海外の技術系の動画など、内容には興味はあるものの、言語が違うため視聴ハードルが高いという問題があります。
そこで、PythonとOpenAIのAPIキーだけで、動画の「声だけ」を別言語に置き換えた吹き替え動画を自動生成するツール 「Fukikae」 を作りました。
ソースコードはオープンソースで公開しています。
デモ(生成例)
このツールで生成した、日本語吹き替え動画です。
元動画の出典: President Obama Tours SpaceX with Elon Musk (FOIA #22-16594-F) / Public Domain(米国政府著作物)
特徴
コストが安い
吹き替え動画生成サービスとして ElevenLabs が有名です。
ただ、コストが高めです。
Fukikaeは同等の目的(吹き替え動画の生成)に対して、約21分の1の価格で作れる想定です。
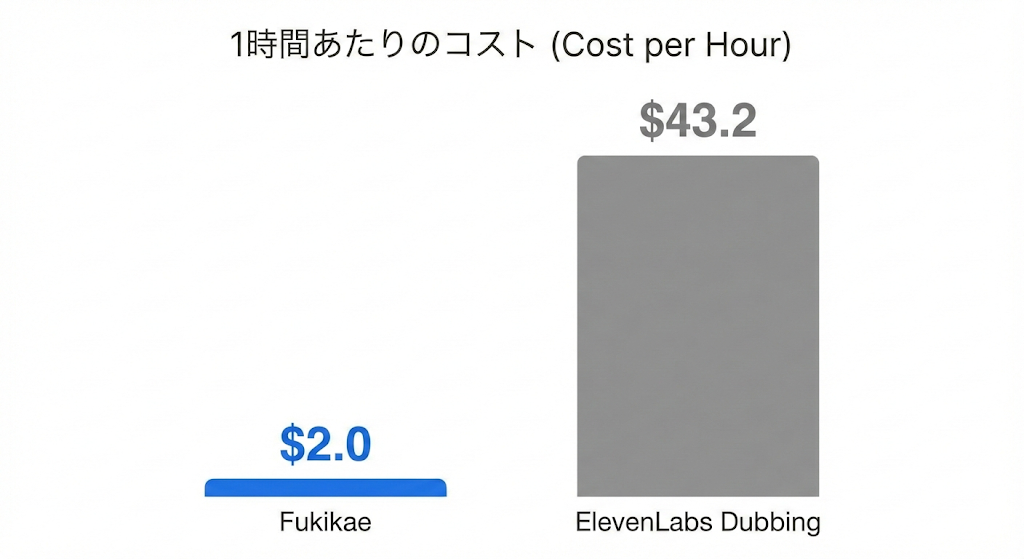
コスト内訳
| 項目 | Fukikae | ElevenLabs Dubbing |
|---|---|---|
| 計算 | Whisper-1(0.36ドル) + gpt-4o-transcribe-diarize(0.36ドル) + GPT-5.2 / GPT-5-mini(~0.3ドル) + gpt-4o-mini-tts(~0.9ドル) | 3,000クレジット/分 × 60分 × 0.24ドル / 1,000クレジット |
使い方
まず、OpenAI APIキーを取得します
取得方法として、こちらの記事がわかりやすいです
次に、各環境ごとにGitHubからクローン&コマンド実行することで、吹き替え動画が生成できます。
macOS
# 1) 依存関係
brew install python ffmpeg
# 2) インストール
git clone https://github.com/Naoki0513/fukikae.git
cd fukikae
pip install -e .
# 3) APIキー設定
cp .env.example .env
# .env を開いて OPENAI_API_KEY を設定
# 4) 実行(path\to\video.mp4 は「吹き替えしたい動画ファイルのパス」です)
fukikae path/to/video.mp4
# → path/to/video_dubbed.mp4 に出力されます
Windows
# 1) Python をインストール
# https://www.python.org/downloads/
# 2) FFmpeg をインストールしてPATHを通す
# https://ffmpeg.org/download.html
# 3) インストール
git clone https://github.com/Naoki0513/fukikae.git
cd fukikae
pip install -e .
# 4) APIキー設定
copy .env.example .env
# .env を開いて OPENAI_API_KEY を設定
# 5) 実行(path\to\video.mp4 は「吹き替えしたい動画ファイルのパス」です)
fukikae path\to\video.mp4
# → path\to\video_dubbed.mp4 に出力されます
AWS
S3に動画をアップロードするだけで、自動的に吹き替え動画が生成されます。
AWSアーキテクチャ・料金
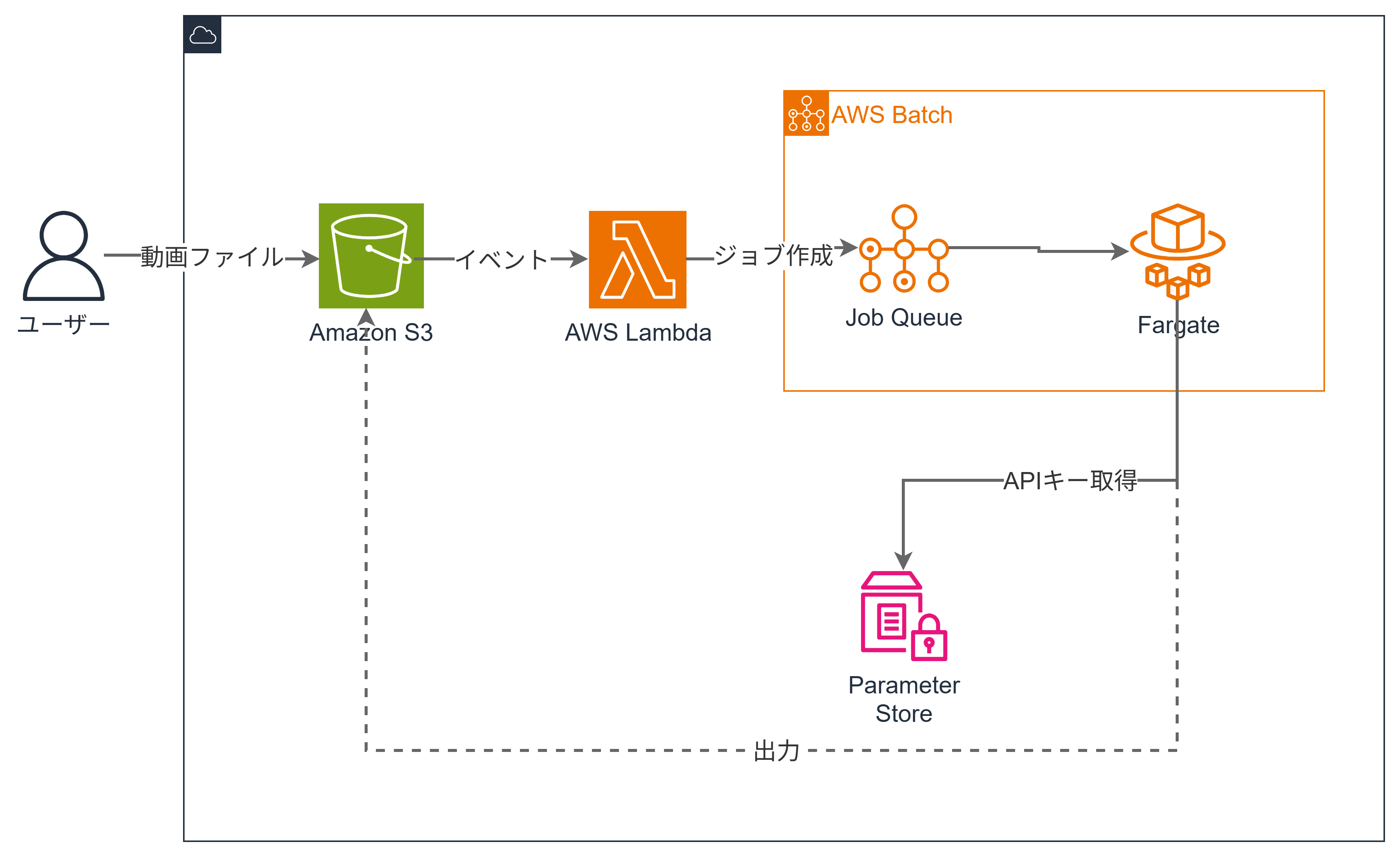
AWS料金
- 未使用時はS3(0.025ドル/GB)とECR(0.10ドル/GB)のストレージ料金のみ
- 実行時はFargate実行時間分のみ(1vCPU/4GBメモリで約0.073ドル/時間)
# 1. CloudShellを開く
# https://console.aws.amazon.com/cloudshell/
# 2. セットアップ
git clone https://github.com/Naoki0513/fukikae.git
cd fukikae/aws
pip install -r requirements.txt
cdk bootstrap
# 3. デプロイ(APIキーも同時に設定)
cdk deploy -c openai_api_key=sk-xxxxxxxxxxxxxxxx --require-approval never
# Outputsに出力される VideoBucketName をメモ
使い方
Outputsに出力されたS3バケットに動画をアップロードします
数分~時間後に、吹き替えされた動画がxxxx_dubbed.mp4という名前で生成されます
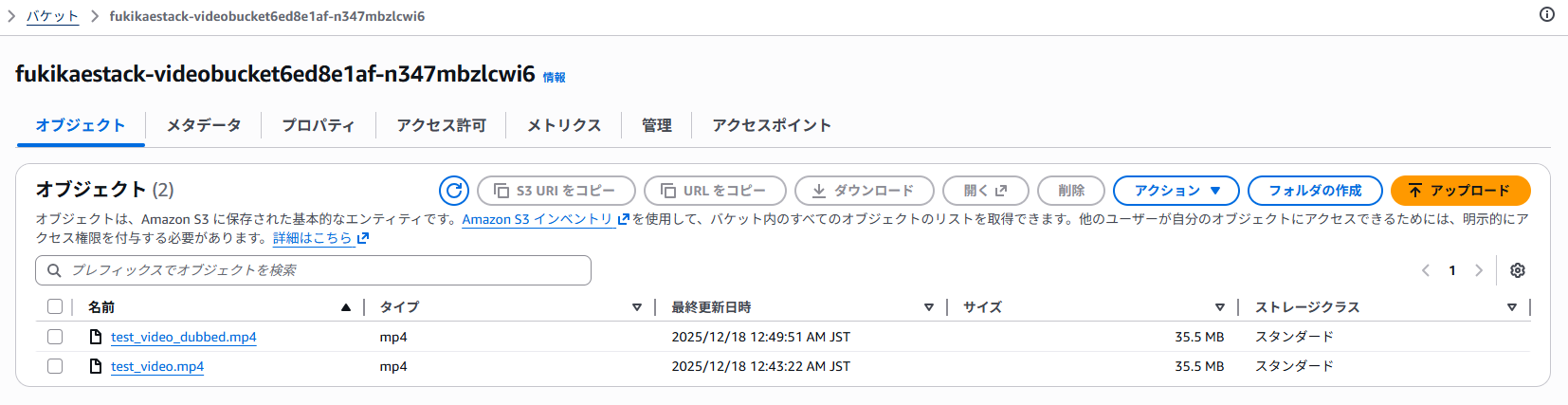
目安として 1時間の動画で処理に約30分かかります
工夫した点
処理の流れは以下の通りです。
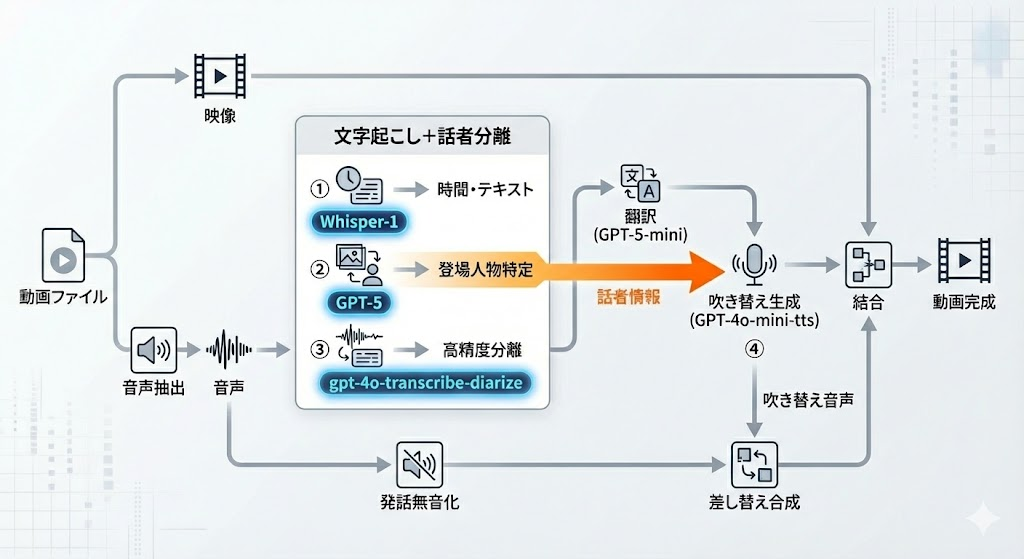
全体としては、
- 音声を 文字起こし
- 翻訳
- 吹き替え音声(TTS) を生成
というシンプルな流れです。
その中で特に工夫したのは、次の3点です。
精度向上
文字起こしは2回に分けて行うことで、文字起こし&話者分離の精度を向上させています
- まず一度文字起こしを行い、その情報を使って話者ごとの音声を抜き出す
- その音声をgpt-4o-transcribe-diarize のknown_speaker_references渡して文字起こしを行う
声を似せる
吹き替え音声が機械的になるのを避けるため、動画のスクリーンショット等の情報を参考にして人物の雰囲気を推定し、gpt-5 が
- 音声の種類の選択
- TTS用のinstruction調整
を行います。
発話タイミングを揃える
吹き替え後の音声がズレると見ていてストレスになります。
そのため、元動画の発話タイミングに合わせて、吹き替え音声の再生タイミングを調整します。
注意点
- 利用する動画の 権利・ライセンスは各自で確認してください
本ツールの使用により生じたいかなる損害についても、作者は責任を負いません
詳細
リポジトリに関して質問があれば、こちらのdeepwikiをご利用ください