はじめに
この記事は、自身で製作しWeb公開にまで至ったボートレース3連単予測サイト「きょう、ていの良い予想は当たるだろうか」の内部コード解説となります。今回はデータフレーム作成に関してまとめていきます。そもそものデータ取得に関しては別記事を作成しますので、そちらをご覧ください。
※コードの書き方は我流なので、アドバイスいただけると有り難いです。
DataFrame化したい元データ
下スナップはボートレース公式からダウンロードできるテキストデータですが、このレース結果を用いてランキング学習をしていきたいので、今回は黄色で囲んだ内容をデータフレームとして整形していきます。
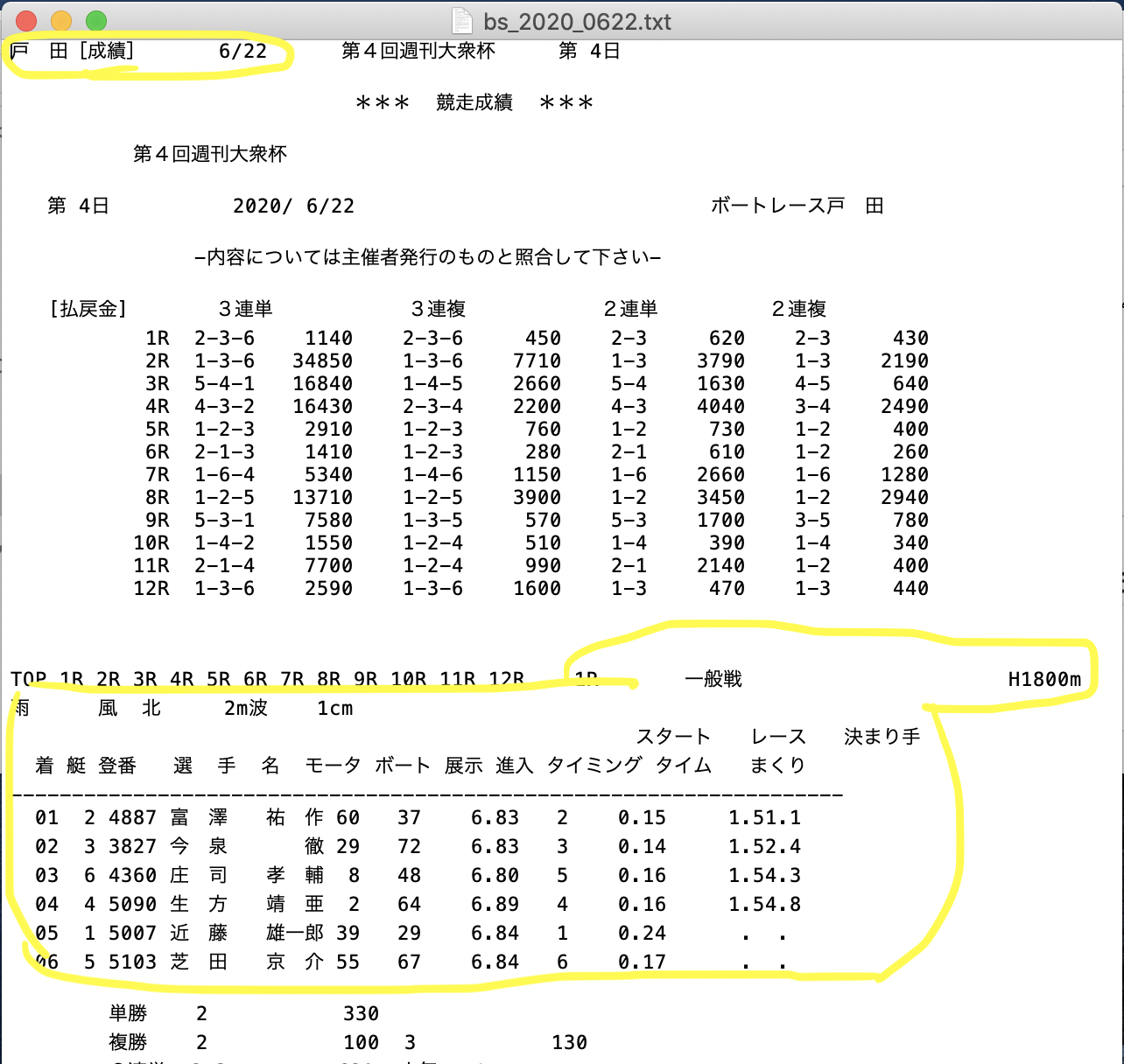
不要なワードや空白スペースの処理
例えば、上図は戸田競艇場の1Race目の情報ですが、「戸田」も「戸 田」となっていたり、全角スペースの存在などが気になります。なので、まずはそのあたりの処理を行います。
import pandas as pd
import numpy as np
filename_txt = 'bs_2020_0622.txt' #オリジナルテキストデータ
output_raw = '2020_0622_raw.txt' #処理後その1_空白処理後のテキストデータ
with open(filename_txt, mode='r', encoding='utf-8') as f:
lines = f.readlines()
for i in range(len(lines)):
with open(output_raw, mode='a', encoding='utf-8') as f:
f.writelines(lines[i].replace("選 手 名","選手名").replace("m波","")\
.replace("cm","").replace("進入固定","")\
.replace("〜","").replace("!","").replace("(","")\
.replace(")","").replace("・","").replace("−","")\
.replace(" ","").replace(" "," ").replace(" "," ")\
.replace(" "," ").replace(" "," ").lstrip())
なんやこのreplaceの山..と思われるかもしれません。より良いアイデアや書き方があれば教えていただけると助かります。
いずれにせよ、オリジナルデータを1行ずつ読み込み、replace処理をかけることでテキストファイルは下図のようになりました。余計な空白(+ワード)が処理できましたね。

正規表現などによるデータ抜き出し
1枚目のスナップの黄色枠で示したように欲しい情報が各テキスト行に散らばっております。データフレーム化する最後の一処理として、欲しい情報が全ての行に記載されるような工夫をします。
import re
output_txt= '2020_0622_txt.txt' #処理後その2_正規表現処理後のテキストデータ
place_list = ['福岡[成績]','大村[成績]','桐生[成績]','戸田[成績]'\
,'多摩川[成績]','浜名湖[成績]','蒲郡[成績]'\
,'常滑[成績]','津 [成績]','琵琶湖[成績]','住之江[成績]'\
,'鳴門[成績]','丸亀[成績]','宮島[成績]'\
,'徳山[成績]','下関[成績]','若松[成績]','三国[成績]'\
,'平和島[成績]','芦屋[成績]','児島[成績]',\
'江戸川[成績]','尼崎[成績]','唐津[成績]']
pattern_list = ['TOP 1R 2R 3R 4R 5R 6R 7R 8R 9R 10R 11R 12R']
pattern = 'TOP 1R 2R 3R 4R 5R 6R 7R 8R 9R 10R 11R 12R (\w+ \w+ \w+ \w+ \w+ \w+ \w+ \w+)'
repattern = re.compile(pattern)
pattern2_list = ['着 艇 登番 選手名 モータ ボート 展示 進入 タイミング タイム']
pattern2 = '着 艇 登番 選手名 モータ ボート 展示 進入 タイミング タイム (\w+)' #'
repattern2 = re.compile(pattern2)
pattern3_list = ['第']
# 空白処理を行ったレース結果を1行ずつ読み込み
with open(output_raw, mode='r', encoding='utf-8') as f:
lines = f.readlines()
# 空のテキストデータを用意
text = ''
text2 = ''
text3 = ''
# 1行ずつ、patternに当てはまる行が存在するか確認していく
for i in range(0,len(lines)):
with open(output_txt, mode='a', encoding='utf-8') as f:
if pattern_list[0] in lines[i]:
#search関数を使って当てはまるかを確認します
match = re.search(repattern, lines[i])
#抽出した文字列を出力します
try:
text = match.group(1)
except:
print(str(lines[i]),i," こやつちょっとエラー")
if pattern2_list[0] in lines[i]:
#search関数を使って当てはまるかを確認します
match = re.search(repattern2, lines[i])
#抽出した文字列を出力します
try:
text2 = match.group(1)
except:
print(str(lines[i]),i," こやつちょっとエラー2")
text2 = "blank"
if pattern3_list[0] in lines[i]:
#抽出した文字列を出力します
text3 = lines[i].replace("第","").replace("/"," ")
for j in place_list:
if j in lines[i]:
k = j.replace("[成績]","")
f.writelines(lines[i])
break
f.writelines(lines[i].replace('. .','.').rstrip()+" "+k+" "\
+text+" "+text2+" "+text3+"\n")
もうちょっといい方法はないんかな..と思いながらもこれにより、以下のようなテキストデータができあがります。今回欲しいレース情報のところに天気であったり日付であったりが入ってきているのが、お分かりいただけるでしょうか..

ようやく、データフレーム化!!
ここまできたら、あと少しです。このテキストデータで私が欲しい情報は上図で書き込んだ赤枠の範囲のみ。つまりテキスト行の先頭文字が"0"から始まる行をデータフレームとして取り込んでいくこととなります。
df = pd.read_table(output_txt, names='A') #カラム名"A"でデータフレームを作成
df_racer = df[df['A'].str.startswith('0')] #"0"から始まる行のみを取得
df_racer = df_racer['A'].str.split(' +', expand=True)\
.rename(columns={0:'Position',1:'Lane',2:'Register',3:'Name',4:'Motor',5:'Boat'\
,6:'Tenji',7:'Entry',8:'Start',9:'Time',10:'Place'\
,11:'Round',12:'RaceType',13:'Course',14:'Wether'\
,15:'Wind',16:'WindDir',17:'WindStr',18:'WaveHgt'\
,19:'RaceResult',20:'RaceDay',21:'Year',22:'Month'\
,23:'Day',24:'Location'})
df_racer = df_racer.reset_index()
半角空白スペースによって各情報は区切られているので、split(' +')とrename処理によって、意味を定義していきます。
そしてできあがったデータフレームがこんな感じ。やったね!
df_racer.head()

おわりに
このテキストデータをデータフレームに変える、という処理はとても大変でした...。見やすいフォーマットと、データ処理しやすいフォーマットは別ということでしょうか。
テキストデータ何個つくってるの?!という感じもしますし、もっとスマートに記述したいなとも思っています。いつかアップデートする..のだろうか..