こんにちは NSS江口 です。
最近事業部内の勉強会グループで ロバストPython の読書会を行っております。
Pythonの思い出
私がPythonを一番ヘビーに利用していたのは、5年前くらいにサーバレスアプリケーションを構築していた時でした。その時のPythonのバージョンは3.6だったと思います。
私は金融システムに携わる人間で、ファーストチョイスは何かとJavaでしたが、当時利用していた AWS Lambda ではJavaを利用するとクラスロードにかかる初回起動のオーバーヘッドがバカにならず、軽量に利用できるということでPythonを選択したとかだったと思います。なお、Javaの記事も書いておりますので、参考までに。
Javaに触れている期間が長いと、初めてPythonやRubyに触れた時
便利だけど、随分と軟派なプログラミング言語だなあ
という感想を持っており、ツールを手軽に作るための言語だと思っていたのですが、まさかAIやデータ分析、AWS-CLI、Webと広い分野でこんなにも幅を利かせるとは思っておらず、自分の先見の明のなさに呆れております。
世の中にはPythonが本番品質ではないと思っている私のような方もまだまだいらっしゃると思うのですが、前述のロバストPythonの読書会を通じてPythonでも堅牢なコーディングをすることができるということを知りました。
今回はそれを実現することができる型アノテーションという機能を紹介したいと思います。
なお、私が利用しているPythonのバージョンは3.12となります。
型アノテーション
まずは型アノテーションの説明ですが、Pythonにおける引数や戻り値の型のヒントを与えられる機能となります。
Pythonは動的型付け言語であるため、引数にも戻り値にも型を宣言しないで記載することができます。それが開発を軽量にしてくれる利点でもあるのですが、一方で保守をする開発者にとっては意図を組むことを難しくしてしまう欠点にもなってしまいます。
// Javaの場合は必ず引数と戻り値に型を記載
public int calc(int value1, int value2) {
...
}
# Pythonの場合はこんなんでいけちゃう
def calc(value1, value2):
...
このメソッドを使おうと思った際に、Javaの場合ですと型という枠組みがあり、あまりヤンチャできませんが、Pythonの場合はvalue1に文字列を渡しても言語仕様上はよいので、時間がたつにつれて、この関数は何をするものなのか? というポリシーがブレて、堅牢性は失われていくことになります。
型アノテーションの文法
続いて文法です。型アノテーションは以下のように引数と戻り値の型の宣言を行います。
def add(value1: int, value2: int) -> int:
return value1 + value2
型チェッカの導入
型アノテーションを利用する場合、型チェッカであるmypyを利用します。以下の通りpip/pip3でインストールします。
pip install mypy
なお、プロキシの関係で結構躓く方は多いと思うので、その場合は以下のコマンドを打っていただければと思います。
# HTTP_PROXY / HTTPS_PROXYの設定 (http://{ユーザID}:{パスワード}@{ホスト名}:{ポート番号})
set HTTP_PROXY=http://username:password@proxy.xxx.co.jp:8080
set HTTPS_PROXY=http://username:password@proxy.xxx.co.jp:8080
# 信頼済みホストを設定し、pip install
pip --trusted-host pypi.python.org --trusted-host files.pythonhosted.org --trusted-host pipy.org install mypy
なお、そのままではmypyコマンドを実行できない場合があるので、環境変数PathにScriptsディレクトリへのパスを追加お願いします。
私の場合はC:\Users\t-eguchi\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.12_qbz5n2kfra8p0\LocalCache\local-packages\Python312\Scriptsでした。
型チェッカの実行
Pythonは本来の軽量さを損なわないために、型アノテーションに反する型を利用していたとしても実行することはできます。以下のコードはどちらも動作します。
def add(value1: int, value2: int) -> int:
return value1 + value2
# これは実行できるし -> 3
result:int = add(1, 2)
print(f"result = {result}")
# これも実行できる -> "AABB"
result = add("AA", "BB")
print(f"result = {result}")
なので、型チェッカ(mypy)を使って確認することになります。以下がその実行結果です。
PS C:\work\git\robust-python\3\src> mypy .\type_anotation.py
type_anotation.py:8: error: Argument 1 to "add" has incompatible type "str"; expected "int" [arg-type]
type_anotation.py:8: error: Argument 2 to "add" has incompatible type "str"; expected "int" [arg-type]
Found 2 errors in 1 file (checked 1 source file)
はい、こんな感じでintのはずなのに、strを設定しているよ。って注意してくれます。
ファイルを設定すればそのファイルだけをチェックしてくれますし、ディレクトリを設定すれば再帰的に検索してチェックしてくれます。
開発がひと段落したら、ルートディレクトリを設定して、mypyを実行してみるのをお勧めします。
また、型アノテーションを利用しておくと、IDEも親切に教えてくれるので、利用者の生産性を上げる効果も期待できそうです。

型制約
基本的な型アノテーションについて説明しましたが、型制約機能を利用することにより更なる制限をかけることができます。
| 型制約 | 説明 |
|---|---|
| Optional | None参照があることを明記する |
| Union | 扱える複数のデータ型を定義する |
| Literal | 指定できる値をごく一部に制限する |
| Annotated | 扱えるデータ型と値の条件を指定する |
| NewType | 特定のコンテキスト内だけで扱えるデータ型を作る |
| Final | 変数を束縛し変更できないようにする |
Optional型
プログラムをしていると困ったときに無効な値としてNoneをreturnしてしまいがちだと思います。
Optionalを使うことで利用者にNoneが予期する戻り値として返ってくることを提示することができます。(引数に利用することもできます。)
def get_user_name(id: int) -> Optional[str]:
users = {
1: "User1",
2: "User2"
}
return users.get(id, None)
name = get_user_name(1)
print(f"lower name = {name.lower()}")
これに対して、mypyを実行すると
optional.py:11: error: Item "None" of "str | None" has no attribute "lower" [union-attr]
といった具合に
Noneが返ってくる可能性があるから、その場合Noneにはlowerメソッドなんて無いよ。
ということを伝えることができ、以下のようにプログラムを誘導することができます。
name = get_user_name(1)
if name is not None:
print(f"lower name = {name.lower()}")
文字列だとあまりピンとこないかもしれませんが、listの場合などは
-
Noneが返る - 無効値として
空リストが返る - 検索対象が存在しなかったという意味で
空リストが返る
などいろいろと悩むポイントはあるので、意図を正確に伝える意味でも利用していくのが良いと思います。
Union型
型アノテーションの良いところとして、利用側に制約を付けることができるというものですが、これはPythonの特性であるダックタイピングの利点と相反するものになってしまいます。
そんな時にUnionを利用することで、これとこれはOKだよという制約を付けられるため、堅牢なプログラミングをしつつ、ダックタイピングの良さも生かすいいとこどりをすることができます。
class Stock: # 株式
def __init__(self):
self.issueCd = "1301"
self.name = "極洋"
self.price = 4510
class Bond: # 債券
def __init__(self):
self.issueCd = "JGB0172"
self.name = "利付国庫債券(5年)(第172回)"
self.price = 100.19
self.expire_date = date(2029, 6, 20)
class Future: # 先物
def __init__(self):
self.issueCd = "NK2252412"
self.name = "日経225先物24年12月"
self.price = 37723.91
self.expire_date = date(2024, 12, 13)
# 終了日を取得します(債券と先物だけ)
def get_end_date(issue: Union[Bond, Future]) -> date:
return issue.expire_date
# 銘柄ごとの終了日を取得し、表示します
bond = Bond()
end_date = get_end_date(bond)
print(f"end_date = {end_date}")
future = Future()
end_date = get_end_date(future)
print(f"end_date = {end_date}")
stock = Stock()
end_date = get_end_date(stock)
print(f"end_date = {end_date}")
これにmypyを実行すると
union.py:39: error: Argument 1 to "get_end_date" has incompatible type "Stock"; expected "Bond | Future" [arg-type]
といった具合に警告してくれます。使い方がハマれば、かなりの堅牢性向上を期待できます。
Literal型
Literal型を利用することにより、設定される値を制限することができるようになります。オブジェクト指向になれた人間としては、利用するユースケースがあまり想像できませんが、
あまり多様な値を入れたくない場合に利用するとのことでした。
個人的に列挙型でよいのでは?とも思いましたが、列挙型より軽量とのことなので、活躍の場はありそうですね。
from dataclasses import dataclass
from typing import Literal
@dataclass
class Janken:
name: Literal["グー", "チョキ", "パー"] # 3種類だけに制限
goo = Janken("グー")
print(goo)
press = Janken("プレス機")
print(press)
mypyの実行結果は
literal.py:10: error: Argument 1 to "Janken" has incompatible type "Literal['プレス機']"; expected "Literal['グー', 'チョキ', 'パー']" [arg-type]
となります。リテラル型で利用しないとmypyは検知してくれないので、そこが少し不便かもしれません。
Annotated型
Literal型は許可する対象が多くなってくるとやや煩雑になってきますが、これをより柔軟にヒントとして与えることができるようになったものがAnnotated型です。
from typing import Annotated, Optional
from pydantic import Field
# 値を 1 ~ 3 に限定
def get_janken_name(id: Annotated[int, Field(ge=1, le=3)]) -> Optional[str]:
jankens = {
1:"グー", 2: "チョキ", 3:"パー"
}
return jankens.get(id)
name = get_janken_name(1)
print(name)
name = get_janken_name(5)
print(name)
しかし、これはFieldの箇所は評価してくれないようでmypyを実行してみると
Success: no issues found in 1 source file
通ってしまいました。正直コメントとの差別化はあまりできていないように思われます。
これからの進化に期待したいと思います。
↓↓↓ Annotatedの記載について、一部修正させていただきます ↓↓↓
いただいたコメントを踏まえて色々と試してみたところ、Annotatedは制約のためというよりは、JavaでいうAnnotation、C#でいうAttributeと一緒でコードに付与できるメタデータでした。
まだmypyはこれを加味するようにはなっていないようですが、pydanticで値のバリデーションに活用されています。
from typing import Annotated, Optional
from pydantic import BaseModel, Field
class Foo(BaseModel):
positive: Annotated[int, Field(gt=0)]
# エラーが発生しうるため、非推奨とのこと
# (筆者の環境では問題なく動く)
non_negative: Optional[int] = Field(ge=0)
foo = Foo(
positive=1,
non_negative=-1
)
print(foo)
これを実際に実行すると
pydantic_core._pydantic_core.ValidationError: 1 validation error for Foo
positive
Input should be greater than 0 [type=greater_than, input_value=0, input_type=int]
For further information visit https://errors.pydantic.dev/2.9/v/greater_than
このようにpositive > 0 でなければならないというエラーを発生させてくれます。
この記事の静的解析の観点からは少しずれますが、こちらもPythonコードの堅牢性を高めてくれる強力な機能となっていますね。
今はまだmypyでは検出できませんが、サポートされるようになればもっと強力になるかもしれません。
NewType型
既存のクラスから便宜的な新しいクラスを作成することができます。これ自体は型制約というより、便利な機能なのですが、これと型アノテーションを組み合わせることにより、意味付けされたテンポラリなクラスで制約を付けることができるようになります。
from typing import NewType
# 新しいクラスの作成
TrimmedStr = NewType("TrimmedStr", str)
# 新しいクラスに限定
def get_word_count(text: TrimmedStr) -> int:
return len(text)
text = " aaaa "
count = get_word_count(text)
print(count)
trimmed_str = TrimmedStr(text.strip())
count = get_word_count(trimmed_str)
print(count)
mypyを実行すると
new_type.py:9: error: Argument 1 to "get_word_count" has incompatible type "str"; expected "TrimmedStr" [arg-type]
つまり通常のstrではダメで、トリムされたstrが必要という制約をかけることができます。
トリムしない文字列を渡してしまい、期待する動作ができなかったときに、メソッド側を修正してしまいがちですが、NewTypeを利用することにより、メソッドはトリムされたstrを求めているわけだから利用側でトリムしてくれ、ということを明確に伝えることができます。
Final型
これは地味ですが、個人的には最も待望だったかもしれません。pythonは定数が命名規則のみによって提供されていましたが、この機能により変数の再定義を防ぐことができます。
from typing import Final
class Const:
PROGRAM: Final = "PYTHON"
Const.PROGRAM = "Java"
print(Const.PROGRAM)
mypyを実行すると
final.py:6: error: Cannot assign to final attribute "PROGRAM" [misc]
今までは定数といっても結局書き換えられるじゃーんと思っていたので、私の中では最も衝撃でしたね。
Github上でのプルリクエスト時のmypyチェック
githubなどでプルリクエストをマージする際のルールに適用できたりしないの?
というコメントをメンバーよりもらいました。
確かにそこまでやってしまえば、いちいち手元でmypyを実行しなくてよいため、
より手軽にチェックを行うことができるなと感じましたので、挑戦してみました。
どうやらプロジェクト直下に.github/workflowsディレクトリを作成し、
その中に*.ymlを置いておけばその内容にしたがってチェックしてくれるようです。(ありがとうCopilot!!)
mypy-check.ymlというファイルを以下のように作成しました。
name: Mypy Check
on: [pull_request]
jobs:
mypy:
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v2
- name: Set up Python
uses: actions/setup-python@v2
with:
python-version: "3.12" # 使用するPythonのバージョンを指定
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install mypy
- name: Run mypy
run: mypy mypy/src # プロジェクトのディレクトリを指定
これでmypyのエラーがある状態でプルリクエストを作成すると
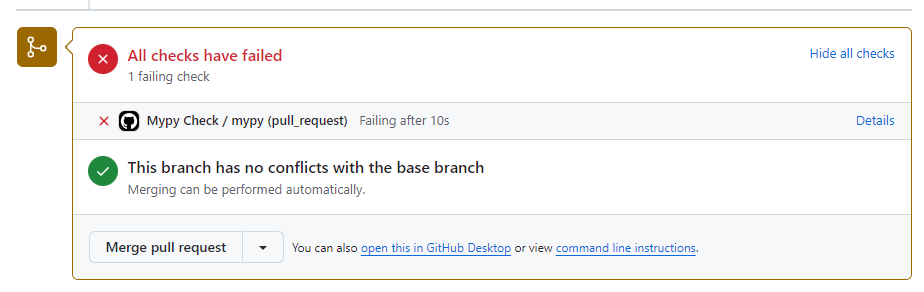
こんな感じでエラー判定してくれてマージができません。Detailをクリックすると
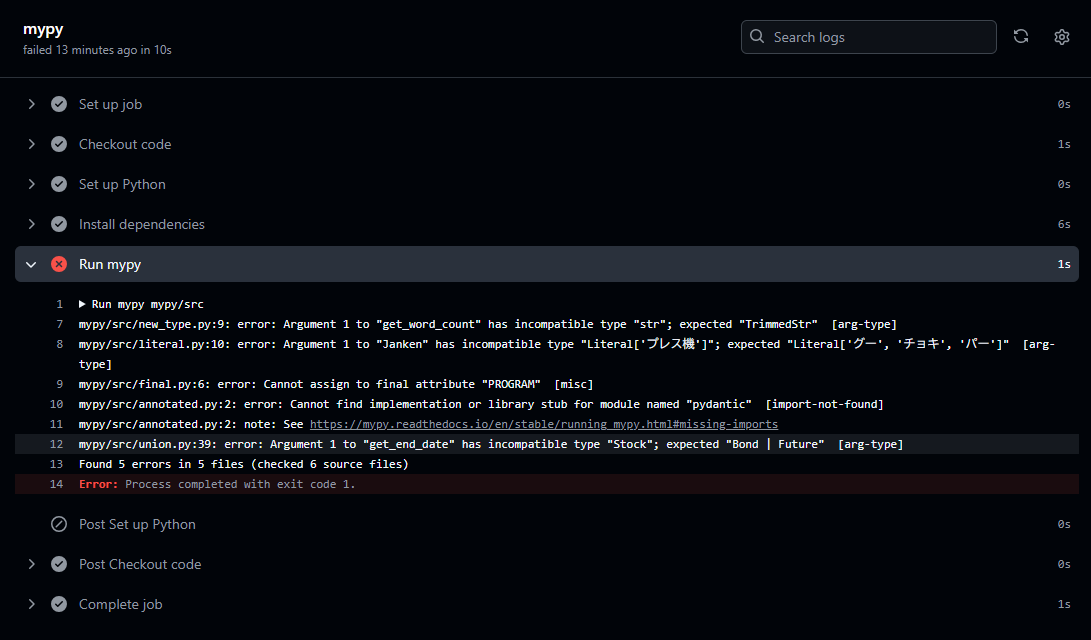
明細も表示されます。これをmypyエラーが出ない状態に修正し、再びプルリクエストを出すと
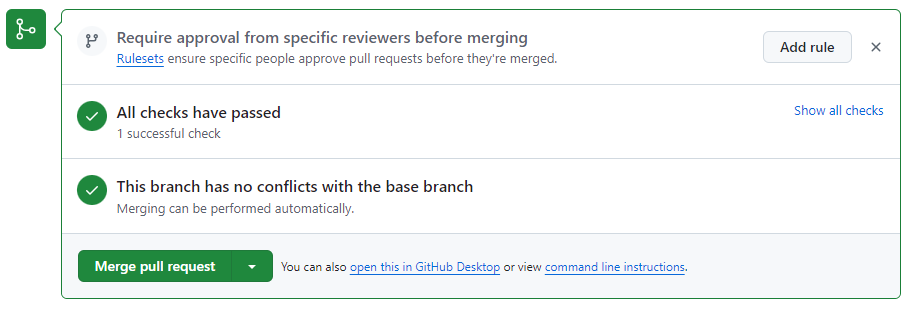
はい、これで無事にmypyチェックも通り、マージすることができるようになりました!
まとめ
プログラムに制約をかけるとはいっても、Pythonはやはりスクリプト言語なので、制約に反していたとしても実行はできてしまいます。
これは高々テキストを加工したいだけなのに、いちいち注意されて実行できなかったらまどろっこしくて仕方がないので、しょうがないことだと思います。
ただし、軽量で便利な言語から堅牢にも作れる言語に進化していると思いますので、さらなるPythonの飛躍を期待したいと思います。