが、行数が多いテーブルに対してクエリを投げるより、行数の少ないテーブルに対して行った方が早く処理を完了できます)
しかし、すべてのテーブルの行は少ない方が良いというわけではありません。
例:商品の購入履歴テーブル
使用するほど増加していくので、データを年ごとに分割しているとします。
2019_purchase_historiesテーブル
| purchase_history_id | user_id | date_purchased | product_name | quantity |
|---|---|---|---|---|
| 1 | 1 | 20191025 | fish | 3 |
2020_purchase_historiesテーブル
| purchase_history_id | user_id | date_purchased | product_name | quantity |
|---|---|---|---|---|
| 2 | 1 | 20201025 | meet | 2 |
2021_purchase_historiesテーブル
| purchase_history_id | user_id | date_purchased | product_name | quantity |
|---|---|---|---|---|
| 3 | 1 | 20211025 | vegetable | 1 |
| 4 | 2 | 20211025 | fish | 2 |
| 5 | 1 | 20211025 | meet | 10 |
デメリット
①条件によってテーブルを選択する必要がある
例ではテーブルを年ごとに分かれているため、データをする際には年によって挿入するテーブルを選択する必要があります。
例えば、2021年が終了時には、2022年になっていた際に2022_purchase_historiesテーブルを作成して、データの挿入先を切り替えるといった手間がかかってしまいます。
②データの整合性管理
自動的に日時を確認してから挿入テーブルを選択する方法がないため、CHECK制約などを設ける必要があります。
③データの同期
アプリケーション側で処理を間違えていた場合を想定します。
上記のデータにて、2021_purchase_historiesテーブルに挿入されている「id = 5」が「date_purchased = 20201025」だった場合、UPDATE文で修正する必要があります。
しかし、該当データを更新するだけでは、2021_purchase_historiesテーブルに格納されてしまいます。
修正するためには、以下のような構文で対象テーブルのデータを削除してから、別のテーブルに追加する必要があります。
DELETE FROM 2021_purchase_histories WHERE id = 5;
INSERT INTO 2020_purchase_histories (user_id, date_purchased, product_name, quantity)
VALUES (1, 20201025, meet, 10);
④一意性の保証
分割されたすべてのテーブルの間で、主キーが一意であることを保障する必要があります。
シーケンスオブジェクトをサポートするDBの場合は同一のシーケンスオブジェクトを使用できますが、サポートされていない場合は主キーを生成する為のテーブルを1つ定義しなければならなりません。
⑤テーブルをまたいだクエリの実行が面倒
例えばCOUNTを使用して、複数テーブルのそれぞれの商品数を数えるとします。
SELECT COUNT(*) FROM (
SELECT * FROM 2019_purchase_histories
UNION
SELECT * FROM 2020_purchase_histories
UNION
SELECT * FROM 2021_purchase_histories ) AS h
GROUP BY h.product_name;
時間が立つとテーブルの個数が増えてしまうため、SQL文を修正する必要が出てきます。
⑥メタデータの同期
列の追加が必要になった際に全てのテーブルに対する操作が必要になっていしまいます。
例えば「price」列を追加することとなると、新しい列はALTER文を用いて追加できます。
しかし年ごとにテーブルが分割されているため、対象テーブル全てに対して共通する列を追加する必要があります。
⑦参照整合性の管理
第6章-Polymorphic Associations(ポリモーフィック関連)でも解説しましたが、親テーブルが複数になる場合は外部キーを設定することができません。
解決策
①水平パーティショニングの使用
行を分割するいくつかのルールを定義して、分割する方法となります。
テーブル作成時にパーティション分割を行うことで、ユーザーからは1テーブルに見えますが、物理的にテーブルを分割することができます。
テーブル作成時に、以下のように設定することで水平パーティショニングを使用できます。
CREATE TABLE purchase_histories (
purchase_history_id INT PRIMARY KEY,
date_purchased DATE,
-- 他の列の設定を省略しています
) PARTITION BY HASH (YEAR(date_purchased) )
PARTITIONS 4;
最後に「PARTITIONS 4」と記述しているため、物理的なテーブル数が4つということを意味します。
データベースが4年以上を超える期間のデータを扱う場合は、どれか1つのパーティションに2年以上の期間のデータが格納されることになります。
ただし、データベースの種類によってパーティショニングの書き方が異なるため、注意が必要となります。
②垂直パーティショニングの使用
水平パーティショニングは行で分割するのに対し、垂直パーティショニングは列で分割を行います。
利用頻度の低い列や非常に桁数の多い列などの、テーブルの一部だけをパーティションへ抜き出す方法となります。
BLOB型、TEXT型といったデータを扱う列がある場合は、それらを別のテーブルとして扱ってデータを保存します。
最近のデータベースでは、自動的に別テーブルにしてくれるらしいです。
③従属テーブルの導入
7章-マルチカラムアトリビュートの解決策と同様となっています。
年ごとにテーブルの分割やカラムの追加を行わず、年の組み合わせごとに1行となるようにテーブルを定義する方法です。
purchase_historiesテーブル
| purchase_history_id | product_name | quantity |
|---|---|---|
| 1 | fish | 3 |
| 2 | meet | 2 |
| 3 | vegetable | 1 |
| 4 | fish | 2 |
| 5 | meet | 10 |
purchase_historie_datesテーブル
| purchase_history_id | date_purchased |
|---|---|
| 1 | 20191025 |
| 2 | 20201025 |
| 3 | 20211025 |
| 4 | 20211025 |
| 5 | 20211025 |
補足
補足1:単語の補足
- ツリー構造ではそれぞれを「ノード」と呼び、ノードは1つ以上の子と1つの親を持つことができます。
- 親を持たない最上位のノードを「根(ルート)」、子を持たない最下部のノードを「葉(リーフ)」といい、中間のノードは「非葉ノード」と言います。
- ツリー構造の一部で、それ自身もツリー構造となっている部分的な箇所をサブツリーと言います。
補足2:再帰クエリについて
テーブルに一時的に名前を付けることで、再帰処理(ループ処理)を実現することができます。
例えば、locationsテーブルの「id = 2(日本)」に紐付いているものを取得する場合は、WITH句を使用すると以下のような構文になります。
WITH r AS (
SELECT * FROM locations WHERE id = 2
UNION ALL
SELECT locations.* FROM locations, r WHERE locations.parent_id = r.id
)
SELECT * FROM r
補足3:LaravelでのID規約の上書きについて
Laravelの場合は、以下のようなマイグレーションファイルを実行することで、主キーを変更することができます。
<?php
class RenameTitles extends Migration
{
public function up()
{
Schema::table('titles', function (Blueprint $table) {
$table->renameColumn('id', 'title_id');
});
}
public function down()
{
Schema::dropIfExists('titles');
}
}
ただし、モデルのデフォルトのプライマリーキーが「id」となっているため、モデル側でのプライマリーキーの設定が必要となります。
<?php
protected $primaryKey = 'title_id';
「id」を変更すると都度設定が必要なため、Laravelではプライマリーキーは「id」を設定したほうが良さそうです。
補足4:特定の文字列の取得に関して
※パターンマッチでも取得できそうですが、ジェイウォークで説明したようにデータベースによって書き方が異なります。
加えて、MySQLだと、WHERE句でmregexp関数を使用して正規表現で条件検索も行うことができますが、マルチバイト文字には対応していません(ユーザー関数を入れれば一応行うことができるそうです。参考: http://www.irori.org/tool/mregexp.html )