はじめに
前回,『お前らの服装がダサいのでおしゃれ判定アプリを作ってみた』という記事で自作おしゃれ判定アプリの紹介を行いました.今回は前回の記事のコメントなどを参考にアプリの仕様等を変更したのでその紹介です.
前回の反省点
前回の反省は以下の2点です.
- データ集めにGoogleの画像検索を使用した
- おしゃれとダサいという2値分類問題でモデルを学習してしまった
1つ目はGoogleの画像検索を使うとコーディネートには関係ない画像もたくさん検索に引っ掛かってしまう場合や,記事のタイトルが『ダサい人がおしゃれになるには』といった記事に貼り付けられている画像はGoogleの画像検索で「ダサい」と「おしゃれ」の両方に反応してしまうためおしゃれクラスとダサいクラスの両方に同じ画像が入ってしまうなどの問題により良いデータセットができませんでした.他にもそもそもネットに自分の服装をあげている人はおしゃれな人が多く本当にダサい人はネットに服装をあげないといった問題もあると考えられます.
2つ目は服装をおしゃれかダサいかの2パターンでしか考えていなかったことです.人は他の人の服装をみて「この人めっちゃおしゃれやな」とか「なんとも思わないし普通やな」とか「めっちゃダサい」など回帰問題っぽく人の服装を見ています(多分).それなのに無理やり「おしゃれ」と「ダサい」の2値分類に落とし込んだことが問題だと考えます(ダサい服装がたくさんあったらそこそこうまくいっていたとは思う).
WEARとは
服装に関心がないエンジニアの皆様のために簡単に説明します.WEARとはZOZOTOWNが運営しているサービスでコーディネート専用のInstagramみたいなSNS?です.自分の服装をアップロードしたり他の人の服装を見ることができます.また,それらの服装に対してTwitterやInstagramと同様にいいねをつけることができます.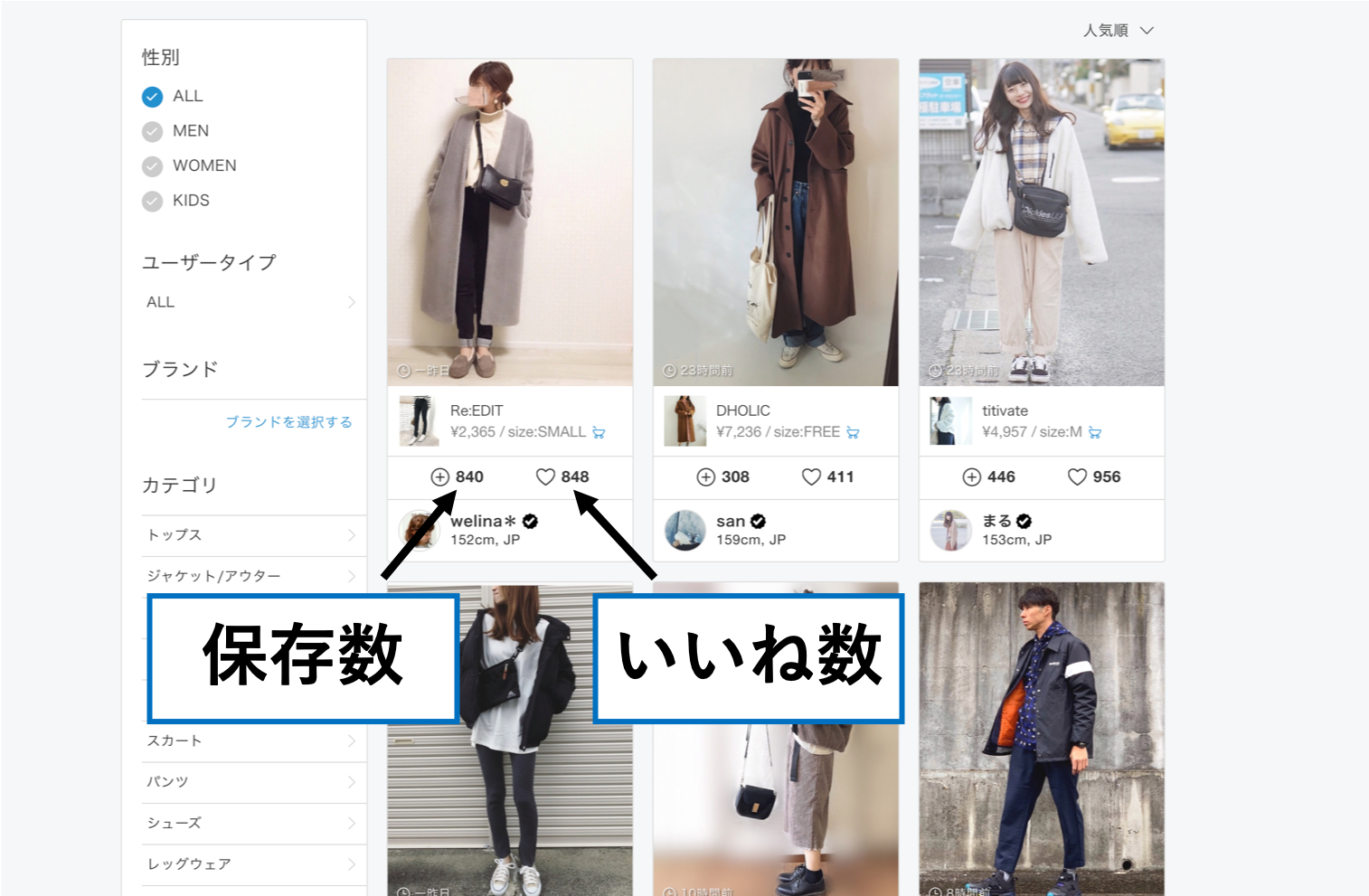
前回からの変更点
前回のアプリの仕様は男女関係なく服装の点数を100点満点で採点するといったものでした.今回は男女別々にモデルを用意し入力された服装に対してWEARのいいね数を予測し出力する仕様にしました.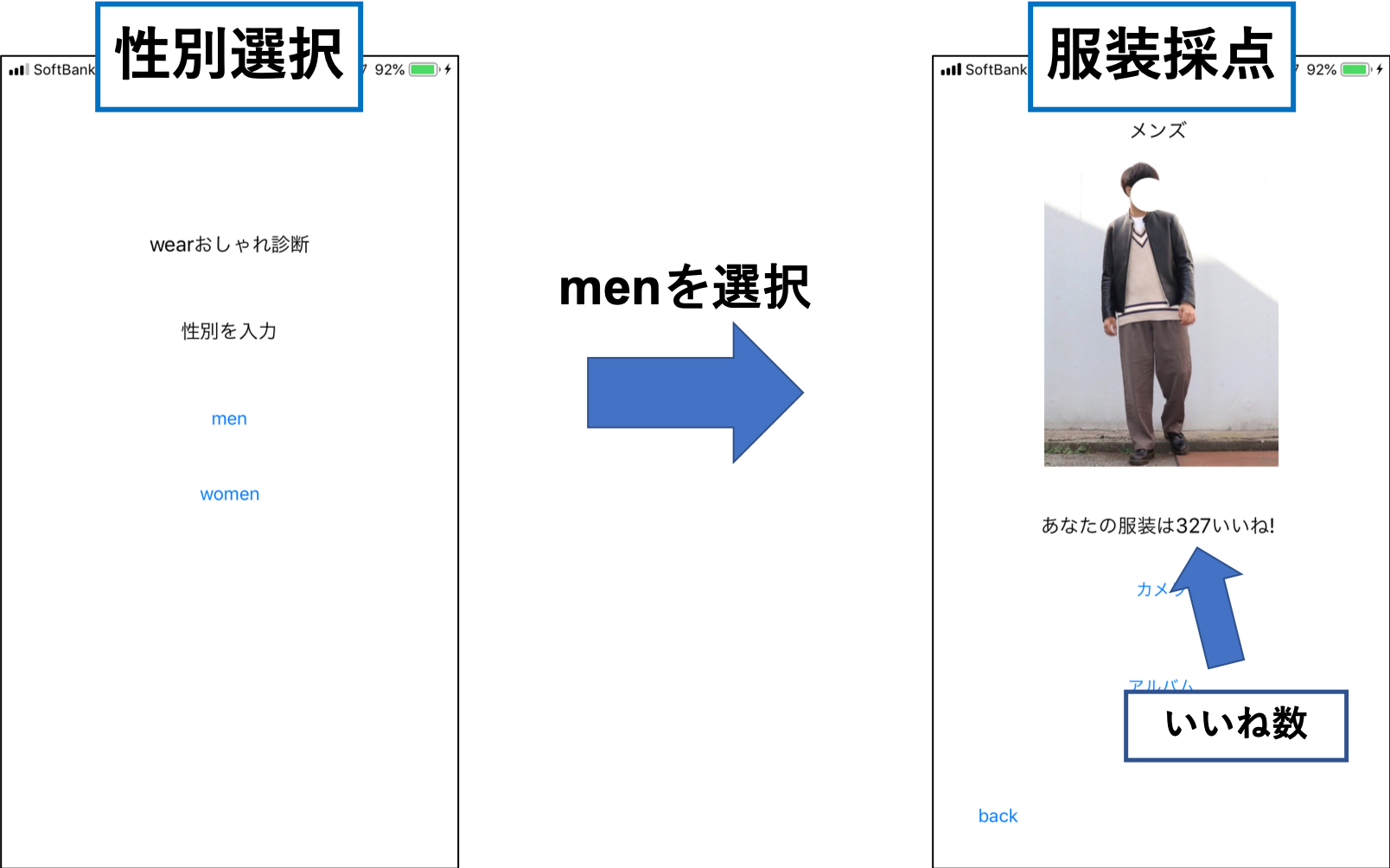
開発環境
-
モデルの学習
- windows 10
- python 3.6
- NVIDIA GTX 1080Ti
-
アプリへの組み込み
- macOS Mojave 10.14.2
- Xcode 10.1
- python 3.6
- ios 12.1.1
画像集め
今回はpythonのライブラリBeautifulSoup4を使って画像スクレイピングを行いました.スクレイピングに関しては全くの初心者だったのですがこちらの『Pythonで画像スクレイピングをしよう』という記事がHTMLの基礎からWebスクレイピングの応用まだわかりやすく書かれており大変参考になりました.服装のいいね数を教師信号にモデルを学習するため服装とそれに対応するいいね数をセットでスクレイピングしました.ソースコードは以下になります.
import requests
import re
from bs4 import BeautifulSoup
import uuid
i = 0
for page in range(1, 223):
r = requests.get('https://wear.jp/men-coordinate/?pageno='+str(page))
soup = BeautifulSoup(r.text,'lxml')
imgs = soup.find_all('img', attrs={"data-originalretina": re.compile('^//cdn.wimg.jp/coordinate')})
goods = soup.find_all('p', attrs={"class" : "btn"})
goods = goods[1::2]
for img, good in zip(imgs, goods):
i = i+1
print('http:' + img["data-originalretina"])
good_ = good.find('span')
r = requests.get('http:' + img["data-originalretina"])
with open(str('picture/')+str(i)+'_'+str(good_.string)+str('.jpeg'),'wb') as file:
file.write(r.content)
for page in range(1, 223):
r = requests.get('https://wear.jp/women-coordinate/?pageno='+str(page))
soup = BeautifulSoup(r.text,'lxml')
imgs = soup.find_all('img', attrs={"data-originalretina": re.compile('^//cdn.wimg.jp/coordinate')})
goods = soup.find_all('p', attrs={"class" : "btn"})
goods = goods[1::2]
for img, good in zip(imgs, goods):
i = i+1
print('http:' + img["data-originalretina"])
good_ = good.find('span')
r = requests.get('http:' + img["data-originalretina"])
with open(str('picture/')+str(i)+'_'+str(good_.string)+str('.jpeg'),'wb') as file:
file.write(r.content)
ターミナルで以下を実行すると画像が指定したフォルダに保存されます.
$ python scraping_wear.py
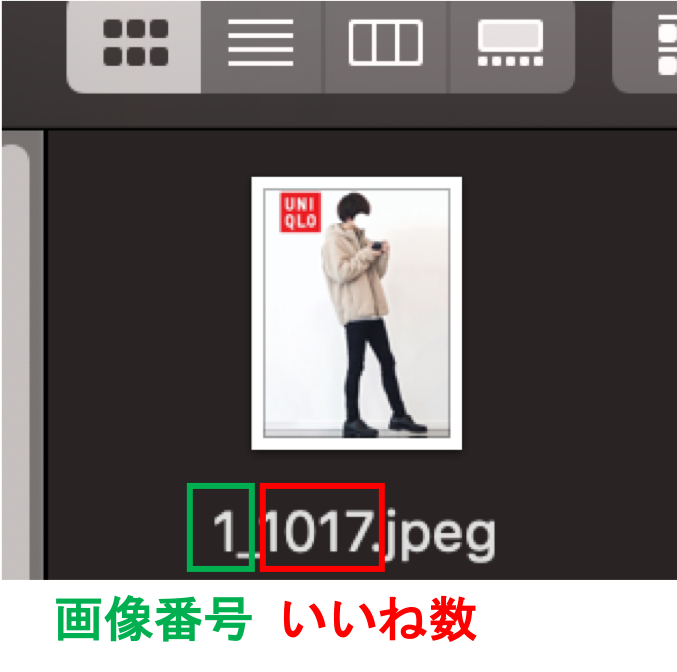
画像の名前に画像番号といいね数をつけています.
モデルの学習
先程も書いた通り今回は画像を入力しそれに対してWEARのいいね数を出力するようにモデルを学習します.また今回はメンズ専用モデルとレディース専用モデルの2つの学習を行いました(男は男の服装,女は女の服装しか評価していないと思ったため).前回同様ResNetの転移学習を行い画像の左右反転やランダムクロップをしてモデルの汎化性能を高めました(データオーギュメントしないと過学習してしまった).訓練画像枚数は男女それぞれ10000枚です.以下はエポック数に対する2乗和誤差のグラフになります.
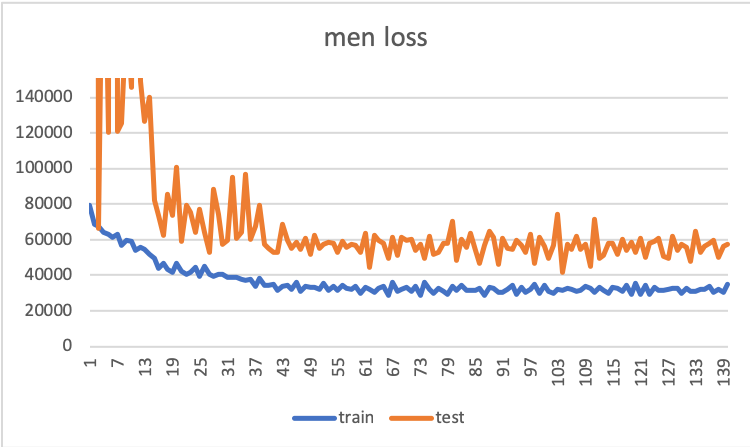
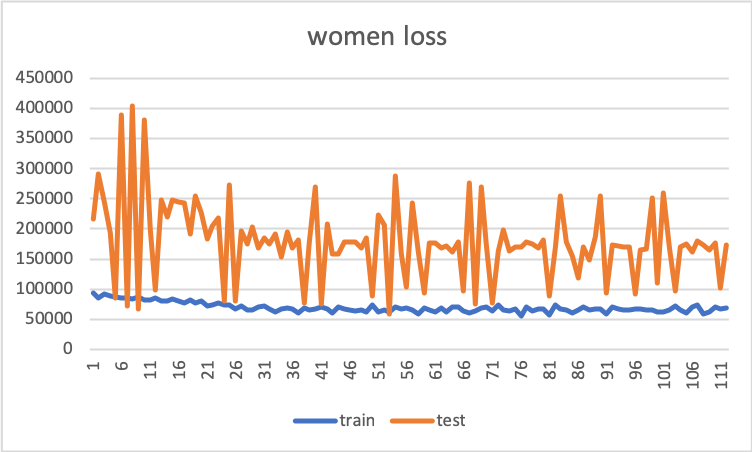
メンズ専用モデルはtest lossがある程度下がっていますが,レディース専用モデルはtest lossの分散がとても大きくあまり汎化性能が出ていない感じがします.
アプリへの組み込み
性別選択画面を追加しました.またswiftで回帰モデルの出力を取り出す方法がわからなかったのですがこちらの記事が大変参考になりました.
今回実装したアプリはGitHubに載せておきます.

考察
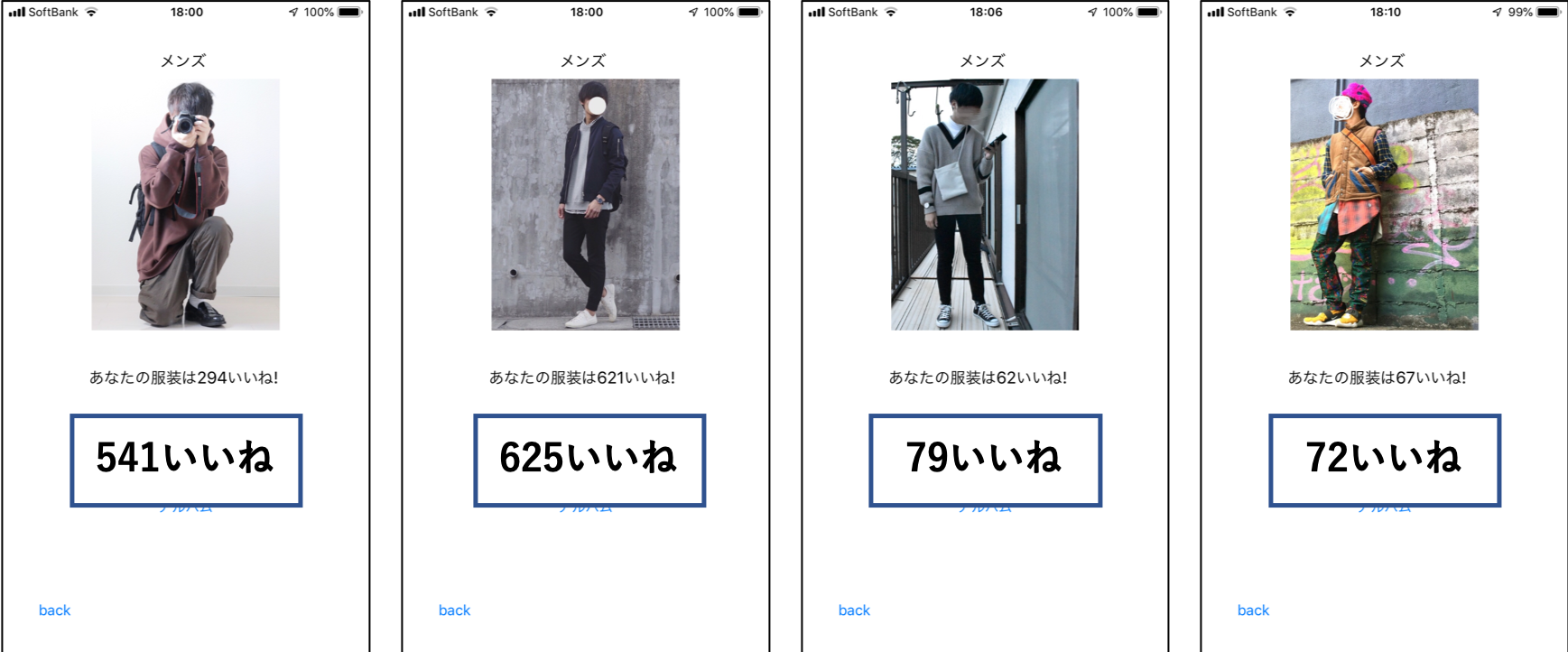
実際にアプリに未学習の画像を入力して確かめたところいいね数が多い服装には大きい値が出力されており,逆にいいね数が少ない服装には小さい値が出力されている傾向にあります.下の枠線の中に書かれているのが正解です.どれもいい感じに予測できています.
まとめ
今回は前回のおしゃれ判定アプリをより真面目に作ってみました.前回作ったモデルよりも少しマシなアプリになったのではないでしょうか.まだまだアプリのUIがダサい点やレディースモデルがあまりうまくいっていない点など問題もあるため少しずつ改善していこうと思います.またこうした方がもっとうまく学習できそうなどの意見がある方は是非コメントよろしくお願いします.