こういうのはやはり自分で学習してみないとということで、独自学習やってみました
まず、やり方は以下のサイトのとおり、
物体検出アルゴリズム(SSD : Single Shot MultiBox Detector)を学習させてみる
のとおり、データをダウンロードして展開して使いました。
※ここで2007はそれなりの大きさのデータですが、2012はかなり大きめ(2GB以上)
2007のデータでさえ、ブラウザ変更してやっとダウンロードできました
どうにかダウンロードして、学習開始。。。
しかし、案外時間かかります。
ということで、モデルを見てみましょう
物体検出のモデル
まず、前半はこんな感じです。
def SSD300v2(input_shape, num_classes=21):
"""SSD300 architecture.
# Arguments
input_shape: Shape of the input image,
expected to be either (300, 300, 3) or (3, 300, 300)(not tested).
num_classes: Number of classes including background.
# References
https://arxiv.org/abs/1512.02325
"""
input_layer = Input(shape=input_shape)
# Block 1
conv1_1 = Conv2D(64, (3, 3),name='conv1_1', padding='same', activation='relu')(input_layer)
conv1_2 = Conv2D(64, (3, 3), name='conv1_2', padding='same', activation='relu')(conv1_1)
pool1 = MaxPooling2D(name='pool1', pool_size=(2, 2), strides=(2, 2), padding='same', )(conv1_2)
# Block 2
conv2_1 = Conv2D(128, (3, 3), name='conv2_1', padding='same', activation='relu')(pool1)
conv2_2 = Conv2D(128, (3, 3), name='conv2_2', padding='same', activation='relu')(conv2_1)
pool2 = MaxPooling2D(name='pool2', pool_size=(2, 2), strides=(2, 2), padding='same')(conv2_2)
# Block 3
conv3_1 = Conv2D(256, (3, 3), name='conv3_1', padding='same', activation='relu')(pool2)
conv3_2 = Conv2D(256, (3, 3), name='conv3_2', padding='same', activation='relu')(conv3_1)
conv3_3 = Conv2D(256, (3, 3), name='conv3_3', padding='same', activation='relu')(conv3_2)
pool3 = MaxPooling2D(name='pool3', pool_size=(2, 2), strides=(2, 2), padding='same')(conv3_3)
# Block 4
conv4_1 = Conv2D(512, (3, 3), name='conv4_1', padding='same', activation='relu')(pool3)
conv4_2 = Conv2D(512, (3, 3), name='conv4_2', padding='same', activation='relu')(conv4_1)
conv4_3 = Conv2D(512, (3, 3), name='conv4_3', padding='same', activation='relu')(conv4_2)
pool4 = MaxPooling2D(name='pool4', pool_size=(2, 2), strides=(2, 2), padding='same')(conv4_3)
# Block 5
conv5_1 = Conv2D(512, (3, 3), name='conv5_1', padding='same', activation='relu')(pool4)
conv5_2 = Conv2D(512, (3, 3), name='conv5_2', padding='same', activation='relu')(conv5_1)
conv5_3 = Conv2D(512, (3, 3), name='conv5_3', padding='same', activation='relu')(conv5_2)
pool5 = MaxPooling2D(name='pool5', pool_size=(3, 3), strides=(1, 1), padding='same')(conv5_3)
これ見ると、やはり過学習になりやすそう。。。ということで一回目転移学習(以下のとおりblock3まで固定)でも過学習になりました。
そこで、学習APの主要部分を見てみましょう。
path_prefix = './VOCdevkit/VOC2007/JPEGImages/'
gen = Generator(gt, bbox_util, 4, path_prefix,
train_keys, val_keys,
(input_shape[0], input_shape[1]), do_crop=False)
model = SSD300v2(input_shape, num_classes=NUM_CLASSES)
# model.load_weights('weights_SSD300.hdf5', by_name=True)
model.load_weights('./checkpoints/weights.01-4.35.hdf5', by_name=True)
freeze = ['input_1', 'conv1_1', 'conv1_2', 'pool1',
'conv2_1', 'conv2_2', 'pool2',
'conv3_1', 'conv3_2', 'conv3_3', 'pool3']#,
# 'conv4_1', 'conv4_2', 'conv4_3', 'pool4']
for L in model.layers:
if L.name in freeze:
L.trainable = False
def schedule(epoch, decay=0.9):
return base_lr * decay**(epoch)
csv_logger = keras.callbacks.CSVLogger('./checkpoints/training.log', separator=',', append=True)
weights_save=keras.callbacks.ModelCheckpoint('./checkpoints/weights.{epoch:02d}-{val_loss:.2f}.hdf5',
verbose=1,
save_weights_only=True)
learnRateSchedule=keras.callbacks.LearningRateScheduler(schedule)
callbacks = [weights_save, csv_logger, learnRateSchedule]
base_lr = 0.0001 #3e-4
optim = keras.optimizers.Adam(lr=base_lr, beta_1=0.9, beta_2=0.999, epsilon=1e-08, decay=0.)
# optim = keras.optimizers.Adam(lr=base_lr)
model.compile(optimizer=optim,
loss=MultiboxLoss(NUM_CLASSES, neg_pos_ratio=2.0).compute_loss)
主要な部分は以上のとおり、案外簡単ですね。
もちろんこれ以外にRegion指定などの部分がありますが、それは後で考えることにします。
※それはSSDの根幹で仕組みに依存するので後回し
このコード見る限りは、ほぼ今まで見てきたフィッティングのコードと同じ。。。
model = SSD300v2(input_shape, num_classes=NUM_CLASSES)
model.load_weights('./checkpoints/weights.01-4.35.hdf5', by_name=True)
ここは文字通り、modelです。
そして、
freeze = ['input_1', 'conv1_1', 'conv1_2', 'pool1',
'conv2_1', 'conv2_2', 'pool2',
'conv3_1', 'conv3_2', 'conv3_3', 'pool3']#,
# 'conv4_1', 'conv4_2', 'conv4_3', 'pool4']
for L in model.layers:
if L.name in freeze:
L.trainable = False
ここは転移学習しますよというところ。つまり、freeze部分はL.trainable=Falseということ(block3まで固定)でパラメータ固定で学習します。ということです。
ということで、この転移学習したところ、
Epoch 5/10
4009/4009 [==============================] - 992s 247ms/step - loss: 2.1328 - val_loss: 2.7515
Epoch 00005: saving model to ./checkpoints/weights.05-2.75.hdf5
Epoch 6/10
4009/4009 [==============================] - 990s 247ms/step - loss: 1.9498 - val_loss: 2.7812
Epoch 00006: saving model to ./checkpoints/weights.06-2.78.hdf5
Epoch 7/10
4009/4009 [==============================] - 989s 247ms/step - loss: 1.7763 - val_loss: 2.8130
Epoch 00007: saving model to ./checkpoints/weights.07-2.81.hdf5
Epoch 8/10
4009/4009 [==============================] - 989s 247ms/step - loss: 1.6258 - val_loss: 2.8545
ということで、過学習の兆候が出てしまいました。
これで、物体検出すると以下のとおりの結果です。
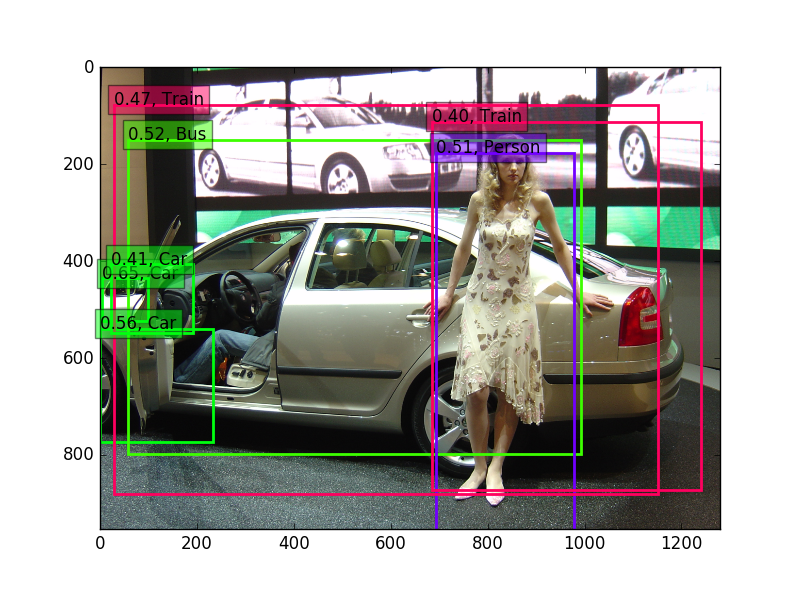
結果はボロボロです。
ということで、ゼロから再学習することとしました。
つまり、コードを以下のとおり変更します。
freeze = ['input_1', 'conv1_1', 'conv1_2', 'pool1',
'conv2_1', 'conv2_2', 'pool2',
'conv3_1', 'conv3_2', 'conv3_3', 'pool3']#,
# 'conv4_1', 'conv4_2', 'conv4_3', 'pool4']
"""
for L in model.layers:
if L.name in freeze:
L.trainable = False
"""
そして、もちろん
# odel.load_weights('./checkpoints/weights.01-4.35.hdf5', by_name=True)
と転移学習を止めます。
ゼロから学習。。。
その結果は、以下のとおり。。。。
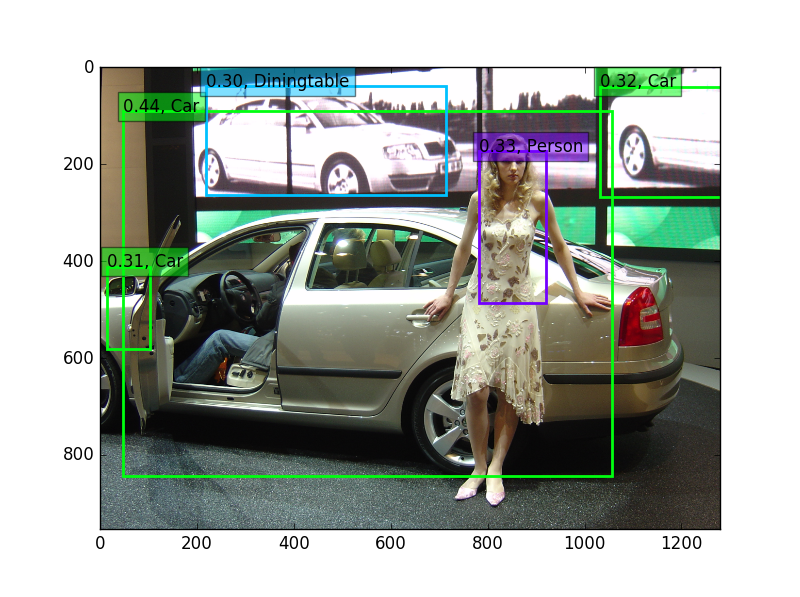
あれ、笑っちゃうくらい悪いんじゃないの??
もちろん、全編過学習なので、モデルを変更しないと。。。
今宵はここまでに致しとうござりまする。。。
明日は、きっと。。。