はじめに
こんにちは、なじむです。
オミクロンが猛威をふるっていますね…こんな時こそ外出を自粛して、家でコツコツとアップデートを確認するいい機会です。
というわけで今週も張り切ってやっていきましょう!AWS Japan さんがまとめている週刊AWSで確認した内容の自分用メモ。
今回は1/17週のアップデートです。
1/17(月)
1/17(月) は米国の祝日(キング牧師の誕生日)のためアップデートがありませんでした。
キング牧師の本名は "マーティン・ルーサー・キング・ジュニア" で、アフリカ系アメリカ人公民権運動の指導者として活動しました。I Have a Dream ! の名言を残しています(Wikipedia より)
1/18(火)
Amazon Corretto 1 月の四半期更新情報
Corretto は Amazon が提供している無料の OpenJDK ディストリビューションです。現在、LTS (Long-Term Supported) として 8, 11, 17 がありますが、四半期に一度行われるマイナーアップデートが各バージョンに対して行われました。
脆弱性への対応と各種 Issue への対応でした。詳細は各バージョンの Change Log を参照ください。
| Version | Change Log |
|---|---|
| 8.322 | Change Log for Amazon Corretto 8 |
| 11.0.14 | Change Log for Amazon Corretto 11 |
| 17.0.2 | Change Log for Amazon Corretto 17 |
Correto は github からダウンロードできます。
(参考) corretto
- 日本リージョン対応状況 ※OSS のため対応リージョン記載なし
- 東京:-
- 大阪:-
PartiQL API コールが消費するスループット容量を DynamoDB が返し、クエリとスループットコストの最適化を支援
DynamoDB は NoSQL データベースのマネージドサービスです。DynamoDB では、SQL互換の PartiQL を使用することで、SQL ライクに DynamoDB のデータを Select したり Update したりできます。
DynamoDB の読み込み、書き込みにはキャパシティユニットが必要になり、DynamoDB の料金はキャパシティユニットの消費量が大きな要因となります。PartiQL は気軽にクエリができる分、想定外にキャパシティユニットを消費して料金が高額になってしまったり、キャパシティユニットを枯渇させて読み込み/書き込みができなくなってしまう可能性があります。
本アップデートでは、PartiQL API を実行する際に ReturnConsumedCapacity オプションを使用することで、以下の情報を返すことができるようになりました。
- 消費される読み取り/書き込みキャパシティユニットの合計容量
- インデックスの統計
これらの情報により、クエリとスループットコストを最適化しやすくなりました。
実際の動作は以下です。
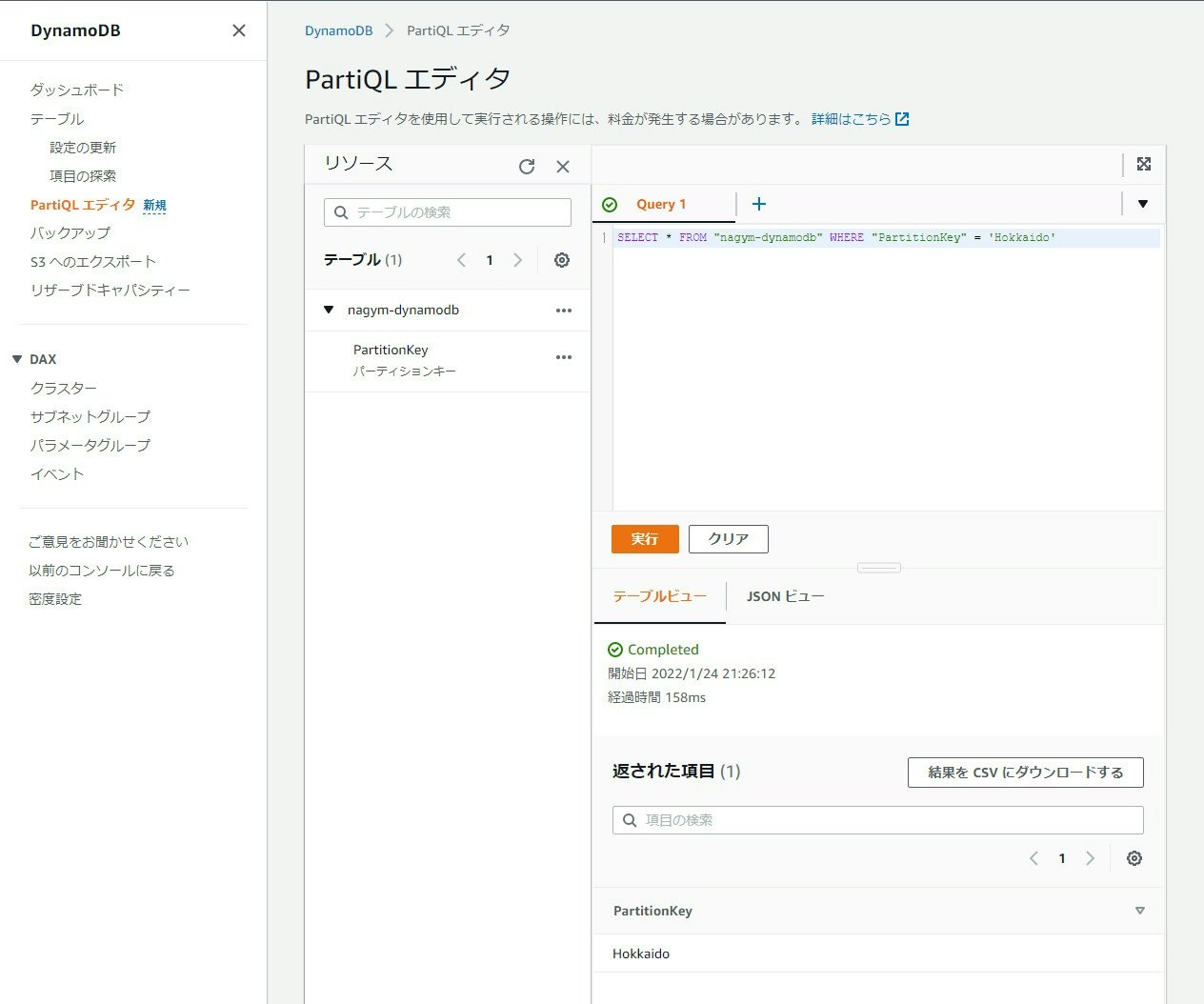
以下のように aws dynamodb execute-statement を実行する際に return-consumed-capacity オプションを使用することで、PartiQL を実行する際に消費されるキャパシティユニットを表示してくれます(CloudShell より実行)
$ aws dynamodb execute-statement --statement \
> "SELECT * FROM \"nagym-dynamodb\" WHERE \"PartitionKey\" = 'Hokkaido'" \
> --return-consumed-capacity TOTAL
{
"Items": [ ★ここは DynamoDB のデータ
{
"PartitionKey": {
"S": "Hokkaido"
}
}
],
"ConsumedCapacity": { ★ここが見えるようになった
"TableName": "nagym-dynamodb",
"CapacityUnits": 0.5
}
}
$
今回のテーブルは非常に小さいデータだったため消費されるキャパシティユニットも少なかったですが、大きなテーブルをクエリする際にはもっと重宝するかもしれません。ReturnConsumedCapacity の詳細は以下を参照ください。
(参考) ExecuteStatement
- 日本リージョン対応状況
- 東京:対応
- 大阪:対応
AWS Elastic Disaster Recovery がフェイルバックオートメーションのサポートを開始
Elastic Disaster Recovery は DR 対策のためのサービスです。オンプレやパブリッククラウドに構築した仮想マシンや DB、 SAP 等のアプリケーションを AWS にバックアップ、AWS 上でのリカバリを行うことが可能です。

(出典) Network diagrams
今回のアップデートでは、DR サイトからオンプレミスの vCenter サーバへのフェイルバックを自動化する機能が追加されました。最新の DRS Mass Failback Automation クライアント (DRSFA クライアント) を利用することで、大規模なフェイルバックを自動化することが可能になります。
利用開始までの大まかな流れは以下です。
- Elastic Disaster Recovery をセットアップする
- オンプレミスの vCenter サーバに Ubuntu Server 20.04 LTS (以下 Ubuntu Server) を構築する
- 構築した Ubuntu Server に、DRSFA クライアントをインストールする
- 適切な権限を持った IAM ユーザと IAM アクセスキーを作成する
- Ubuntu Server で、DRSFA クライアントを起動、設定する(設定時にアクセスキーが必要)
-
$ python3 drs_failback_automation_init.pycを実行して Failback 時の動作を設定する
上述の流れは以下を参照したものです。キャプチャ付きで分かりやすかったのでぜひご覧ください。
(参考) Performing a failback with the DRS Mass Failback Automation client
vCenter Server とかないので実機検証はしていません…
- 日本リージョン対応状況
- 東京:対応
- 大阪:未対応 ※Elastic Disaster Recovery 自体に未対応
1/19(水)
Amazon FSx for NetApp ONTAP が Amazon CloudWatch でパフォーマンスと容量のメトリクスの提供を開始
FSx for NetApp ONTAP は NetApp ONTAP (ファイルストレージ) のマネージドサービスです。

(出典) 新サービス – Amazon FSx for NetApp ONTAP
これまで FSx for NetApp ONTAP のモニタリングを行うためには、NetApp のモニタリングツール (NetApp Cloud Insights や Harvest with Grafana) を使用してモニタリングする必要がありました。本アップデートにより CloudWatch のメトリクスを利用可能になり、追加設定なしでボリュームのパフォーマンスとストレージ使用量のモニタリング、アラームの設定ができるようになりました。
取得できるメトリクスは以下です(各メトリクスの説明は Monitoring with Amazon CloudWatch を参照ください)
|メトリクス|File system metrics|Detailed file system metrics|Volume metrics|Detailed volume metrics|
|--- | --- | --- | --- | --- |--- |
|DataReadBytes|○||○||
|DataWriteBytes|○||○||
|DataReadOperations|○||○||
|DataWriteOperations|○||○||
|MetadataOperations|○||○||
|DataReadOperationTime|||○||
|DataWriteOperationTime|||○||
|MetadataOperationTime|||○||
|StorageCapacity|||○|○||
|StorageUsed|○|○|○|○||
|LogicalDataStored|○||||
|FilesUsed|||○||
|FilesCapacity|||○||
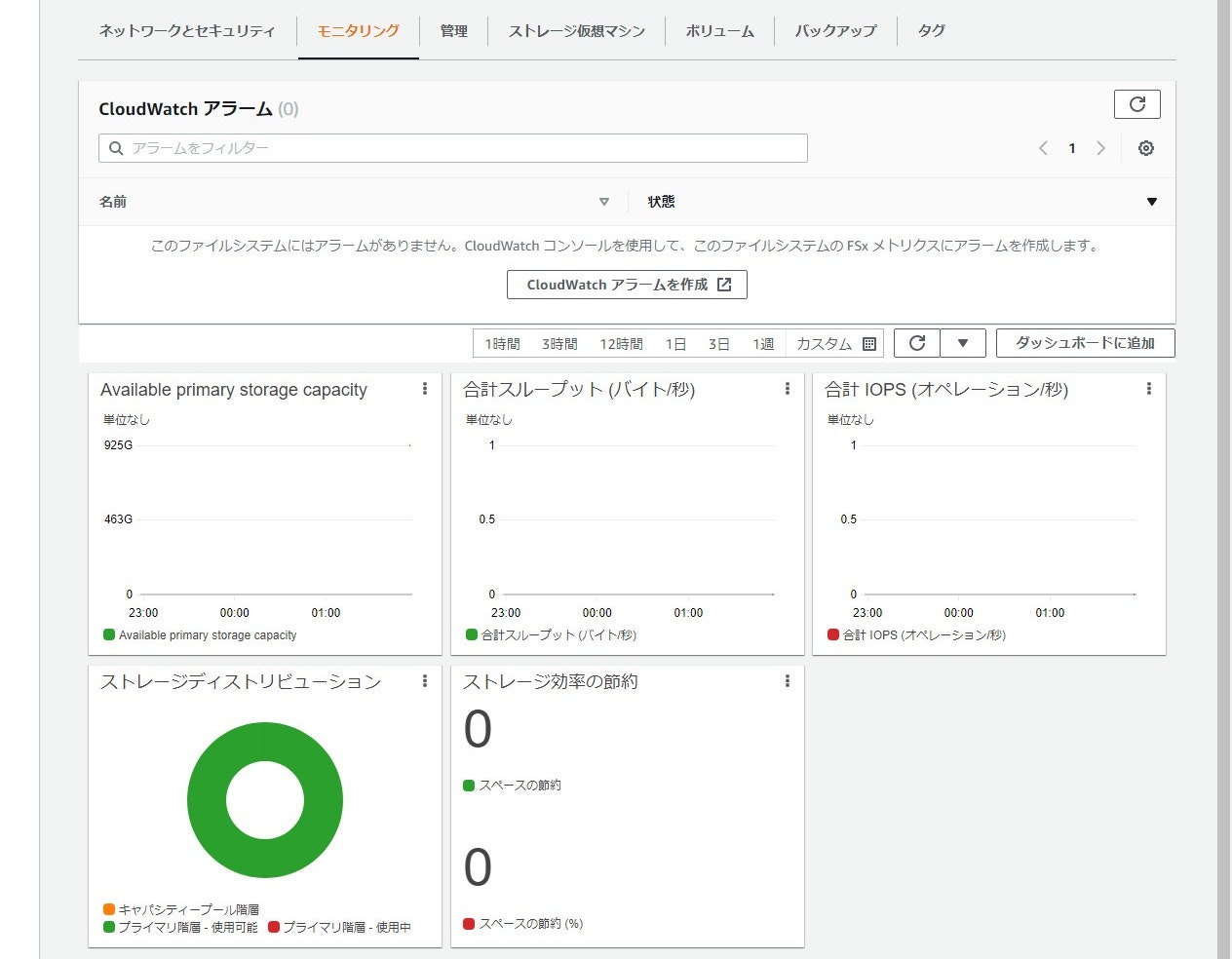
実際の画面は以下です。
FSx for NetApp ONTAP の画面から見るとこんな感じです(起動した直後なので何もない…)
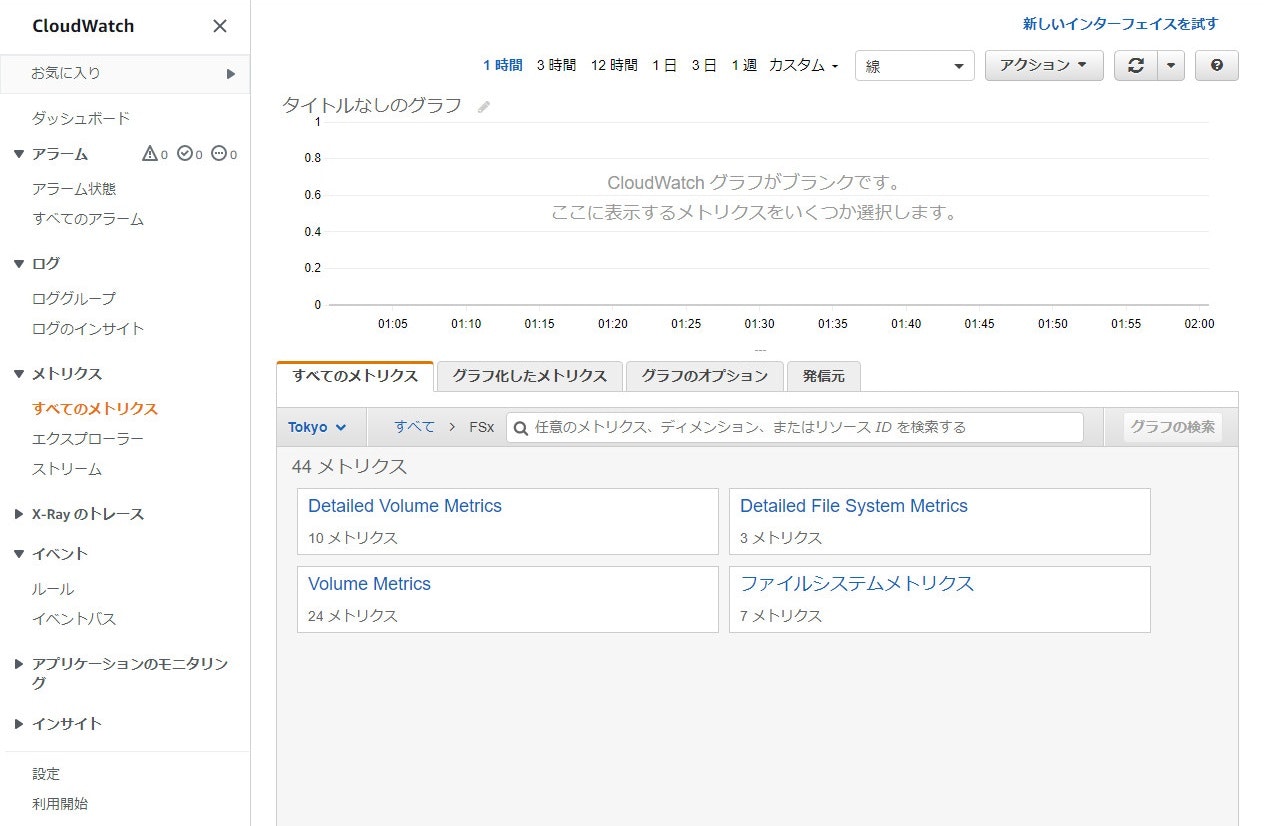
Cloudwatch の画面から見るとこんな感じです(この下の詳細な項目は省きます)
- 日本リージョン対応状況
- 東京:対応
- 大阪:未対応 ※FSx for NetApp ONTAP に未対応
1/20(木)
アジアパシフィック (大阪) における Amazon RDS スナップショットの S3 へのエクスポート機能のお知らせ
RDS はリレーショナルデータベースのマネージドサービスです。
RDS には、スナップショットを Apache Parquet 形式で S3 にエクスポートする機能があります。Apache Parquet 形式はテキスト形式と比較して、エクスポートが速い、S3 でのストレージ使用量が少ないといった特徴があります。エクスポートしたデータは Athena や SageMaker、Apache Spark などを使用して分析することも可能です。本アップデートにより、この機能が大阪リージョンでも使用可能になりました。

(出典) Amazon S3 への Amazon RDS Snapshot Export によるデータレイクの構築とデータ保持ポリシーの実装
実際の画面は以下です。
エクスポートできるようになっています。


エクスポートした S3 を見たところ、RDS に DB を作成していないせいでデータが何もエクスポートされなかった(それはそう…)ため、実際の動作は以下を参照ください。
(参考) [新機能]RDSのスナップショットがS3にエクスポートできるようになりました。
なお、本機能を使用するためには RDS で使用するエンジンのバージョンに指定があったり、S3 は RDS と同じリージョンにないといけない等、いくつが注意が必要です。詳細はホワイトペーパーを参照ください。
(参考) Amazon S3 への DB スナップショットデータのエクスポート
- 日本リージョン対応状況
- 東京:対応
- 大阪:対応
Red Hat OpenShift Service on AWS (ROSA) がアジアパシフィック (大阪) リージョンで利用可能に
Red Hat OpenShift Service on AWS (ROSA) は、Red Hat 社が提供している Kubernetes のプラットフォームである OpenShift を、AWS で動かすためのマネージドサービスです。OpenShift を使用することで、通常の Kubernetes には備わっていない機能を利用できたり、長期サポートを受けられたりします。
実際に構築できていないのですが、大阪リージョンで利用可能になっていました。
やってみた系のブログはクラメソさんのブログが参考になりますのでご覧ください。
(参考) Red Hat OpenShift Service on AWSがGAになったので触ってみた
- 日本リージョン対応状況
- 東京:対応
- 大阪:対応
Amazon EC2 のお客様は EC2 Instance Connect の認証で ED25519 キーが使用可能に
EC2 は仮想マシンのサービスです。
EC2 に接続するためには以下のような方法があります。
- ローカルマシンでターミナルソフトを起動し、SSH 接続する
- セッションマネージャから接続する
- EC2 Instance Connect から接続する
- EC2 シリアルコンソールから接続する
これまで、CLI を使用して "EC2 Instance Connect"、"EC2 シリアルコンソール" の接続をする場合は RSA のキーペアしか使用できませんでした。本アップデートにより、それらのログインに CLI を使用した場合でも ED25519 のキーペアが使用可能になりました。
ED25519 は 2021/8/17 に EC2 へのログインに利用可能になり、従来の RSA のキーペアよりもセキュアとなっています。
(参考) Amazon EC2 のお客様は、インスタンス接続操作中の認証で ED25519 キーを使用できるようになりました
今回は EC2 Instance Connect を使用して実際の動作を確認していきます。
EC2 Instance Connect は、EC2 Instance Connect CLI (mssh) を使用する以外に、独自の SSH キーで接続することもできます。今回は ED25519 キーを新規作成して SSH 接続してみます。実施する前に AWS CLI を最新版にアップデートしてください。
早速ですが、EC2 Instance Connect で接続した結果は以下です(※必要に応じてマスクしています)
$ ssh-keygen -t ed25519 -f nagym-keypair-ed25519
(省略)
$ ls nagym-keypair-ed25519*
nagym-keypair-ed25519 nagym-keypair-ed25519.pub
$ aws --version
aws-cli/2.4.13 Python/3.8.8 Linux/4.14.252-195.483.amzn2.x86_64 exec-env/CloudShell exe/x86_64.amzn.2 prompt/off
$ aws ec2-instance-connect send-ssh-public-key \
> --instance-id i-xxxxxxxxxx \ # マスク
> --availability-zone ap-northeast-1d \ # 適切な AZ に
> --instance-os-user ec2-user \
> --ssh-public-key file://nagym-keypair-ed25519.pub # 適切な keypair に
{
"RequestId": "12345678-abcd-1122-aabb-1234abcd5678",
"Success": true
}
$ ssh -o "IdentitiesOnly=yes" -i nagym-keypair-ed25519 ec2-user@ec2-xxx-xxx-xxx-xxx.ap-northeast-1.compute.amazonaws.com
Last login: Tue Jan 25 11:34:25 2022 from ec2-xxx-xxx-xxx-xxx.ap-northeast-1.compute.amazonaws.com
__| __|_ )
_| ( / Amazon Linux 2 AMI
___|\___|___|
https://aws.amazon.com/amazon-linux-2/
11 package(s) needed for security, out of 17 available
Run "sudo yum update" to apply all updates.
$
ちなみに、AWS CLI が古いと以下のように失敗します。ED25519 に対応していないと公開鍵長が 256 未満は対応していないようです。
$ aws --version
aws-cli/2.4.6 Python/3.8.8 Linux/4.14.252-195.483.amzn2.x86_64 exec-env/CloudShell exe/x86_64.amzn.2 prompt/off
$ aws ec2-instance-connect send-ssh-public-key \
> --instance-id i-xxxxxxxxxx \ # マスク
> --availability-zone ap-northeast-1d \ # 適切な AZ に
> --instance-os-user ec2-user \
> --ssh-public-key file://nagym-keypair-ed25519.pub # 適切な keypair に
Parameter validation failed:
Invalid length for parameter SSHPublicKey, value: 145, valid min length: 256
$
今回は EC2 Instance Connect で確認しましたが、EC2 シリアルコンソール接続の場合も aws ec2-instance-connect コマンドを使用しているため同様のアップデートが適用されています。それぞれの接続方法の詳細は以下を参照ください。
(参考) EC2 Instance Connect を使用した Linux インスタンスへの接続
(参考) EC2 Serial Console for Linux instances
- 日本リージョン対応状況
- 東京:対応
- 大阪:未対応 ※EC2 Instance Connect に未対応(と思われる)
Amazon GuardDuty で、別の AWS アカウントから使用された EC2 インスタンスの認証情報の検出が可能に
GuardDuty は AWS アカウントや AWS に構築した環境に対する脅威検知のためのマネージドサービスです。CloudTrail や VPC Flow Logs、DNS Logs をデータソースとして悪意のあるアクティビティを検知します。

(出典) Amazon GuardDuty
これまで、漏洩した IAM ロールの認証情報が AWS の外で使用される場合は検知ができました。本アップデートにより、漏洩した IAM ロールの認証情報が他の AWS で使用された場合でも検知がで切るようになりました。
以下の操作を実行して検証します。
- AWS Account A(攻撃される側):認証情報を確認
メタデータにアクセスすることで、IAM ロールの認証情報を取得します。
$ curl http://169.254.169.254/latest/meta-data/iam/security-credentials/<role-name>/
{
"Code" : "Success",
"LastUpdated" : "yyyy-MM-ddThh:mm:ssZ",
"Type" : "AWS-HMAC",
"AccessKeyId" : "xxxxxxxxxxxx",
"SecretAccessKey" : "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
"Token" : "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
"Expiration" : "yyyy-MM-ddThh:mm:ssZ"
}
$
- AWS Account B(攻撃する側):認証情報を用いて S3 に対するコマンドを実行
$ export AWS_ACCESS_KEY_ID="上述の出力結果の該当箇所を貼り付け"
$ export AWS_SECRET_ACCESS_KEY="上述の出力結果の該当箇所を貼り付け"
$ export AWS_SESSION_TOKEN="上述の出力結果の該当箇所を貼り付け"
$ aws sts get-caller-identity
(AWS Account A の認証情報であることが分かります)
$ aws ec2 describe-instances
(オブジェクトの一覧が表示されます)
- 実際の GuardDuty の検知画面は以下です。
UnauthorizedAccess:IAMUser/InstanceCredentialExfiltration.InsideAWS が検知されています。
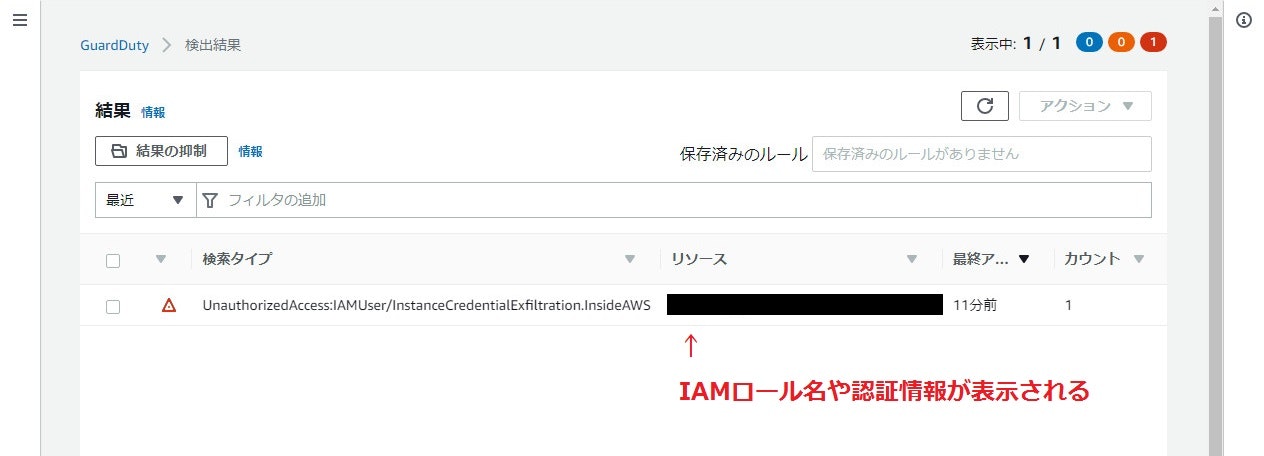
イベントをクリックすると詳細が表示されますが、その内容は公式ブログを参照ください。
(参考) Amazon GuardDuty で EC2 インスタンス認証情報漏洩の検出を強化
- 日本リージョン対応状況
- 東京:対応
- 大阪:対応(おそらく対応していると思います)
Amazon EMR が Apache Spark SQL のサポートを開始し、Lake Formation の統合が有効になっている場合に Glue Data Catalog テーブルへのデータ挿入や更新が可能に
EMR はビッグデータを分析するためのプラットフォームです。Apache Hadoop や Apache Spark 等を使用して、データ分析を行うことができます。

(出典) Amazon EMR
2020/10/9 に EMR 5.31 以降で EMR と Lake Formation の統合が GA となりました。この時は Spark SQL を 用いた参照系の処理(SHOW DATABASES, DESCRIBE TABLE 等)の操作が可能でした。
(参考) Amazon EMR と AWS Lake Formation の統合が一般提供開始
本アップデートでは EMR と Lake Formation の統合に機能を追加し、Spark SQL を用いた更新系の処理(INSERT INTO, INSERT OVERWRITE, ALTER TABLE)が Glue Data Catalog テーブルに対して実行可能になりました。
実機での動作は確認できていませんが、EMR と Lake Formation の統合は以下が参考になると思いますのでご覧ください。
(参考) Lake Formation を使用した Amazon EMR クラスターを起動する
なお、本機能は EMR 5.34 以降でのみ利用可能であり、EMR 6.x.x では利用不可のためご注意ください。
- 日本リージョン対応状況
- 東京:対応
- 大阪:未対応
AWS Lambda がイベントソースとして Amazon MSK、Apache Kafka、Amazon MQ for Apache Active MQ、RabbitMQ の Max Batching Window をサポート
Lambda はサーバレスでコードを実行できるマネージドサービスです。
Lambda では、実行するためのトリガーとして様々なサービスが選択できます。本アップデートでは、以下のメッセージキューイングサービスをトリガーにした場合、一定の間隔(例えば 300 秒)で Lambda を実行するバッチウィンドウを設定できるようになりました。
- Apache Kafka
- Amazon MSK
- RabbitMQ
- Amazon MQ for Apache Active MQ
これにより、一回の実行で Lambda に渡されるレコードの平均数を増やすことができ、呼び出し回数を減らし、コストを削減することが可能です。
その他には、次の条件のいずれかが満たされると、関数が呼び出されます。
- ペイロードサイズが 6 MB に達する
- バッチサイズが最大値に達する
- Max Batching Window が最大値に達する <- New
実際の画面は以下です(例としてMSKを確認します)
バッチウィンドウが設定できるようになっています。
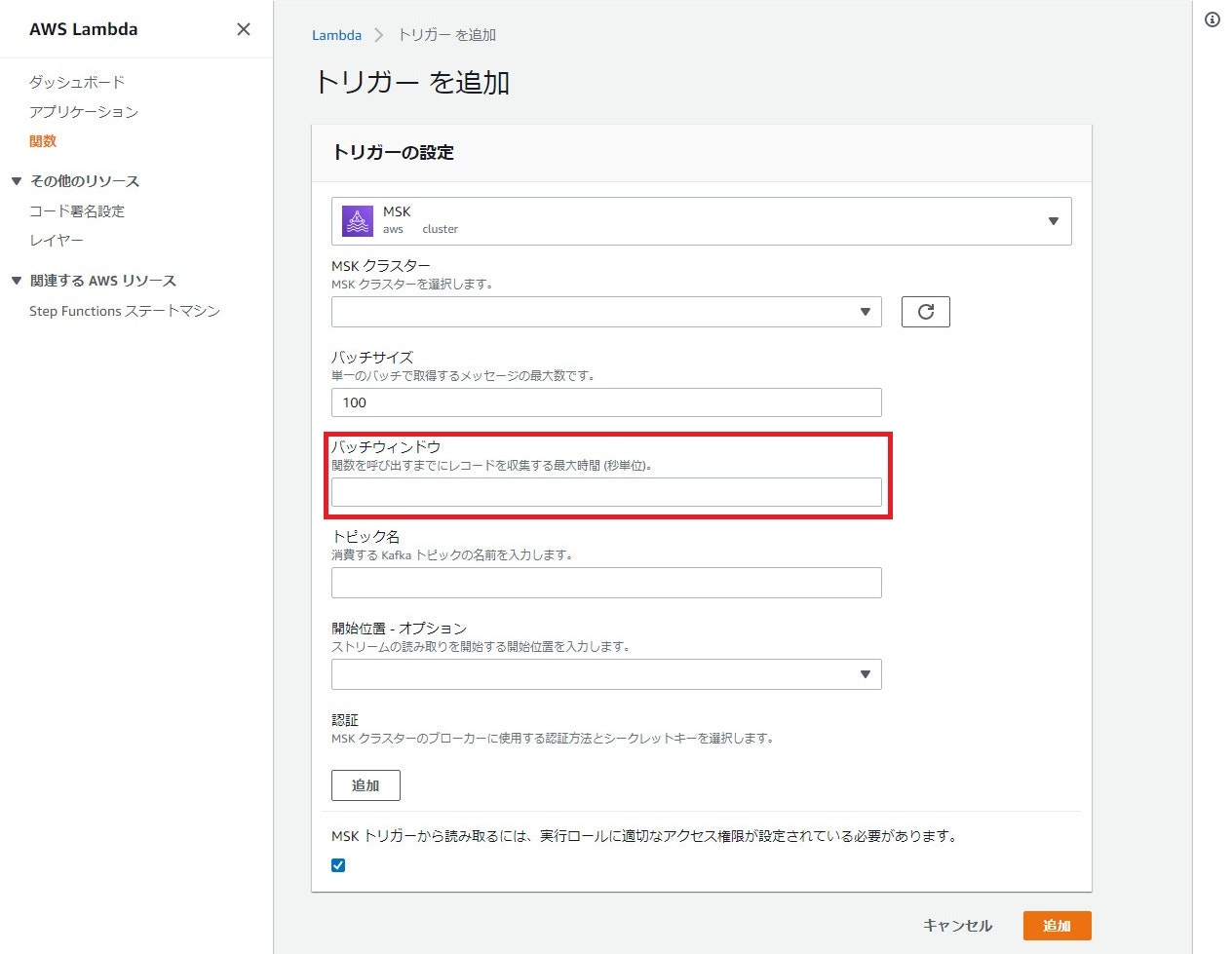
- 日本リージョン対応状況
- 東京:対応
- 大阪:対応
1/21(金)
Amazon EMR がデータレイク向けの高パフォーマンス、並列処理、ACID に準拠しているテーブルフォーマットの Apache Iceberg のサポートを開始
EMR はビッグデータを分析するためのプラットフォームです。Apache Hadoop や Apache Spark 等を使用して、データ分析を行うことができます。
(出典) Amazon EMR
本アップデートでは、EMR 6.5.0 を使用している場合に Apache Iceberg 0.12 が利用可能になりました。Apache Iceberg はテーブルフォーマット形式(テーブルを構成するファイルをどのように管理、整理、追跡するか)の一つです。Iceberg を用いることにより、データレイク(例えば S3)に保存されたデータに対して Spark、Hive、Presto から 更新処理を行うことができるようになります。
Apache Iceberg に関しては、2021/11/29 に Athena が Iceberg に対応した時の以下ブログが非常に参考になりましたのでご覧ください。
(参考) Amazon Athena の Apache Iceberg 対応 previewを試す
EMR で Iceberg を使用するには、クラスター(6.5.0)作成時の詳細設定で classification=iceberg-defaults,properties=[iceberg.enabled=true] の設定を入れてあげれば良いようです。

東京リージョンでも設定自体はできたのですが、アップデートのページには東京/大阪リージョンには対応していないと書いてあったので実際に動作はしないのかもしれません。
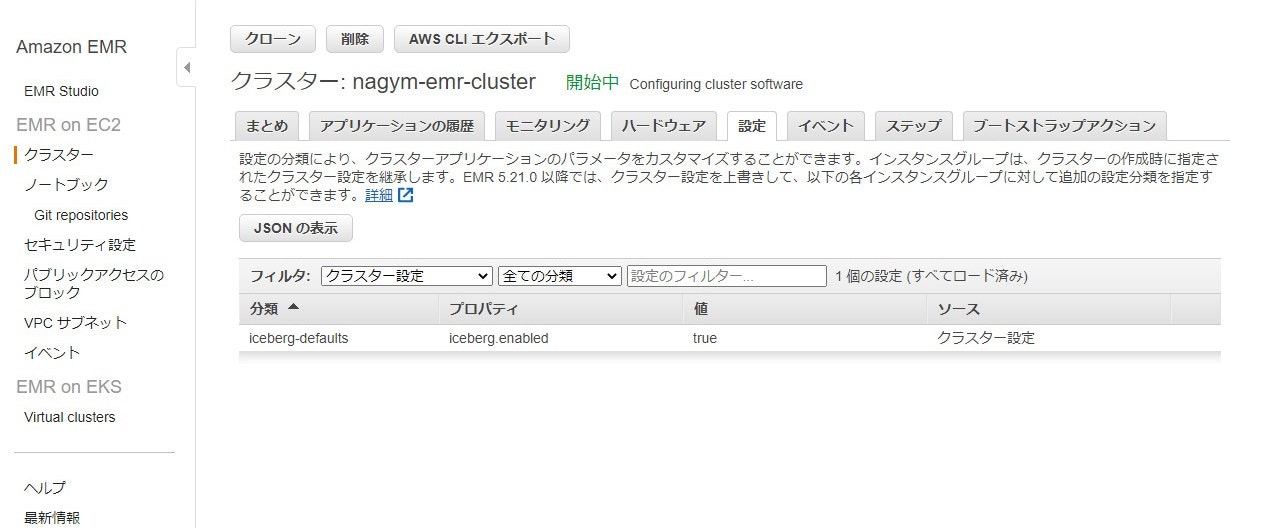
- 日本リージョン対応状況
- 東京:未対応 ※Iceberg 0.12 に未対応?
- 大阪:未対応 ※Iceberg 0.12 に未対応?
感想
投稿が遅くなってしまいました…
時間が取れず実機確認ができないものが多かったので、来週分はしっかり確認していこうと思います。。