はじめに
この記事では, 私がインターン先で取り組んだTVCMの広告効果検証ついて紹介させていただきます.
広告を出稿した際に, その広告にどの程度効果があったのかを検証することは, 今後の広告施策を考える上で非常に重要なことだと考えられます. しかし, web広告などに比べてTVCMでは, どんなユーザーがどの広告経由でコンバージョンしたかといった詳細な情報を取得することがメディアの性質上基本的には出来ません. そのため, 因果推論の分野でよく利用される傾向スコアなどのユーザー属性に基づく指標を利用した, マッチングやIPW(逆確率重み付け)などによる効果推定を行うことが通常は困難です.1
今回は, このような取得できるデータが限られた状況でもなんとか広告効果を推定したいというモチベーションから, DID(差の差分法)とCausalImpactを利用して広告効果の推定を行いました. より具体的には, TVCMによる宣伝を行った自社アプリのダウンロードログデータに対してそれぞれの手法を適用し, TVCMに自社アプリのダウンロード件数を増加させる広告効果がどのくらいあったのかについての分析・検証を行いました.
目次
- 使用データについて
- DIDとは
- DIDを利用した広告効果推定
- CausalImpactとは
- CausalImpactを利用した広告効果推定
- おわりに
使用データについて
今回使用するデータは, 自社アプリの日別のダウンロード件数を記録したログデータであり, データの詳細は次のようになっています.
※実際のダウンロードログデータを公開する事は出来ないため, この記事では擬似データを使用しています.
# 使用ライブラリ
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
import datetime
# データの読み込み
df = pd.read_csv("test.csv")
# "date"をdatetime型に変換
df["date"] = pd.to_datetime(df["date"])
# データ確認
df.head()
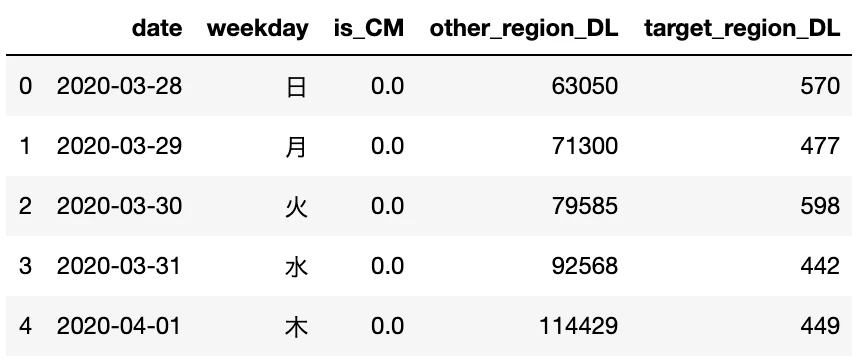
【データ詳細】
date : 日付
weekday : 曜日
is_CM : CM放映前(0), CM放映後(1)
other_region_DL : CMが放映されていない地域のDL総数(→複数の地域を含むデータ)
target_region_DL : CMが放映された地域のDL総数(→特定の1つの地域のデータ)
TVCMが放映された地域(target_region_DL)とそれ以外の地域(other_region_DL)それぞれのDL件数の推移をグラフで確認すると以下のようになっています.
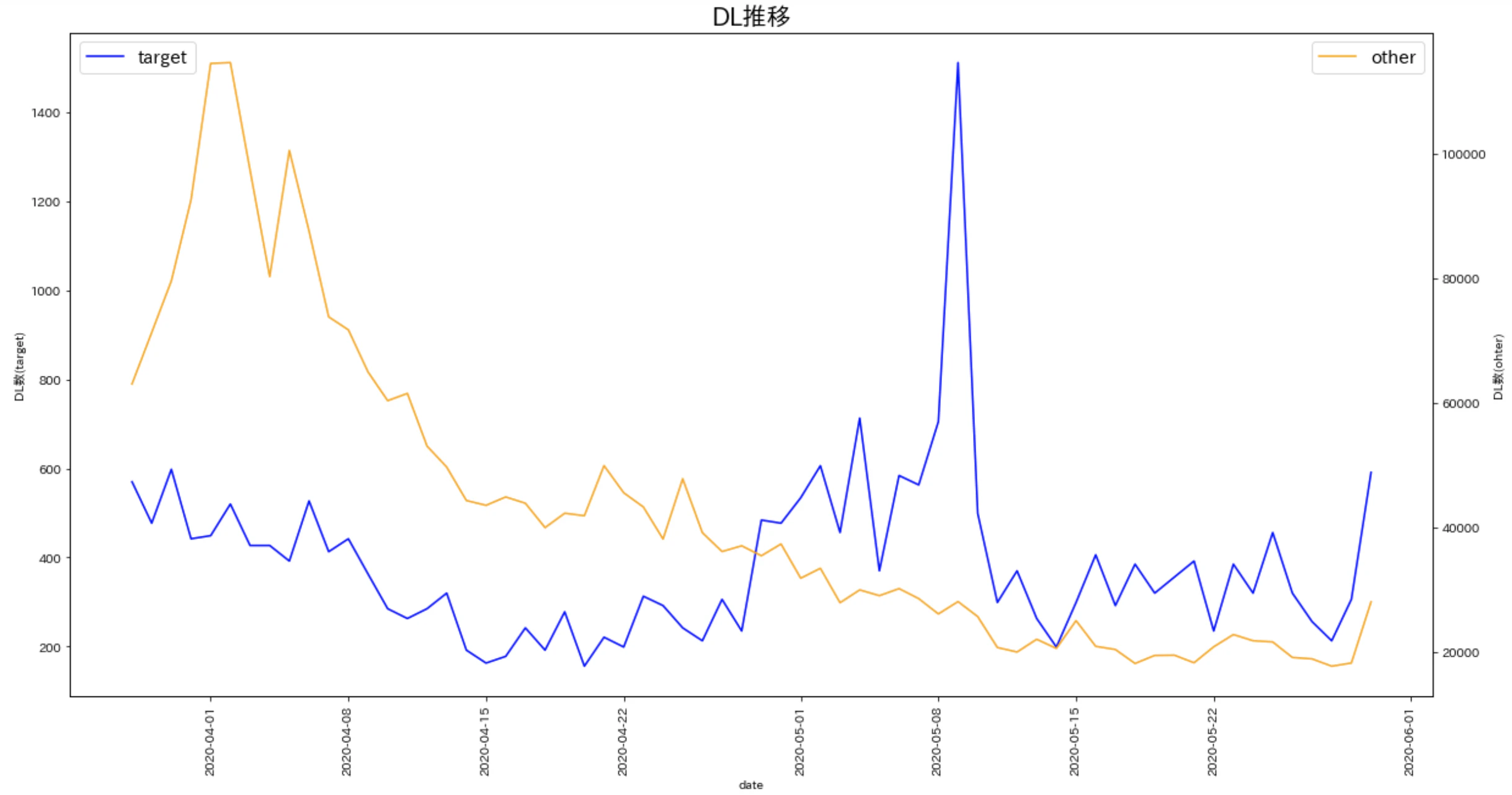
表やグラフからもわかるように, target_region_DLに比べてother_region_DLの方が全体的に大きい値になっていますが, これはtarget_region_DLがCMの放映を行った特定の1つの地域のDL数のデータを表しているのに対し, other_region_DLはCMの放映をしていない複数の地域のDL数を合算したデータを表しているためです.
DIDとは
効果検証を行う手法の中には, DID(差の差分法, DD)と呼ばれるある時期から介入を始め, その開始時期の前後の比較で効果を考える手法があります. あるタイミングから介入がスタートする場面としては今回のような「特定の地域における広告の放映」や, 他にも「特定の店舗での価格の変更」, 「特定の県や地区での政策実施」などが挙げられます. DIDはこのような状況で, 介入が行われるグループとそうでないグループの介入が行われる前後の情報を利用して介入効果を推定します[1].
集計による効果検証の問題点
例えば, CMが放映された地域のDL総数を次のように介入の前後で集計し, 単純に前後比較を行った結果を広告効果とした場合, どのようなことが問題になるでしょうか?
# 介入前
df_before = df[df["is_CM"]==0]
# 介入後
df_after = df[df["is_CM"]==1]
# 広告効果 = 介入後のDL総数 - 介入前DL総数
CM_effect = df_after.target_region_DL.sum() - df_before.target_region_DL.sum()
print(f"広告効果: {CM_effect}")
# >> 広告効果: 3543
同一地域のサンプルで前後比較を行っているため一見セレクションバイアスが存在しないように見えますが, この結果にはタイミングによるセレクションバイアスが発生している可能性があります. つまり, 前後比較で広告効果が**+3543DLという結果が今回のように得られたとしても, 実はそもそもDL数は上昇トレンドでTVCMを放映しなくても同じようにDL数が増加する状況だった, という可能性を否定できません. よって, 同じ地域での前後比較をした場合, その差分には本来の広告効果の他にも時間を通じた自然な変化(トレンド)が含まれていることになります**.
他にも, 介入を受けた地域と受けていない地域のDL数を比較するという集計も考えられますが, この場合は別々の地域のDL数を比較していることになるので地域によるセレクションバイアスが発生します. 特に今回のデータ場合は, CMを放映した地域数よりも放映していない地域数の方が圧倒的に多く, 介入前の段階のDL数に大きな違いがあることなどからも単純な地域の比較を広告効果とすることが問題なのは明らかでしょう.
では, タイミングによるセレクションバイアスと地域によるセレクションバイアスを排除して妥当な広告効果を推定するためにはどうしたらいいでしょうか. ここでDIDの考え方が登場します.
DIDのアイデア
DIDでは観測されている「DL数($Y_{t,i})$)」を次のような 「地域固有の効果($Area_i$)」, 「時間による効果($Time_t$)」, 「TVCMの広告効果($τ$)」に分解して表すことができると考えます.
Y_{after,treat} = Area_{treat} + Time_{after}+τ \\
Y_{before,treat} = Area_{treat} + Time_{before}\\
Y_{after,control} = Area_{control} + Time_{after}\\
Y_{before,control} = Area_{control} + Time_{before}
添字の$i$($control$または$treat$)は介入の有無, つまりTVCMを放映した地域かそうでないかを表していて, $Area_{control}$, $Area_{treat}$はTVCMを放映した地域とそうでない地域それぞれの時間で変化しない地域固有の効果を表します.2 また, 添字$t$($before$または$after$)は介入時期を表していて, $Time_{before}$と$Time_{after}$は地域によって変化しない時間による効果を表します.3
そしてこの時, 介入効果(TVCMの広告効果)$τ$ は,
(Y_{after,treat}-Y_{before,treat}) - (Y_{after,control}-Y_{before,control})\\
= (Time_{after}-Time_{before}+τ)-(Time_{after}-Time_{before})\\
= τ
によって求めることができます. それぞれの地域の差分に対する差分をとっているとことから**DID(Difference in Difference: 差の差分法)**と呼ばれています.
このように地域による比較だけでなく同時に介入前後の時期の比較を行うことにより, ユーザーに関する詳細な情報が得られず, 介入が行われた後の期間のデータでセレクションバイアスをうまく減らせない際にも, よりバイアスの少ない分析結果を得ることが期待できます.
DIDを利用する際の注意点(平行トレンド仮定)
DIDを行う際には平行トレンド仮定と呼ばれる仮定が満たされている必要があります. 平行トレンド仮定とは, 介入群と非介入群の目的変数の時間を通じた変化, いわゆるトレンドが同一であるという仮定です.
しかし, 平行トレンド仮定は「介入グループの介入されなかった場合」という実際には観測されることのない現象に対する仮定であるため, 厳密に平行トレンド仮定が満たされているのかを検証することは難しく, 多くのケースでその判断は, 分析者がデータを生み出した地域や現象についてどのような解釈をしているかに依存することになるようです.
この辺りの内容についてより詳しい説明を知りたい方は, [1] 効果検証入門や[2] 調査観察データの統計科学などが非常に参考になるかと思います.
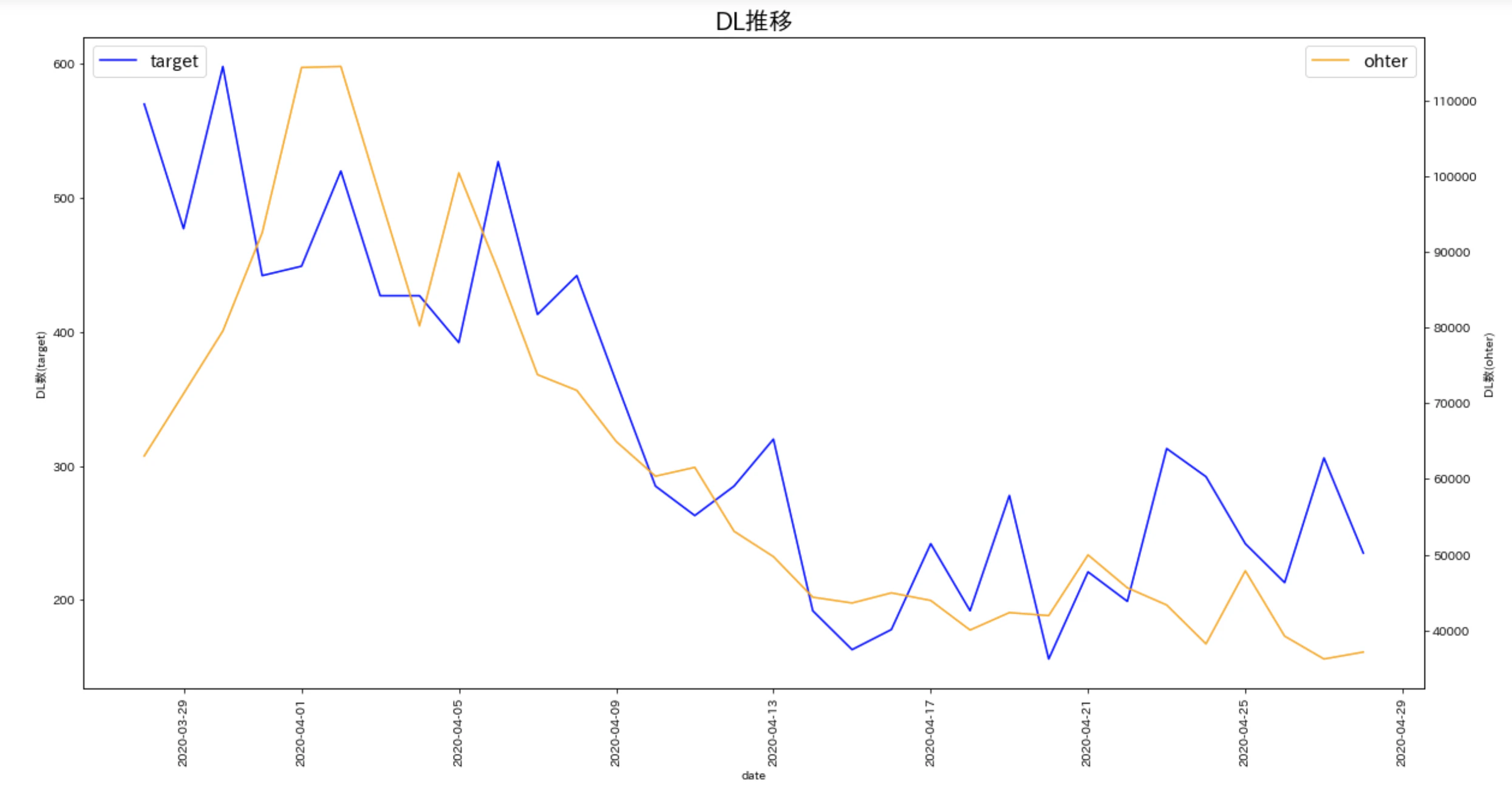
今回は, 介入前の期間でそれぞれの地域のDL数の推移を確認したところ, 次のグラフのように概ね同じ推移をしていたため平行トレンドが成り立っているとして話を進めています.
DIDを利用した広告効果推定
それでは実際に, DIDを利用してTVCMの広告効果を推定してみます.
# other_region_DLの差分
Y_after_control = df_after["other_region_DL"].sum()
Y_before_control = df_before["other_region_DL"].sum()
diff_other_region = Y_after_control-Y_before_control
gap_rate_other_region = ((Y_after_control-Y_before_control)/Y_before_control)*100
print(f"other_region_DLの差分: {diff_other_region}")
print(str(gap_rate_other_region)+"%")
# > other_region_DLの差分: -1194482
# > -60.47569189891977%
TVCMを放映していない地域(対照群)の差分の結果から, トレンドとしてはDL数が-1194482件という結果が得られました. しかしこの時, 平行トレンド仮定として, TVCMを放映した地域でも同じように-1194482件だと仮定するのは, 比較している対象の基準となるDL数が大きく違うことから適切でないと考えられます.
よってここでは減少したDL数を割合に直し, TVCMを放映した地域でも約60.5%DL数が減少するという平行トレンド仮定に基づいて分析を行います.
# target_region_DLの差分
Y_after_treat = df_after["target_region_DL"].sum()
Y_before_treat = df_before["target_region_DL"].sum()
diff_target_region = Y_after_treat-Y_before_treat
gap_rate_target_region = ((Y_after_treat-Y_before_treat)/Y_before_treat)*100
print(f"target_region_DLの差分: {diff_target_region}")
print(str(gap_rate_target_region)+"%")
# > target_region_DLの差分: 3543
# > 33.35530032009038%
同様の手順で TVCMを放映した地域(介入群)に対する差分を計算したところ, 約33.4%のDL数が上昇するという結果が得られました.
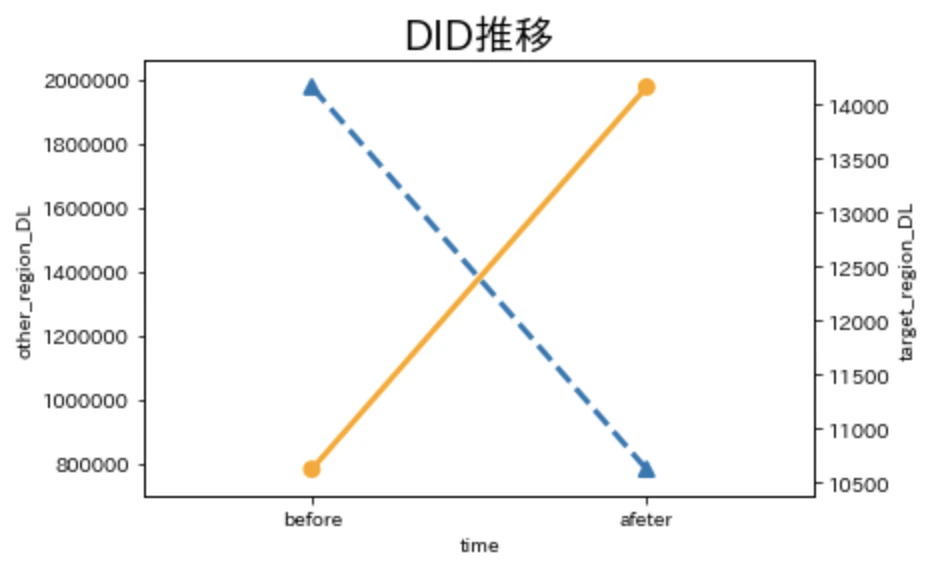
DL件数の変化をまとめると次のようになります.

また, 結果をプロットすると次のようになります. 青がTVCMを放映していない地域のDL推移, オレンジがTVCMを放映した地域のDL推移を表しています.
実際にDIDの計算を割合で行うと次のようになります.
33.4 - (-60.5) = 93.9
つまり, TVCMには**+93.9%程のDL数を増加する広告効果があった**という結果になり, DL数に直すと
10622 × 0.936 = 9942.2
なので, 約9942件ほどのDL数増加がTVCMによってもたらされたという推定結果になりました.4
CausalImpactとは
続いてCausalImpactでも広告効果の推定を行います. CausalImpactのライブラリの中では, Bayesian Structural Time Series Modelと呼ばれる状態空間モデルの一種が利用されているようですが, モデルの中身を説明できるほど詳細な理解ができていないため, ここではモデルの基本的なアイデアと使い方について紹介させていただきます.
大まかなアイデアとしては介入群の目的変数Yの反実仮想を, 様々な種類の変数Xを用いて予測する時系列モデルを作成し, 「観測された目的変数」と「予測された目的変数の反実仮想」との差分を介入効果とするというものです. 今回のTVCMの放映のケースであれば, 「CMが放映された地域で, もし仮にCMが放映されなかったらどのようなDLログになったか」をTVCMが放映されなかった地域のDLログから予測し, 実際のDLログと予測されたDLログの差分を取ることで広告効果を推定します.
CausalImpactを利用した広告効果推定
それでは, 実際にCausalImpactのライブラリを使用して広告効果の推定を行います. DIDでは介入前・介入後の2時点の比較で広告効果推定を行いましたが, CausalImpactではTVCMを放映した地域でもし仮にCMが放映されなかった場合のDL件数(反実仮想)を日別に予測して, 実測との差分を広告効果としています.
# ライブラリのインストール
pip install causalimpact
# CausalImpactのライブラリのインポート
from causalimpact import CausalImpact
# CausalImpactを実行する際、わかりやすいように日付データをindexに指定する
df = df.set_index('date')
# 入力するデータだけに絞る
df = df[["other_region_DL","target_region_DL"]]
# カラムの入れ替え(1列目を予測したい目的変数にし, 2列目以降を説明変数(共変量)にする)
df = df.reindex(columns=["target_region_DL","other_region_DL"])
# TVCM放送前と放映後を指定する
pre_period = ['2020-03-28', '2020-04-28']#TVCM放映開始前
post_period = ['2020-04-29', '2020-05-30']#TVCM放映開始後
# CausalImpactの実行
ci = CausalImpact(df, pre_period, post_period)
ci.plot(figsize=(22, 20))
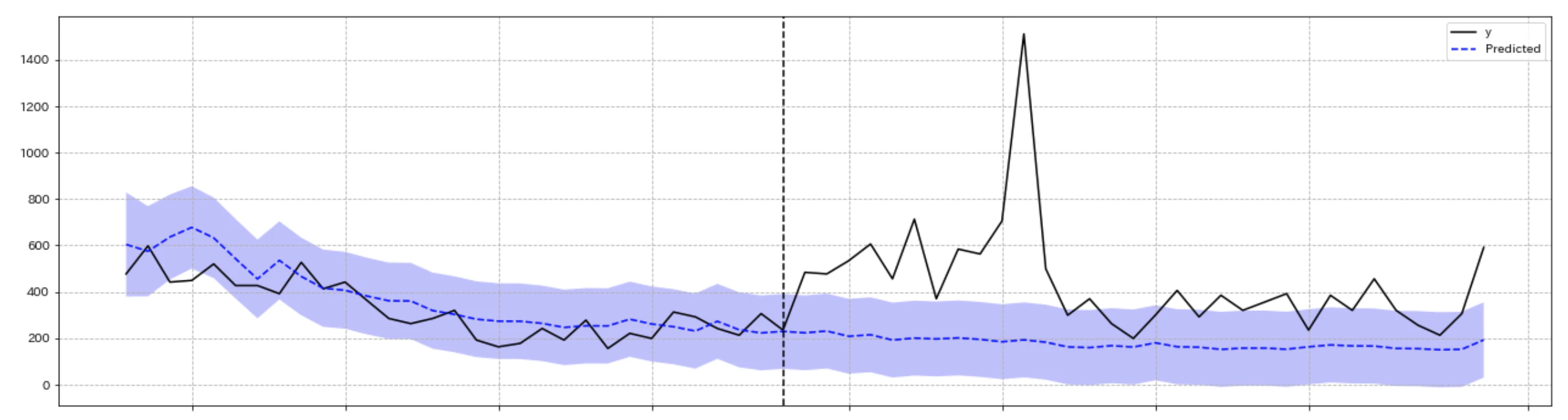
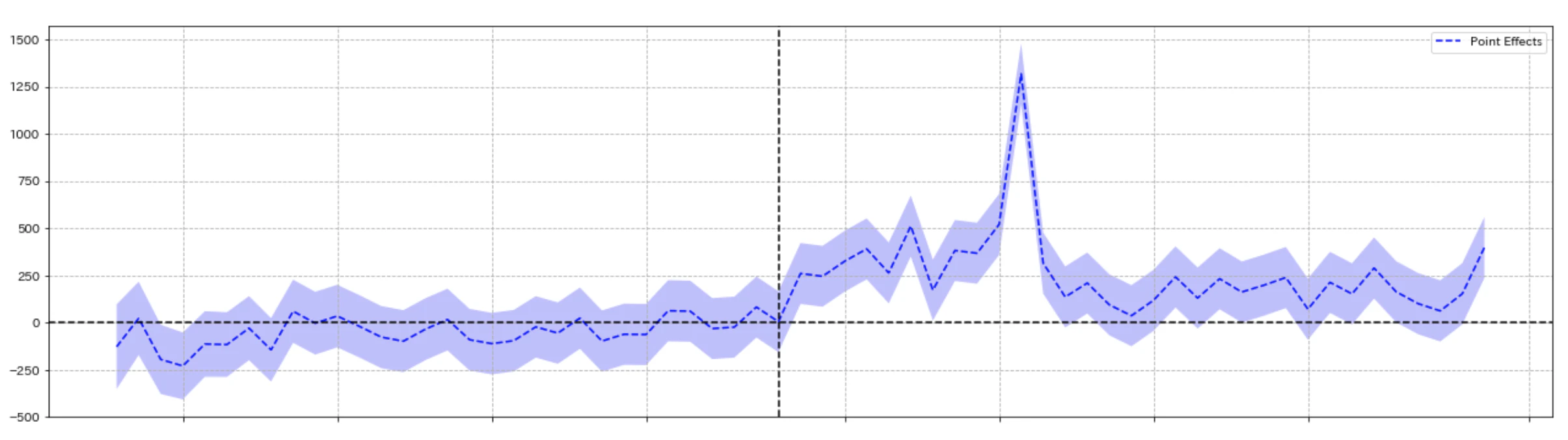
以下が推定結果を表した図になります. 上段の図が「TVCMを放映した地域の日別DL件数推移(黒線)」と, 反実仮想である「もし仮にCMが放映されなかった場合の日別DL件数推移(青線)」を表していて, 中段の図がその差分, つまり日別の広告効果の推移を表しています. そして下段がその広告効果の累積和で, トータルどの程度広告効果があったかを表しています.5また, それぞれの図の中心にある垂直の点線がTVCMが放映され始めたタイミングを表しています.
【実測値と予測値】
【実測値と予測値との差分=広告効果】
【累積の広告効果】
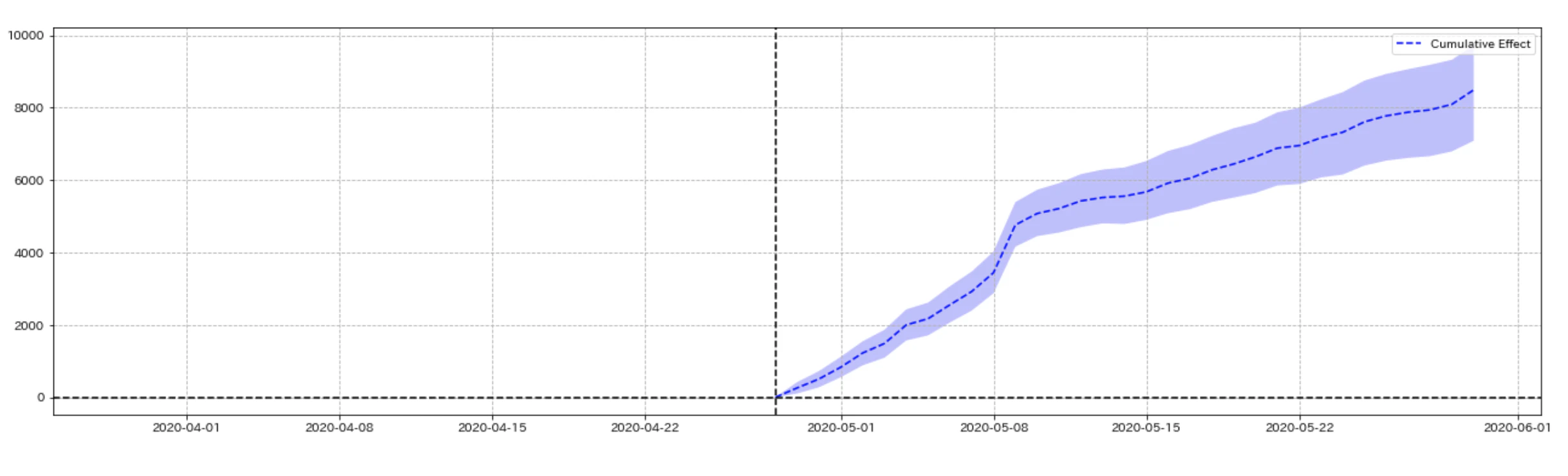
上段の図のTVCMが放映されるまでの期間の予測と実測を見ると, そこまで大きな誤差が無く予測が上手くいっていることがわかります. さらに, 下段の図を見ると,累計で約+8491件ほどのDL数の増加が広告によってもたらされたことを示しています. また, 累積広告効果の95%ベイズ信頼区間は7087.2~9719.18でした. DIDの推定結果がおよそ9942だったので, DIDに比べると少し少ない推定結果となりましたが, 概ね似たような結果であることがわかります.
おわりに
この記事では, DIDとCausalImpactを利用してTVCMの広告効果推定に取り組みました. 結果として, どちらの手法を利用した場合でも概ね同程度のDL数を増加させる広告効果があったという結果が得られました. 実際に事業会社のデータを利用してこのような広告効果検証を行える機会はなかなか無いと思うので, メンターの方やインターン先には非常に感謝しています.
また, 手法の理解や実装などが間違っていましたらご指摘いただけると幸いです.
参考文献
[1] 安井 翔太, 効果検証入門 , 技術評論社, 2020.
[2] 星野 崇宏, 調査観察データの統計科学, 岩波書店, 2009.
[3] Python版CausalImpactを用いたTVCMの効果検証(https://www.lifull.blog/entry/2020/04/20/114200)