初めに
データの集計処理をGlueで実装中に、途中の処理結果を一旦S3に出力して確認したい時がある。この時何も設定せず出力先にS3バケットを指定するとS3バケットには複数に分割されたファイルが大量に出力されて中身の確認が大変になります。
これに対処するためのS3バケットに1ファイルで結果を出力する方法(今回はCSVファイル)を記事にしました。
使うAWSサービス
・AWS Glue
・Amazon S3
実現方法
アーキテクチャ図(Glue Studio)
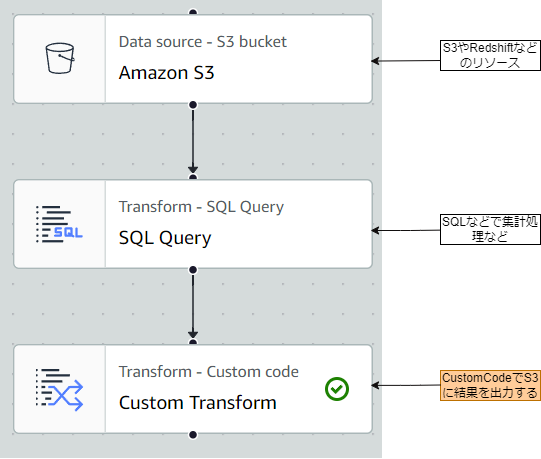
構成説明
①DataSource
・図ではS3Bucketを指定している
・用途によってはRedshiftなど他のDataSourceを指定可能
※今回の話の記事の主題ではないので説明は割愛
②Transform
・図ではSQLQueryを指定している
・DataSourceから受け取ったデータをSQLやPythonコードで集計/加工する
※今回の話の記事の主題ではないので説明は割愛
③Custom Code ★
・結果をCSVに出力するにはCustomCodeを使用する
・下記のコードのように指定するとS3にファイルが1つ出力できる
・出力には区切り文字や並び特定の文字の置換、行の並び替えなど様々なオプションをつけることが可能だが、今回は良く使うオプションを記載した。
<コード例>
sample
def MyTransform2 (glueContext, dfc) -> DynamicFrameCollection:
selected = dfc.select(list(dfc.keys())[0]).toDF() # 前処理の結果を取得
path = "【s3://bucket-name/key-name】" # S3の出力先を指定
selected
.orderBy("COLUMN_1","COLUMN_2","COLUMN_3") # 出力データの並び替えを行う場合に指定
.coalesce(1) # 1つのパーティションに結合
.write # 書き込み命令
.option("header", "True") # ヘッダ有無
.option("sep", ",") # 区切り文字
.option("quoteAll", "True") # ダブルクォートで囲むか
.option("escape", "\"") # エスケープしたい文字
.option("emptyValue", "") # 空文字をどのように出力するか
.option("nullValue", "") # NULL値をどのように出力するか
.mode("overwrite") # 出力先ファイルの扱いoverwriteは上書き
.csv(path) # 出力先
※parquetで出力したい場合
sample
df.write.mode("overwrite").format("parquet").save(path)
さいごに
Lambda関数だとコードの途中にprint()を使うことで途中の結果をコンソール画面の「TEST」の実行結果画面に出力できるのでデバッグが比較的しやすいが、Glueだと処理の途中の結果などをどのように確認したらよいか、良い方法を探していました。
私の業務ではRedshiftやS3の結果をCSV形式で出力することも多いのでこの記事の内容のように結果をS3にファイル出力する方法があればGlueでのデバッグもかなり楽になる。