BigQuery 最新情報
・smart analitycs:Googleのインフラのデータプラットフォームを提供。BIを提供。
・BigQuery:
- サーバレスで分析に集中できる。
- ある客は350PBを管理、100兆行のクエリ対象行数、1万クエリを同時実行
- 事例:HSBC大規模なクエリ実行、規制対応
- 信頼性:SLA可用性99.99%になった。他社は99.9%
- パフォーマンス向上:1PBに対して6分かかった(2016年)→2分(2018年)→4秒(2020年)
- 管理:スロットワークの割り当て、
- infomation schema
- スロット自動スケジューリング機能、スロットの自動スケジューリング、
- 管理パネルモニタリング:BQ内でモニタリングできるようになる、料金、スロットなど。リアルタイムと過去30日。実行されているクエリ、トップユーザの確認
- 顧客の課題:度のクエリがひっ迫してるのか?オンデマンドクエリモデルがいいのか?月や年で購入するのか?→BigQueryスロットレコメンダーでコスト最適化の推奨値を提案する。
- UI刷新:DataFlowも構築できる
- コネクティッドシート:スプレッドシートから分析可能。ピボットテーブル、グラフ、式でBQを使える。
- Data QnA:BQの自然言語インターフェース。API有効にするだけ。質問をなげかけると返答してくれる。Lockerなどでもつかえるようになる。Googleアシスタントと同じテクノロジー。
- BQの組み込みML:推論まで可能。データの準備にかかる時間が減る。SQLのチューニングに時間がかからなくなる。ロジスティック回帰など様々なモデルに対応。
- リアルタイム分析:
- BIengine:高速DBエンジン。Tableuなどからのクエリも高速化される。すべて自動管理する。
- BQ適応型キャッシング:すべてを自動で管理する
- BigQueryOmni:マルチクラウドに対応。ユーザインターフェースから操作。他社クラウド側Anthosにて実行される。
- 軽度な分析でBigQueryOmniを使い、詳細な分析はGCPをつかう。
- サーバレスなので、スモールスタートも可能。10GBから無料提供している。
・MachineLerning:分類、予測が可能。
・データレイクの相互運用性。BigQuery上のデータをBigQuwryで処理する。
・他Saasサービスにデータがある場合:様々なコネクタや転送サービスがある
=====
Looker's Roadmap: 2020 & Beyond
・すぐに使えるので、テスト→実装→監視→開発→テストのサイクルをやりやすい
・Lookerで大規模なデータガバナンス、ユーザー自身が様々な操作可能、柔軟な分析、データの運用が可能。
・あらゆるサイズのデータを高速処理。
・レポート機能があり、資料作成が容易。
・他のツールとAPI連携が可能。
・画面を自由にカスタマイズでき、どんな分析をしているかもわかりやすくできる。
・23言語に対応
・スタンドアロンとして構築が可能
・アラートの設定が可能
・ワークフローを簡単に一元化および自動化
・ツール間でシームレスにデータを移動し、常に同期する
・スプレッドシートやGsuiteのword、PowerPointと連携
・スマホアプリもある
・LookMLを使い、データベースにアクセスし、ロールアップテーブルを作成および実体化できる
Scaling Data-Driven Insights Across a Complex Global Organization with Looker and BigQuery
・Iron Mountain
ストレージおよび情報管理サービスのグローバルリーダー
数十億を保存および保護しています
安全な記録の保存、情報を含むソリューションの提供、管理、デジタル変換、安全な破壊、データセンター、クラウド、サービスとアートの保管と物流
・構成図あり
複数の場所からデータをGCSにインポート
レポートの作成を行った
====ー
Analytics in a Multi-Cloud World with BigQuery Omni
・世界のデータは2025年までに175ゼタバイトになると予測されている。
・データは管理されていないものがほとんどで、ばらばらに保管されている。
・BigQuery Omniをつかうことでサイロ化しているデータの分析が可能
・他社クラウドのデータも視覚化可能
・パイプラインを最適化できる
====
Data Catalog for Data Discovery and Metadata Management
・Data Catalog とは
データが分散している組織が、データ検出を効果的に実行したい場合、データカタログにより、すべてのデータ資産を発見、管理できる
https://cloud.google.com/blog/products/data-analytics/data-catalog-metadata-management-now-generally-available?utm_source=google_owned_website&utm_medium=et&utm_content=noa_smart_analytics_session_lp&utm_term=-&utm_campaign=-
・話の内容は上記のURLの内容
===
MLB’s Data Warehouse Modernization
・AWSからの移行
・従来のデータウェアハウスの課題
- データの増加に対応できない、拡張が遅い
- データが最新ではない
- データへのアクセス制限
- 機械学習とAIをサポートしていない
- 予算浪費、ライセンスの更新が必要
・TeradataからBigQueryへ移行したMLBの事例
・移行前の課題 - 増分コピーへのデータの変更
- すべての履歴データを再コピーするスキーマが必要
- クラブとMLB間でデータを共有しない。
- リアルタイムのデータにアクセスの手段はない
・移行後の改善点
- MLB内および30のMLBクラブでのデータセットの双方向の共有は、今では簡単です。
- 実行時間が50%短縮されました。
- Okta / GSuite統合により認証が効率的
- ダウンタイムなし
- 初期コストも安くすんだ(予約されたスロット)
- 自動バックアップ、自動スケーリング
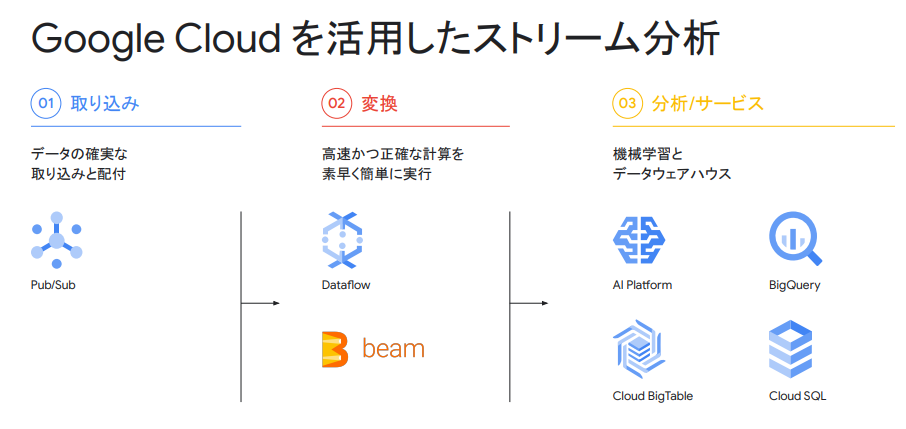
ストリーム分析
イベント ストリームをリアルタイムに取り込み、処理し、分析します。Google Cloud のストリーム分析ソリューションによって、データが生成された瞬間から整理され、便利で使いやすいものになります。