std::map と std::unordered_map と boost::flat_map の速度比較をする。
unordered_map と map の速度比較(emplace編) の続き。
この記事の続編はmap, unordered_map, flat_map の速度比較(operator[]編)
結論
boost::flat_map が圧倒的に速い。
次点は概ね std::unordered_map
やったこととやってないこと
やったこと
- C++17 で、
std::map<std::string, int>とstd::unordered_map<std::string, int>,boost::flat_map<std::string, int>の 範囲for文を回して、その部分の時間を測定するコードを書いた。 - 要素数とキーとなる文字列の長さはコマンドライン引数で指定。
- 上記コードからできたバイナリをたくさん呼んで csv化するスクリプトを ruby で書いた。
- 上記コードで出来上がった csv をグラフにするスクリプトを R で書いた。
- 全部実行した。
やらなかったこと
- 範囲for文 以外の操作の時間を測ること
-
<std::string, int>以外のテンプレートパラメータについての調査 - ランダムな文字列以外のキーについての調査
実験に使ったソースコード
C++17
まずは C++17 のソースコード。
c++17(bench.cpp)
// clang++ -std=c++17 -O2 bench.cpp -o bench
# include <iostream>
# include <chrono>
# include <map>
# include <unordered_map>
# include <string>
# include <vector>
# include <cstdlib>
# include <random>
# include <boost/container/flat_map.hpp>
char randchar()
{
static std::mt19937_64 rng(0xbeef);
std::uniform_int_distribution<> dist(1, 255);
return static_cast<char>(dist(rng));
}
template< typename map_t >
map_t prepare(int len, int count)
{
map_t map;
for (int vi = 0; vi < count; ++vi)
{
std::string s;
s.reserve(len);
for (int si = 0; si < len; ++si)
{
s += randchar();
}
map.emplace( std::move(s), vi );
}
return map;
}
template <typename map_t>
void run(int len, int count)
{
map_t map = prepare<map_t>( len, count );
int sum=0;
auto start = std::chrono::high_resolution_clock::now();
for( auto const & [ k, v ] : map ){ // 構造化束縛(C++17)
sum += v;
}
auto end = std::chrono::high_resolution_clock::now();
std::cout
<< std::chrono::duration_cast<std::chrono::nanoseconds>(end - start).count() * 1e-6
<< "ms"
<< "," << sum // 最適化されないように sum を使ってみる。
<< std::endl;
}
int main(int argc, char const *argv[])
{
char type = *argv[1];
int len = std::atoi(argv[2]);
int count = std::atoi(argv[3]);
switch (type)
{
case 'm':
run<std::map<std::string, int>>(len, count);
break;
case 'u':
run<std::unordered_map<std::string, int>>(len, count);
break;
case 'f':
run<boost::container::flat_map<std::string, int>>(len, count);
break;
default:
std::cout << "unexpected type" << std::endl;
}
}
ruby2.6
上記の C++ のコードを走らせて csv に変換するスクリプト
ruby2.6(run.rb)
require "csv"
require "pp"
def run( t, len, count )
r = %x( ./bench #{t} #{len} #{count} ).gsub( /ms.*/, "" ).to_f
[t, len, count, r]
end
N=15
def out(csv,data)
csv << %w( len count u m f )
data.transpose.each do |u,m,f|
csv << [ u[1], u[2], u[3], m[3], f[3] ]
end
end
%x( clang++ -std=c++17 -O2 bench.cpp -o bench )
p :len
CSV.open( "len.csv", "w" ) do |csv|
data = %w( u m f ).map do |t|
N.downto(6).map do |e|
p e
run(t, (10**(e/3.0)).round, 1000) # 平準化のために走らせる
run(t, (10**(e/3.0)).round, 1000)
end
end
out(csv,data)
end
p:count
CSV.open( "count.csv", "w" ) do |csv|
data = %w( u m f ).map do |t|
N.downto(6).map do |e|
p e
run(t, 10, (10**(e/3.0)).round) # 平準化のために走らせる
run(t, 10, (10**(e/3.0)).round)
end
end
out(csv,data)
end
R
上記のスクリプトの実行結果をグラフにする R のプログラム
R(graph.R)
pdf("len.pdf", width=8, height=5) # 8×5 inch
dt<-read.csv("len.csv")
plot(
dt$len,dt$m,
col="red",
type="o",
pch=20,
log="xy",
xlab="string length",ylab="time(ms)",
ylim=c(0.00001,0.1))
lines(dt$len,dt$u,col="blue",type="o",pch=20,xlab="foo",ylab="hoge")
lines(dt$len,dt$f,col="green",type="o",pch=20,xlab="bar",ylab="fuga")
legend("bottomright", legend=c("map", "unorderd_map", "flat_map"),pch=20,col=c("red","blue","green"),lwd=1,lty=1)
dev.off()
pdf("count.pdf", width=8, height=5) # 8×5 inch
dt<-read.csv("count.csv")
plot(
dt$count,dt$m,
col="red",
type="o",
pch=20,
xlab="item count",ylab="time(ms)",
log="xy",
ylim=c(0.0001,10))
lines(dt$count,dt$u,col="blue",type="o",pch=20,xlab="foo",ylab="hoge")
lines(dt$count,dt$f,col=" green",type="o",pch=20,xlab="foo",ylab="hoge")
legend("bottomright", legend=c("map", "unorderd_map", "flat_map"),pch=20,col=c("red","blue","green"),lwd=1,lty=1)
dev.off()
測定結果
結果その1 - 文字列長を変えて、要素数固定
キーになる文字列の長さを変えて測定。要素数は 1000 で固定。
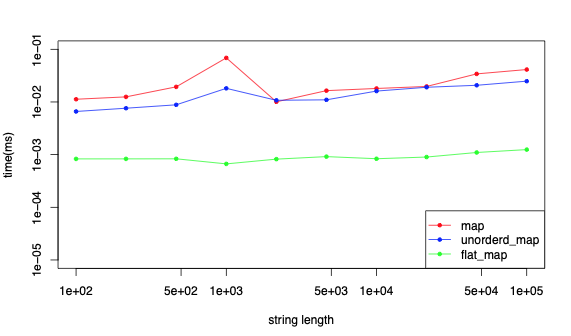
対数目盛注意。
文字列の長さは forループに要する時間に影響を与えない。まあそりゃそうだよね。
速度比較は boost::flat_map の圧勝。10倍ぐらい速い。まあそりゃそうだよね。
std::unordered_map と std::map の対決は、概ね std::unordered_map の勝ち。
もっと差がつくと思っていたけど、辛勝といったところ。
結果その2 - 要素数を変えて、文字列長固定
キーになる文字列は 10文字 固定。要素数を変えて測定。
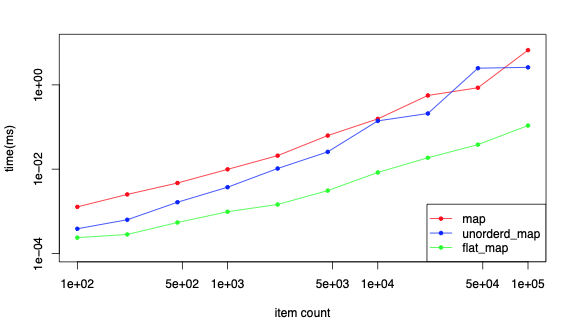
対数目盛注意。
要素数が増えれば forループに要する時間も増える。当たり前だよね。
ここでも boost::flat_map の圧勝。要素数が増えるとなぜか差が開く。なんでだろう。
std::unordered_map と std::map の対決は、概ね std::unordered_map の勝ち。
要素数が多くなると std::unordered_map の優位性は揺らいでくる。なんでだろう。
まとめ
- forループを回している時は、
boost::flat_mapが速い。10倍とかそれぐらい。 -
std::unordered_mapとstd::mapの対決は、概ねstd::unordered_mapの勝ち。でも、その差はあまり大きくない。