今回は、Autoencoderと比較してみる。
特に、中間層の役割を中心に生成画像の良しあしとどのようにかかわっているかを見る。
コードは、以下に置いた
MuAuan/AutoEncoder
また、以下を参考にした。
【参考】
1.Kerasで学ぶAutoencoder
ということで、今回やったこと
①Convolutional Autoencoderの中間層の次元を変更して、中間層画像と生成画像の相関を見る
MNISTとCifar10についてやってみました
②CapsNetをAutoencoderに分解して多層化してみるとともに、生成画像の中間層の次元依存性を見る
説明
①Convolutional Autoencoderの中間層の次元を変更して、中間層画像と生成画像の相関を見るについては、コードの以下の箇所に対応するもののみ変更した
以下は、Cifar10の場合のmodel.summary()である。
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_3 (Conv2D) (None, 8, 8, 48) 13872
dim_factor=1*2*3
encoding_dim = 32*dim_factor
input_img = Input(shape=(32,32,3))
# input_img = Input(shape=(3072,))
encoded = encoded(input_img, dim_factor)
decoded = decoded(encoded, dim_factor)
autoencoder = Model(input=input_img, output=decoded)
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 32, 32, 3) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 32, 32, 64) 1792
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 16, 16, 64) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 16, 16, 32) 18464
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 8, 8, 32) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 8, 8, 48) 13872
_________________________________________________________________
conv2d_4 (Conv2D) (None, 8, 8, 48) 20784
_________________________________________________________________
up_sampling2d_1 (UpSampling2 (None, 16, 16, 48) 0
_________________________________________________________________
conv2d_5 (Conv2D) (None, 16, 16, 3) 1299
_________________________________________________________________
up_sampling2d_2 (UpSampling2 (None, 32, 32, 3) 0
_________________________________________________________________
conv2d_6 (Conv2D) (None, 32, 32, 3) 84
=================================================================
Total params: 56,295
Trainable params: 56,295
Non-trainable params: 0
_________________________________________________________________
結果
MNISTの中間層の次元の影響について
以下は、中間層の次元が4D(4x1x1)の場合の収束による変化を見ている。すなわち、10000個データx10epochと10000個データx50epochを比較したものである。予想に反して、そもそも中間層の画像も大きく変化する(模様が変わる)。
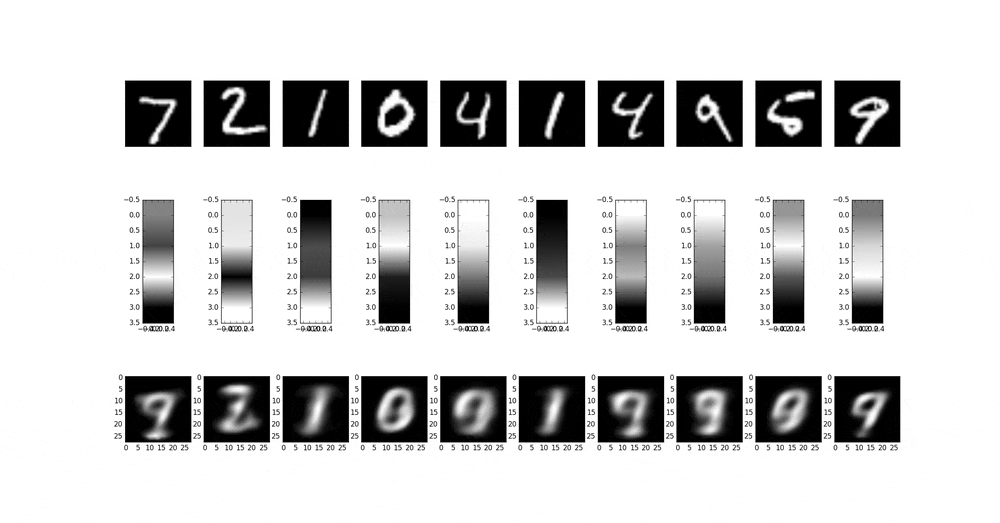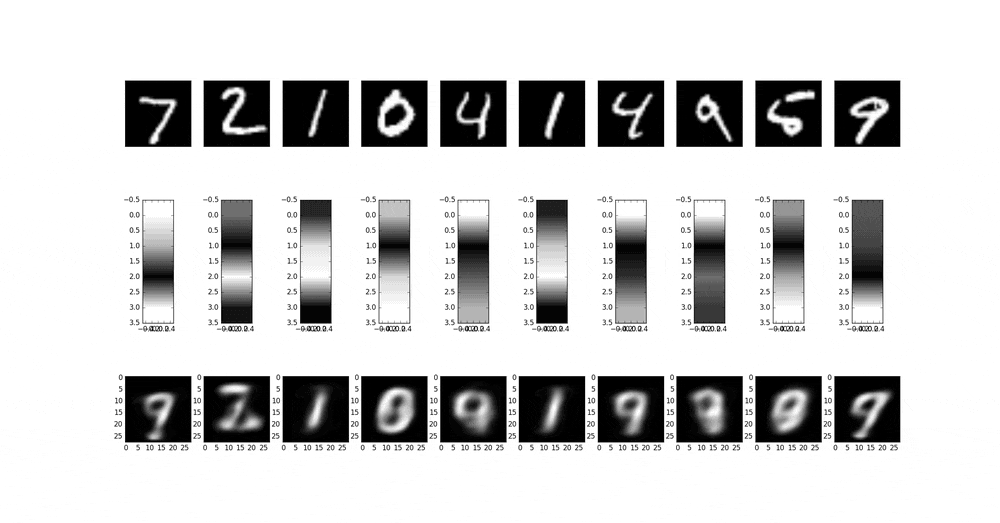
以下は、中間層の次元が40D(40x1x1)の場合の収束による中間層の変化を見ている。条件は同上。
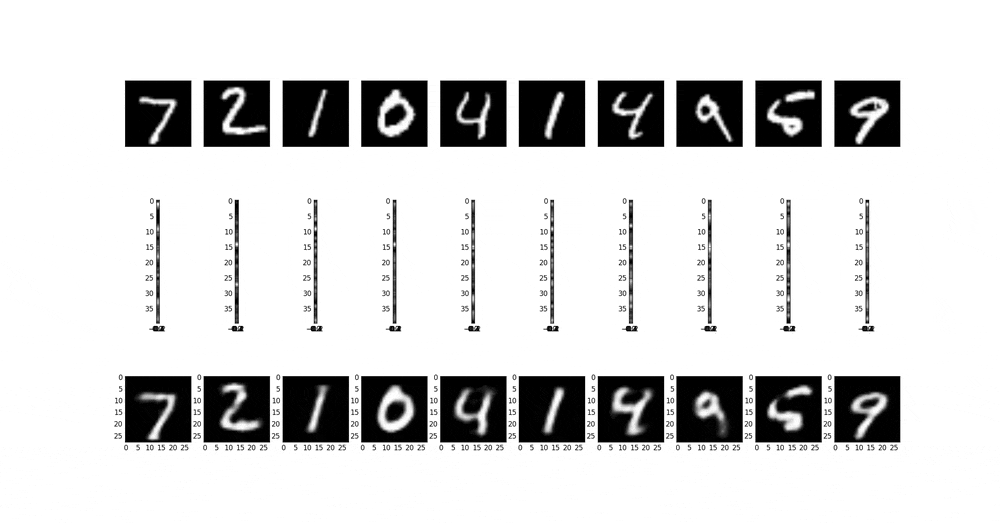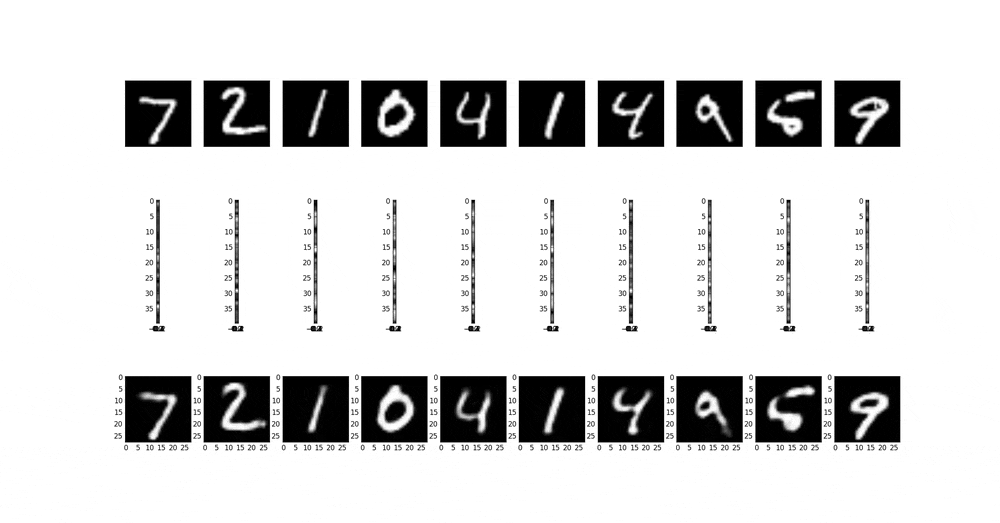
以下は、中間層の次元を1D(1x1x1)から1000D(1000x1x1)まで変更したときの中間層の画像を生成画像を並べたものである。条件は10000個データx10epochである。予想どおり、中間層の次元が小さいと表現力ないから数字のような簡単なものも再現できない。流石に1000次元あると綺麗な画像が出る。だいたい20次元超えたあたりから急に綺麗になって、100次元で再現している。

Autoencoderって、こんなに綺麗な画像生成ができるんですね。。。
中間層の次元、以下のとおり変更した
第一グループ「32x1x1,32x10x1,32x32x1」
第二グループ「32x6x1,32x16x1,32x16x3,32x32x3,64x64x3」
早速、以下に得られた画像を示す。
第一グループ「32x1x1,32x10x1,32x32x1」

第二グループ「32x6x1,32x16x1,32x16x3,32x32x3,64x64x3」

簡単なAutoencoderでも中間層の次元さえ増やせばこんなに綺麗なるとは知らなかった。下手なGANよりよほど美しい。むしろ仕組みというより下手なGANは中間層の次元が足りていない可能性がある。
以上は、通常のAutoencoderでの生成画像の中間層の次元依存性であるが、以下今回ターゲットであるCapsNetについて同じような中間層の次元という観点で生成画像の美しさを見ようと思う。そもそもCapsNetは画像の特徴をより空間的に把握するために導入されたものであり、(皮肉的な意味で)誤解した書き方をすれば中間層の表現力をつける目的で導入されていると解釈できる。
CapsNetの多層化による精度向上と生成画像の美しさとCapsNetの中間層の次元と生成画像
CapsNetの多層化により、75%程度の精度向上までは出来たが、生成画像はほとんどシャープにはならなかった。
以下は、CapsNetの中間層、つまりCapsLayer周りの次元を見るために、digitcapsとその手前のconv2dの出力を無理やりカラー画像に変換して、生成画像を見たものである。
※本来はもともとの目的である空間的な把握した実体を表現したかったが、方法が見つからないので二次元カラー画像とした(論文ではそのような分類での記載があるがウワンには意味不明であった)

そして、以下のような構造であるため、CapsNetの中間層の次元を変更しようとすると、Mask()の次元はCapsuleLayerの次元と同一でありそれ以上上げられないということで、生成画像が中間層の次元に依存しており、ほとんど改善は見られなかった。
因みに、上記の中間層は96次元の場合のものである。
Train on 50000 samples, validate on 10000 samples
Epoch 1/1
50000/50000 [==============================] - 1390s 28ms/step - loss: 0.3467 - out_caps_loss: 0.1070 - out_recon_loss: 0.0240 - out_caps_acc: 0.8881 - val_loss: 0.4062 - val_out_caps_loss: 0.1858 - val_out_recon_loss: 0.0220 - val_out_caps_acc: 0.7552
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) (None, 32, 32, 3) 0
__________________________________________________________________________________________________
conv1 (Conv2D) (None, 32, 32, 256) 62464 input_1[0][0]
__________________________________________________________________________________________________
batch_normalization_1 (BatchNor (None, 32, 32, 256) 1024 conv1[0][0]
__________________________________________________________________________________________________
conv2 (Conv2D) (None, 32, 32, 256) 5308672 batch_normalization_1[0][0]
__________________________________________________________________________________________________
batch_normalization_2 (BatchNor (None, 32, 32, 256) 1024 conv2[0][0]
__________________________________________________________________________________________________
conv3 (Conv2D) (None, 24, 24, 256) 5308672 batch_normalization_2[0][0]
__________________________________________________________________________________________________
batch_normalization_3 (BatchNor (None, 24, 24, 256) 1024 conv3[0][0]
__________________________________________________________________________________________________
conv2d_1 (Conv2D) (None, 8, 8, 256) 5308672 batch_normalization_3[0][0]
__________________________________________________________________________________________________
batch_normalization_4 (BatchNor (None, 8, 8, 256) 1024 conv2d_1[0][0]
__________________________________________________________________________________________________
reshape_1 (Reshape) (None, 2048, 8) 0 batch_normalization_4[0][0]
__________________________________________________________________________________________________
lambda_1 (Lambda) (None, 2048, 8) 0 reshape_1[0][0]
__________________________________________________________________________________________________
digitcaps (CapsuleLayer) (None, 10, 16) 2641920 lambda_1[0][0]
__________________________________________________________________________________________________
input_2 (InputLayer) (None, 10) 0
__________________________________________________________________________________________________
mask_1 (Mask) (None, 16) 0 digitcaps[0][0]
input_2[0][0]
__________________________________________________________________________________________________
dense_1 (Dense) (None, 512) 8704 mask_1[0][0]
__________________________________________________________________________________________________
dropout_1 (Dropout) (None, 512) 0 dense_1[0][0]
__________________________________________________________________________________________________
dense_2 (Dense) (None, 1024) 525312 dropout_1[0][0]
__________________________________________________________________________________________________
dropout_2 (Dropout) (None, 1024) 0 dense_2[0][0]
__________________________________________________________________________________________________
dense_3 (Dense) (None, 3072) 3148800 dropout_2[0][0]
__________________________________________________________________________________________________
out_caps (Length) (None, 10) 0 digitcaps[0][0]
__________________________________________________________________________________________________
out_recon (Reshape) (None, 32, 32, 3) 0 dense_3[0][0]
==================================================================================================
Total params: 22,317,312
Trainable params: 22,294,784
Non-trainable params: 22,528
__________________________________________________________________________________________________
まとめ
・Autoencoderの画像は中間層の次元を上げると美しくなる
・CapsNetについても、中間層の次元を操作して精度と生成された画像の変化を見たが、Cifar10では綺麗な画像は得られなかった。
・これは、Mask()層の次元が小さいためであり、何らかの改善をしないと綺麗な画像は得られないことが判明した
課題
・Autoencoderの知見を活かしてカテゴライズと綺麗な画像生成ができるマルチタスク型のClassifier_Autoencoderを実現できるはずである
・CapsuleLayerとMask()のような、入力画像の空間的特徴を蓄積できる高機能でさらに軽くて高次元な中間層は構築できるか