TL;DR
testing-libraryのgetByTextをはじめとしたByText系のクエリーや、@testing-library/jest-domのtoHaveTextContentマッチャーは空白文字を正規化するので、必要に応じて正規化オプションを設定しましょう。
import { it, expect, afterEach } from "vitest";
import "@testing-library/jest-dom/vitest";
import {
render,
screen,
getDefaultNormalizer,
} from "@testing-library/react";
const App: FC = () => {
return (
<div>
<textarea
defaultValue={
"textareaタグではこのように↓\n↑改行は改行として扱われます"
}
/>
</div>
);
};
it("textareaタグでgetByTextできるようにnormalizerを設定する", () => {
render(<App />);
expect(
screen.getByText(
"textareaタグではこのように↓\n↑改行は改行として扱われます",
{
normalizer: getDefaultNormalizer({ collapseWhitespace: false }),
},
),
).toBeInTheDocument();
});
it("textareaの中身を見る", () => {
render(<App />);
// toHaveTextContentで比較すると正規化された状態でテストされる
expect(screen.getByRole("textbox")).toHaveTextContent(
"textareaタグではこのように↓ ↑改行は改行として扱われます",
);
// toHaveValueで比較すると正規化されない状態でテストされる
expect(screen.getByRole("textbox")).toHaveValue(
"textareaタグではこのように↓\n↑改行は改行として扱われます",
);
// toHaveTextContentで比較するとき正規化する内容をカスタマイズしてテストする
expect(screen.getByRole("textbox")).toHaveTextContent(
"textareaタグではこのように↓\n↑改行は改行として扱われます",
{ normalizeWhitespace: false },
);
});
はじめに
@testing-libraryでgetByTextによって要素を取得するときに、空白文字が正規化されていることに気がついたので、その動作を調べてCodeSandboxにサンプルコードを用意しました。
@testing-libraryでgetByTextは空白文字をどのように正規化しているか
@testing-libraryのgetByTextなどのByText系のクエリーは、文字列内の複数の隣接する空白文字を1つのスペースとみなして要素を検索しています。(公式ドキュメント: About Queries#Normalization | Testing Library)
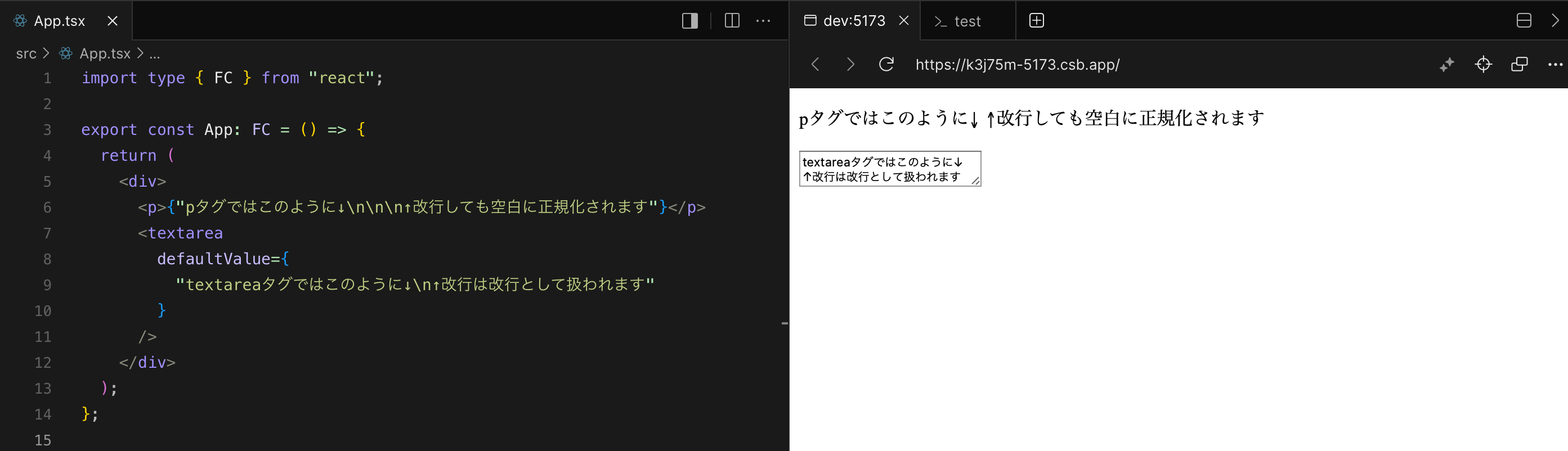
例えば以下のようなReactエレメントについて、
<p>{"A↓\n\n\n↑B"}</p>
次のgetByTextを実行しても要素を取得できません。
conse elem = screen.getByText("A↓\n\n\n↑B"); // 見つからずに例外が排出される
なおgetByTextを実行しているので、見つからない場合は例外(TestingLibraryElementError)が投げられ、そのためにテストが失敗します。
@testing-libraryのクエリの種類については以下を参照してください。
About Queries | Testing Library
https://testing-library.com/docs/queries/about
しかし次のgetByTextでは要素を取得することができます。
// 正規化されることを見越して連続した空白を1つのスペースとして要素を取得する
conse elem = screen.getByText("A↓ ↑B");
expect(elem).toBeInTheDocument(); // OK
このことから、@testing-libraryでは空白文字について正規化を行なった上で、要素を取得していることが確認できます。ちなみに@testing-libraryのソースコード上ではこの箇所が処理を担っています。
ところでpタグの中に改行\nを入れても、ブラウザで表示する時には改行されず一つの空白として表示されます。改行したいときは<br>タグを使う必要がありますね。@testing-libraryの空白文字の正規化の仕様は、ブラウザの仕様に則したものであると言えるでしょう。
getByTextの正規化をカスタマイズする
@testing-libraryにおける空白の取り扱い方はカスタマイズできます。(公式ドキュメント: About Queries#Normalization | Testing Library)
やり方はgetByTextの第二引数のオプションにnormalizerを指定することです。normalizerには正規化前の文字列を受け取って、正規化した文字列を返す関数(text: string) => stringを指定します。
今回は公式ドキュメントのサンプルにあるように、デフォルトのnormalizerを取得する関数をgetDefaultNormalizerを使ってgetByTextの正規化をカスタマイズします。getDefaultNormalizerは現在2つのオプションtrimとcollapseWhitespaceを指定できます。
これらを使って改行を改行のまま要素を取得できるgetByTextを作ってみると次のように書けます。
import { screen, getDefaultNormalizer } from "@testing-library/react";
const elem = screen.getByText("A↓\n\n\n↑B", {
normalizer: getDefaultNormalizer({
/* 前後の空白を切り詰めるか */
trim: false,
/* 複数の空白を1つのスペースに置き換えるか */
collapseWhitespace: false,
}),
});
expect(elem).toBeInTheDocument(); // OK
これの使い所
改行が入っているpタグをgetByTextで引いてきたいというケースは少ないかもしれません。前述の通りブラウザで表示する時には改行は空白にまとめられます。また、ソースコードのJSX中で改行をしてもレンダリングまでに複数の空白は1つのスペースにまとめられるため、ここまで示してきた例ではReactのpの直下に文字列を入れるという不自然な書き方で複数の空白が正規化される様子を確認してきました。
一方、getByTextはtextareaのvalueに応じて要素を引いてくることもできるので、サンプルコードではtextareaを取得する例を示しました。しかし、textareaについても要素を引くのに、getByRole("textbox")を用いて、取得後その中身をテストした方がいいかもしれません。
ところで、textboxの中身を評価する際にも、ここまでgetByTextの例で見てきたような空白の正規化が行われます。次章で説明します。
@testing-library/jest-domのtoHaveTextContentも空白文字の正規化を行なっている
@testing-library/jest-domのtoHaveTextContentもデフォルトでは連続する空白文字を1つのスペースとみなして評価します。toHaveTextContentの引数にはオプションとしてnormalizeWhitespaceを渡すことができ、これを無効にすることができます。(公式ドキュメント: testing-library/jest-dom#toHaveTextContent)
@testing-library/jest-domのソースコード上ではこの箇所が処理を担っています。
例えば変数elemに次のような要素をが入っている時、
<textarea defaultValue={"A↓\n\n\n↑B"} />
// ↑を変数elemに入れる
const elem = getByRole("textbox");
toHaveTextContentが空白文字を正規化することを前提として次のようなテストを書くことができますが、
expect(elem).toHaveTextContent("A↓ ↑B");
textareaでは改行がそのまま表示されるので、ユーザーに見えているものとは違った内容でテストしていると言えます。
このような例の場合、@testing-library/jest-domのtoHaveValueという、textareaやinputのvalueの内容をテストするマッチャーが適しているでしょう。
expect(elem).toHaveValue("A↓\n\n\n↑B");
なお、toHaveTextContentで比較するとき正規化する内容をカスタマイズしてテストすることも可能で次のように書くことができます。
expect(elem).toHaveTextContent("A↓\n\n\n↑B", { normalizeWhitespace: false });
CodeSandboxによるサンプルコード
CodeSandboxのcloud sandboxのqiitaへの埋め込みは以下を参考にしました
サンプルコードについて
CodeSandboxのDevboxのテンプレートReact (Vite + TS)にVitestを導入してテストを書いてあります。
サンプルコード見どころ
- ソースコード
-
/src/App.test.tsx: テストコードが書いてあります -
/src/App.tsx: テスト対象のコンポーネントが書いてあります -
package.json: 今回検証に使ったライブラリのバージョンが指定されています
-
- コンソールのタブ
-
dev:5173: テスト対象のコンポーネントのレンダリング結果が表示されています -
test:Vitestのテスト結果が表示されています
-