はじめに
この記事は、自身で製作しWeb公開にまで至ったボートレース3連単予測サイト「きょう、ていの良い予想は当たるだろうか」の内部コード解説となります。今回は機械学習モデルに関してまとめていきます。そもそものデータ取得や整形に関しては別記事を作成しますので、そちらをご覧ください。
※コードの書き方は我流なので、アドバイスいただけると有り難いです。
ランキング学習とは?
使えるようになるにあたり、以下の記事を大変参考にしました。
ランキング学習とは、相対的な順序関係を学習するための方法と言われております。
上記リンクのように、競馬や競艇などのような複数人(馬)の相対的な強さを学習するのに向いているんじゃないかな、と思い取り組んでみました。
論文はまだ積ん読されていますが(笑)、まずは使ってみようと思います。
使用するライブラリはlightgbmです。
Queryデータセットを準備する
今回は2020年1月〜4月を学習データ、2020年5月のデータを検証データとします。
ランキング学習の特徴として、「Queryデータ」があります。このQueryデータは、1つのレースに含まれている学習データの数を表します。ボートレースの場合はトラブルがなければ6艇でレースが行われるので、
Queryデータの箱 = [6,6,6,...,6]
といった、(欠場者がいなければ)”6”がレース数分だけ並んだリストができあがるはずです。
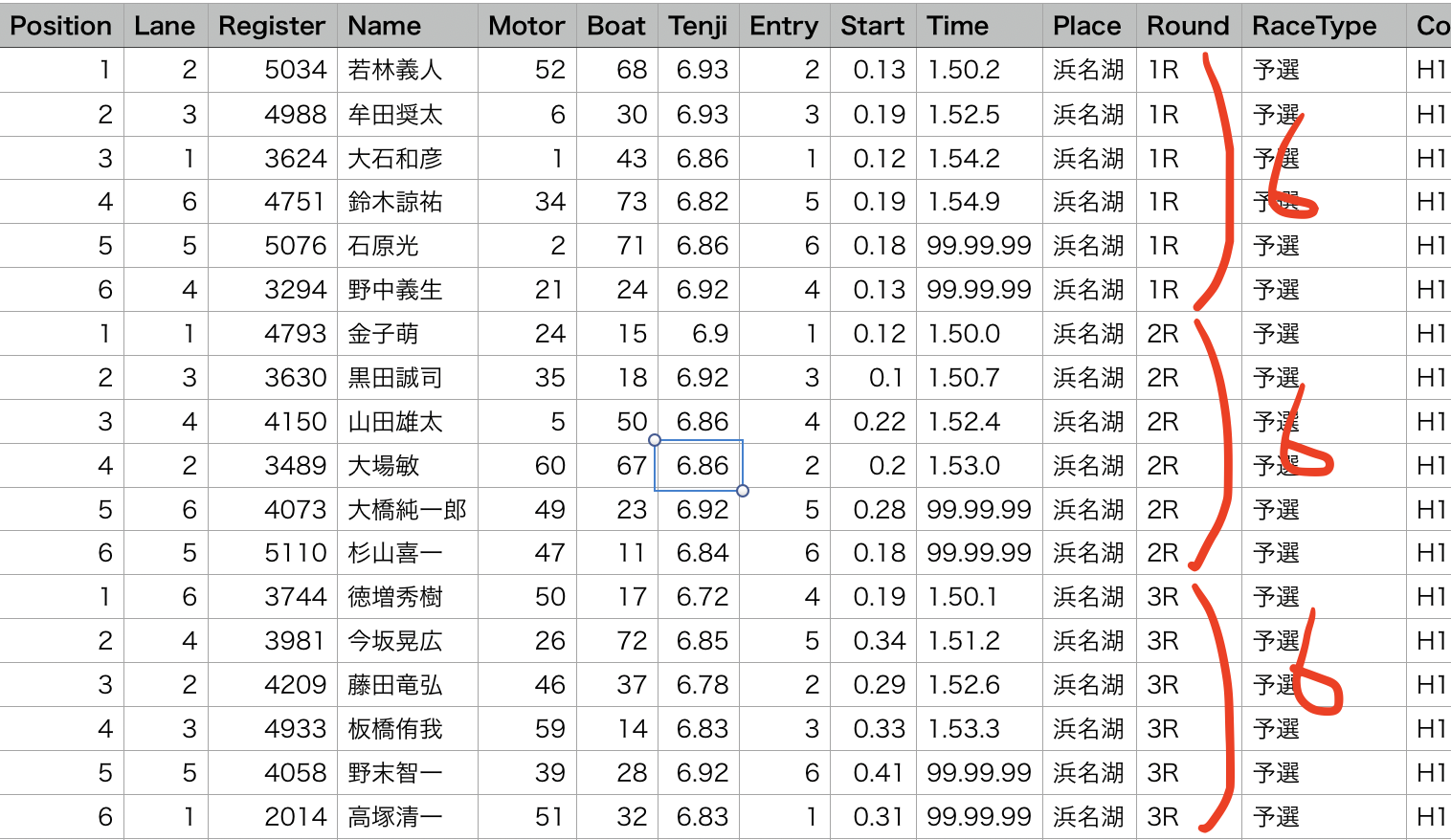
ということで以下のコードでQueryデータの箱をつくっていきます。
%%time #時間を測る
target_cols = ["Position"]
feature_cols = ["Name","Lane","Round","Month","Place"]
train = pd.read_csv(train_file)
train_shuffle = pd.DataFrame([],columns=train.columns)
train_group =[]
for i,k in enumerate(train["Round"]):
if i == 0:
temp = k
temp2 = i
else:
if k == temp:
pass
else:
train_group.append(i-temp2)
#↓ .sampleでシャッフルしたデータにする。
train_shuffle=train_shuffle.append(train[temp2:i].sample(frac=1))
temp = k
temp2 = i
# 最後の組が含まれていないのでを追加
train_group.append(i+1-temp2)
train_shuffle=train_shuffle.append(train[temp2:i+1].sample(frac=1))
train_y = train_shuffle[target_cols].astype(int)
train = train_shuffle[feature_cols]
print(train.shape)
read_csvで読んでいるtrain fileは取得した競艇テキストデータからデータフレームを作成するの記事をもとにできあがっています。
同じレース(Round)の数をかぞえ、train_groupのリストに格納しています。そして参考記事を読んだところ、**このグループ内の順序をシャッフルしておかないとヤバいことになる、、**との事だったので、train_shuffleに格納する際に.sampleでシャッフル処理をしています。
上記のコードを検証用データセットにも行い、検証用Queryデータセットを作成しておきます。
LightGBMを使用する
欠損処理やFeature engineering、One-hot encodingなどは割愛させていただきますが、学習データセット、Queryデータセットが準備できれば今の世の中、機械学習の実行は簡単です。ただ一点、lightgbmの仕様なのか、日本語がカラムに入っているとエラーが発生します。そのため以下のような処理を加えました。
column_list = []
for i in range(len(comb_onehot.columns)):
column_list.append(str(i)+'_column')
comb_onehot.columns = column_list
※comb_onehotというDataFrame型はTrain datasetとValid datasetを結合し、One-hot encodingを処理した際につくられたデータフレームです。この処理の後、
train_onehot = comb_onehot[:len(train)]
val_onehot = comb_onehot[len(train):]
として、学習用と検証用に再分離しました。
さて、機械学習を実施します。
import lightgbm as lgb
lgbm_params = {
'task': 'train',
'boosting_type': 'gbdt',
'objective': 'lambdarank', #←ここでランキング学習と指定!
'metric': 'ndcg', # for lambdarank
'ndcg_eval_at': [1,2,3], # 3連単を予測したい
'max_position': 6, # 競艇は6位までしかない
'learning_rate': 0.01,
'min_data': 1,
'min_data_in_bin': 1,
# 'num_leaves': 31,
# 'min_data_in_leaf': 20,
# 'max_depth':35,
}
lgtrain = lgb.Dataset(train_onehot, train_y, group=train_group)
lgvalid = lgb.Dataset(val_onehot, val_y,group=val_group)
lgb_clf = lgb.train(
lgbm_params,
lgtrain,
num_boost_round=250,
valid_sets=[lgtrain, lgvalid],
valid_names=['train','valid'],
early_stopping_rounds=20,
verbose_eval=5
)
num_leavesなどのハイパーパラメータは調整するべきですが、ここでは考えず進みましょう。
検証データに対する予測はこんな感じ。ほんと、便利な時代です..。
y_pred = lgb_clf.predict(val_onehot,group=val_group, num_iteration=lgb_clf.best_iteration)
結果は...
ランキング学習による3連単予測は以下のようになりました。3連単は8.15%..!!

ちなみに上記の的中率(特に2連単や3連単)を手に入れるため、以下のようなコードを書きました。う〜ん、冗長!
# Validデータ的中率の算出
j = 0
solo_count = 0
doub_count = 0
tri_count = 0
for i in val_group:
result = y_pred[j:j+i]
ans = val_y[j:j+i].reset_index()
result1st = np.argmin(result)
if len(np.where(result==sorted(result)[1])[0])>1:
result2nd = np.where(result==sorted(result)[1])[0][0]
result3rd = np.where(result==sorted(result)[1])[0][1]
else:
if i > 1:
result2nd = np.where(result==sorted(result)[1])[0][0]
if i > 2:
result3rd = np.where(result==sorted(result)[2])[0][0]
ans1st = int(ans[ans["Position"]==1].index.values)
if len(ans[ans["Position"]==2].index.values)>1:
ans2nd = int(ans[ans["Position"]==2].index.values[0])
ans3rd = int(ans[ans["Position"]==2].index.values[1])
else:
if i > 1:
ans2nd = int(ans[ans["Position"]==2].index.values[0])
if i > 2:
ans3rd = int(ans[ans["Position"]==3].index.values[0])
if ans1st==result1st:
#print(ans1st,result1st)
solo_count = solo_count+1
if i > 1:
if (ans1st==result1st)&(ans2nd==result2nd):
doub_count = doub_count+1
if i > 2:
if (ans1st==result1st)&(ans2nd==result2nd)&(ans3rd==result3rd):
tri_count = tri_count+1
j=j+i
print("単勝的中率:",round(solo_count/len(val_group)*100,2),"%")
print("2連単的中率:",round(doub_count/len(val_group)*100,2),"%")
print("3連単的中率:",round(tri_count/len(val_group)*100,2),"%")
さいごに
上記の結果は何も考えずに買うよりは高い的中率です。(最も高い頻度で起こる3連単の組み合わせが"1-2-3"であり、その頻度は7%程度)
ただ、この結果だけだと的中率として心許ないので、もう一工夫が必要と感じました。
そこのところはまた別記事にてまとめたいと思います。