これって、イロハだけど、。。。ほんと難しい
特徴がない物体ほど物体検出はし難い。。。
最近、先行の記事があるのでそこからデータもいただいて、やってみました。
【参考】
【物体検出】AI開発者になりたいけど餅つきをしたくない
しかし、こんな難しい話を簡単そうにやっている。。。特にデータ読み込み
今回は学習済のSSD300モデルを利用してFineTuningして、〇△×を物体検出しました。
ここではFineTuningする層を変化させながら、結果の変化を見て、最適なFineTuningする層を見出すことを試みました。
学習データについて
これは、半分は自前で作ってみました。
最初は、Chainer導入して上記サイトから丸ごともらおうと思いましたが、。。。できませんでした^^;
次に、専用のものを作ろうとかサイト利用してと考えましたが、結局Windowsなので「ペイントブラシ」でできました。
①〇△xをかけること
②情報をXMLデータにするために、WidthとHeight、そして矩形で囲んだときの(xmin,ymin)(xmax,ymax)が必要です。あとは名称
一応、データ数は多く、そしてバリエーションが必要(だと思っていました)
今回は、学習データ全部で62個です。
そして、Trainデータとしては49個、残り13個がTestデータです。
そのほかに、Validationというか、こんなの検出できるのというような複数で若干難しめの検出課題を課しました。
モデルの構成
モデルは以下のとおりなので、どこまでを固定してどこを再学習するかということです。
SSD300の場合は以下のとおりです。
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) (None, 300, 300, 3) 0
__________________________________________________________________________________________________
conv1_1 (Conv2D) (None, 300, 300, 64) 1792 input_1[0][0]
__________________________________________________________________________________________________
conv1_2 (Conv2D) (None, 300, 300, 64) 36928 conv1_1[0][0]
__________________________________________________________________________________________________
pool1 (MaxPooling2D) (None, 150, 150, 64) 0 conv1_2[0][0]
__________________________________________________________________________________________________
。。。conv1と全く同じ構造のconv2とconv3が続きます
conv4_1 (Conv2D) (None, 38, 38, 512) 1180160 pool3[0][0]
__________________________________________________________________________________________________
conv4_2 (Conv2D) (None, 38, 38, 512) 2359808 conv4_1[0][0]
__________________________________________________________________________________________________
conv4_3 (Conv2D) (None, 38, 38, 512) 2359808 conv4_2[0][0]
__________________________________________________________________________________________________
pool4 (MaxPooling2D) (None, 19, 19, 512) 0 conv4_3[0][0]
__________________________________________________________________________________________________
同じ構造のconv5が続き、次のfc6が続きます。。。
fc6 (Conv2D) (None, 19, 19, 1024) 4719616 pool5[0][0]
__________________________________________________________________________________________________
fc7 (Conv2D) (None, 19, 19, 1024) 1049600 fc6[0][0]
__________________________________________________________________________________________________
またまた、補助的な2層のconv6と7が続きます。
conv6_1 (Conv2D) (None, 19, 19, 256) 262400 fc7[0][0]
__________________________________________________________________________________________________
conv6_2 (Conv2D) (None, 10, 10, 512) 1180160 conv6_1[0][0]
__________________________________________________________________________________________________
conv7_1 (Conv2D) (None, 10, 10, 128) 65664 conv6_2[0][0]
__________________________________________________________________________________________________
conv7_1z (ZeroPadding2D) (None, 12, 12, 128) 0 conv7_1[0][0]
__________________________________________________________________________________________________
conv7_2 (Conv2D) (None, 5, 5, 256) 295168 conv7_1z[0][0]
__________________________________________________________________________________________________
ただし、conv7では一度ZeroPaddingを入れて、ボリュームを増やしています
conv8_1 (Conv2D) (None, 5, 5, 128) 32896 conv7_2[0][0]
__________________________________________________________________________________________________
conv4_3_norm (Normalize) (None, 38, 38, 512) 512 conv4_3[0][0]
__________________________________________________________________________________________________
conv8_2 (Conv2D) (None, 3, 3, 256) 295168 conv8_1[0][0]
__________________________________________________________________________________________________
pool6 (GlobalAveragePooling2D) (None, 256) 0 conv8_2[0][0]
__________________________________________________________________________________________________
conv8のpoolingは、GlobalAveragePooling2Dを使っています。
ここまでが、物体の識別に使われる個所だと考えていいと思います。そういう意味ではカテゴリに追加する場合などは、ここまでのNetworkを変更して学習するのがいいだろうと思います。
ここからは上記の出力を利用して、物体検出するためのLayerです。
conv4_3_norm_mbox_conf (Conv2D) (None, 38, 38, 63) 290367 conv4_3_norm[0][0]
__________________________________________________________________________________________________
fc7_mbox_conf (Conv2D) (None, 19, 19, 126) 1161342 fc7[0][0]
__________________________________________________________________________________________________
conv6_2_mbox_conf (Conv2D) (None, 10, 10, 126) 580734 conv6_2[0][0]
__________________________________________________________________________________________________
conv7_2_mbox_conf (Conv2D) (None, 5, 5, 126) 290430 conv7_2[0][0]
__________________________________________________________________________________________________
conv8_2_mbox_conf (Conv2D) (None, 3, 3, 126) 290430 conv8_2[0][0]
__________________________________________________________________________________________________
そして、各出力からまずはmbox_confを作成します。
conv4_3_norm_mbox_loc (Conv2D) (None, 38, 38, 12) 55308 conv4_3_norm[0][0]
__________________________________________________________________________________________________
fc7_mbox_loc (Conv2D) (None, 19, 19, 24) 221208 fc7[0][0]
__________________________________________________________________________________________________
conv6_2_mbox_loc (Conv2D) (None, 10, 10, 24) 110616 conv6_2[0][0]
__________________________________________________________________________________________________
conv7_2_mbox_loc (Conv2D) (None, 5, 5, 24) 55320 conv7_2[0][0]
__________________________________________________________________________________________________
conv8_2_mbox_loc (Conv2D) (None, 3, 3, 24) 55320 conv8_2[0][0]
__________________________________________________________________________________________________
そして、最後に各出力からmbox_locを作成します。
以下、predictionに向けて束ねていきます。
ということで、FineTuning的には、上記のconv1-5~fc6,7~conv6,7,8のパラメータを一部動かして決めるのだと思います。
そして検出層である、その後の層はフリーにして全てフィッティング対象とするのがいいと思います。
プログラム的には以下の部分をパラメータの固定調整します。
以下の例では、conv5-fc6-fc7-conv6とPredictionまでの層をフリーにして、その他(conv1,2,3,4,7,8)を固定としています。
freeze = ['input_1',
'conv1_1', 'conv1_2', 'pool1',
'conv2_1', 'conv2_2', 'pool2',
'conv3_1', 'conv3_2', 'conv3_3', 'pool3',
'conv4_1', 'conv4_2', 'conv4_3', 'pool4',
# 'conv5_1', 'conv5_2', 'conv5_3', 'pool5',
# 'fc6','fc7',
# 'conv6_1', 'conv6_2',
'conv7_1','conv7_2',
'conv8_1', 'conv8_2', 'pool6']
for L in model.layers:
if L.name in freeze:
L.trainable = False
結果
SSD500のFineTuningはそれなりに新たな物体〇△×を検出してくれました。
が、それなりにどの層を固定した方が良いのかの傾向は見えてきました。
以下、いくつかの層を固定した場合の違いを見ていきましょう。
conv4のみフリーの結果
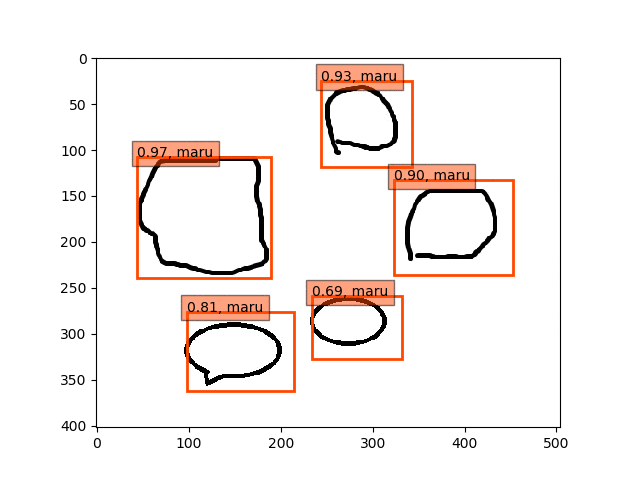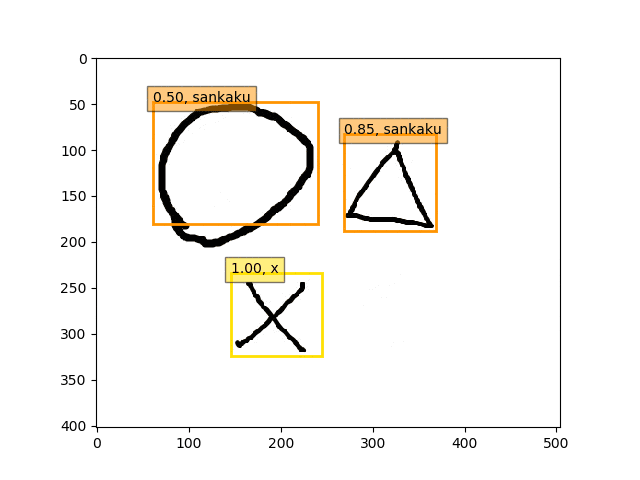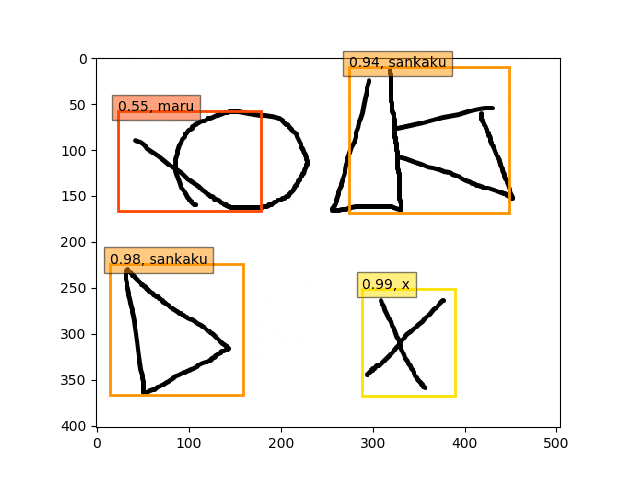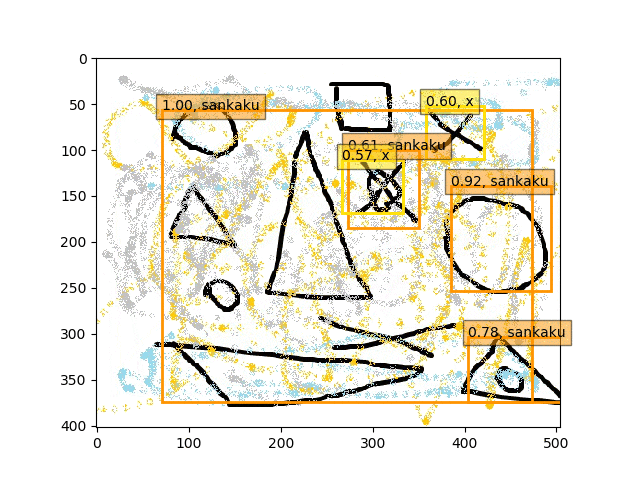
conv5-fc6,fc7のみフリーの結果
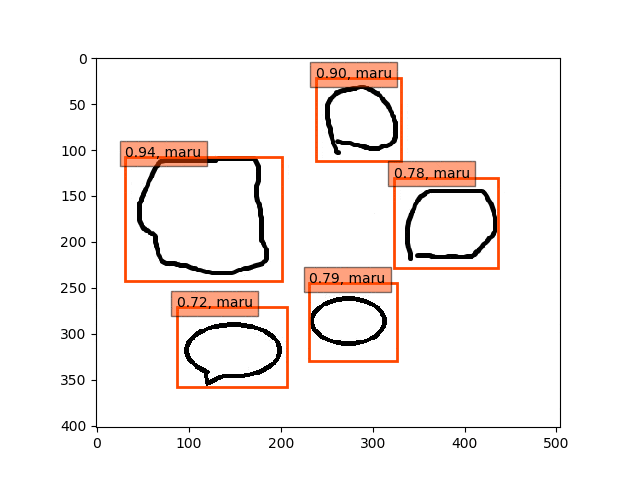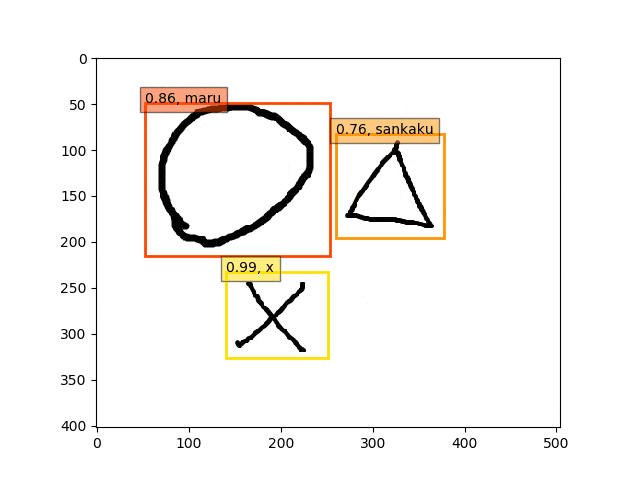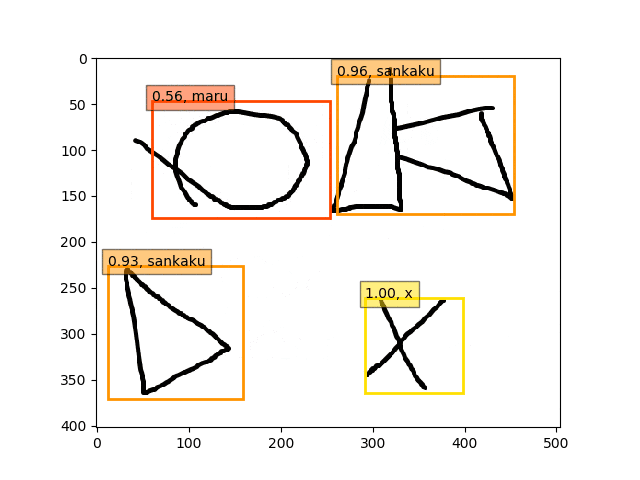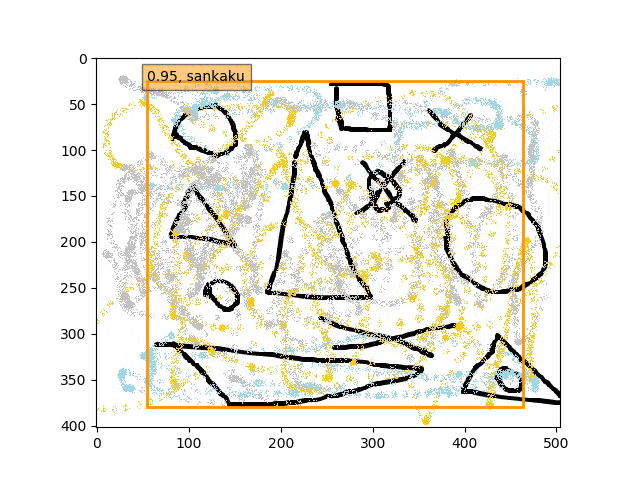
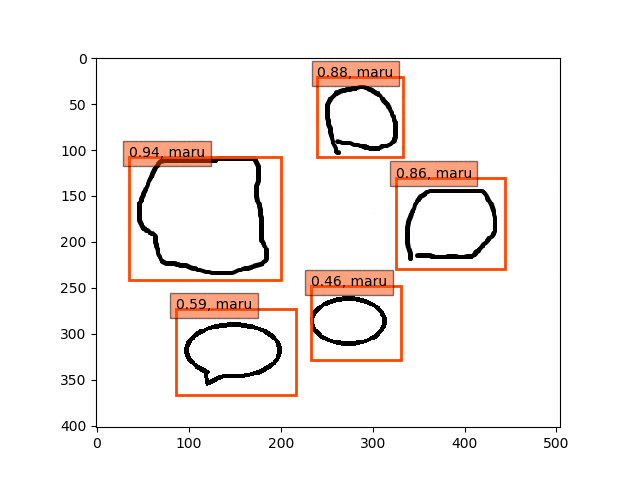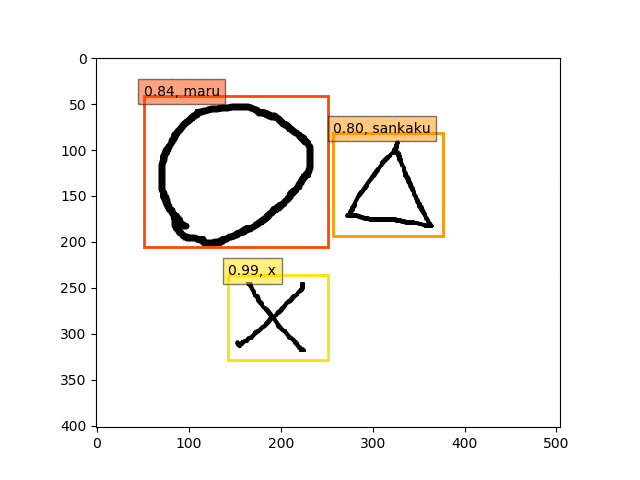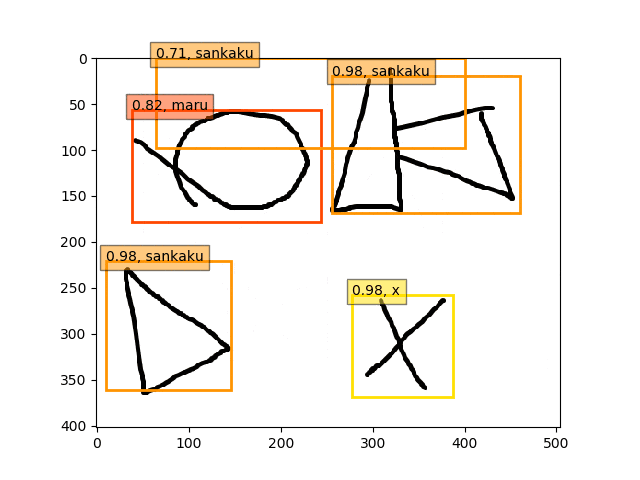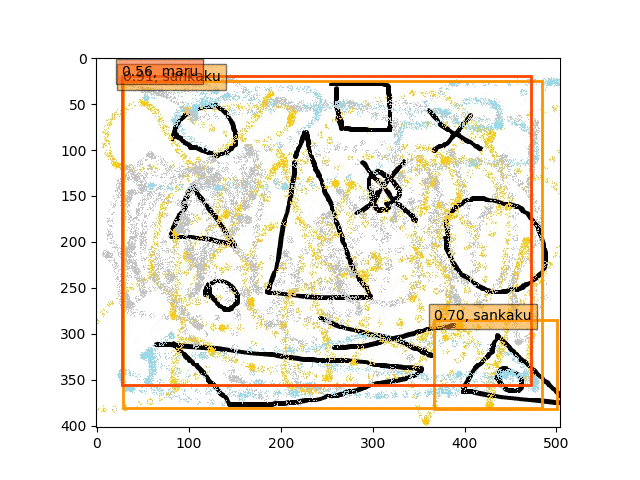
fc6,fc7-conv6のみフリーの結果
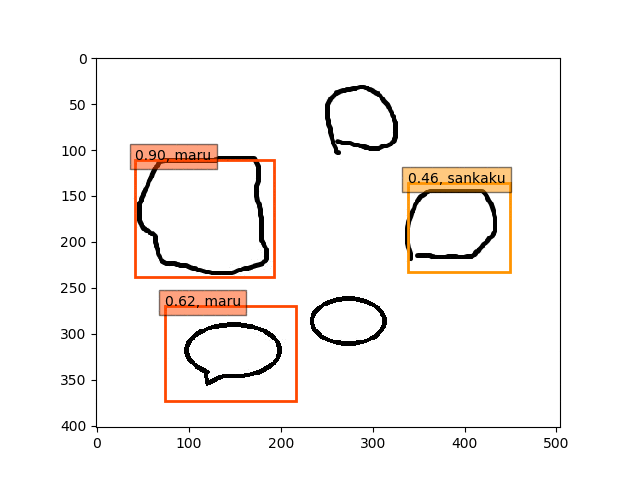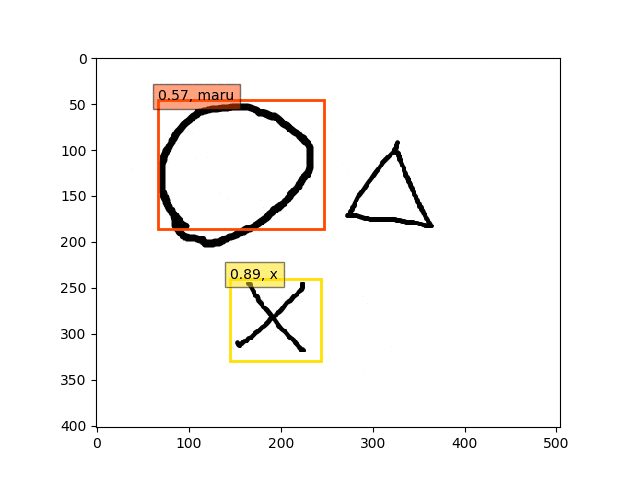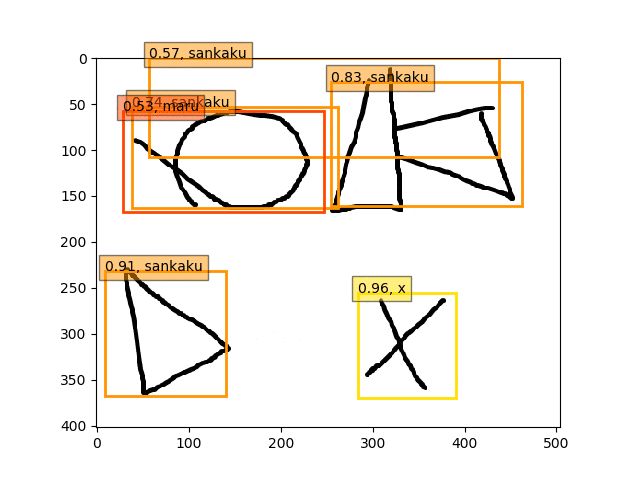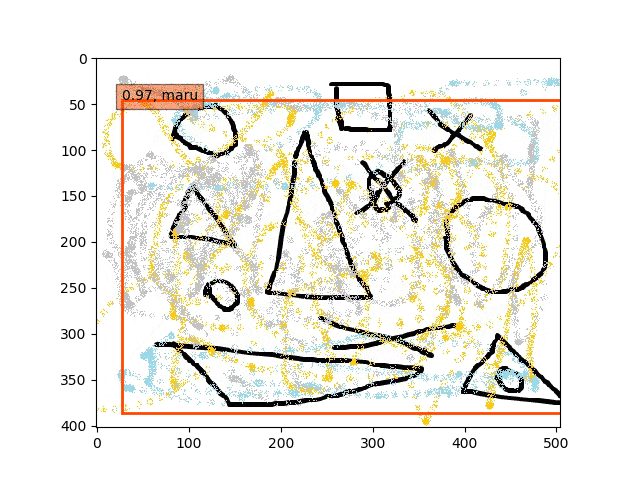
conv5-fc6,fc7-conv6のみフリーの結果
1epoch時点
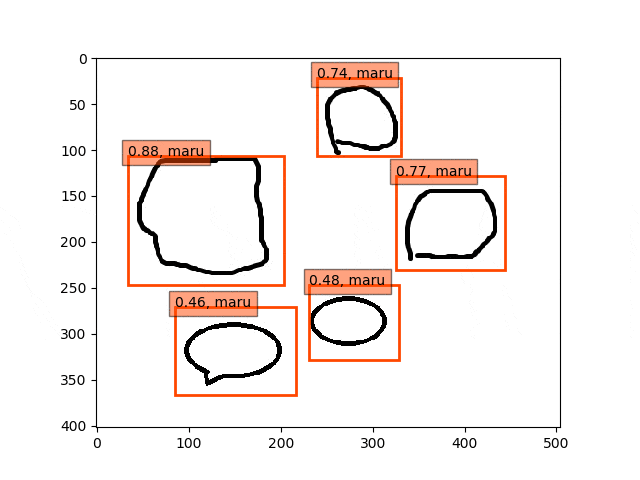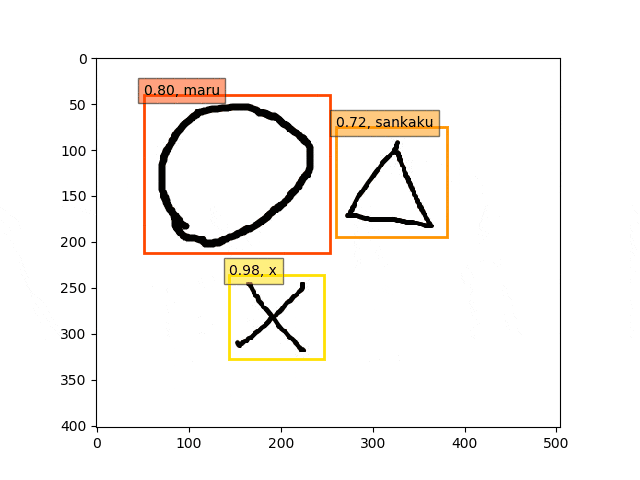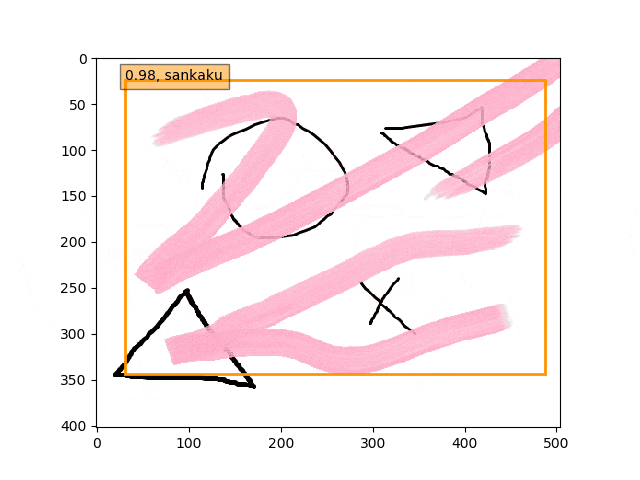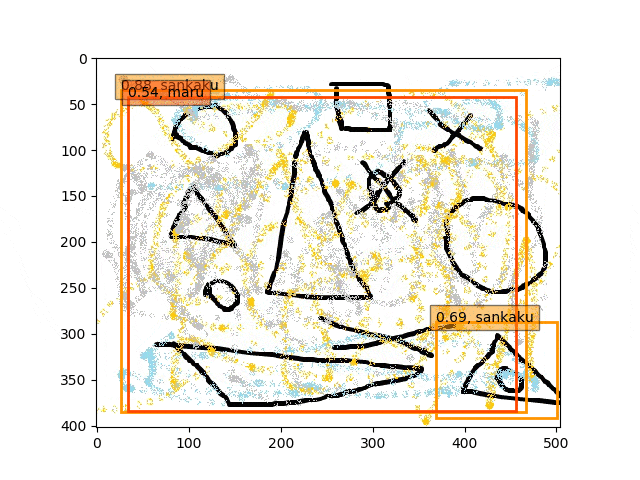
9epoch時点
conv5-fc6,fc7-conv6-conv7のみフリーの結果
1epoch時点
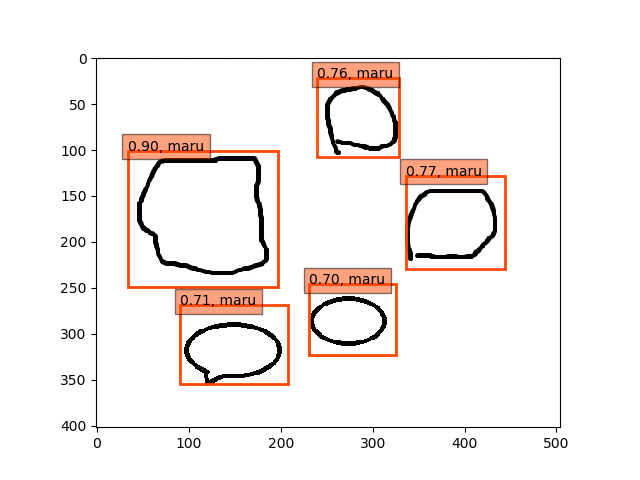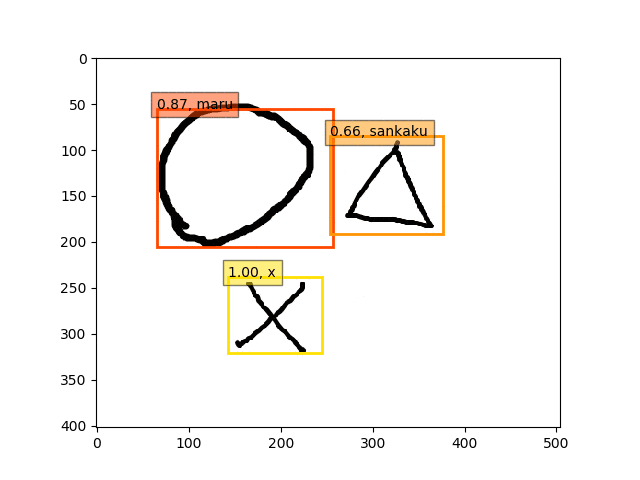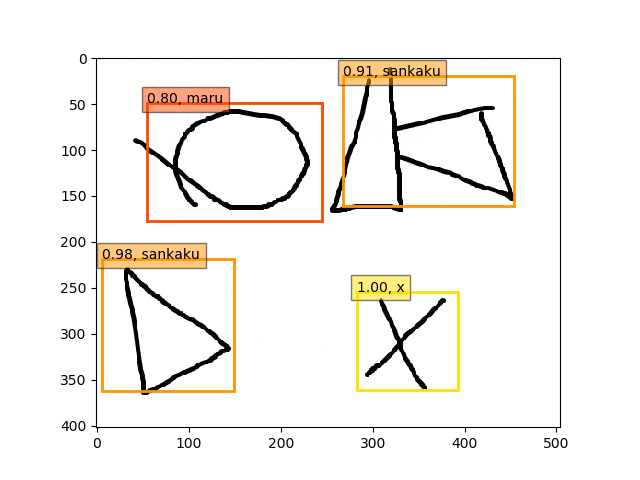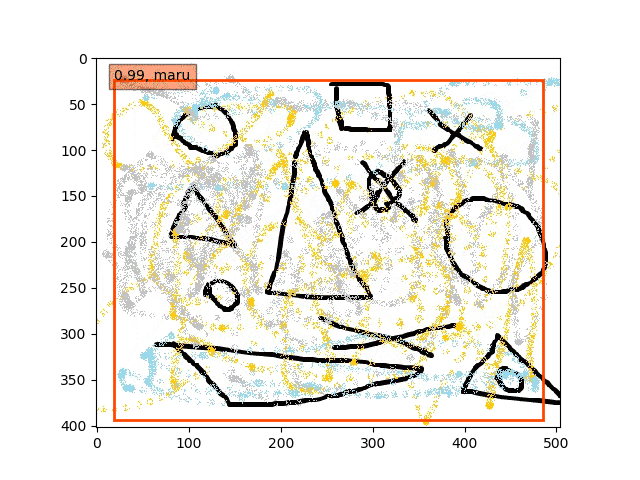
9epoch時点
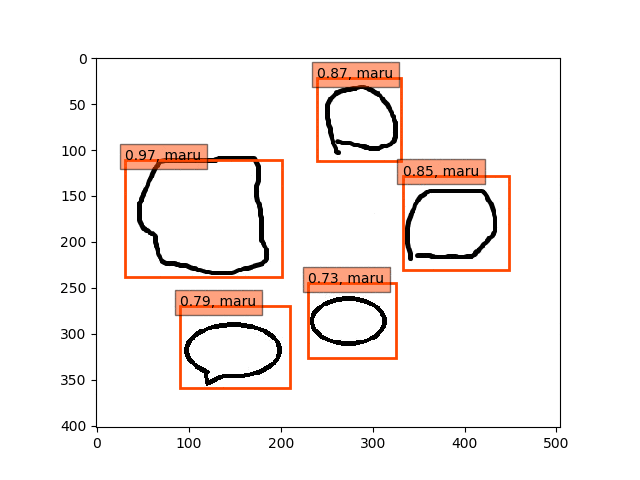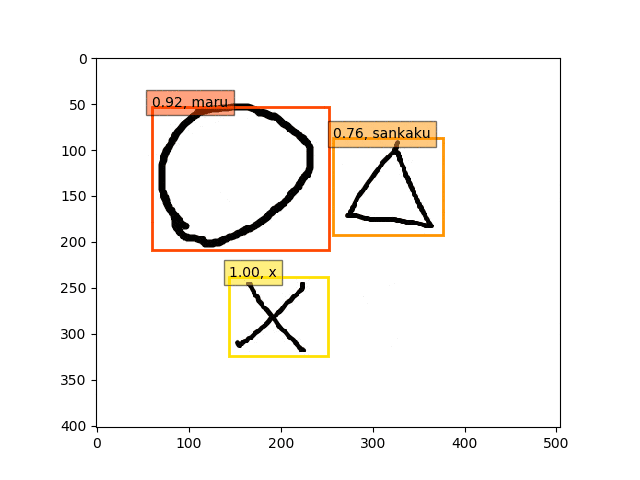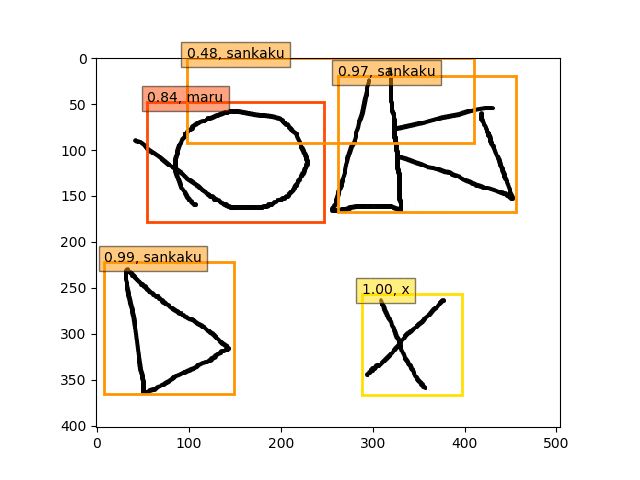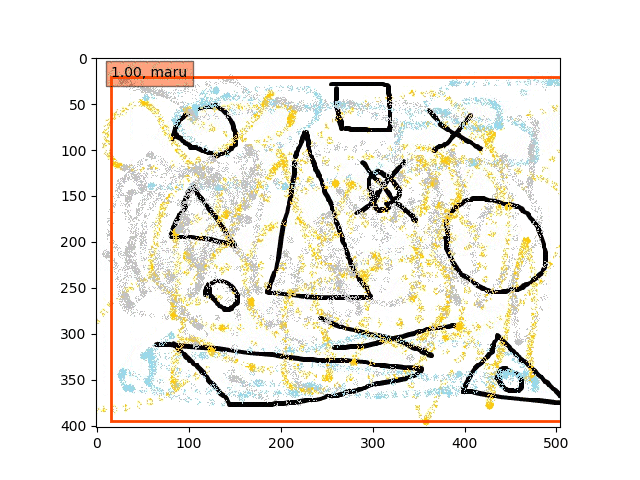
conv5-fc6,fc7-conv6-conv7-conv8のみフリーの結果
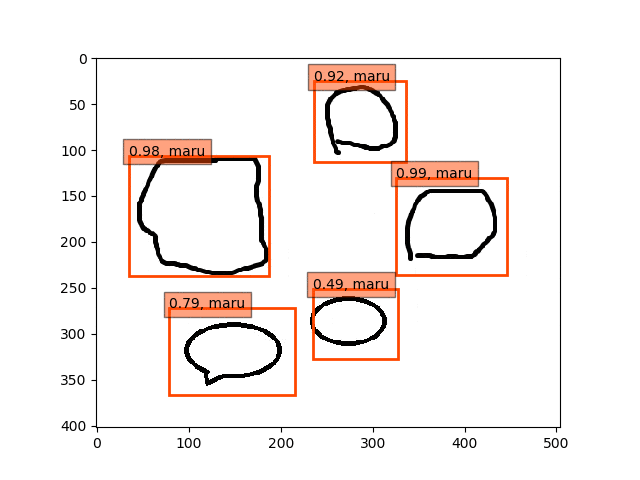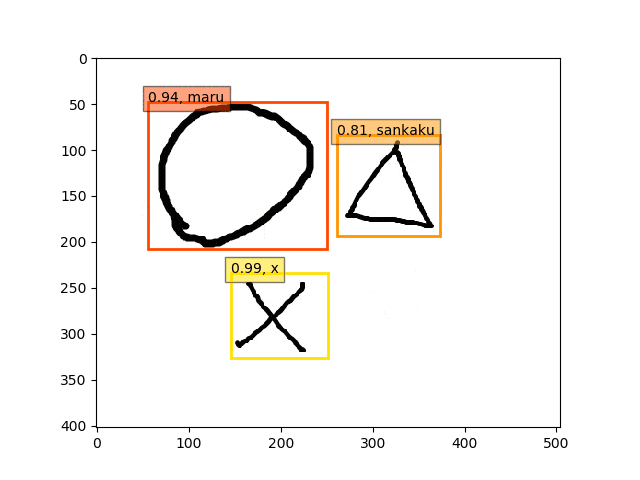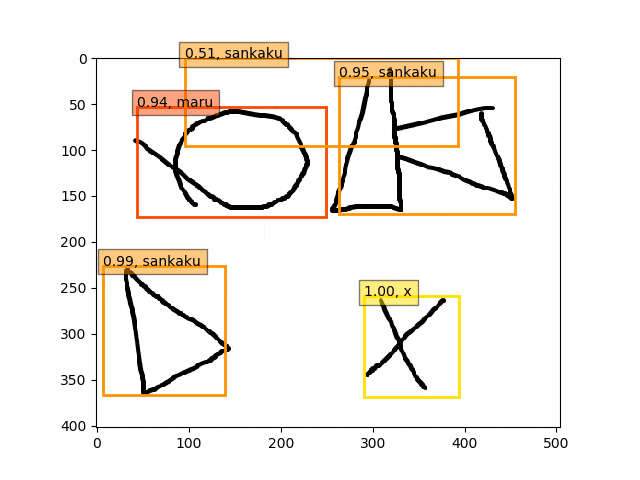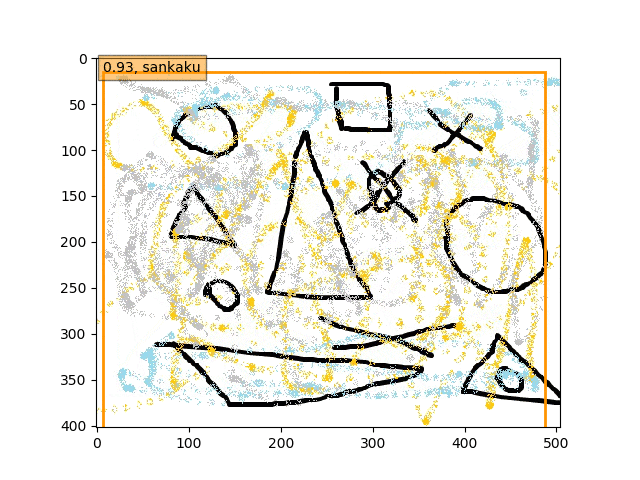
ということで、conv5-fc6,fc7-conv6のみフリーの結果のepoch9あたりが一番最適な検出結果になっているようです。
あんまり、フリーの領域を広げすぎても(今回はデータが少ないこともあり??)うまくいかないようです。
あくまで学習データは単独の〇△×であり、一方検証データは複合的なある意味ノイズを載せたりの難しい状況での検出である。
まとめ
・SSD500のFineTuningにより、〇△×データの物体検出を行った。
その結果、〇△×を検出できた。
・FineTuningとして、動かす層をどこにすべきかについて最適なフィッティング方法がありそうだ
・今回はVOC2007のデータ等で学習済のパラメータを使ったが、物体認識同様、本来どういう学習をしておけばより最適なのかは不明である。当然同様な問題領域のデータ群でpretrainingされていた方が有利であろう
・もともと、論文では物体認識でpretrainingしたNetworkで物体検出部分(box等)の学習をすべきらしいので検証の必要がある