 第五夜は、train_policy.pyのコード解説と学習について記述します。
### 説明したいこと
(1)コードのダウンロードサイト
(2)train_policy.pyのコード解説
(3)学習について
### (1)コードのダウンロードサイト
本書にも紹介されていますが、マイナビの本書の紹介ページからGitHubのサイトを紹介されているのでここで掲載します。
・[将棋AIで学ぶディープラーニング](https://book.mynavi.jp/ec/products/detail/id=88752)
[このGihubのサイト](https://github.com/TadaoYamaoka/python-dlshogi)から必要な[コードをダウンロードして昨夜の環境を作成](https://qiita.com/MuAuan/items/54c827a09b88475802cc)してください。
### (2)train_policy.pyのコード解説
学習するコードは以下のとおりです。
第五夜は、train_policy.pyのコード解説と学習について記述します。
### 説明したいこと
(1)コードのダウンロードサイト
(2)train_policy.pyのコード解説
(3)学習について
### (1)コードのダウンロードサイト
本書にも紹介されていますが、マイナビの本書の紹介ページからGitHubのサイトを紹介されているのでここで掲載します。
・[将棋AIで学ぶディープラーニング](https://book.mynavi.jp/ec/products/detail/id=88752)
[このGihubのサイト](https://github.com/TadaoYamaoka/python-dlshogi)から必要な[コードをダウンロードして昨夜の環境を作成](https://qiita.com/MuAuan/items/54c827a09b88475802cc)してください。
### (2)train_policy.pyのコード解説
学習するコードは以下のとおりです。
import numpy as np
import chainer
from chainer import cuda, Variable
from chainer import optimizers, serializers
import chainer.functions as F
chainerで必要なものをimportします。
from pydlshogi.common import *
from pydlshogi.network.policy import PolicyNetwork
from pydlshogi.features import *
from pydlshogi.read_kifu import *
python-shogiをインストールして上記のように利用します。
gunyarakun/python-shogi
import argparse
import random
import pickle
import os
import re
import logging
そして必要な関数をimportします。ここでreは正規表現を利用して、re.subでファイルの名称検知に利用しています。
parser = argparse.ArgumentParser()
parser.add_argument('kifulist_train', type=str, help='train kifu list')
parser.add_argument('kifulist_test', type=str, help='test kifu list')
parser.add_argument('--batchsize', '-b', type=int, default=32, help='Number of positions in each mini-batch')
parser.add_argument('--test_batchsize', type=int, default=512, help='Number of positions in each test mini-batch')
parser.add_argument('--epoch', '-e', type=int, default=10, help='Number of epoch times')
parser.add_argument('--model', type=str, default='model/model_policy', help='model file name')
parser.add_argument('--state', type=str, default='model/state_policy', help='state file name')
parser.add_argument('--initmodel', '-m', default='', help='Initialize the model from given file')
parser.add_argument('--resume', '-r', default='', help='Resume the optimization from snapshot')
parser.add_argument('--log', default=None, help='log file path')
parser.add_argument('--lr', type=float, default=0.01, help='learning rate')
parser.add_argument('--eval_interval', '-i', type=int, default=1000, help='eval interval')
args = parser.parse_args()
外部設定できるパラメータを定義し、default設定しています。
logging.basicConfig(format='%(asctime)s\t%(levelname)s\t%(message)s', datefmt='%Y/%m/%d %H:%M:%S', filename=args.log, level=logging.DEBUG)
--logが指定されている場合のlogファイル出力を定義しています。
model = PolicyNetwork()
model.to_gpu()
optimizer = optimizers.SGD(lr=args.lr)
optimizer.setup(model)
from pydlshogi.network.policy import PolicyNetworkで読み込んだPolicyNetworkでモデルを定義し、gpuに送ります。そして、optimizerを設定します。
# Init/Resume
if args.initmodel:
logging.info('Load model from {}'.format(args.initmodel))
serializers.load_npz(args.initmodel, model)
if args.resume:
logging.info('Load optimizer state from {}'.format(args.resume))
serializers.load_npz(args.resume, optimizer)
保管されているモデルと状態をloadします。
logging.info('read kifu start')
# 保存済みのpickleファイルがある場合、pickleファイルを読み込む
# train data
train_pickle_filename = re.sub(r'\..*?$', '', args.kifulist_train) + '.pickle'
if os.path.exists(train_pickle_filename):
with open(train_pickle_filename, 'rb') as f:
positions_train = pickle.load(f)
logging.info('load train pickle')
else:
positions_train = read_kifu(args.kifulist_train)
# test data
test_pickle_filename = re.sub(r'\..*?$', '', args.kifulist_test) + '.pickle'
if os.path.exists(test_pickle_filename):
with open(test_pickle_filename, 'rb') as f:
positions_test = pickle.load(f)
logging.info('load test pickle')
else:
positions_test = read_kifu(args.kifulist_test)
棋譜のpickleがあれば読み込みます。なければkifulistから読み込みます。
# 保存済みのpickleがない場合、pickleファイルを保存する
if not os.path.exists(train_pickle_filename):
with open(train_pickle_filename, 'wb') as f:
pickle.dump(positions_train, f, pickle.HIGHEST_PROTOCOL)
logging.info('save train pickle')
if not os.path.exists(test_pickle_filename):
with open(test_pickle_filename, 'wb') as f:
pickle.dump(positions_test, f, pickle.HIGHEST_PROTOCOL)
logging.info('save test pickle')
logging.info('read kifu end')
そして、pickleファイルがなければ保存します。
logging.info('train position num = {}'.format(len(positions_train)))
logging.info('test position num = {}'.format(len(positions_test)))
以下のような出力がでます。
2018/08/24 21:32:26 INFO train position num = 1892246
2018/08/24 21:32:26 INFO test position num = 208704
# mini batch
def mini_batch(positions, i, batchsize):
mini_batch_data = []
mini_batch_move = []
for b in range(batchsize):
features, move, win = make_features(positions[i + b])
mini_batch_data.append(features)
mini_batch_move.append(move)
return (Variable(cuda.to_gpu(np.array(mini_batch_data, dtype=np.float32))),
Variable(cuda.to_gpu(np.array(mini_batch_move, dtype=np.int32))))
def mini_batch_for_test(positions, batchsize):
mini_batch_data = []
mini_batch_move = []
for b in range(batchsize):
features, move, win = make_features(random.choice(positions))
mini_batch_data.append(features)
mini_batch_move.append(move)
return (Variable(cuda.to_gpu(np.array(mini_batch_data, dtype=np.float32))),
Variable(cuda.to_gpu(np.array(mini_batch_move, dtype=np.int32))))
上記で、mini_batchを読み込みます。
そして以下で学習します。このあとのロジックは先日のMNISTとほぼ同様です。
# train
logging.info('start training')
itr = 0
sum_loss = 0
for e in range(args.epoch):
positions_train_shuffled = random.sample(positions_train, len(positions_train))
itr_epoch = 0
sum_loss_epoch = 0
for i in range(0, len(positions_train_shuffled) - args.batchsize, args.batchsize):
x, t = mini_batch(positions_train_shuffled, i, args.batchsize)
y = model(x)
model.cleargrads()
loss = F.softmax_cross_entropy(y, t)
loss.backward()
optimizer.update()
itr += 1
sum_loss += loss.data
itr_epoch += 1
sum_loss_epoch += loss.data
# print train loss and test accuracy
if optimizer.t % args.eval_interval == 0:
x, t = mini_batch_for_test(positions_test, args.test_batchsize)
y = model(x)
logging.info('epoch = {}, iteration = {}, loss = {}, accuracy = {}'.format(optimizer.epoch + 1, optimizer.t, sum_loss / itr, F.accuracy(y, t).data))
itr = 0
sum_loss = 0
# validate test data
logging.info('validate test data')
itr_test = 0
sum_test_accuracy = 0
for i in range(0, len(positions_test) - args.batchsize, args.batchsize):
x, t = mini_batch(positions_test, i, args.batchsize)
y = model(x)
itr_test += 1
sum_test_accuracy += F.accuracy(y, t).data
logging.info('epoch = {}, iteration = {}, train loss avr = {}, test accuracy = {}'.format(optimizer.epoch + 1, optimizer.t, sum_loss_epoch / itr_epoch, sum_test_accuracy / itr_test))
optimizer.new_epoch()
logging.info('save the model')
serializers.save_npz(args.model, model)
logging.info('save the optimizer')
serializers.save_npz(args.state, optimizer)
この学習までのロジックは今後も学習データを変更したり、そもそもモデルを変更したりするのに必須な知識です。
(3)学習について
学習はMNISTと同様です。
>python train_policy.py kifulist3000_train.txt kifulist3000_test.txt --eval_interval 100
せっかくなので、昨夜のkifulist3000_train.txt kifulist3000_test.txtを使って学習してみました。
2018/08/24 19:56:30 INFO read kifu start
2018/08/24 20:02:12 INFO save train pickle
2018/08/24 20:02:13 INFO save test pickle
2018/08/24 20:02:13 INFO read kifu end
2018/08/24 20:02:13 INFO train position num = 1892246
2018/08/24 20:02:13 INFO test position num = 208704
2018/08/24 20:02:13 INFO start training
2018/08/24 20:02:18 INFO epoch = 1, iteration = 100, loss = 7.6466594, accuracy = 0.005859375
2018/08/24 20:02:21 INFO epoch = 1, iteration = 200, loss = 7.2374353, accuracy = 0.0078125
...
2018/08/24 20:30:30 INFO epoch = 1, iteration = 58700, loss = 2.9090836, accuracy = 0.24804688
2018/08/24 20:30:33 INFO epoch = 1, iteration = 58800, loss = 2.9746766, accuracy = 0.30078125
2018/08/24 20:30:36 INFO epoch = 1, iteration = 58900, loss = 2.96551, accuracy = 0.29101562
2018/08/24 20:30:39 INFO epoch = 1, iteration = 59000, loss = 2.9492474, accuracy = 0.33984375
2018/08/24 20:30:42 INFO epoch = 1, iteration = 59100, loss = 2.915308, accuracy = 0.27734375
2018/08/24 20:30:43 INFO validate test data
2018/08/24 20:32:40 INFO epoch = 1, iteration = 59132, train loss avr = 3.755527, test accuracy = 0.29243502
2018/08/24 20:32:40 INFO save the model
2018/08/24 20:32:40 INFO save the optimizer
学習時間は、棋譜読み込みに6分かかっていますが、その後は30分程度でした。
※環境は1080です
結果は、train loss avr = 3.755527, test accuracy = 0.29243502
でした。
そして、標準出力をファイルにコピペしてファイル出力して、logをplotすると以下のとおりになりました。
>python utils\plot_log.py log3000_policy
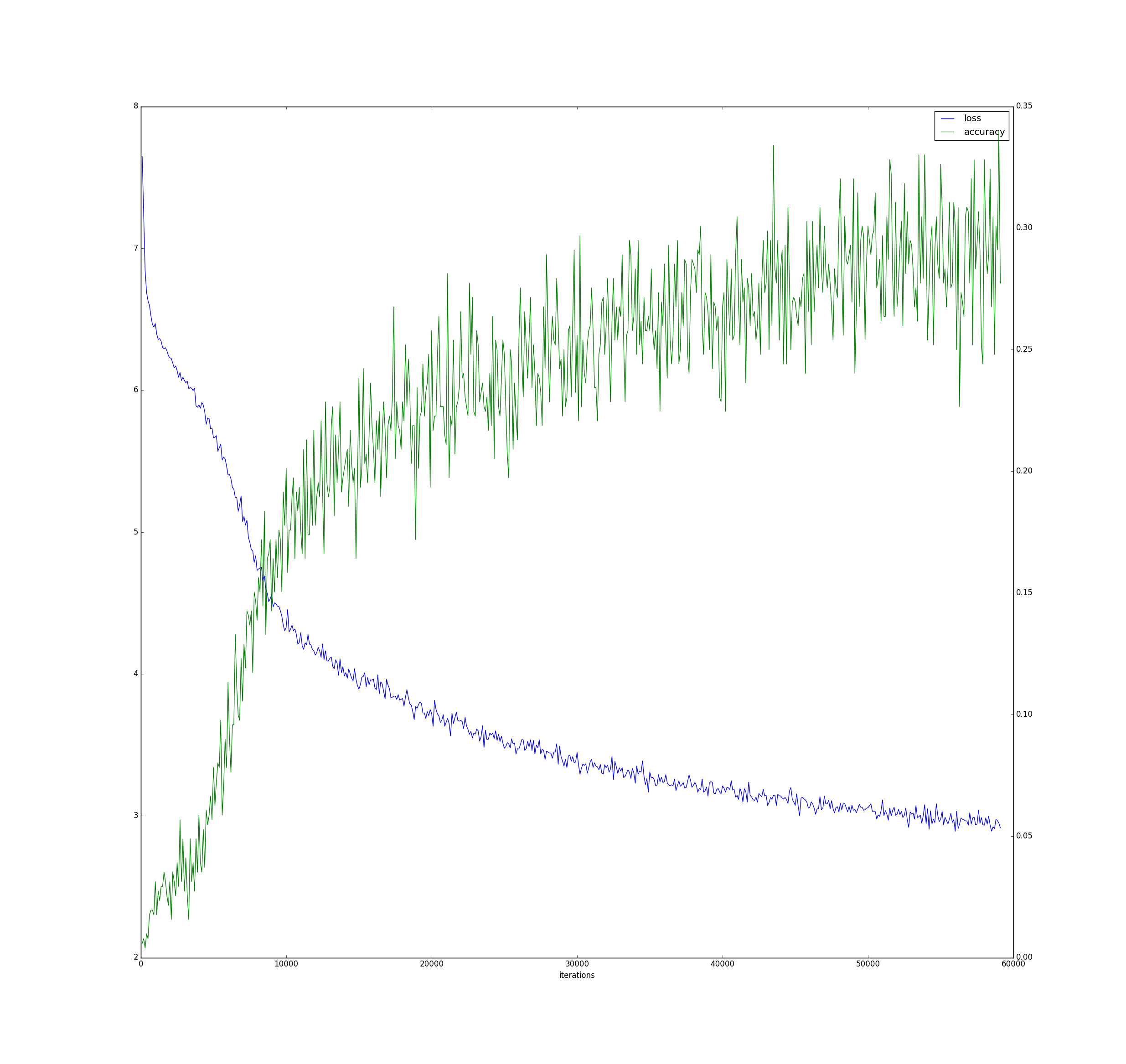
さらに10epoch(約4時間半)回した結果、以下のとおりとなりました。
>python train_policy.py kifulist3000_train.txt kifulist3000_test.txt --eval_interval 1000 -m model\model_policy -r model\state_policy
昨夜の結果(-m model\model_policy -r model\state_policy
)を利用して続きを計算しています。
2018/08/25 00:48:29 INFO Load model from model\model_policy
2018/08/25 00:48:29 INFO Load optimizer state from model\state_policy
2018/08/25 00:48:29 INFO read kifu start
2018/08/25 00:48:49 INFO load train pickle
2018/08/25 00:48:52 INFO load test pickle
2018/08/25 00:48:52 INFO read kifu end
2018/08/25 00:48:52 INFO train position num = 1892246
2018/08/25 00:48:52 INFO test position num = 208704
2018/08/25 00:48:52 INFO start training
2018/08/25 00:49:18 INFO epoch = 2, iteration = 60000, loss = 2.892616, accuracy = 0.29101562
2018/08/25 00:49:44 INFO epoch = 2, iteration = 61000, loss = 2.8935423, accuracy = 0.28515625
...
2018/08/25 05:22:19 INFO epoch = 11, iteration = 649000, loss = 1.8333049, accuracy = 0.41992188
2018/08/25 05:22:45 INFO epoch = 11, iteration = 650000, loss = 1.8299339, accuracy = 0.43554688
2018/08/25 05:22:57 INFO validate test data
2018/08/25 05:24:44 INFO epoch = 11, iteration = 650452, train loss avr = 1.807204, test accuracy = 0.40758222
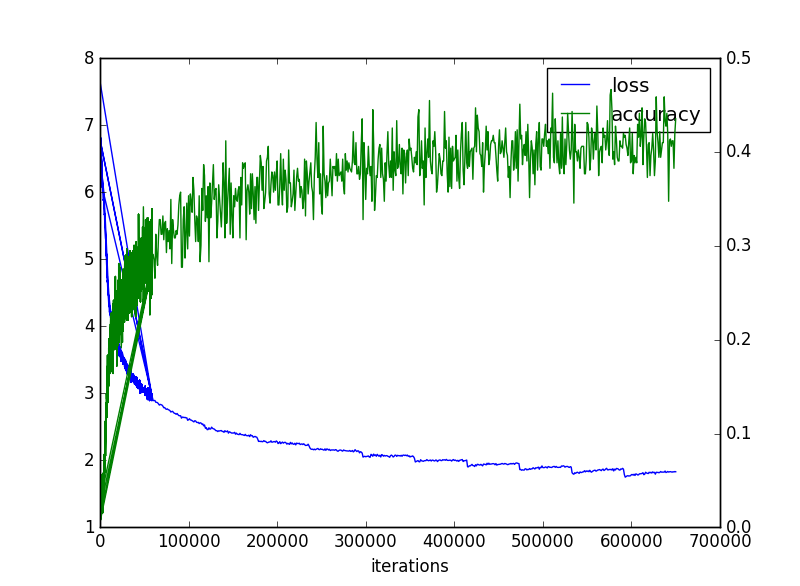
train loss avr = 1.807204, test accuracy = 0.40758222
まで行きました。120万回まわしてみると以下のとおりになりました。
そして、この辺りでどうにか飽和したようです。そして若干test accuracyが下がったように見えます。
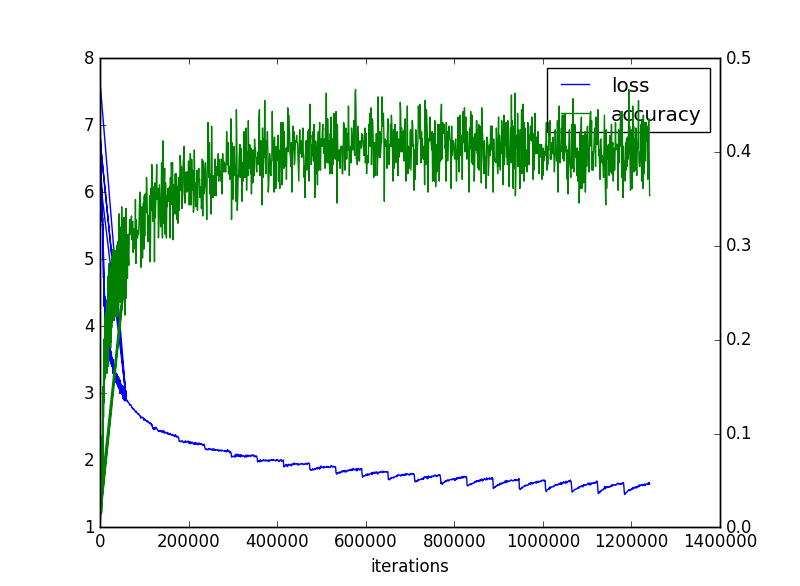
まとめ
・train_policy.pyの概略を説明した
・方策ネットワークで学習した
・1epoch30分くらいであり、11epoch65万回でtest accuracy = 0.40758222まで到達し、21epoch124万回でほぼlossが飽和してaccuracyは若干悪化したように見える
・どの程度の強さか対戦してみよう
おまけ
ここが本来将棋らしいところですが、何せ難易度高いのと、上述したように知らないとしても、学習やモデルの変更などは出来るので、必須とは言えない部分です。ただし、他の課題や応用するためにはここを理解することはとても有意義な部分だし、そもそも将棋というゲームを成り立たせている部分です。
ということで、ここは詳述については本書を参照願います。
まず、python-shogiのインストールは以下のとおりです。
>pip install python-shogi
棋譜の読み込みや局面の管理を行います。
上記使われている3つの関数を説明します。
read_kifu.py
features.py
common.py
まず、上記のコードで以下に説明するように将棋ならではのロジックが含まれています。以下で棋譜を読みます。
positions_train = read_kifu(args.kifulist_train)
コードは以下のとおりです。
import shogi
import shogi.CSA
import copy
from pydlshogi.features import *
# read kifu
def read_kifu(kifu_list_file):
positions = []
with open(kifu_list_file, 'r') as f:
for line in f.readlines():
filepath = line.rstrip('\r\n')
kifu = shogi.CSA.Parser.parse_file(filepath)[0]
win_color = shogi.BLACK if kifu['win'] == 'b' else shogi.WHITE
board = shogi.Board()
for move in kifu['moves']:
if board.turn == shogi.BLACK:
piece_bb = copy.deepcopy(board.piece_bb)
occupied = copy.deepcopy((board.occupied[shogi.BLACK], board.occupied[shogi.WHITE]))
pieces_in_hand = copy.deepcopy((board.pieces_in_hand[shogi.BLACK], board.pieces_in_hand[shogi.WHITE]))
else:
piece_bb = [bb_rotate_180(bb) for bb in board.piece_bb]
occupied = (bb_rotate_180(board.occupied[shogi.WHITE]), bb_rotate_180(board.occupied[shogi.BLACK]))
pieces_in_hand = copy.deepcopy((board.pieces_in_hand[shogi.WHITE], board.pieces_in_hand[shogi.BLACK]))
# move label
move_label = make_output_label(shogi.Move.from_usi(move), board.turn)
# result
win = 1 if win_color == board.turn else 0
positions.append((piece_bb, occupied, pieces_in_hand, move_label, win))
board.push_usi(move)
return positions
ここで、
kifu = shogi.CSA.Parser.parse_file(filepath)[0]
で棋譜を読み込みます。
そして、棋譜の再生は以下のとおりです。
board = shogi.Board()
for move in kifu['moves']:
boad.push_usi(move)
そして、
piece_bb;駒ごとの配置の配列0;空白、1;歩、2;香車、。。
occupied;手番ごとに占有している座標の配列0;先手、1;後手
pieces_in_hand;手番ごとの持ち駒の配列
そして以下のfeatures.pyでビットボードから入力特徴に変換します。
import numpy as np
import shogi
import copy
from pydlshogi.common import *
def make_input_features(piece_bb, occupied, pieces_in_hand):
features = []
for color in shogi.COLORS:
# board pieces
for piece_type in shogi.PIECE_TYPES_WITH_NONE[1:]:
bb = piece_bb[piece_type] & occupied[color]
feature = np.zeros(9*9)
for pos in shogi.SQUARES:
if bb & shogi.BB_SQUARES[pos] > 0:
feature[pos] = 1
features.append(feature.reshape((9, 9)))
# pieces in hand
for piece_type in range(1, 8):
for n in range(shogi.MAX_PIECES_IN_HAND[piece_type]):
if piece_type in pieces_in_hand[color] and n < pieces_in_hand[color][piece_type]:
feature = np.ones(9*9)
else:
feature = np.zeros(9*9)
features.append(feature.reshape((9, 9)))
return features
def make_input_features_from_board(board):
if board.turn == shogi.BLACK:
piece_bb = board.piece_bb
occupied = (board.occupied[shogi.BLACK], board.occupied[shogi.WHITE])
pieces_in_hand = (board.pieces_in_hand[shogi.BLACK], board.pieces_in_hand[shogi.WHITE])
else:
piece_bb = [bb_rotate_180(bb) for bb in board.piece_bb]
occupied = (bb_rotate_180(board.occupied[shogi.WHITE]), bb_rotate_180(board.occupied[shogi.BLACK]))
pieces_in_hand = (board.pieces_in_hand[shogi.WHITE], board.pieces_in_hand[shogi.BLACK])
return make_input_features(piece_bb, occupied, pieces_in_hand)
def make_output_label(move, color):
move_to = move.to_square
move_from = move.from_square
# 白の場合盤を回転
if color == shogi.WHITE:
move_to = SQUARES_R180[move_to]
if move_from is not None:
move_from = SQUARES_R180[move_from]
# move direction
if move_from is not None:
to_y, to_x = divmod(move_to, 9)
from_y, from_x = divmod(move_from, 9)
dir_x = to_x - from_x
dir_y = to_y - from_y
if dir_y < 0 and dir_x == 0:
move_direction = UP
elif dir_y == -2 and dir_x == -1:
move_direction = UP2_LEFT
elif dir_y == -2 and dir_x == 1:
move_direction = UP2_RIGHT
elif dir_y < 0 and dir_x < 0:
move_direction = UP_LEFT
elif dir_y < 0 and dir_x > 0:
move_direction = UP_RIGHT
elif dir_y == 0 and dir_x < 0:
move_direction = LEFT
elif dir_y == 0 and dir_x > 0:
move_direction = RIGHT
elif dir_y > 0 and dir_x == 0:
move_direction = DOWN
elif dir_y > 0 and dir_x < 0:
move_direction = DOWN_LEFT
elif dir_y > 0 and dir_x > 0:
move_direction = DOWN_RIGHT
# promote
if move.promotion:
move_direction = MOVE_DIRECTION_PROMOTED[move_direction]
else:
# 持ち駒
move_direction = len(MOVE_DIRECTION) + move.drop_piece_type - 1
move_label = 9 * 9 * move_direction + move_to
return move_label
def make_features(position):
piece_bb, occupied, pieces_in_hand, move, win = position
features = make_input_features(piece_bb, occupied, pieces_in_hand)
return (features, move, win)
ここでcommon.pyは以下のように180度盤を回転したりする関数です。
先手―後手の変更に際して利用しています。
import shogi
# 移動の定数
MOVE_DIRECTION = [
UP, UP_LEFT, UP_RIGHT, LEFT, RIGHT, DOWN, DOWN_LEFT, DOWN_RIGHT, UP2_LEFT, UP2_RIGHT,
UP_PROMOTE, UP_LEFT_PROMOTE, UP_RIGHT_PROMOTE, LEFT_PROMOTE, RIGHT_PROMOTE, DOWN_PROMOTE, DOWN_LEFT_PROMOTE, DOWN_RIGHT_PROMOTE, UP2_LEFT_PROMOTE, UP2_RIGHT_PROMOTE
] = range(20)
# 成り変換テーブル
MOVE_DIRECTION_PROMOTED = [
UP_PROMOTE, UP_LEFT_PROMOTE, UP_RIGHT_PROMOTE, LEFT_PROMOTE, RIGHT_PROMOTE, DOWN_PROMOTE, DOWN_LEFT_PROMOTE, DOWN_RIGHT_PROMOTE, UP2_LEFT_PROMOTE, UP2_RIGHT_PROMOTE
]
# 指し手を表すラベルの数
MOVE_DIRECTION_LABEL_NUM = len(MOVE_DIRECTION) + 7 # 7は持ち駒の種類
# rotate 180degree
SQUARES_R180 = [
shogi.I1, shogi.I2, shogi.I3, shogi.I4, shogi.I5, shogi.I6, shogi.I7, shogi.I8, shogi.I9,
shogi.H1, shogi.H2, shogi.H3, shogi.H4, shogi.H5, shogi.H6, shogi.H7, shogi.H8, shogi.H9,
shogi.G1, shogi.G2, shogi.G3, shogi.G4, shogi.G5, shogi.G6, shogi.G7, shogi.G8, shogi.G9,
shogi.F1, shogi.F2, shogi.F3, shogi.F4, shogi.F5, shogi.F6, shogi.F7, shogi.F8, shogi.F9,
shogi.E1, shogi.E2, shogi.E3, shogi.E4, shogi.E5, shogi.E6, shogi.E7, shogi.E8, shogi.E9,
shogi.D1, shogi.D2, shogi.D3, shogi.D4, shogi.D5, shogi.D6, shogi.D7, shogi.D8, shogi.D9,
shogi.C1, shogi.C2, shogi.C3, shogi.C4, shogi.C5, shogi.C6, shogi.C7, shogi.C8, shogi.C9,
shogi.B1, shogi.B2, shogi.B3, shogi.B4, shogi.B5, shogi.B6, shogi.B7, shogi.B8, shogi.B9,
shogi.A1, shogi.A2, shogi.A3, shogi.A4, shogi.A5, shogi.A6, shogi.A7, shogi.A8, shogi.A9,
]
def bb_rotate_180(bb):
bb_r180 = 0
for pos in shogi.SQUARES:
if bb & shogi.BB_SQUARES[pos] > 0:
bb_r180 += 1 << SQUARES_R180[pos]
return bb_r180