Snowflake Cortex AISQL関数の概要とユースケース
目次
はじめに
みなさんはSnowflakeのCortex AISQLについてご存じでしょうか?
フル活用している、使い道がいまいちわからない、聞いたことはあるけど使ったことはない、など様々な方がいらっしゃると思います。
AI_SQL関数は、SQLの文法のままでテキスト・画像などの非構造化データを処理できるようにする、とても便利で簡単な関数です。
updateがされ続けているため機能なので、今後の拡張にも期待ができます。
一方でそのupdate頻度もあってか、各関数の使用方法とユースケースを網羅的に説明している記事が少ないように感じました。
なので今後もupdateがあるかもしれませんが、ここで一度網羅的に紹介したいと思います。
Cortex AISQLの概要
Cortex AISQLを使用すると、使い慣れたSQLコマンドを使用してスケーラブルなAIパイプラインを構築できます。
テキスト、画像、オーディオをより迅速かつコスト効率よく処理し、構造化データと非構造化データの両方からより深い分析情報を同時に得ることができます。
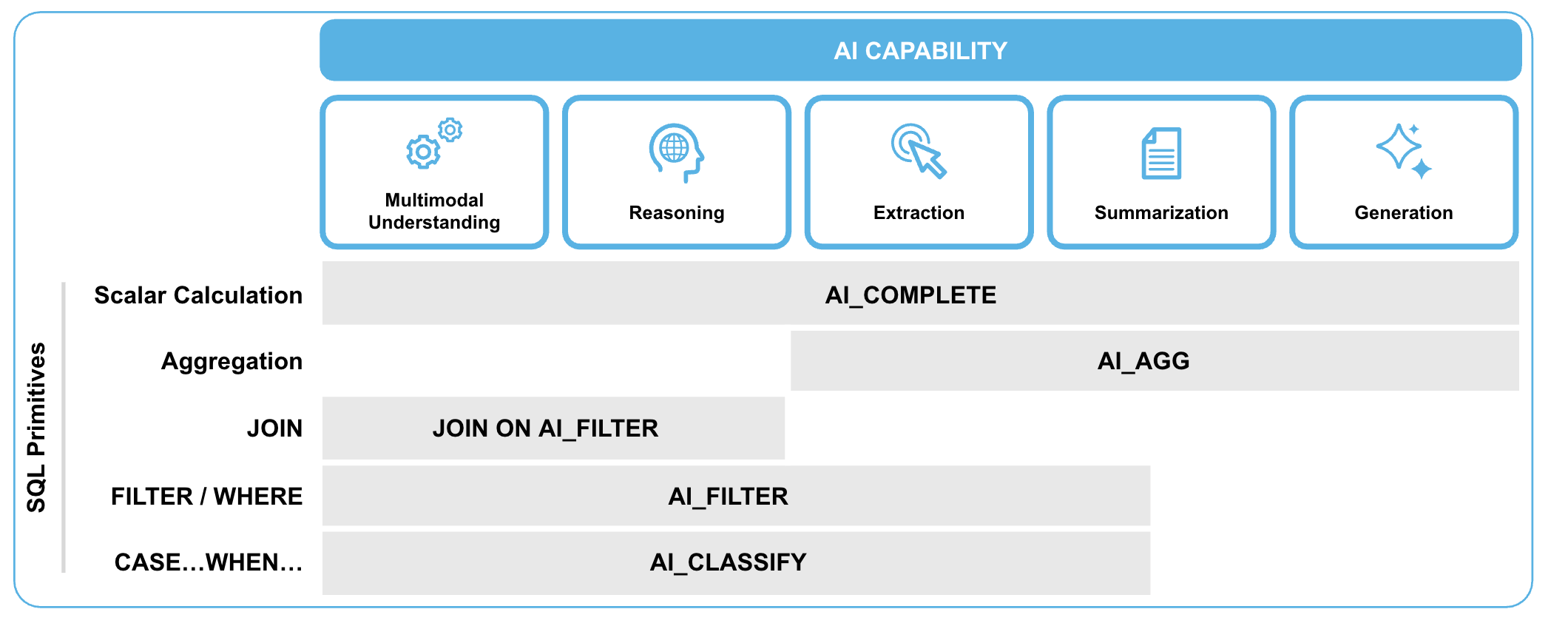
出典 : Getting Started with Cortex AISQL
- AI_COMPLETE:要約や生成など、幅広いLLMタスクを実行
- AI_EXTRACT:構造化されていないデータから質問の答えを抽出
- EXTRACT_ANSWER:質問に対する答えとスコアをJSON形式で出力
- AI_FILTER:イメージやテキストの入力に対してTrueかFalseを返す
- JOIN ON AI_FILTER:AI_FILTERの結果をフィルターできます。
- AI_CLASSIFY:テキストや画像をユーザー定義のカテゴリに分類
- SUMMARIZE:指定したテキストの要約
- AI_AGG:テキスト列を集約し、複数の行にわたる洞察を返す
- AI_SUMMARIZE_AGG:テキスト列を集約し、複数行にわたるサマリーを返す
- TRANSLATE:言語間のテキストを翻訳
- AI_SIMILARITY:2つの入力間の埋め込み類似度を計算
- AI_SENTIMENT:テキストからセンチメントスコアを抽出
- AI_PARSE_DOCUMENT:内部または外部ステージからテキストを抽出
- AI_TRANSCRIBE:音声データの文字起こし
- AI_COUNT_TOKENS: 指定されたモデルまたはCortex関数に基づいてテキストのトークン数を返す
※リージョンによるプレビュー・GAは公式リファレンス参照
https://docs.snowflake.com/ja/user-guide/snowflake-cortex/aisql#label-cortex-llm-ai-function
それでは、順を追って紹介します。
事前準備
AI_SQL関数を使用するためのデータを用意します。
ここではGetting Started with Cortex AISQLのテキスト・画像・音声データを使用します。
ウェアハウス、データベース、スキーマ、テーブルの名前は自由に変更してください。
自前のデータを使用する場合はスキップしても大丈夫です。
-
Snowsight » プロジェクト » ワークシート » SQLワークシートを作成
で以下のsetup.sqlを実行しテキストデータを取得、EMAILS table・SOLUTION_CENTER_ARTICLES tabelを作成-- setup.sql -- Run the following statements to create a database, schema, and a table with data loaded from AWS S3. CREATE DATABASE IF NOT EXISTS DASH_DB; CREATE SCHEMA IF NOT EXISTS DASH_SCHEMA; CREATE WAREHOUSE IF NOT EXISTS DASH_WH_S WAREHOUSE_SIZE=X-SMALL; USE DASH_DB.DASH_SCHEMA; USE WAREHOUSE DASH_WH_S; create or replace file format csvformat skip_header = 1 field_optionally_enclosed_by = '"' type = 'CSV'; -- Emails table create or replace stage emails_data_stage file_format = csvformat url = 's3://sfquickstarts/sfguide_getting_started_with_cortex_aisql/emails/'; create or replace TABLE EMAILS ( USER_ID NUMBER(38,0), TICKET_ID NUMBER(18,0), CREATED_AT TIMESTAMP_NTZ(9), CONTENT VARCHAR(16777216) ); copy into EMAILS from @emails_data_stage; -- Solutions Center Articles table create or replace stage sc_articles_data_stage file_format = csvformat url = 's3://sfquickstarts/sfguide_getting_started_with_cortex_aisql/sc_articles/'; create or replace TABLE SOLUTION_CENTER_ARTICLES ( ARTICLE_ID VARCHAR(16777216), TITLE VARCHAR(16777216), SOLUTION VARCHAR(16777216), TAGS VARCHAR(16777216) ); copy into SOLUTION_CENTER_ARTICLES from @sc_articles_data_stage; -- Run the following statement to create a Snowflake managed internal stage to store the sample image files. create or replace stage DASH_IMAGE_FILES encryption = (TYPE = 'SNOWFLAKE_SSE') directory = ( ENABLE = true ); -- Run the following statement to create a Snowflake managed internal stage to store the sample audio files. create or replace stage DASH_AUDIO_FILES encryption = (TYPE = 'SNOWFLAKE_SSE') directory = ( ENABLE = true ); -- Enable cross-region inference ALTER ACCOUNT SET CORTEX_ENABLED_CROSS_REGION = 'ANY_REGION'; -
images_files をDLし、
Snowsight » 取り込み » データを追加 » ステージにファイルをロード
でDLした画像ファイルを DASH_DB.DASH_SCHEMA.DASH_IMAGE_FILES に追加 -
audio_filesをDLし、
Snowsight » 取り込み » データを追加 » ステージにファイルをロード
でDLした音声ファイルを DASH_DB.DASH_SCHEMA.DASH_AUDIO_FILES に追加 -
Snowsight » プロジェクト » ワークシート » SQLワークシートを作成
で以下のimages.sqlを実行し画像データを取得、IMAGES tableを作成-- images.sql -- PREREQUISITE: Execute statements in setup.sql USE DASH_DB.DASH_SCHEMA; USE WAREHOUSE DASH_WH_S; -- Image Files table create or replace table IMAGES as select to_file(file_url) img_file, DATEADD(SECOND, UNIFORM(0, 13046400, RANDOM()), TO_TIMESTAMP('2025-01-01 00:00:00')) as created_at, UNIFORM(0, 200, RANDOM()) as user_id, * from directory(@DASH_DB.DASH_SCHEMA.DASH_IMAGE_FILES); -
Snowsight » プロジェクト » ワークシート » SQLワークシートを作成
で以下のaudio.sqlを実行し音声データを取得、VOICEMAILS tableを作成-- audio.sql -- PREREQUISITE: Execute statements in setup.sql USE DASH_DB.DASH_SCHEMA; USE WAREHOUSE DASH_WH_S; -- Audio Files table create or replace table VOICEMAILS as select to_file(file_url) audio_file, DATEADD(SECOND, UNIFORM(0, 13046400, RANDOM()), TO_TIMESTAMP('2025-01-01 00:00:00')) as created_at, UNIFORM(0, 200, RANDOM()) as user_id, * from directory(@DASH_DB.DASH_SCHEMA.DASH_AUDIO_FILES); -
Snowsight » プロジェクト » ノートブック で新規ノートブックを作成する。
- ノートブックの場所 :
データベースを選択 : DASH_DB
スキーマを選択 : DASH_SCHEMA - ランタイム : ウェアハウスで実行
- クエリウェアハウス : DASH_WH_S
- Notebookウェアハウス : SYSTEM$STREAMLIT_NOTEBOOK_WH(デフォルト)
- ノートブックの場所 :
-
notebookでpythonを使用する場合、以下のライブラリをimportする ※SQLのみ使用する場合は不要
# import library import streamlit as st import pandas as pd import altair as alt from snowflake.snowpark.context import get_active_session session = get_active_session()
AI_SQL関数の使用方法とユースケース
使用するテーブル
- EMAILS
- IMAGES
- VOICEMAILS
- SOLUTION_CENTER_ARTICLES
AI_COMPLETE
AI_COMPLETEはプロンプトを用いて要約や生成など、幅広いタスクを実行できる汎用関数です。
画像データの要約でも非常に簡単に行えます。音声データにも対応できるため、データ管理やRAG、機械学習など、さまざまなシーンで活用できます。
ここでは画像と文章の要約を実施しています。
-- AI_COMPLETE:画像の要約
SELECT
AI_COMPLETE('pixtral-large', prompt('このスクリーンショットに示された問題を、1文で簡潔に要約してください。: {0}', img_file)) AS summary
FROM images;
-- AI_COMPLETE:文章の要約
SELECT
AI_COMPLETE('claude-3-7-sonnet', prompt('この問題を1文で簡潔に要約してください。ユーザーが音楽の好みに関することを述べている場合は、その情報も残してください。: {0}', content)) AS summary
FROM emails;
- 画像の要約:結果

- 文章の要約:結果

AI_EXTRACT
AI_EXTRACTでは構造化されていないデータから質問の答えを抽出できます。
-- AI_EXTRACT
SELECT
AI_EXTRACT(
file => img_file,
responseFormat => ['これは何についての画像ですか?']) AS ext
FROM images;
- 結果

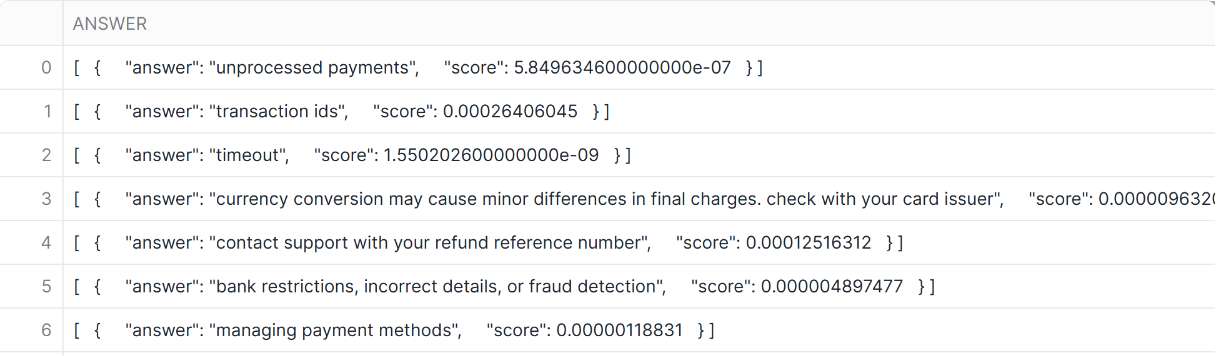
EXTRACT_ANSWER
EXTRACT_ANSWERでは質問に対する答えとスコアをJSON形式で出力できます。
回答と正確度がJSON形式で出力され、正解度が1に近いほど確度が高い回答になります。
-- EXTRACT_ANSER
SELECT
SNOWFLAKE.CORTEX.EXTRACT_ANSWER(solution,'チケット代金の返金方法について教えてください。') AS answer
FROM SOLUTION_CENTER_ARTICLES;
- 結果
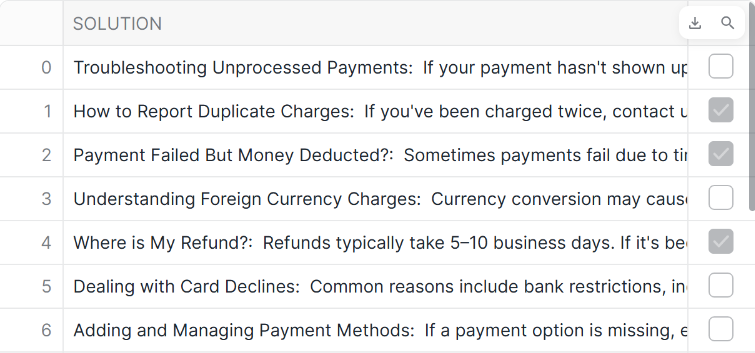
AI_FILTER
AI_FILTERではイメージやテキストの入力に対してTrueかFalseを返すことができます。
-- AI_FILTER
SELECT
solution,
AI_FILTER(
PROMPT('これは返金についての文章ですか?:{0}',solution)
) AS bool
FROM SOLUTION_CENTER_ARTICLES
- 結果
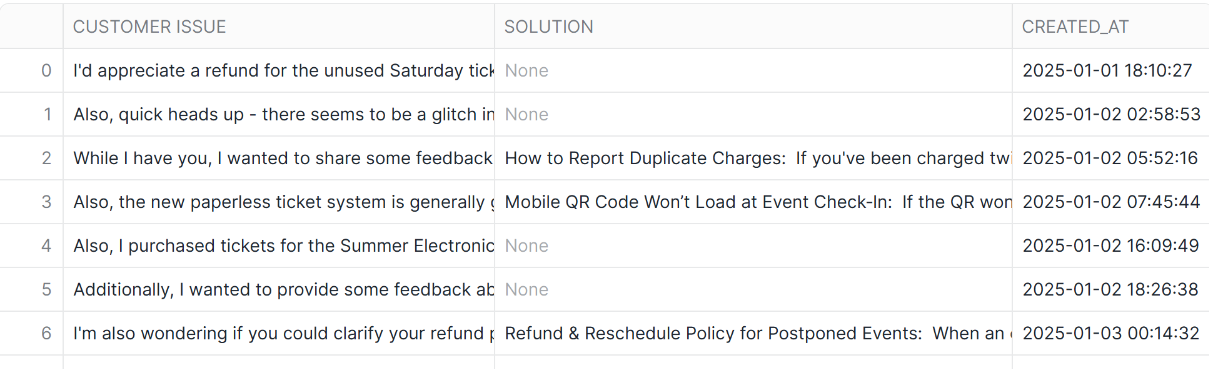
JOIN ON AI_FILTER
JOIN句とAI_FILTERを組み合わせたJOIN ON AI_FILTERでは、AI_FILTERの結果をフィルターできます。
これまで人手で対応していた作業が、自動化で一気に効率化できるのは大きなメリットです。
ここではJOIN ON AI_FILTERを使って、課題に対応する解決策を結合してみます。
-- AI_COMPLETE関数を使用し、要約のカラム(summary)を持ったinsightsテーブルを作成
CREATE TABLE IF NOT EXISTS insights AS
WITH IMAGE_INSIGHTS AS (
SELECT
created_at,
user_id,relative_path AS ticket_id,
img_file AS input_file,
file_url AS input_file_url,
AI_COMPLETE('pixtral-large', prompt('このスクリーンショットに示された問題を、1文で簡潔に要約してください: {0}', img_file)) AS summary,
summary AS content
FROM images
),
EMAIL_INSIGHTS AS (
SELECT
created_at,
user_id,
ticket_id::text AS ticket_id,
null AS input_file,
'' AS input_file_url,
content AS content,
AI_COMPLETE('claude-3-7-sonnet', prompt('この問題を1文で簡潔に要約してください。ユーザーが音楽の好みに関することを述べている場合は、その情報も残してください。: {0}', content)) AS summary
FROM emails
)
SELECT
'Image' AS source,
created_at,
user_id,
ticket_id,
input_file,
input_file_url,
content,
summary
FROM IMAGE_INSIGHTS
UNION
SELECT
'Email' AS source,
created_at,
user_id,
ticket_id,
input_file,
input_file_url,
content,
summary
FROM EMAIL_INSIGHTS;
-- JOIN ON AI_FILTERで対応する課題と解決策を結合
SELECT
c.content AS "CUSTOMER ISSUE",
s.solution,
c.created_at,
FROM
INSIGHTS c
LEFT JOIN
SOLUTION_CENTER_ARTICLES s
ON
AI_FILTER(prompt('お客様の問い合わせ内容と、ソリューションセンターの記事が与えられています。この記事が、お客様の懸念に対応できるかどうかを確認してください。エラーの詳細が一致しているかどうかも忘れずに確認してください。Customer issues: {0}; \n\nSolution: {1}', content, s.solution))
ORDER BY created_at ASC;
- 結果
AI_CLASSIFY
AI_CLASSIFYではテキストや画像をユーザー定義のカテゴリに分類できます。
ラベル付けは機械学習においても重要ですが、これまではマスタがなければ手作業で行う必要がありました。AI_CLASSIFYにより、分類タスクの生産性が大幅に向上し、これまで手を付けられなかった領域にも挑戦できそうです。
-- AI_CLASSIFYのプロンプト
SET CLASSIFY_PROMPT = 'このコメントに記載されている音楽の好みを分類してください。: ';
-- 音楽ジャンルの定義
SET MUSIC_GENRES = 'Electronic/Dance Music (EDM), Jazz, Indie/Folk, Rock, Classical, World Music, Blues, Pop';
-- AI_CLASSIFY
SELECT
source,
summary,
AI_CLASSIFY($CLASSIFY_PROMPT || summary,SPLIT($MUSIC_GENRES, ','))['labels'][0] as classified_label
FROM
-- AI_FILTERで音楽の意見について抽出
(SELECT *
FROM insights
WHERE AI_FILTER(PROMPT('お客様のコメントに、特定の音楽ジャンルの好みが記載されているかを確認しようとしています。このコメントには、お客様による特定の音楽ジャンルの好みが記載されていますか?: {0}', summary))
);
- 結果

SUMMARIZE
SUMMARIZEでは指定したテキストの要約ができます。
SQLは簡潔ですが、AI_COMPLETEの方が汎用性が高いのであまり使うことはないかもしれません。
SELECT
SNOWFLAKE.CORTEX.SUMMARIZE(content) as summary
FROM emails;
- 結果

AI_AGG
AI_AGGではテキスト列を集約し、複数の行にわたる洞察を返します。
集約は任意の方法(プロンプト)でできるため、課題の優先順位が一目で把握できます。
-- AI_AGG
SELECT
monthname(created_at) AS month,
count(*) AS total_tickets,
count(distinct user_id) AS unique_users,
AI_AGG(summary,'チケットレビューを分析し、問題の包括的な一覧を作成してください。回答は各問題を箇条書きで示し、それぞれの発生頻度(%)も記載してください。') AS top_issues_reported,
FROM insights
GROUP BY month
- 結果

AI_SUMMARIZE_AGG
AI_SUMMARIZE_AGGではテキスト列を集約し、複数行にわたるサマリーを返します。
AIAGGと比較すると要約に特化しているため、全体的な傾向が一目で把握できます。
-- AI_SUMMARIZE_AGG
SELECT
monthname(created_at) AS month,
count(*) AS total_tickets,
count(distinct user_id) AS unique_users,
AI_SUMMARIZE_AGG(summary) AS issues_reported,
FROM insights
GROUP BY month
- 結果

TRANSLATE
TRANSLATEでは言語間のテキストを翻訳します。
-- TRANSLATE
SELECT
content AS original_content,
SNOWFLAKE.CORTEX.TRANSLATE(content, 'en', 'ja') AS translate_content
FROM emails;
- 結果

AI_SIMILARITY
AI_SIMILARITYでは2つの入力間の埋め込み類似度(cosine類似度)を計算します。
-- AI_SIMILARITY
SELECT
CONTENT,
AI_SIMILARITY(
CONTENT,
'土曜日のチケットについて'
) AS cosine_similarity
FROM emails
-- ORDER BY cosine_similarity DESC
- 結果
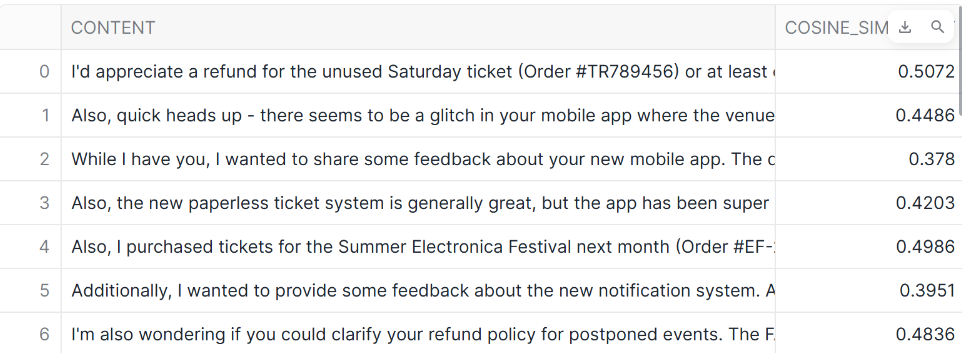
AI_SENTIMENT
AI_SENTIMENTではテキストからセンチメントスコアを出力します。
['ticket','quality']のようにカテゴリを指定すると、それぞれのカテゴリについてもポジネガ判定を行います。指定しなければ、全体のポジネガのみ判定します。
-- AI_SENTIMENT
SELECT
AI_SENTIMENT(
content,
['ticket','quality']
) AS sentiment
FROM emails;
- 結果
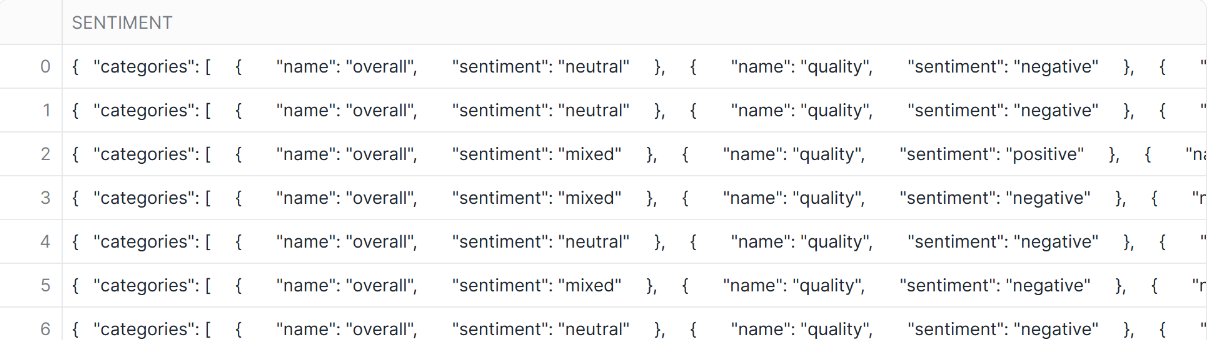
AI_PARSE_DOCUMENT
AI_PARSE_DOCUMENTでは内部または外部ステージからテキストを抽出します。
画像データからテキストをそのまま抽出したいときなどに有用です。
-- AI_PARSE_DOCUMENT
SELECT
relative_path,
AI_PARSE_DOCUMENT(
TO_FILE('@DASH_IMAGE_FILES', relative_path),
{'mode': 'OCR' , 'page_split': False}
) AS result
FROM DIRECTORY (@DASH_IMAGE_FILES);
- 結果
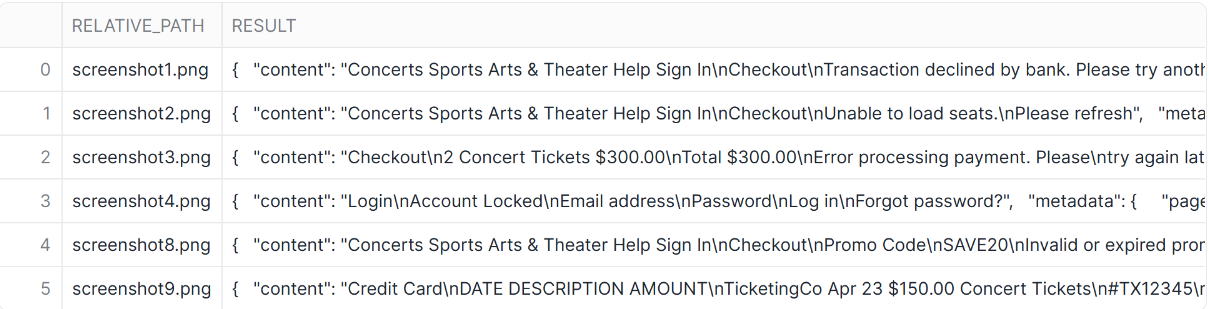
AI_TRANSCRIBE
AI_TRANSCRIBEでは音声データの文字起こしを行います。
音声データからテキストをそのまま抽出したいときなどに有用です。
-- AI_TRANSCRIBE
SELECT
(AI_TRANSCRIBE(audio_file)['text']) AS transcribe
FROM voicemails
- 結果

AI_COUNT_TOKENS
AI_COUNT_TOKENSでは指定されたモデルまたはCortex関数に基づいてテキストのトーク
ン数を返します。
事前にトークンの使用量を確認することで、コストを正確に見積もることが可能です。
-- AI_COUNT_TOKENS
SELECT
AI_COUNT_TOKENS('ai_complete','llama3.3-70b',content)
FROM emails;
- 結果
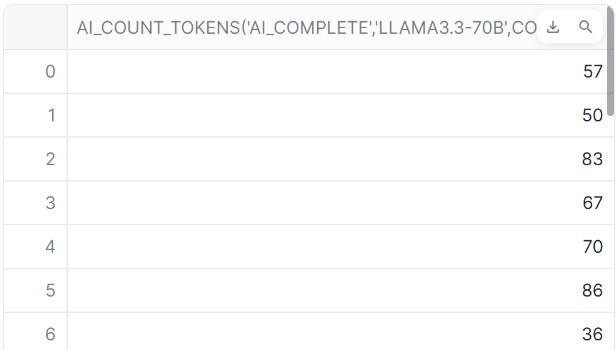
まとめ
AISQL関数の最大のメリットは、「SQLと同じ構文で」「簡潔に」「安価に」「クイックに」LLMの機能をフル活用できる点だと考えています。なので使ったことがない方や使い方がわからない方も是非これを機に一度触ってみてください。応用すればMLにも活用でき、いままで作りたくても作れなかった特徴量や変数の補完が簡単にできてしまうかもしれません。
また最初にもお伝えした通り、これらの関数は日々アップデートされ、新しい関数も提供され続けています。そのため最新の情報を追うには公式リファレンスを見るのが一番かと思いますが、今回の記事がAISQL関数の理解とユースケースについての一助となれば幸いです。
長くなりましたがお付き合いいただきありがとうございます。