SQLアンチパターンをまとめました。
この本では4つのパートに分けてそれぞれアンチパターンを解説しており、
- データベース論理設計のアンチパターン(1〜8章)
- データベース物理設計のアンチパターン(9〜12章)
- クエリのアンチパターン(13〜18章)
- アプリケーション開発のアンチパターン(19〜25章)
この記事では「3. クエリのアンチパターン」について記述します。
目次
第13章-Fear of the Unknown(恐怖のunknown)
第14章-Ambiguous Groups(曖昧なグループ)
第15章-Random Selection(ランダムセレクション)
第16章-Poor Man's Search Engine(貧者のサーチエンジン)
第17章-Spaghetti Query(スパゲッティクエリ)
第18章-Implicit Columns(暗黙の列)
第13章-Fear of the Unknown(恐怖のunknown)
NULLを一般値として使用する(または、一般値をNULLとして使用する)アンチパターンです。
データベースのNULLは、プログラミングのNULLとは同一ではありません。
デメリット
①計算に使用できない
例:働いた時間を記録する勤怠管理のためのwork_timesテーブル
| id | user_id | hours | date |
|---|---|---|---|
| 1 | 1 | 8 | 2021-01-10 |
| 2 | 2 | 8 | 2021-01-10 |
| 3 | 1 | 9 | 2021-01-11 |
| 4 | 2 | 9 | 2021-01-11 |
ここでhours列に休憩時間の1時間を合わせた値を取得する、以下のクエリを実行するとします。
SELECT user_id, hours + 2, date FROM work_times;
(この場合は都合が良いかもしれませんが)NULLは0と同様ではないため、hours列にNULLが存在する列は「2」にならず、NULLとなってしまいます。
また、文字列とNULLを連結する場合でもNULLになります。
②NOT句で検索されない
以下のクエリを実行すると、hours列が「8」の全ての行が返ってきます。
SELECT * FROM work_times WHERE hours = 8;
問題となるのは、NOT句を使用したクエリです。
SELECT * FROM work_times WHERE NOT (hours = 8);
多くの人が直感的に「hours = 8以外の残りの行」が取得できると考えてしまいますが、
「hours列が8以外の行」と 「hours列にNULLを含まない行」 が取得されます。
これはWHERE句の条件は、trueの場合のみ返すようになっているために起こってしまいます。
NULLを用いてしまうとtrue(またはfalse)ではなく、不明(unknown)を返却します。
そのため、以下のようにWHERE句にNULLを用いた場合でも、その条件に指定した行がNULLの値を取得することはできません。
SELECT * FROM work_times WHERE hours = NULL;
SELECT * FROM work_times WHERE NOT (hours = NULL);
③プリペアドステートメントでNULLを使用できない
プリペアードステートメント(SQLインジェクション対策のために必要な値を置換すること)のパラメータ化したSQLで、NULLは使用することができません。
SELECT * FROM work_times WHERE hours = ?;
④NULLの使用を避ける
NULLによるクエリの複雑化を避けるために、「unknown(不明)」や「inapplicable(適用不能)」などの新たに定義した値を使用する開発者もいます。
しかし、unknown = -1が「不明」の意味で設定すると、数値としての意味を持ってはいけないのに持っている状態になってしまいます。
そのためNULLの代わりに使用してしまうと、計算の際にはWHERE句などを用いて、この行を除去する必要が出てきてしまいます。
SELECT AVG ( hours ) FROM work_times WHERE hours <> -1;
解決策:NULLを一意な値として扱う
プログラミング言語の殆どはNULLは2値論理に対して、SQLではNULLが3値論理であるため、混乱してしまう原因となっています。
そのため、SQLではNULLが3値論理であることを学ぶ必要があります。
①スカラー式でのNULL
| 式 | 予想した結果 | 実際の結果 | 理由 |
|---|---|---|---|
| NULL = 0 | TRUE | NULL | NULLは0ではない |
| NULL = 12345 | FALSE | NULL | 不明な値がある値と等しいかはわからない |
| NULL <> 12345 | TRUE | NULL | 不明な値がある値と等しいかはわからない |
| NULL + 12345 | 12345 | NULL | NULLは0ではない |
| NULL ‖ 'string' | 'string' | NULL | NULLは空文字列ではない |
| NULL = NULL | TRUE | NULL | 不明な値と不明な値が等しいかどうかはわからない |
| NULL <> NULL | FALSE | NULL | 不明な値と不明な値が等しくないかどうかはわからない |
②論理式でのNULL
| 式 | 予想した結果 | 実際の結果 | 理由 |
|---|---|---|---|
| NULL AND TRUE | FALSE | NULL | NULLはFALSEではない |
| NULL AND FALSE | FALSE | FALSE | AND FALSEの真理値は全てFALSEになる |
| NULL OR FALSE | FALSE | NULL | NULLはFALSEではない |
| NULL OR TRUE | TRUE | TRUE | OR TRUEの真理値は全てTRUEになる |
| NOT (NULL) | TRUE | NULL | NULLはFALSEではない |
③NULLの検索
NULLの検索の際には、「IS NULL演算子(もしくはIS NOT NULL演算子)」を使用することで、NULLか(NULLではないか)の判定を行うことができます。
SELECT * FROM work_times WHERE hours IS NULL;
SELECT * FROM work_times WHERE hours IS NOT NULL;
また、「IS DISTINCT FROM比較演算子(もしくはIS NOT DISTINCT FROM比較演算子)」を使用することで、比較の前に「IS NULL」を記述しなくて良くなります。
SELECT * FROM work_times WHERE hours IS NULL OR hours <> 1;
-- IS DISTINCT FROMを使用(上の式と同様)
SELECT * FROM work_times WHERE hours IS DISTINCT FROM 1;
「IS DISTINCT FROM比較演算子」の挙動は以下になります。
| A | B | A = B | A IS DISTINCT FROM B |
|---|---|---|---|
| 0 | 0 | true | false |
| 0 | 1 | false | true |
| 0 | null | unknown | true |
| null | null | unknown | false |
また、「IS DISTINCT FROM比較演算子」は、プリペアドステートメントも使用できます※。
※IS DISTINCT FROM比較演算子のサポートはデータベース製品によって異なります。
サポート対象:PostgreSQL、IBM DB2、Firebird、MySQL(「<==>」がIS DISTINCT FROMと同等となっています)
サポート対象外:Oracle、Microsoft SQL Server
SELECT * FROM work_times WHERE hours IS DISTINCT FROM ?;
④列にNOT NULL制約を宣言する
その列でNULLを使用する意味がない場合は、NOT NULL制約を宣言することで、データベース側で制約を強制することができます。
基本的にNULLが入ることはない列は、NOT NULL制約を宣言すべきです。
CREATE TABLE work_times (
id INT PRIMARY KEY NOT NULL,
user_id INT UNSIGNED NOT NULL,
hours NUMERIC(9, 2) NOT NULL,
date DATE,
FOREIGN KEY (user_id) REFERENCES users (user_id)
);
⑤動的なデフォルト(COALESCE関数)
COALESCE関数を使用することで、NULLを別の値に置き換えることができます。
SELECT id, user_id, COALESCE(hours, "時間がNULLです"), date FROM work_times;
第14章-Ambiguous Groups(曖昧なグループ)
グループ内で最大値(または最小値)を持つ行を取得する際、その行のグループ化されていない列を取得する際に発生するアンチパターンです。
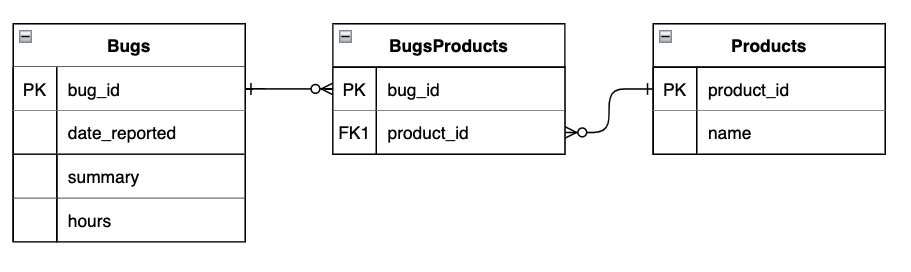
3つのテーブルを用いて直近のバグを製品ごとにまとめたテーブル(製品名、日時、バグID)を、以下のクエリで取得しようとするとします。
SELECT product_id, MAX(date_reported) AS latest, bug_id
FROM Bugs INNER JOIN BugsProducts USING (bug_id)
GROUP BY product_id;
デメリット
①エラー or 信頼性の低い結果が返ってくる
上のクエリでは、あるproduct_idに対応したbug_idには、複数の値が存在する状態となっています。
そのためbug_idが「単一値の原則」の適用外となってしまい、これらの列でグループ内のすべての行に同じ値があることを常に保証できなくなってしまいます。
単一値の原則:「SELECT句の選択リストに列挙される全ての列は、行グループごとに単一の値でなければならない」という規則
GROUP BY句で指定していない列では、単一値の原則が適応されません。
このように非グループ化列を参照してしまうと、発行対象のクエリはエラーになる(PostgreSQLやOracleなど)か、信頼性の低い値を返してしまいます(MySQLやSQliteなど)。
②SQLがクエリの意図を汲んでくれるとは限らない
「クエリが最大値を取得する時に、ついでに他の列の値もその最大値に存在する列から取得してきてくれる」と考えてしまいますが、SQLにはグループ内のどの行から取得するべきかを判断する機能は存在しません。
「date_reported」列で同じ日付でさらに最大値である場合、どちらのbug_idを取得できるのかは不明です。
また、クエリで2つの異なる集約関数を実行したときに、最大値と最小値のどちらの値に紐づいたものが取得されるか不明となります。
SELECT product_id, MAX(date_reported) AS latest, MIN(date_reported) AS earliest, bug_id
FROM Bugs INNER JOIN BugsProducts USING (bug_id)
GROUP BY product_id;
AVGやCOUNT、SUMなどの集約関数で返された値と一致する行がテーブルにない場合も同様です。
SELECT product_id, SUM(hours) AS total_project_estimate, bug_id
FROM Bugs INNER JOIN BugsProducts USING (bug_id)
GROUP BY product_id;
解決策:曖昧でない列を使用する
①関数従属性のある列のみのクエリを実行する
最も単純な解決方法は、クエリから曖昧な列を排除することです。
以下の例では最新のバグに対応するbug_idは取得できませんが、この結果でも十分なケースもあります。
SELECT product_id, MAX(purchase_date) AS latest
FROM Bugs
INNER JOIN BugsProducts USING (bug_id)
GROUP BY product_id;
②相関サブクエリを使用する
相関サブクエリ(外側のクエリの値をサブクエリ内で使用するもの)を利用することで、最新の日付を持つバグの取得を行うことができます。
以下のように、同じ製品でより新しい日付のバグを検索する相関サブクエリを実行することで、製品ごとの最新のバグを特定することができます。
SELECT bp1.product_id, b1.date_reported AS latest, b1.bug_id
FROM Bugs b1 INNER JOIN BugsProducts bp1 USING (bug_id)
WHERE NOT EXISTS
(SELECT * FROM Bugs b2 INNER JOIN BugsProducts bp2 USING (bug_id)
WHERE bp1.product_id = bp2.product_id
AND b1.date_reported < b2.date_reported);
サブクエリが結果を1つも検出しない場合に、外部クエリのバグが最新となります。
ただし、サブクエリを各行ごとに対してそれぞれ実行しているため、パフォーマンス低下の恐れがあります。
③導出テーブルを使用する
サブクエリを導出テーブルとして使用することで、product_idと各製品に対応する最新のバグレポートの日付のみの中間結果を取得できます。
その結果をJOINさせて、クエリの最終結果に製品ごとの最新日付を持つバグのみ含めるようにできます。
SELECT m.product_id, m.latest, b1.bug_id
FROM Bugs b1 INNER JOIN BugsProducts bp1 USING (bug_id)
INNER JOIN (SELECT bp2.product_id, MAX(b2.date_reported) AS latest
FROM Bugs b2 INNER JOIN BugsProducts bp2 USING (bug_id)
GROUP BY bp2.product_id) m
ON bp1.product_id = m.product_id AND b1.date_reported = m.latest;
ただし、方法についても解決法②と同様に、パフォーマンスが低下する可能性があります。
④JOINを使用する
外部結合(OUTER JOIN)を利用することで、存在しない可能性のある行に対して突き合わせ処理を実行できます。
SELECT bp1.product_id, b1.date_reported AS latest, b1.bug_id
FROM Bugs b1
INNER JOIN BugsProducts bp1
ON b1.bug_id = bp1.bug_id
LEFT OUTER JOIN (
Bugs AS b2 INNER JOIN BugsProducts AS bp2
ON b2.bug_id = bp2.bug_id
)
ON (bp1.product_id = bp2.product_id
AND (b1.date_reported < b2.date_reported
OR b1.date_reported = b2.date_reported AND b1.bug_id < b2.bug_id))
WHERE b2.bug_id IS NULL;
欠点としては可読性が低いため、仕組みの理解や保守が難しくなってしまいます。
しかし、サブクエリと比較するとパフォーマンス高いため、大量のデータに対するパフォーマンスが重要な場合に使用すべきです。
⑤他の列に対しても集約関数を使用する
他の列にも集約関数を使用することで、単一値の原則に従わせてアンチパターンを回避できます。
SELECT product_id, Max(date_reported) AS latest, Max(Bugs.bug_id) AS latest_bug_id
FROM Bugs INNER JOIN BugsProducts USING (bug_id)
GROUP BY product_id;
この方法はバグ報告が時系列順におこわなれている場合にのみ、使用できます。
⑥グループごとにすべての値を連結する
MySQLとSQLiteでは、GROUP_CONCAT関数(各グループ内のすべての値を一つに連結する)をサポートしています。
SELECT product_id, Max(date_reported) AS latest, GROUP_CONCAT(bug_id) AS bug_id_list
FROM Bugs INNER JOIN BugsProducts USING (bug_id)
GROUP BY product_id;
ただし、GROUP_CONCAT関数にはいくつか欠点があります。
- 最新日付に対応するbug_idを特定できない
- 各グループのbug_idがすべて含まれてしまう
- SQL標準に準拠していない
よってこの方法は、GROUP BYで指定されていない列で、単一値原則に違反する可能性が残っている場合に使用するべきです。
第15章-Random Selection(ランダムセレクション)
ランダムにソートを行い、その結果を取得するとパフォーマンスが低下してしまうアンチパターンです。
ランダムに結果を使用する場面としては、以下などが考えられます。
- サイトに出す広告をローテーションで表示
- データ監査のための一部データの取り出し
- コールセンターの電話のオペレーターの割当
- テストデータの生成
ランダムな行の取得の一般的な方法としては、RAND関数を使用して以下のようなクエリを実行することです。
SELECT * FROM 〇〇 ORDER BY RAND() LIMIT 1;
デメリット
①インデックスのメリットを受けることができない
RAND関数のようなソートの基準を行ごとにランダムな値を返す関数では、結果が各行の値と無関係なため、順番はソートするたびに変わってしまいます。
そのため、ランダムな関数から返された値を含むインデックスは存在しないため、インデックスを使用できません。
インデックスはソートの高速化のためには、最善策の一つです。
インデックスを使用できない場合には、データベースはクエリの全ての結果を一時的なテーブルとして保存してから、物理的に行を入れ替える作業を行います(「テーブルスキャン」と呼ばれています)。
当然ながらテーブルスキャンを行うと、インデックスによるソートよりも遅く、パフォーマンスが低下に繋がります。
②非効率
ランダムに結果を使用する場面では、基本的に必要なのは1行です。
1行のために、毎回データセット全体をソートしなければいけないのは極めて非効率です。
解決策:特定の順番に依存しない
①1〜最大値の間のランダムなキー値を選択する
この方法は主キーが1から開始されていて、かつ連続で主キーが生成されている場合に使用できます。
SELECT * FROM 〇〇 AS hoge1
INNER JOIN (
SELECT CEIL(RAND() * (SELECT MAX(id) FROM 〇〇)) AS rand_id
) AS hoge2 ON hoge1.id = hoge2.rand_id;
②欠番の穴の後にあるキー値を選択する
1〜最大キー値間に欠番があり、かつ乱数によって欠番キー値が算出されてしまう場合に、欠番の後のキー値を使用します。
SELECT * FROM 〇〇 AS hoge1
INNER JOIN (
SELECT CEIL(RAND() * (SELECT MAX(id) FROM 〇〇)) AS rand_id
) AS hoge2 ON hoge1.id >= hoge2.rand_id
ORDER BY hoge1.id
LIMIT 1;
ただし、欠番の1つ上のキー値が選択される可能性が高くなってしまい、結果が均等にはなりません。
③全てのキー値のリストを受け取り、ランダムに1つ選択する
テーブル全体のソートを回避でき、各キー値も均等に選択することができます。
<?php
// キーの値をリストを取得
$id_list = $pdo->query("SELECT id FROM 〇〇")->fetchAll(PDO::FETCH_ASSOC);
// 0~列数間でランダムな値を生成
$rand = rand(0, count($id_list) - 1);
// ランダムな値を整数型に変換
$rand_id = intval($id_list[$rand]['id']);
// $rand_idを使用して取得
$stmt = $pdo->prepare("SELECT * FROM 〇〇 WHERE id = ?");
$stmt->bindValue(1, $rand_id, PDO::PARAM_INT);
// クエリの実行
$stmt->execute();
$rand_result = $stmt->fetch();
ただし、全てのid値を取得するとリストのサイズが大きくなる可能性があり、アプリケーションメモリのリソースを超えてしまうと、エラーが発生してしまいます。
単純なクエリを使用する場合で、かつサイズがあまり大きくないものを選択するときに適しています。
④オフセットを用いてランダムに行を選択する
以下はデータセットの行数をカウントして、0〜行数間の乱数を返す方法です。
データセットにクエリを実行する際に、その数をオフセット値として使用しています。
<?php
// 乱数の取得と整数型に変換
$rand_sql = "SELECT FLOOR (RAND() * (SELECT COUNT(*) FROM 〇〇)) AS id_offset";
$result = $pdo->query($rand_sql)->fetch(PDO::FETCH_ASSOC);
$offset = intval($result['id_offset']);
// 乱数を用いて、LIMIT句で1行のみ取得
$sql = "SELECT * FROM 〇〇 LIMIT 1 OFFSET :offset";
$stmt = $pdo->prepare($sql);
$stmt->bindValue(':offset', $offset, PDO::PARAM_INT);
// クエリの実行
$stmt->execute();
$rand_result = $stmt->fetch();
LIMIT句はMySQL、PostgreSQL、SQLiteでサポートされています。
この解決策は解決策①〜③の欠点を回避しています。
キー値が連続していることが前提とせず、各行が平等に選択される必要がある場合の使用に適しています。
⑤ベンダー依存の解決策
| データベース製品 | ランダムな値を返すためのオプション |
|---|---|
| Microsoft SQL Server 2005 | TABLESAMPLE句 |
| Oracle | SAMPLE句 |
それぞれに特有の制限やオプションがあるため、使用する際には注意が必要です。
第16章-Poor Man's Search Engine(貧者のサーチエンジン)
キーワード検索でパターンマッチ述語を使用するアンチパターンです。
パターンマッチ述語の代表的なものとしては、「Like演算子」と「正規表現述語」の2つがあります。
Like演算子
0個以上の文字と一致するワイルドカード「%」が使用することができます。
例えば、Bugsテーブルのdescription列に「crash」が含まれるもの全てを取得する場合、以下のクエリになります。
SELECT * FROM Bugs WHERE description LIKE '%crash%';
正規表現述語
Like演算子と異なり、ワイルドカードは不要になります。
MySQLの場合はREGEXP関数を使用します。
SELECT * FROM Bugs WHERE description REGEXP 'crash';
デメリット
①パフォーマンスが低下してしまう
パターンマッチ述語はインデックスのメリットを受けることができないため、テーブルの全ての行のスキャンが必要となります。
そのため、パフォーマンスの低下に繋がってしまいます。
②意図しないマッチが生じてしまう
例えば「one」に部分一致する行を取得するために、以下のようなクエリを実行するとします。
SELECT * FROM Bugs WHERE description LIKE '%one%';
しかしこのようにした場合、「money」、「prone」、「lonely」などもマッチしてしまいます。
前後をスペースで区切っても、今度は前後に句読点がある場合や文末にある場合にマッチしなくなります※。
※ただし、データベース製品によっては、これらの問題を対応するための特別なパターンが用意されています。
MySQLでは以下のようなものがあります。
SELECT * FROM Bugs WHERE description REGEXP '[[:<:]]one[[:>:]]';
解決策:適切なツールを使用する
最善の方法は、SQLの代わりに専用の全文検索エンジンを使用することです。
①MySQLのフルテキストインデックス
フルテキストインデックスが使用できるのはCHAR型とVARCHAR型、TEXT型になります。
例えば、Bugsテーブルのsummary列とdescription列のフルテキストインデックスの定義は以下になります。
ALTER TABLE Bugs ADD FULLTEXT INDEX bugfts (summary, description);
インデックスに格納されたテキストからキーワード検索を行うためには、MATCH関数を用いて以下のように記述します(列名は複数指定できます)。
SELECT * FROM Bugs WHERE MATCH(summary, description) AGAINST ('crash');
-- MySQL4.1以降
SELECT * FROM Bugs WHERE MATCH(summary, description)
AGAINST ('+crash -save' IN BOOLEAN MODE);
②Oracleのテキストインデックス
いくつかのインデックスのタイプがあり、Oracleのテキストインデックスは複雑で多機能なため、4種類の概要のみをそれぞれ記載しています。
1. CONTEXT
単一のテキストの列に対してインデックスを作成します。
インデックスはデータ変更に対する一貫性が維持されませんが、定義時に「PARAMETER('SYNC(ON COMMIT)')」を追加することで自動で内容を同期してくれるようになります。
CREATE INDEX BugText ON Bugs (summary) INDEXTYPE IS CTSYS.CONTEXT;
SELECT * FROM Bugs WHERE CONTAINS(summary, 'crash') > 0;
インデックスを用いた検索にはCONTAINS演算子を使用します。
2. CTXCAT
短いテキストに特化したインデックスです。
同じテーブルの他の列と組み合わせて構造化されます。
インデックス化対象のデータがトランザクションで更新されても、インデックスの一貫性は維持されます。
CTX_DDL.CREATE_INDEX_SET('BugsCatalogSet');
CTX_DDL.CREATE_INDEX_SET('BugsCatalogSet', 'status');
CTX_DDL.CREATE_INDEX_SET('BugsCatalogSet', 'priority');
CREATE INDEX BugsCatalog ON Bugs(summary) INDEXTYPE IS CTXSYS.CTXCAT PARAMETERS('BugsCatalogSet');
SELECT * FROM Bugs WHERE CATSARCH(summary, '(crash save)', 'status = "NEW"') > 0;
CATSARCH演算子は検索するテキスト列、検索条件、構造化条件式を指定します。
3. CTXXPATH
XMLドキュメントを検索する用途に特化したインデックスです。
CREATE INDEX BugTestXml ON Bugs(testoutput) INDEXTYPE IS CTXSYS.CTXXPATH;
SELECT * FROM Bugs WHERE existsNode('testsuite/test/[@status="fail"]') > 0;
検索にはexistsNode関数を使用します。
4. CTXRULE
大量の文書解析ルールを設計し、分類結果を確認できるインデックスです。
③Microsoft SQL Serverでの全文検索
CONTAINS述語などでクエリ検索が行えます。
-- 最初に全文検索機能を有効化し、データベースにカタログを定義
EXEC sp_fulltext_database 'enable'
EXEC sp_fulltext_catalog 'BugsCatalog', 'create'
-- フルテキストインデックスを定義し、列追加後に有効化
EXEC sp_fulltext_table 'Bugs', 'create', 'BugsCatalog', 'bug_id'
EXEC sp_fulltext_column 'Bugs', 'summary', 'add', '2057'
EXEC sp_fulltext_column 'Bugs', 'description', 'add', '2057'
EXEC sp_fulltext_table 'Bugs', 'active'
-- インデックスの生成プロセスの開始
EXEC sp_fulltext_table 'Bugs', 'start_change_tracking'
EXEC sp_fulltext_table 'Bugs', 'start_change_updateindex'
EXEC sp_fulltext_table 'Bugs', 'start_full'
-- 上記の処理が完了後にCONTAINS述語が使用可能
SELECT * FROM Bugs WHERE CONTAINS(summary, 'crash');
④PostgreSQLでのテキスト検索
文書を検索可能な語要素に変換してパターン検索することができます。
パフォーマンス最適化のために、オリジナルのテキスト形式と特別なデータ型「TSVECTOR」を用いてコンテンツを収納する必要があります。
CREATE TABLE Bugs (
bug_id SERIAL PRIMARY KEY,
summary VARCHAR(80),
description TEXT,
ts_bugtext TSVECTOR
);
-- TSVECTOR列の同期のトリガー設定
CREATE TRIGGER ts_bugtext BEFORE INSERT OR UPDATE ON Bugs FOR EACH ROW EXECUTE PROCEDURE
tsvector_update_trigger(ts_bugtext, 'pg_catalog.english', summary, description);
-- 汎用転置インデックスの作成
CREATE INDEX bugs_ts ON Bugs USING GIN(ts_bugtext);
-- 上記の処理が完了後に@@演算子での検索が可能
SELECT * FROM Bugs WHERE ts_bugtext @@ to_tsqery('crash');
⑤SQLiteでの全文検索(FTS)
SQLiteの拡張機能のFTSを使用することで、検索可能なテキストを専用の仮想テーブルに格納することができます。
-- FTSの有効化
TCC += -DSQLITE_CORE = 1
TCC += -DSQLITE_ENABLE_FTS3 = 1
-- 仮想テーブルの作成
CREATE VIRTUAL TABLE BugsText USING fts3(summary, description);
-- コピー元テーブルの行と関連付け
INSERT INTO BugsText (docid, summary, description)
SELECT bug_id, summary, description FROM Bugs;
-- 上記の処理が完了後にMATCHで検索できる
SELECT b.* FROM BugsText t INNER JOIN Bugs b ON t.docid = b.bug_id WHERE BugText MATCH 'crash';
⑥サードパーティーのサーチエンジン
データベース製品独自の機能に依存せずにテキストの全文検索を行いたい場合は、SQLデータベースから独立して動作する検索エンジンを利用することができます。
代表的なものとして、「Sphinx Serach」や「Apache Lucene」等が挙げられます。
- Sphinx Serach
- MySQLやPostgreSQLとの連携が行いやすく、インデックスの作成と検索が高速で、分散クエリもサポートしている
- 高いスケーラビリティが要求されて、更新頻度が低いデータに対して適している
- Apache Lucene
- Javaアプリケーション向けの検索エンジン(他の言語向けのプロジェクトも存在)
- テキストドキュメントの集合に対して、独自形式のインデックスを構築する
- インデックス作成元と同期しないため、列の挿入や更新には変更を都度適用する必要がある
第17章-Spaghetti Query(スパゲッティクエリ)
複雑な問題をワンステップで解決しようとして、解読や修正が困難なクエリを作成してしまうアンチパターンです。
例えば、投稿サイトの管理側で以下の機能を、SQLクエリの数を減らすために1つのクエリで実現しようとします。
- 取り扱っている製品数
- バグを修正した開発者数
- 開発者一人あたりの平均バグの修正数
- 修正したバグの中で顧客から報告されたバグ数
SELECT COUNT(bp.product_id) AS how_many_products,
COUNT(dev.account_id) AS how_many_developers,
COUNT(b.bug_id)/COUNT(dev.account_id) AS avg_bugs_per_developer,
COUNT(cust.account_id) AS how_many_customers
FROM Bugs b INNER JOIN BugsProducts bp ON b.bug_id = bp.bug_id
INNER JOIN Accounts dev ON b.assigned_to = dev.account_id
INNER JOIN Accounts cust ON b.reported_by = cust.account_id
WHERE cust.email = NOT LIKE '%example.com'
GROUP BY bp.product_id;
デメリット:意図に反した結果が得られてしまう
バグデータベースに、製品別の修正済みバグ数と未修正済みバグ数を問い合わせるために以下のクエリを実行するとします。
SELECT p.product_id,
COUNT(f.bug_id) AS count_fixed,
COUNT(o.bug_id) AS count_open
FROM BugsProducts p
INNER JOIN Bugs f ON p.bug_id = f.bug_id AND f.status = 'FIXED'
INNER JOIN BugsProducts p2 USING (product_id)
INNER JOIN Bugs o ON p2.bug_id = o.bug_id AND o.status = 'OPEN'
WHERE p.product_id = 1
GROUP BY p.product_id;
実際の結果とクエリの結果が異なってしまいます。
| product_id | count_fixed | count_open | |
|---|---|---|---|
| 実際の結果 | 1 | 11 | 7 |
| クエリの結果 | 1 | 77 | 77 |
これは、BugsProductsテーブルがBugsテーブルの二つの部分集合と結合され、結果としてこれらの2つの部分集合の「デカルト積」が生じたためです。
そのため「count_fixed」と「count_open」の結果が、11x7となってしまいました。
このように一つのクエリで二つのタスクを実現使用とすると、意図しないデカルト積が生じてしまう可能性があります。
他にもクエリの記述や修正、デバッグが困難になってしまったり、実行時のコストが上がってしまったりすることもあります。
解決策: 分割統治を行う
①ワンステップずつ行う
意図しないデカルト積が生じているテーブル間に論理的な結合条件が見つからない場合は、単に条件がそもそも存在しない可能性もあります。
デカルト積を避けるためには、幾つかのクエリに分割するのが効果的です。
他にも分割することでメンテナンスが楽になり、さらに可読性が高く実行コストが低くなるメリットがあります。
-- 修正済みバグ数の取得
SELECT p.product_id, COUNT(f.bug_id) AS count_fixed
FROM BugsProducts p
LEFT OUTER JOIN Bugs f ON p.bug_id = f.bug_id AND f.status = 'FIXED'
WHERE p.product_id = 1
GROUP BY p.product_id;
-- 未修正済みバグ数の取得
SELECT p.product_id, COUNT(o.bug_id) AS count_open
FROM BugsProducts p
LEFT OUTER JOIN Bugs o ON p.bug_id = o.bug_id AND o.status = 'OPEN'
WHERE p.product_id = 1
GROUP BY p.product_id;
②UNIONを用いる
複数のクエリの結果は、UNIONによって一つにまとめることができます。
(SELECT p.product_id, 'FIXED' AS status, COUNT(f.bug_id) AS bug_count
FROM BugsProducts p
LEFT OUTER JOIN Bugs f ON p.bug_id = f.bug_id AND f.status = 'FIXED'
WHERE p.product_id = 1
GROUP BY p.product_id)
UNION ALL
(SELECT p.product_id, 'OPEN' AS status, COUNT(o.bug_id) AS bug_count
FROM BugsProducts p
LEFT OUTER JOIN Bugs o ON p.bug_id = o.bug_id AND o.status = 'OPEN'
WHERE p.product_id = 1
GROUP BY p.product_id)
ORDER BY bug_count DESC;
このように記述すると、各サブクエリの結果を合わせたものがクエリの結果として出力されます。
(UNIONは、両方のサブクエリの列に互換性があるときにのみ使用が可能です。)
③問題を解決する
もともと欲しかった結果は以下で、最善の解決策は、これらのタスクを分割して処理することです。
- 取り扱っている製品数
- バグを修正した開発者数
- 開発者一人あたりの平均バグの修正数
- 修正したバグの中で顧客から報告されたバグ数
-- 取り扱っている製品数
SELECT COUNT(*) AS how_many_products
FROM Products;
-- バグを修正した開発者数
SELECT COUNT(DISTINCT assigned_to) aAS how_many_developers
FROM Bugs
WHERE status = 'FIXED';
-- 開発者一人あたりの平均バグの修正数
SELECT AVG(bugs_per_developer) AS average_bugs_per_developer
FROM (SELECT dev.account_id, COUNT(*) AS bugs_per_developer
FROM Bugs b INNER JOIN Accounts dev
ON b.assigned_to = dev.account_id
WHERE b.status = 'FIXED'
GROUP BY dev.account_id) t;
-- 修正したバグの中で顧客から報告されたバグ数
SELECT COUNT(*) AS how_many_customer_bugs
FROM Bugs b INNER JOIN Accounts cust ON b.reported_by = cust.account_id
WHERE b.status = 'FIXED' AND cust.email NOT LIKE '%@example.com';
第18章-Implicit Columns(暗黙の列)
暗黙的な列指定を不適切に使用するアンチパターンです。
暗黙的な列指定というのは * (ワイルドカード)などを示します。
アスタリスク(*)はすべての列を意味するため、カラム名のリストは明示的ではなく暗黙的に指定されます。
この機能を用いることで簡潔に書くことができるため、可読性が高くなることにも繋がります。
-- カラム名を指定して取得(SELECT)
SELECT bug_id, date_reported, summary, description, resolution, reported_by, assigned_to, verified_by, status, priority, hours
FROM Bugs;
-- ワイルドカードを使用して取得(SELECT)
SELECT * FROM Bugs;
-- カラム名を指定して取得(INSERT)
INSERT INTO Accounts (account_id, account_name, first_name, last_name,email, password_hash, portrait_image, hourly_rate)
VALUES (DEFAULT, 'bkarwin', 'Bill', 'karwin', 'bill@example.com', SHA2('xyzzy', 256), NULL, 49.95);
-- ワイルドカードを使用して取得(INSERT)
INSERT INTO Accounts VALUES (DEFAULT,' bkarwin', 'Bill', 'karwin', 'bill@example.com', SHA2('xyzzy', 256), NULL, 49.95);
デメリット
①リファクタリングの際に様々な問題が生じる
例えば、Bugsテーブルに新たにdate_due列を加えるとします。その場合、Bugsテーブルの列数は12個になってしまいます。
ALTER TABLE Bugs ADD date_due DATE;
列数が増えたため、ワイルドカードを用いたINSERTのクエリがエラーになってしまいます。
-- ワイルドカードを使用して取得(INSERT)
INSERT INTO Accounts VALUES (DEFAULT,'bkarwin', 'Bill', 'karwin', 'bill@example.com', SHA2('xyzzy', 256), NULL, 49.95);
暗黙的な列を使ったINSERT文では、テーブルに列が定義されている順番と同じ順番で、すべての列に値を指定する必要があります。
列の定義を変更した場合、エラーになるか誤った列に値が格納されてしまう可能性が出てきます。
②パフォーマンスとスケーラビリティ(拡張性)の低下
ワイルドカードを使用すると、クエリが多くの列をフェッチするようになります。
アプリケーション側で使用していない値もワイルドカードで取得、挿入していると、その分の多くのデータの受け渡しがデータベースとの間で行なわれてしまいます。
本番稼働中のアプリケーションでは、多くのクエリを同時に実行することがあり、これらは同じネットワーク帯域幅を利用します。
そのため、数千行を返すクエリを100個も同時に実行すれば、帯域幅がいっぱいになってしまう可能性があります。
解決策:列名を明示的に指定する
できるだけ、ワイルドカードや暗黙的な列指定を使わずに、必要な列名は明示的に指定するようにします。
ワイルドカードを使用しないと以下のメリットがあります。
- テーブル定義の列の順番が変更されても、結果の列の位置は変更されない
- ALTER文などで列が加えられた場合でも、クエリ結果に影響はない
- テーブルから列が削除された場合、クエリが実行されるとエラーが返ってくる