
コピペで利用して頂けることを目指しつつも、お手元のデータに適用するためには、当記事で紹介させて頂くサンプルクエリを参考に、お使い頂く環境に応じてSQLを一部手直し頂く必要があるため、『SQLを少し読める方』向けの内容です。
SQLの実行環境は、『BigQuery』を想定しています。
BigQuery以外の環境ではクエリの手直しが必要になる場合がありますのでご了承ください。
はじめに
こんにちは、@N1_Data_Ninjya_U です。
普段はニフティ株式会社でData Ninjaとして、分析などのデータ活用の仕事をしています。

N1!Data Ninjaについて詳しくはこちら
ニフティでは、ニフティで「いちばん」その分野に詳しい人、もしくは、いずれ「いちばん」になりうる人、という意味を込めて、N1!(NIFTY No.1)と命名し、職種を問わず、様々な分野で活躍している社員の活躍を後押しするための制度があります。
私は、そのN1!制度の中で”データを使って色々分析や活用”という分野でN1!を頂き、
N1!Data Ninjaという肩書で仕事をしております。※Data Ninjaとは、アメリカの一部で流行っている肩書で、
一般的には
・データアナリスト
・データサイエンティスト
・データエンジニア
などを指す肩書ですが、弊社では
”データを使って色々分析や活用をする人”のような意味で使われています。
本記事では、データ分析において、同じような悩みを抱える方の助けとなればと思い、
データ分析に関する小ネタテクニックをご紹介させて頂きます。
少しでもお悩み解決の助けとなれば幸いです。
また、ニフティでは一緒に働いて頂ける仲間を募集しております!
もし本記事をきっかけにニフティに興味を持って頂けましたら、
就職先・転職先の候補の1つとして、ニフティを選択肢に入れて頂ければ幸いです。
『最初から使いやすいデータなんて存在しない!
『分析用に使いやすい形式でデータが最初からあるとは限らない』
これは色々データ分析をしてきた中での私の中での教訓です。
基本的にログやシステム管理上のデータを引っ張ってきて分析をする
わざわざ分析に都合よい状態で整形済のデータは、あればラッキーですが最初からあることを期待してはいけません。
- 『扱いやすい形でデータがないと、一切分析できません』
- 『データを綺麗にしてから渡して貰して貰えないと分析できません』
という高飛車スタンスでは、
周りから面倒くさく思われてしまったり、スピード感も削がれてしまいます。
そのため、データ分析者には、ありもののデータから
データを分析しやすい形のデータを作り出す整形する能力があると、
更に活躍の幅が広がるかと思います。
今回はその中でも下記のケースで使える方法をご紹介します。
実は期間が連続しているのに、データ上レコードが分かれてしまっている!?
例えばこのようなデータがあったとします。
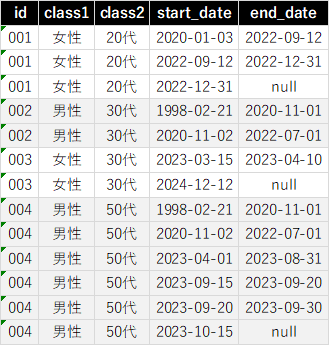
よく見て頂くと、レコードは分かれていますが実は連続しているレコードがありますね。
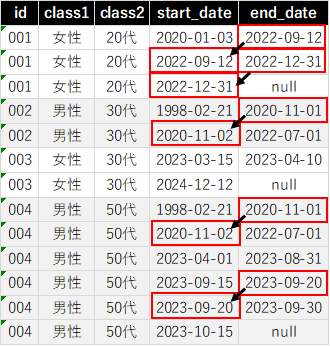
レコードが別れていることに意味がある場合もありますが、
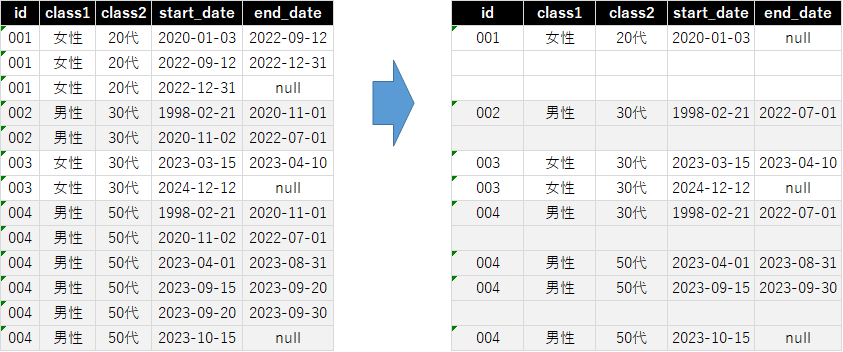
本来であればこんな感じにまとめた上で分析したいというときがあれば、
下記のクエリで右側のような状態にデータを加工できます。
SQLはこちら
↓↓↓↓↓↓↓↓↓↓
本当は連続しているのに、レコードが分かれてしまっているデータを整理するSQL
※2023-10-19 @takahasinaoki(なおき)さん のコメントを参考にリライト
WITH SUB AS (
SELECT id, class1, class2, start_date
, COALESCE(end_date, '9998-12-31') AS end_date
, LAG(end_date) OVER(PARTITION BY id ORDER BY start_date) AS prev_end_date
FROM my_table --任意のテーブル名
), SUB2 AS (
SELECT *
, SUM(CASE WHEN DATE_DIFF(start_date, prev_end_date, DAY) <= 1 /*INTERVALを指定*/ THEN 0 ELSE 1 END)
OVER (PARTITION BY id ORDER BY start_date) AS grp
FROM SUB
)
SELECT id, class1, class2
, MIN(start_date) AS start_date
, CASE WHEN MAX(end_date) = '9998-12-31' THEN null ELSE MAX(end_date) END AS end_date
FROM SUB2
GROUP BY id, class1, class2, grp
ORDER BY id,start_date
リライト前のSQL
SELECT
id,
class1,
class2,
start_date,
CASE WHEN end_date_edit = '9998-12-31' THEN null ELSE end_date_edit END AS end_date
FROM
/*004_連続レコードグループの一番最初のレコードに一番最後のレコードの終了日をもってくる------------------------------------------------------------------------------------------------------------------------STR*/
(
SELECT
*,
CASE WHEN flg_first_con =1 THEN LAST_VALUE(end_date) OVER (PARTITION BY id,con_num ORDER BY start_date RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) ELSE end_date END AS end_date_edit
FROM
/*003_連続レコードグループの枝番カラムの追加-----------------------------------------------------------------------------------------------------------------STR*/
(
SELECT
*,
CASE WHEN (flg_first_con =1 OR flg_lag_con = TRUE) THEN SUM(flg_first_con) OVER (PARTITION BY id ORDER BY start_date) ELSE null END AS con_num
FROM
/*002_連続レコードの最初判定カラムの追加-----------------------------------------------------------------------------------------------------STR*/
(
SELECT
*,
CASE WHEN (flg_lag_con IS NULL OR flg_lag_con = FALSE) AND flg_lead_con = TRUE THEN 1 ELSE null END AS flg_first_con
FROM
/*001_前後が連続しているか?の判定カラムの追加-------------------------------------------------------------------------------------STR*/
(
SELECT
*,
--許容するstart_dateとend_dateが何日離れているか?を連続していると見なすかの許容範囲を設定しています。
--許容範囲に応じてINTERVAの値を変更してください。(※初期設定では1日と設定しています。)
--※1日と設定した場合の許容範囲イメージ
-- 3/15と3/16 →許容する 3/15と3/17 →許容しない
DATE_ADD(LAG(end_date) OVER (PARTITION BY id ORDER BY start_date) , INTERVAL 1 DAY) >= start_date AS flg_lag_con,
DATE_ADD(end_date, INTERVAL 1 DAY) >= LEAD(start_date) OVER (PARTITION BY id ORDER BY start_date) AS flg_lead_con
FROM
/*000_重複レコード防止のおまじない------------------------------------STR*/
(
SELECT
id,
class1,
class2,
start_date,
IFNULL(end_date,'9998-12-31') AS end_date
FROM
--任意のテーブルを指定してください
任意のテーブル名
WHERE
start_date IS NOT null
GROUP BY
id,
class1,
class2,
start_date,
end_date
)
/*000_重複レコード防止のおまじない------------------------------------END*/
ORDER BY
id,
start_date
)
/*001_前後が連続しているか?の判定カラムの追加-------------------------------------------------------------------------------------END*/
ORDER BY
id,
start_date
)
/*002_連続レコードの最初判定カラムの追加-----------------------------------------------------------------------------------------------------END*/
ORDER BY
id,
start_date
)
/*003_連続レコードグループの枝番カラムの追加-----------------------------------------------------------------------------------------------------------------END*/
ORDER BY
id,
start_date
)
/*004_連続レコードグループの一番最初のレコードに一番最後のレコードの終了日をもってくる------------------------------------------------------------------------------------------------------------------------END*/
WHERE
con_num IS NULL
OR flg_first_con = 1
ORDER BY
id,
start_date
id,class1,class2,start_date,end_date
001,女性,20代,2020-01-03,2022-09-12
001,女性,20代,2022-09-12,2022-12-31
001,女性,20代,2022-12-31,
002,男性,30代,1998-02-21,2020-11-01
002,男性,30代,2020-11-02,2022-07-01
003,女性,30代,2023-03-15,2023-04-10
003,女性,30代,2024-12-12,
004,男性,50代,1998-02-21,2020-11-01
004,男性,50代,2020-11-02,2022-07-01
004,男性,50代,2023-04-01,2023-08-31
004,男性,50代,2023-09-15,2023-09-20
004,男性,50代,2023-09-20,2023-09-30
004,男性,50代,2023-10-15,
おわりに
同じようなデータでお悩みの方の助け・ご参考になれば幸いです。
筆者紹介
ニフティ株式会社でData Ninjaとして、分析などのデータ活用の仕事をしています。
当社についてご興味あれば、以下のリンクをご覧下さい。