こんにちは!私のような AI(大規模言語モデル)のベースにもなっている非常に重要なアーキテクチャ「Transformer」について解説します。
2017年に Google の研究チームが発表した論文『Attention Is All You Need』で登場して以来、Transformer は自然言語処理(NLP)の常識を覆し、現在の ChatGPT(GPTシリーズ)や BERT といった LLM の基盤となっています。
今回は、その画期的な仕組みの全体像をざっくりと把握していきましょう。
Transformer の何がすごかったのか?
Transformer 以前の自然言語処理では、RNN(再帰型ニューラルネットワーク)や LSTM といった「データを系列順(順番)に処理する」モデルが主流でした。しかし、これらには以下の弱点がありました。
- 計算の並列化が難しい:前から順番に処理しないといけないため、GPU の強みを活かしきれない。
- 長期依存性の問題:長い文章だと、過去(文の最初の方)の文脈を忘れやすい。
論文のタイトル通り、Transformer は RNN や CNN を一切使わず、「Attention(注意機構)」のみでネットワークを構築することで、これらの問題を一挙に解決しました。シーケンスを並列に処理できるため、学習スピードと精度が飛躍的に向上したのです。
Transformer を構成する4つの重要要素
Transformer のアーキテクチャは、大きく分けて「全体構造」と「3つのコアメカニズム」から成り立っています。
1. 全体構造:Encoder(エンコーダ)と Decoder(デコーダ)
オリジナルの Transformer は機械翻訳のタスクで提案されたため、2層構造になっています。
- Encoder: 入力された文章(例:英語)を読み込み、文脈を理解して特徴量ベクトルに変換する。
- Decoder: Encoder から受け取った情報と、これまで生成した単語の情報を元に、次に来るべき単語(例:日本語)を予測・生成する。
Note: その後、Encoder のみをベースに発展したのが読解の専門家「BERT」、Decoder のみをベースに巨大化したのが**文章生成の天才「GPT」です。
2. コアメカニズム①:Self-Attention(自己注意機構)
Transformer の心臓部です。入力された文の中の「どの単語が、他のどの単語と強く関連しているか」を計算します。
例えば、「The animal didn't cross the street because it was too tired」という文における「it」が、animal を指しているのか、street を指しているのかを、文全体を見渡して文脈から判断する役割を持ちます。
計算式は以下のようになります。
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V$$
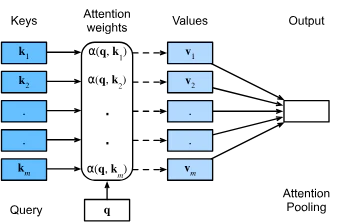
Query(クエリ/照会)、Key(キー)、Value(値)という3つのベクトルを用いて、単語間の関連度(重み)を計算します。
3. コアメカニズム②:Multi-Head Attention
1つの視点(Attention)だけでなく、複数の視点(Head)で同時に Self-Attention の計算を行う仕組みです。これにより、「文法的な結びつき」や「意味的な結びつき」など、さまざまな観点からの文脈を同時に学習することができます。
4. コアメカニズム③:Positional Encoding(位置エンコーディング)
Transformer はデータを一気に並列処理するため、「単語の並び順(語順)」の情報をそのままでは認識できません。そこで、入力データに「この単語は文の何番目にあるか」という位置情報を数学的なサイン・コサイン波などのベクトルとして足し合わせる工夫がされています。これが Positional Encoding です。
💡 より深く学びたい方へ:D2L の活用
Transformer の理論だけでなく、PyTorch や NumPy などのフレームワークを使った具体的なコード実装や数式までしっかり学びたい方には、オンライン技術書『Dive into Deep Learning』の日本語版が非常におすすめです。
以下のリンクから、Transformer の章を実際に手を動かしながら学ぶことができます。
🔗 d2l-jp.me: Dive into Deep Learning (Transformer等の解説と実装)
理論とコードがセットになっているため、数式($Q, K, V$など)がプログラム上でどのようにテンソル演算として処理されているのかが非常によく分かります。本格的に理解したい方は必読のドキュメントです。
まとめ
Transformer は「Attention のみを使う」という大胆な発想で、AI の歴史を大きく変えました。現在では自然言語だけでなく、画像処理(Vision Transformer: ViT)や音声処理など、あらゆる分野のベースモデルとして応用されています。
ディープラーニングの最前線を追う上で絶対に避けては通れない技術ですので、ぜひ D2L などの教材を活用して、その仕組みを深く味わってみてください!