OpenAIの利用がAzure上で開始されました!
OpenAIのサイトからでも申請すればAPIは利用できますが、GPTの機能としてはAzureのものと大きな差はありません。
手元のAzureからすぐに利用できそうなので、Azure上の機能で何か作ってみたいなあ、、、そういえば、Streamlitを使えば簡単にWebアプリ化できるし、これも組み合わせてみよう!
そうだ データサイエンティストをサポートできるなにかをとりあえず作ってみよう!
ということで、CSVファイルを入力してターゲットを設定したら、簡単な予測モデルを作成するpythonコードをChatGPTに作ってもらえるWebアプリケーションをStremlitで作ろうと思いました!
注:AzureからOpenAIサービスは利用申請が別途必要になります。 2023/4/6現在
まとめ
- OpenAIのAPIは簡単に使えます!
- Streamlitを使えば、インプット・アウトプットのUIも簡単に作成でき、2時間たらずで簡単なアプリを作成できました!
- 今回は雑なアイデアでアプリ化してみたが、ChatGPTの入力やアイデア次第では、もっと活用はできそうだと思いました!
画面はこんな感じです!
CSVファイルをアップロードして(今回は適当に作成したダミーデータを使います)、

予測カラム名を選択して、
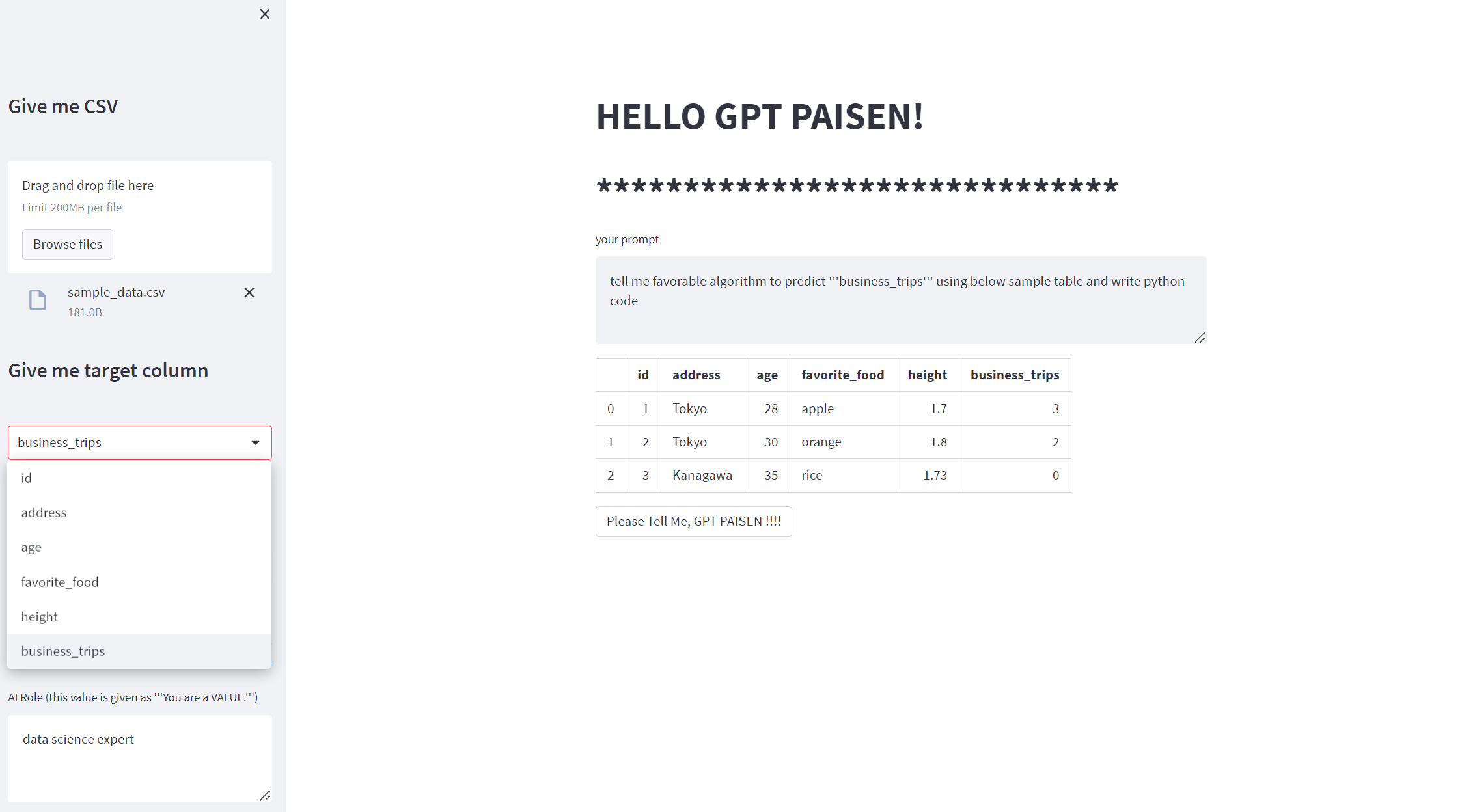
実行ボタン「Plase Tell Me, GPT PAISEN!!!!」をクリックすると、、、予測のpythonコードを書いてくれます!!!

予測カラムのデータタイプがクラスなのか数値なのかも付加情報などで与えた方が良さそうなど、もろもろツッコみどころはある気がしますが、モックアプリが簡単に作れることが体感できました!
作成手順
なお、コードはモックとしてかなり簡単な書き方で書いています。
1. ライブラリのインポート
openai, streamlit, pandas など諸々のライブラリはすでにインストールしてあるとします。
import os
import requests
import json
from io import StringIO
import gc
gc.enable()
import pandas as pd
import streamlit as st
import openai
2. OpenAIのコンフィグ関係の設定
ここでは、AzureのCognitiveServiceから確認できるAPIキー、APIのエンドポイント、デプロイ名称など自分の環境のものを設定します。
openai.api_key = "" ## Azureから確認できるAPI Key
openai.api_base = "" ## Azureから確認できる APIのエンドポイント
openai.api_type = "azure"
openai.api_version = "" ## API バージョン名
_deployment_name = "" ## Azureでデプロイされた名称
3. アプリのUI
ここからは、Streamlitを利用してアプリのUI部分と処理部分を同時に作成していきます!
3.1 タイトル設定
まずは肝心なアプリのタイトルからです!
今回はGPTに教えていただく、ということでGPT PAISENのタイトルにしました。
st.title("HELLO GPT PAISEN!")
st.title("*"*30)
続けて、アプリの左のサイドバー部分を作成していきます。
3.2 サイドバー 1. CSVファイルの読み込み
CSVファイルの読み込み部分では、アップロードのコンポーネントを作成します。
- 読み込まれたら(if文最初)、read_csvでpandasのDataFrameで読み込みます。
- 読み込まれなかったら、(else文)、空のDataFrameを用意します。
3.3 サイドバー 2. ファイルの先頭3行の取得
全てを読み込んでGPTに入力したり、画面上に表示するとかなり非効率なので、今回は先頭3行までを利用します。
3.4 サイドバー 3. ターゲット列の名前の指定
データを読み込んだら、どの列名が予測対象なのかGPTに教えるために、ここでプルダウンの選択式にしています。
もしCSVファイルが読み込まれていたらファイルのカラム列を選択する、ファイルが読み込まれていないなら、選択不可能になります。
3.5 サイドバー 4. GPTのハイパーパラメータ設定
- 4.1では、GPTの出力の最大トークン数を指定します。最大とはいいつつも、あまり出すぎると料金も比例して増えていくので、いったん1000を最大にできるようにしました。 デフォルトは300です。
- 4.2では、temperature(温度)を設定します。ここでいう温度とは、出力のランダム性を示すもので、temperatureが高いほど、出力のたびによりバリエーションに富んだ文章が出力されます。 デフォルト値ではいったん0.8としました。
- 4.3では、GPTに与えるロールの役割を設定します。今回は、予測モデルを作成してほしいので、デフォルトで「data science expert」としています。
with st.sidebar:
## 3.2 CSVファイルを読み込み
st.markdown("# Give me CSV")
_uploaded_file = st.file_uploader("")
if _uploaded_file is not None:
_df = pd.read_csv(_uploaded_file)
else:
_df = pd.DataFrame()
## 3.3 ファイルの先頭3行の取得
_df_sample = _df.head(3)
## 3.4 ターゲット列の名前の指定
st.markdown("# Give me target column")
_target_col = st.selectbox('', _df_sample.columns)
## 3.5 GPTのハイパーパラメータ設定
st.markdown('## GPT Config')
## 3.5 出力の最大トークン設定
_max_tokens = st.number_input("max tokens", 10, 1000, 300)
## 3.5 出力のtemperature設定
_temperature = st.slider('temperature', 0., 1., 0.8, step=0.001)
## 3.5 AIへのロール設定
_system_role = st.text_area("AI Role (this value is given as '''You are a VALUE.''')", value="data science expert")
3.6 プロンプト入力
ここではGPTで最も大切なプロンプト入力のコンポーネントを作成します。
とはいいつつも、今回は予測モデルを作ってほしいので、デフォルトにある程度のテンプレを埋め込もうと思います。
ここで、サイドバー3の入力したカラム名を埋め込むようなコードにしています。これによって、なるべくユーザーには画面をポチっとするだけで操作してもらえるようにしました。
st.markdown(_df_sample.to_markdown()) では、入力したCSVファイルを表示するようにしています。
_text_input = st.text_area("your prompt", value=f"tell me favorable algorithm to predict '''{_target_col}''' using below sample table and write python code")
st.markdown(_df_sample.to_markdown())
st.write('\n\n\n')
3.7 ボタンクリックでGPTへ入力・出力を表示
ここまで準備できたら、あとはGPTのAPIをコールするだけです!
今回はボタンを推したら、APIを呼ぶようにしました。(if st.button(): の構造)
3.8 入力プロンプト整形
GPTに入力するプロンプトを整形します。3.6の入力文章に加え、読み込んだCSVファイルの先頭をマークダウンに落とし込んで入力としてみました。
3.9 APIコール
openai.ChatCompletion.create()を利用しました。
- システムに演じてほしい対象を入力するために、{"role": "system", "content": f"You are a {_system_role}."} で表現しました。
- 入力プロンプトは {"role": "user", "content": _prompt} で表現しました。
- トークン最大長や、温度もそのまま引数で渡しています。
3.10 GPTの出力結果の表示
GPTの結果を取り出し、markdownで表示します。
## 3.7 ボタンクリックでGPTへ入力・出力を表示
if st.button("Please Tell Me, GPT PAISEN !!!!"):
## 3.8 入力プロンプト整形
_prompt = _text_input + '\n' + _df_sample.to_markdown()
## 3.9 APIコール
response = openai.ChatCompletion.create(
engine = _deployment_name,
messages = [
{"role": "system", "content": f"You are a {_system_role}."},
{"role": "user", "content": _prompt},
],
max_tokens = _max_tokens,
temperature = _temperature,
)
## 3.10 GPTの出力結果の表示
_text_output = response["choices"][0]["message"]["content"]
st.markdown("\n\n")
st.markdown(f"[GPT Paisen]\n{_text_output}")
以上でコードは終了です!
約80行ほどのコードでGPT先輩にコードを教えてもらえるアプリができました!
Streamlitもそうですが、OpenAIのAPIもかなり簡単に利用できることが確認できました。
システムに組み込むなどすれば、さらに広い活用先が考えられそうです!
参照元
- Azure OpenAI Service
- OpenAI API
- クイック スタート: Azure OpenAI Service で ChatGPT (プレビュー) と GPT-4 (プレビュー) の使用を開始する
- Streamlit
仲間募集
NTTデータ テクノロジーコンサルティング事業本部 では、以下の職種を募集しています。