今回は、pytorchで事前学習されたモデルを利用してClassificationしてみます。
簡単な話ですが、ちゃんと出来るのかというレベルを目指すと奥は深いと思います。
モデルは以下の参考で公開されています。
使い方のtutorialが見つかりませんが、だいたい参考に情報は掲載されています。
ということで、今回は一番簡単な使い方、Classificationに焦点をあてて、これらの種々のモデルの性能比較をやろうと思います。
【参考】
①TORCHVISION.MODELS
やったこと
・一番簡単な転移学習とFine-Tuningをやってみる
・いろいろなモデルを使ってみる
・入力サイズ依存を測定
・一番簡単な転移学習とFine-Tuningをやってみる
基本のコードは、以前まとめた以下の参考のおまけに掲載したコードのモデルを変更して、利用します。このnetwork関数を転移学習に利用する学習済のnetwork関数とします。
【参考】
②【pytorch-lightning入門】初めてのLit♬
転移学習のコード
以下のコードは、元々のImagenetで学習したモデルで1000カテゴリまで分類しているので、それをCifar10向けにさらに10カテゴリに分類するために全結合層を新たに追加しています。最初から元のモデルの最終層を10カテゴリ出力に変更するでも同様な効果です。また、この全結合層をもう少しリッチにするなどの工夫もできますが、今回は一番単純な方式としています。
class customize_model(nn.Module):
def __init__(self):
super(customize_model, self).__init__()
self.model_ = models.resnet18(pretrained=True)
for param in self.model_.parameters():
param.requires_grad = True #False
self.f_resnet = nn.Sequential(
nn.Linear(in_features=np.int(1000), out_features=10, bias=True)
)
def forward(self, input):
midlevel_features = self.model_(input)
output = self.f_resnet(midlevel_features)
return output
上記では、全てのWeightsやBiasなどを学習するか・しないかのどちらかしか設定できません。
実際には、自分の趣味(学習の状況)に合わせて、層を選んで学習したい。
pytorchでも当然出来るはずで、以下の参考②にありました。
【参考】
②【PyTorch】torchvisionから学習済みモデルを使用する際のTips
ということで、いろいろ試した結果以下のようにできました。
for i, param in enumerate(self.model_.parameters()):
param.requires_grad = True
if i >= 20:
param.requires_grad = False #True #False
print(i, param.requires_grad)
j =0
for name, param in self.model_.named_parameters():
param.requires_grad = True
if j >= 10:
param.requires_grad = False
print(j, name, param.requires_grad)
j +=1
・いろいろなモデルを使ってみる
上記の単独のモデルを拡張して、以下のようなnetwork関数を定義しました。
以下のclassを読みだすことにより、modelをそれぞれ生成している。
class customize_model(nn.Module):
def __init__(self, input_size=128, sel_model='resnet18'):
super(customize_model, self).__init__()
## Select model
if sel_model == 'resnext50':
self.model_ = models.resnext50_32x4d(pretrained=True)
elif sel_model == 'vgg16':
self.model_ = models.vgg16_bn(pretrained=True) #, num_classes=10) #365)
elif sel_model == 'wide50':
self.model_ = models.wide_resnet50_2(pretrained=True) #, num_classes=10) #365)
elif sel_model == 'mobilev2':
self.model_ = models.mobilenet_v2(pretrained=True)
elif sel_model == 'densenet121':
self.model_ = models.densenet121(pretrained=True)
else:
self.model_ = models.resnet18(pretrained=True)
j =0
for name, param in self.model_.named_parameters():
param.requires_grad = True
if j >= 10:
param.requires_grad = False
print(j, name, param.requires_grad)
j +=1
self.f_resnet = nn.Sequential(
nn.Linear(in_features=np.int(1000), out_features=10, bias=True)
)
def forward(self, input):
midlevel_features = self.model_(input)
output = self.f_resnet(midlevel_features)
return output
これらの性能は上記のリンクからImagenetに対して以下の通りだそうです。
今回は、これにCifar10の測定結果を追記しています。
測定条件は、128□に拡大し、規格化実施したが、それ以外は読込通りで何ら手を加えていないが、ばらつきがあるもののtop-1 errorが10%以下で比較的よい。
これは、imagenetでの学習パラメータを初期値としてFine-Tuningを実施しているためかもしれないが、いわゆる学習を10カテゴリへのfc層に限った場合は、右の数字になっているので、Fine-Tuning(再学習)が成功していると言える。
| モデル名 | top-1 error | top-10 error | training_time/epoch;Fine-Tuning | Cifar10 top-1 error/10epoch | training_time/epoch;transfer | Cifar10 top-1 error | weights size |
|---|---|---|---|---|---|---|---|
| VGG-16 with batch normalization | 26.63 | 8.50 | 179.1a/124.1b | 9.37a/9.57b | 185.5 | 18.4 | 35.6MBa(138MB)/21.0MBb |
| ResNet-18 | 30.24 | 10.92 | 120.0 | 9.54 | 61.5 | 20.3 | 11.7MB |
| Densenet-121 | 25.35 | 7.83 | 253.1 | 6.35 | 112.8 | 17.8 | 8.0MB |
| MobileNet V2 | 28.12 | 9.71 | 124.7 | 8.04 | 65.3 | 21.1 | 3.5MB |
| ResNeXt-50-32x4d | 22.38 | 6.30 | 425.2 | 7.57 | 149.5 | 19.23 | 25.0MB |
| Wide ResNet-50-2 | 21.49 | 5.91 | 810.1(batch8)/258.5e/419f | 30.9(batch8)/12.4e/11.1f | 173.1c/124.0d | 21.55/17.48d | 68.9MB/29.3MBd/67.3MBe |
| a;AdaptiveAvgPool2d-45のパラメータ固定 | |||||||
| b;AdaptivAvgPool2d-45を削除してFlatten()に置き換え | |||||||
| c;計算中停止時間を引く1931sec-200sec/10epoch | |||||||
| d;j <= 140 False (64,64) | |||||||
| e; j <= 44: False (1.6MB) (64,64) batch32 | |||||||
| f; j <= 44: False (1.6MB) (128,128) batch32 |
測定条件
Cifar10/128x128画像をbatch=32読み込み時に以下の変換を実施しているが、それ以外のAugumentationは実施していない。
self.transform = transforms.Compose([
transforms.ToTensor(),
transforms.Resize((self.width, self.height)),
transforms.Normalize((0.5, 0.5, 0.5), (0.25, 0.25, 0.25))
])
VGG16モデルのAdaptiveAvgPool2d-45のパラメータ固定と削除
上記の計算において、VGG16_bnでは、全結合層への入り口でAdaptiveAvgPool2dを利用して、出力を51277=4096統一しているようだ。
この方法は、他のモデルでも利用されているが、AdaptiveAvgPool2d(output_size=(1, 1)) と出力サイズが(1,1)となっており、Weightsもそれなりのサイズに収まっている。
ところが、VGG16では、AdaptiveAvgPool2d(output_size=(7, 7))とサイズが大きく、特にWeightsのサイズはほぼ102MBと大きいので目立っている。
固定で利用する場合は、どうにか学習できるが、学習しようとするとメモリー不足で計算できない。
そこで、今回は上の計算で利用した、固定と削除の方法を記載しておく。
固定について
VGG16_bnでは、以下のように52番目のweightsをFalseにすれば固定される。
j =0
for name, param in self.model_.named_parameters():
param.requires_grad = True
if j == 52:
param.requires_grad = False
print(j, name, param.requires_grad)
j +=1
一方、削除は以下のようにモデルの定義で以下のように削除する。
elif sel_model == 'vgg16':
model_0 = models.vgg16_bn(pretrained=True)
self.model_ = nn.Sequential(*list(model_0.children())[0])
これは、model0.children()を以下のように出力すると分かるが、AdaptiveAvgPool2d(output_size=(7, 7))は、以下のように別のレイヤーとして定義されており、最初の(features): Sequential()の次の(avgpool):となっている。
そこで、上では*list(model_0.children())[0]と最初の塊を取得している。
vgg16 Net(
(net): customize_model(
(model_): VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
...
(42): ReLU(inplace=True)
(43): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
(f_resnet): Sequential(
(0): Linear(in_features=1000, out_features=10, bias=True)
)
)
そして、上記の(classifier)の代わりに以下を追加した。
if sel_model =='vgg16':
self.f_resnet = nn.Sequential(
nn.Flatten(),
nn.Linear(in_features=np.int(512*2*2), out_features=2048, bias=True),
nn.ReLU(),
nn.Dropout(p=0.2, inplace=False),
nn.Linear(in_features=np.int(512*2*2), out_features=1000, bias=True),
nn.Linear(in_features=np.int(1000), out_features=10, bias=True)
)
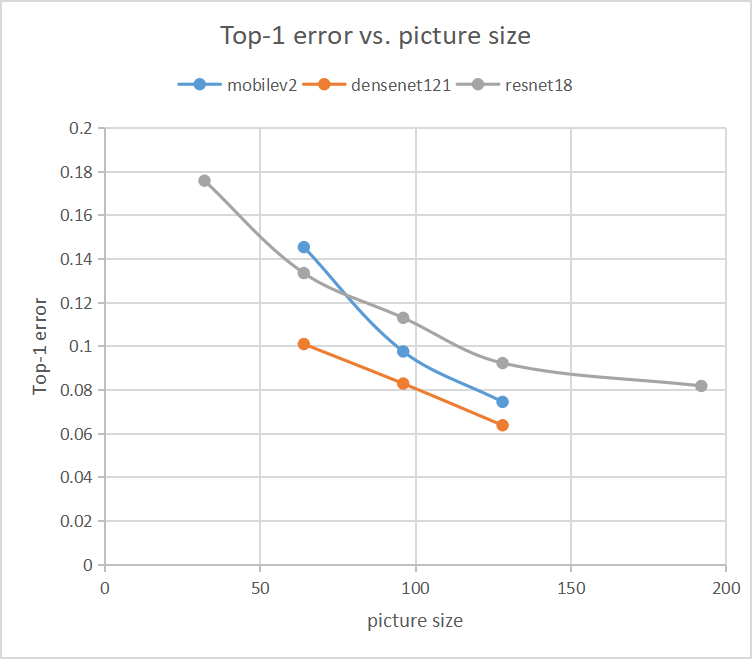
入力サイズ依存性
resnet18、densenet121とmobilev2の入力画像サイズ依存性
測定条件は、上記と同一で、上の表でWeightsサイズが小さく比較的扱いやすい三つのモデルを選んでサイズ依存性をやってみました。
Cifar10の入力サイズを32,64, 96, 128, 192そして224に変更して10epoch Fine-Tuningした結果は以下の表の通りになりました。
| resnet18 | val_acc | Train_time | model_size | memory_size |
|---|---|---|---|---|
| 32 | 0.8242 | 633 | 11.7MB | 137MB |
| 64 | 0.8665 | 732 | ||
| 96 | 0.887 | 927 | ||
| 128 | 0.9077 | 1186 | ||
| 192 | 0.9182 | 1957 | ||
| 224 | 0.9136 | 2697 |
| densenet121 | val_acc | Train_time | model_size | memory_size |
|---|---|---|---|---|
| 32 | 0.7705 | 1249 | 8.0MB | 94MB |
| 64 | 0.8990 | 1404 | ||
| 96 | 0.9171 | 1726 | ||
| 128 | 0.9362 | 2522 | ||
| 192 | - | - |
| mobilev2 | val_acc | Train_time | model_size | memory_size |
|---|---|---|---|---|
| 32 | 0.5443 | 543 | 3.5MB | 41MB |
| 64 | 0.8546 | 682 | ||
| 96 | 0.9024 | 839 | ||
| 128 | 0.9255 | 1252 | ||
| 192 | 0.9222 | 2454 |
以下の依存性があるようだ。
まとめ
・pytorch掲載のmodelsで遊んでみた
・Imagenetで学習済パラメータの転移学習をcifar10に適用したが、val_accはあまり向上しない
・Fine-tuningではtop-1 errorで10%以下の値を得た
・top-1 errorは、入力画像サイズ依存性があり、ほぼ単調に減少する傾向が見られた
・層毎の利用が出来るようになった
・mobile v2とdensenet121辺りの性能及び学習時間が良好であった
・マシンのメモリー不足で大きなレンジで測定できなかった
おまけ
一番短いVGG16です。
0 True
1 True
2 True
3 True
4 True
5 True
6 True
7 True
8 True
9 True
10 True
11 True
12 True
13 True
14 True
15 True
16 True
17 True
18 True
19 True
20 False
21 False
22 False
23 False
24 False
25 False
26 False
27 False
28 False
29 False
30 False
31 False
32 False
33 False
34 False
35 False
36 False
37 False
38 False
39 False
40 False
41 False
42 False
43 False
44 False
45 False
46 False
47 False
48 False
49 False
50 False
51 False
52 False
53 False
54 False
55 False
56 False
57 False
0 features.0.weight True
1 features.0.bias True
2 features.1.weight True
3 features.1.bias True
4 features.3.weight True
5 features.3.bias True
6 features.4.weight True
7 features.4.bias True
8 features.7.weight True
9 features.7.bias True
10 features.8.weight False
11 features.8.bias False
12 features.10.weight False
13 features.10.bias False
14 features.11.weight False
15 features.11.bias False
16 features.14.weight False
17 features.14.bias False
18 features.15.weight False
19 features.15.bias False
20 features.17.weight False
21 features.17.bias False
22 features.18.weight False
23 features.18.bias False
24 features.20.weight False
25 features.20.bias False
26 features.21.weight False
27 features.21.bias False
28 features.24.weight False
29 features.24.bias False
30 features.25.weight False
31 features.25.bias False
32 features.27.weight False
33 features.27.bias False
34 features.28.weight False
35 features.28.bias False
36 features.30.weight False
37 features.30.bias False
38 features.31.weight False
39 features.31.bias False
40 features.34.weight False
41 features.34.bias False
42 features.35.weight False
43 features.35.bias False
44 features.37.weight False
45 features.37.bias False
46 features.38.weight False
47 features.38.bias False
48 features.40.weight False
49 features.40.bias False
50 features.41.weight False
51 features.41.bias False
52 classifier.0.weight False
53 classifier.0.bias False
54 classifier.3.weight False
55 classifier.3.bias False
56 classifier.6.weight False
57 classifier.6.bias False
model_customize vgg16= customize_model(
(model_): VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(7): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(9): ReLU(inplace=True)
(10): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(12): ReLU(inplace=True)
(13): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(14): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(16): ReLU(inplace=True)
(17): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(19): ReLU(inplace=True)
(20): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(21): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(26): ReLU(inplace=True)
(27): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(28): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(29): ReLU(inplace=True)
(30): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(31): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(32): ReLU(inplace=True)
(33): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(34): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(35): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(36): ReLU(inplace=True)
(37): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(38): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(39): ReLU(inplace=True)
(40): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(41): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(42): ReLU(inplace=True)
(43): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
(f_resnet): Sequential(
(0): Linear(in_features=1000, out_features=10, bias=True)
)
)
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 128, 128] 1,792
BatchNorm2d-2 [-1, 64, 128, 128] 128
ReLU-3 [-1, 64, 128, 128] 0
Conv2d-4 [-1, 64, 128, 128] 36,928
BatchNorm2d-5 [-1, 64, 128, 128] 128
ReLU-6 [-1, 64, 128, 128] 0
MaxPool2d-7 [-1, 64, 64, 64] 0
Conv2d-8 [-1, 128, 64, 64] 73,856
BatchNorm2d-9 [-1, 128, 64, 64] 256
ReLU-10 [-1, 128, 64, 64] 0
Conv2d-11 [-1, 128, 64, 64] 147,584
BatchNorm2d-12 [-1, 128, 64, 64] 256
ReLU-13 [-1, 128, 64, 64] 0
MaxPool2d-14 [-1, 128, 32, 32] 0
Conv2d-15 [-1, 256, 32, 32] 295,168
BatchNorm2d-16 [-1, 256, 32, 32] 512
ReLU-17 [-1, 256, 32, 32] 0
Conv2d-18 [-1, 256, 32, 32] 590,080
BatchNorm2d-19 [-1, 256, 32, 32] 512
ReLU-20 [-1, 256, 32, 32] 0
Conv2d-21 [-1, 256, 32, 32] 590,080
BatchNorm2d-22 [-1, 256, 32, 32] 512
ReLU-23 [-1, 256, 32, 32] 0
MaxPool2d-24 [-1, 256, 16, 16] 0
Conv2d-25 [-1, 512, 16, 16] 1,180,160
BatchNorm2d-26 [-1, 512, 16, 16] 1,024
ReLU-27 [-1, 512, 16, 16] 0
Conv2d-28 [-1, 512, 16, 16] 2,359,808
BatchNorm2d-29 [-1, 512, 16, 16] 1,024
ReLU-30 [-1, 512, 16, 16] 0
Conv2d-31 [-1, 512, 16, 16] 2,359,808
BatchNorm2d-32 [-1, 512, 16, 16] 1,024
ReLU-33 [-1, 512, 16, 16] 0
MaxPool2d-34 [-1, 512, 8, 8] 0
Conv2d-35 [-1, 512, 8, 8] 2,359,808
BatchNorm2d-36 [-1, 512, 8, 8] 1,024
ReLU-37 [-1, 512, 8, 8] 0
Conv2d-38 [-1, 512, 8, 8] 2,359,808
BatchNorm2d-39 [-1, 512, 8, 8] 1,024
ReLU-40 [-1, 512, 8, 8] 0
Conv2d-41 [-1, 512, 8, 8] 2,359,808
BatchNorm2d-42 [-1, 512, 8, 8] 1,024
ReLU-43 [-1, 512, 8, 8] 0
MaxPool2d-44 [-1, 512, 4, 4] 0
AdaptiveAvgPool2d-45 [-1, 512, 7, 7] 0
Linear-46 [-1, 4096] 102,764,544
ReLU-47 [-1, 4096] 0
Dropout-48 [-1, 4096] 0
Linear-49 [-1, 4096] 16,781,312
ReLU-50 [-1, 4096] 0
Dropout-51 [-1, 4096] 0
Linear-52 [-1, 1000] 4,097,000
VGG-53 [-1, 1000] 0
Linear-54 [-1, 10] 10,010
================================================================
Total params: 138,376,002
Trainable params: 122,842
Non-trainable params: 138,253,160
----------------------------------------------------------------
Input size (MB): 0.19
Forward/backward pass size (MB): 105.46
Params size (MB): 527.86
Estimated Total Size (MB): 633.51
----------------------------------------------------------------
以下が二番目に短いResnet18です。
0 True
1 True
2 True
3 True
4 True
5 True
6 True
7 True
8 True
9 True
10 True
11 True
12 True
13 True
14 True
15 True
16 True
17 True
18 True
19 True
20 False
21 False
22 False
23 False
24 False
25 False
26 False
27 False
28 False
29 False
30 False
31 False
32 False
33 False
34 False
35 False
36 False
37 False
38 False
39 False
40 False
41 False
42 False
43 False
44 False
45 False
46 False
47 False
48 False
49 False
50 False
51 False
52 False
53 False
54 False
55 False
56 False
57 False
58 False
59 False
60 False
61 False
0 conv1.weight True
1 bn1.weight True
2 bn1.bias True
3 layer1.0.conv1.weight True
4 layer1.0.bn1.weight True
5 layer1.0.bn1.bias True
6 layer1.0.conv2.weight True
7 layer1.0.bn2.weight True
8 layer1.0.bn2.bias True
9 layer1.1.conv1.weight True
10 layer1.1.bn1.weight False
11 layer1.1.bn1.bias False
12 layer1.1.conv2.weight False
13 layer1.1.bn2.weight False
14 layer1.1.bn2.bias False
15 layer2.0.conv1.weight False
16 layer2.0.bn1.weight False
17 layer2.0.bn1.bias False
18 layer2.0.conv2.weight False
19 layer2.0.bn2.weight False
20 layer2.0.bn2.bias False
21 layer2.0.downsample.0.weight False
22 layer2.0.downsample.1.weight False
23 layer2.0.downsample.1.bias False
24 layer2.1.conv1.weight False
25 layer2.1.bn1.weight False
26 layer2.1.bn1.bias False
27 layer2.1.conv2.weight False
28 layer2.1.bn2.weight False
29 layer2.1.bn2.bias False
30 layer3.0.conv1.weight False
31 layer3.0.bn1.weight False
32 layer3.0.bn1.bias False
33 layer3.0.conv2.weight False
34 layer3.0.bn2.weight False
35 layer3.0.bn2.bias False
36 layer3.0.downsample.0.weight False
37 layer3.0.downsample.1.weight False
38 layer3.0.downsample.1.bias False
39 layer3.1.conv1.weight False
40 layer3.1.bn1.weight False
41 layer3.1.bn1.bias False
42 layer3.1.conv2.weight False
43 layer3.1.bn2.weight False
44 layer3.1.bn2.bias False
45 layer4.0.conv1.weight False
46 layer4.0.bn1.weight False
47 layer4.0.bn1.bias False
48 layer4.0.conv2.weight False
49 layer4.0.bn2.weight False
50 layer4.0.bn2.bias False
51 layer4.0.downsample.0.weight False
52 layer4.0.downsample.1.weight False
53 layer4.0.downsample.1.bias False
54 layer4.1.conv1.weight False
55 layer4.1.bn1.weight False
56 layer4.1.bn1.bias False
57 layer4.1.conv2.weight False
58 layer4.1.bn2.weight False
59 layer4.1.bn2.bias False
60 fc.weight False
61 fc.bias False
model_customize resnet18= customize_model(
(model_): ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=1000, bias=True)
)
(f_resnet): Sequential(
(0): Linear(in_features=1000, out_features=10, bias=True)
)
)
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 64, 64] 9,408
BatchNorm2d-2 [-1, 64, 64, 64] 128
ReLU-3 [-1, 64, 64, 64] 0
MaxPool2d-4 [-1, 64, 32, 32] 0
Conv2d-5 [-1, 64, 32, 32] 36,864
BatchNorm2d-6 [-1, 64, 32, 32] 128
ReLU-7 [-1, 64, 32, 32] 0
Conv2d-8 [-1, 64, 32, 32] 36,864
BatchNorm2d-9 [-1, 64, 32, 32] 128
ReLU-10 [-1, 64, 32, 32] 0
BasicBlock-11 [-1, 64, 32, 32] 0
Conv2d-12 [-1, 64, 32, 32] 36,864
BatchNorm2d-13 [-1, 64, 32, 32] 128
ReLU-14 [-1, 64, 32, 32] 0
Conv2d-15 [-1, 64, 32, 32] 36,864
BatchNorm2d-16 [-1, 64, 32, 32] 128
ReLU-17 [-1, 64, 32, 32] 0
BasicBlock-18 [-1, 64, 32, 32] 0
Conv2d-19 [-1, 128, 16, 16] 73,728
BatchNorm2d-20 [-1, 128, 16, 16] 256
ReLU-21 [-1, 128, 16, 16] 0
Conv2d-22 [-1, 128, 16, 16] 147,456
BatchNorm2d-23 [-1, 128, 16, 16] 256
Conv2d-24 [-1, 128, 16, 16] 8,192
BatchNorm2d-25 [-1, 128, 16, 16] 256
ReLU-26 [-1, 128, 16, 16] 0
BasicBlock-27 [-1, 128, 16, 16] 0
Conv2d-28 [-1, 128, 16, 16] 147,456
BatchNorm2d-29 [-1, 128, 16, 16] 256
ReLU-30 [-1, 128, 16, 16] 0
Conv2d-31 [-1, 128, 16, 16] 147,456
BatchNorm2d-32 [-1, 128, 16, 16] 256
ReLU-33 [-1, 128, 16, 16] 0
BasicBlock-34 [-1, 128, 16, 16] 0
Conv2d-35 [-1, 256, 8, 8] 294,912
BatchNorm2d-36 [-1, 256, 8, 8] 512
ReLU-37 [-1, 256, 8, 8] 0
Conv2d-38 [-1, 256, 8, 8] 589,824
BatchNorm2d-39 [-1, 256, 8, 8] 512
Conv2d-40 [-1, 256, 8, 8] 32,768
BatchNorm2d-41 [-1, 256, 8, 8] 512
ReLU-42 [-1, 256, 8, 8] 0
BasicBlock-43 [-1, 256, 8, 8] 0
Conv2d-44 [-1, 256, 8, 8] 589,824
BatchNorm2d-45 [-1, 256, 8, 8] 512
ReLU-46 [-1, 256, 8, 8] 0
Conv2d-47 [-1, 256, 8, 8] 589,824
BatchNorm2d-48 [-1, 256, 8, 8] 512
ReLU-49 [-1, 256, 8, 8] 0
BasicBlock-50 [-1, 256, 8, 8] 0
Conv2d-51 [-1, 512, 4, 4] 1,179,648
BatchNorm2d-52 [-1, 512, 4, 4] 1,024
ReLU-53 [-1, 512, 4, 4] 0
Conv2d-54 [-1, 512, 4, 4] 2,359,296
BatchNorm2d-55 [-1, 512, 4, 4] 1,024
Conv2d-56 [-1, 512, 4, 4] 131,072
BatchNorm2d-57 [-1, 512, 4, 4] 1,024
ReLU-58 [-1, 512, 4, 4] 0
BasicBlock-59 [-1, 512, 4, 4] 0
Conv2d-60 [-1, 512, 4, 4] 2,359,296
BatchNorm2d-61 [-1, 512, 4, 4] 1,024
ReLU-62 [-1, 512, 4, 4] 0
Conv2d-63 [-1, 512, 4, 4] 2,359,296
BatchNorm2d-64 [-1, 512, 4, 4] 1,024
ReLU-65 [-1, 512, 4, 4] 0
BasicBlock-66 [-1, 512, 4, 4] 0
AdaptiveAvgPool2d-67 [-1, 512, 1, 1] 0
Linear-68 [-1, 1000] 513,000
ResNet-69 [-1, 1000] 0
Linear-70 [-1, 10] 10,010
================================================================
Total params: 11,699,522
Trainable params: 130,394
Non-trainable params: 11,569,128
----------------------------------------------------------------
Input size (MB): 0.19
Forward/backward pass size (MB): 20.52
Params size (MB): 44.63
Estimated Total Size (MB): 65.34
----------------------------------------------------------------