前回の記事でこんなことできないのかと絶望したWeightsパラメータの転移学習ができました♬
今回はそれだけだけど、ちょっと苦労したのと、学習時間の大幅短縮になる、そして何より高精度検出器作成の可能性が大いに期待できるので紹介することとする。
Kerasにおける層毎転移学習
そもそも、ググってみると。。。あるじゃないか。。。
【参考】
①Neural Style Transfer: Prismaの背景技術を解説する
②loading weights of a sequential model into a graph model #1728
①は内容も面白いが、今回はとにかくWeightsパラメータの転移学習。
実は、転移学習に関してはほぼ同じ記述。。。つまり以下のようなコード
# get the symbolic outputs of each "key" layer (we gave them unique names).
layer_dict = dict([(layer.name, layer) for layer in model.layers])
# load the weights
import h5py
weights_path = 'vgg16_weights.h5'
f = h5py.File(weights_path)
for k in range(f.attrs['nb_layers']):
if k >= len(model.layers):
# we don't look at the last (fully-connected) layers in the savefile
break
g = f['layer_{}'.format(k)]
weights = [g['param_{}'.format(p)] for p in range(g.attrs['nb_params'])]
model.layers[k].set_weights(weights)
f.close()
print('Model loaded.')
まあ、まったく同じコードなので文句ないでしょ。
って感じですが、実はこれ今回のように入力でVGG16の転移学習しているとこのままでは通りません。
しかし、参考の②の下の方を見ていくと、。。ありました!
f = h5py.File(weights_path4)
f = f['model_weights']
layer_names = [n.decode('utf8') for n in f.attrs['layer_names']]
g = f[layer_names[0]]
weight_names = [n.decode('utf8') for n in g.attrs['weight_names']]
weight_values = [g[weight_name] for weight_name in weight_names]
としておいて、
give you the weight_values in layer_name (0 here) and you can set it to your layers weight with model.layers[k].set_weights(weights)
ということで、できるはずだけど、これは一層のWeights転移学習なので、必要な層の転移学習をする必要があります。
因みに、Keras_Documentationには以下の記載になっています。
・model.set_weights(weights): Numpy 配列のリストからモデルの重みの値をセットします.リスト中のNumpy 配列のshapeはget_weights()で得られるリスト中のNumpy配列のshapeと同じ必要があります.
確かに書いてあるようですが、。。
で、以下のようなコードを書きました。
weights_path = 'weights_SSD300.hdf5'
f = h5py.File(weights_path,mode="r")
layer_names = [n.decode('utf8') for n in f.attrs['layer_names']]
for k in range(11,66):
print(k," ",layer_names[k],model.layers[k-8])
for k in range(12,len(layer_names)):
# k=12
print(k,layer_names[k])
g = f[layer_names[k]]
print(g)
weight_names = [n.decode('utf8') for n in g.attrs['weight_names']]
weight_values = [g[weight_name] for weight_name in weight_names]
print(weight_names)
print(model.layers[k-8])
model.layers[k-8].set_weights(weight_values)
f.close()
print('Model loaded.')
いろいろ、無駄コード入っていますが、履歴として残しました。つまり、ここで普通に1からとか転移学習しようとしてもできません。
結局、読み込んでいるWeightsの順番と転移したいネットワークの層の対応を取って、model.layers[k].set_weights(weight_values)する必要があります。
物体検出SSDに応用する
ということで、InceptionV3の場合は上記のコードで転移学習できました。
とはいえ、なかなか物体検出の精度が出ないので、以下のとおり、
一度VGG16にして、学習の仕方を学ぶこととしました。
まず、以下のように全58層に対して、2から4層以外を固定にして回すと。。。
for layer in model.layers[4:58]:
layer.trainable = False
for layer in model.layers[0:2]:
layer.trainable = False
for layer in model.layers[2:4]:
layer.trainable = True
これはもともとのFeatureExtractorというモデル(VGG16のBlock3までの層)は、Imagenetの学習済パラメータを読込んでいるので、それでよしとするという考えからです。
また、検出部も同じく学習済パラメータを読み込んでいるのでそれを使う。
つまり、そこを結合する2から4層だけ学習するというこです。
1回目に、30epochでweights.1.81-0.511.hdf5が得られました。
つまり、val_loss=1.81 val_acc=51.1%です。
そして、まだまだval_accが上がりそうなので、学習継続します。
しかし、やはりこれだけ固定すると、結局5回回したところで、
weights.1.88-0.545.hdf5が得られ、以降は飽和しました。
今回は、これで良しとしました。
ちなみに、学習は以下のような感じで推移しています。
4009/4009 [==============================] - 791s 197ms/step - loss: 1.5340 - acc: 0.5068 - val_loss: 1.8873 - val_acc: 0.5019
Epoch 00001: saving model to ./checkpoints/weights.1.89-0.502.hdf5
Epoch 2/30
4009/4009 [==============================] - 787s 196ms/step - loss: 1.4756 - acc: 0.5054 - val_loss: 1.8788 - val_acc: 0.5040
Epoch 00002: saving model to ./checkpoints/weights.1.88-0.504.hdf5
Epoch 3/30
4009/4009 [==============================] - 787s 196ms/step - loss: 1.3953 - acc: 0.5100 - val_loss: 1.8512 - val_acc: 0.5034
Epoch 00003: saving model to ./checkpoints/weights.1.85-0.503.hdf5
Epoch 4/30
4009/4009 [==============================] - 785s 196ms/step - loss: 1.3253 - acc: 0.5133 - val_loss: 1.8578 - val_acc: 0.5180
Epoch 00004: saving model to ./checkpoints/weights.1.86-0.518.hdf5
Epoch 5/30
4009/4009 [==============================] - 786s 196ms/step - loss: 1.2671 - acc: 0.5161 - val_loss: 1.8311 - val_acc: 0.5225
Epoch 00005: saving model to ./checkpoints/weights.1.83-0.522.hdf5
Epoch 6/30
4009/4009 [==============================] - 787s 196ms/step - loss: 1.2183 - acc: 0.5195 - val_loss: 1.8796 - val_acc: 0.5451
Epoch 00006: saving model to ./checkpoints/weights.1.88-0.545.hdf5
つまり、785s/epoch程度の時間がかかっています。一方、全層動かした場合の学習では、1300s/epoch程度なので一定の効果はありそうです。
しかし、このあと、全層動かしてフィッティングすると、15epoch後に
Epoch 15/30
4009/4009 [==============================] - 1294s 323ms/step - loss: 0.1490 - acc: 0.5871 - val_loss: 4.5035 - val_acc: 0.5963
Epoch 00015: saving model to ./checkpoints/weights.4.50-0.596.hdf5
になりました。そして、loss=0.1490,acc=0.5871, val_acc=0.596と良くなりましたが、val_loss=4.5035と悪化しています。これは、SSD特有な過学習であることを示しているようです。
また、VGG16の転移学習+検出部(weightsSSD300.hdf5)を利用して、全層固定の場合は、
Epoch 1/30
4009/4009 [==============================] - 731s 182ms/step - loss: 7.8363 - acc: 0.3570 - val_loss: 7.8457 - val_acc: 0.3526
Epoch 00001: saving model to ./checkpoints/weights.7.85-0.353.hdf5
。。。になりました。
一方、他のモデルはどうなのか。。。
例えば、InceptionV3だとあまりいい結果が得られません。
まず、全層固定では、
loss=9.51
acc=0.826
となり、accは非常に高いものの、lossが低くまったく検出できません。
そして、認識部分4層までをフィッティングし直すと、いきなり
acc=0.3台に落ちてしまい、フィッティングし直しになってしまいます。
Epoch 1/30
4008/4009 [============================>.] - ETA: 0s - loss: 4.6079 - acc: 0.3273Epoch 00001: saving model to ./checkpoints/weights.3.97-0.328.hdf5
4009/4009 [==============================] - 681s 170ms/step - loss: 4.6075 - acc: 0.3273 - val_loss: 3.9711 - val_acc: 0.3279
さらに、21層までをフィッティングすると、さらに悪化というか、ほとんど全層フィッティングと同じ程度のパラメータ数になってしまい、かつaccも悪化しました。
Total params: 28,562,521
Trainable params: 25,409,184
Non-trainable params: 3,153,337
Epoch 1/30
4008/4009 [============================>.] - ETA: 0s - loss: 3.8723 - acc: 0.1888Epoch 00001: saving model to ./checkpoints/weights.3.43-0.226.hdf5
4009/4009 [==============================] - 878s 219ms/step - loss: 3.8719 - acc: 0.1888 - val_loss: 3.4319 - val_acc: 0.2259
これは、やはり物体認識部分の一部しか利用していないことが悪さをしているといえると思います。つまり、まともな物体検出器を作るにはそのモデルにあったネットワーク設計が必要なのだろうと思います。
学習済SSD300のWeightsの入手
最初の記事のKerasサイトから入手できます。
【参考】
cory8249/ssd_keras
結果
上記VGG16の物体検出(weights.1.88-0.545.hdf5)は以下のとおりになりました。
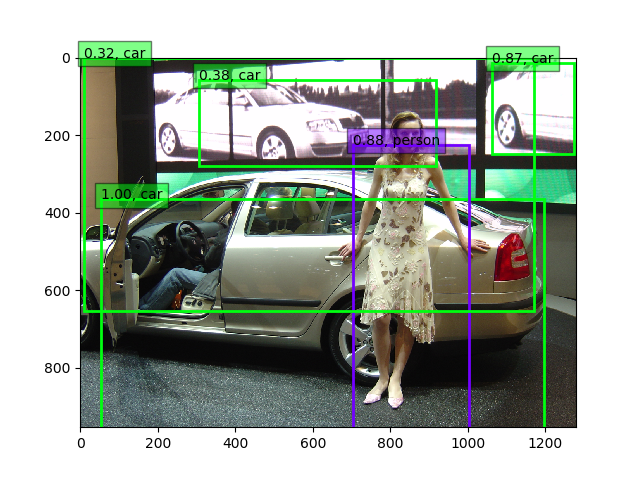
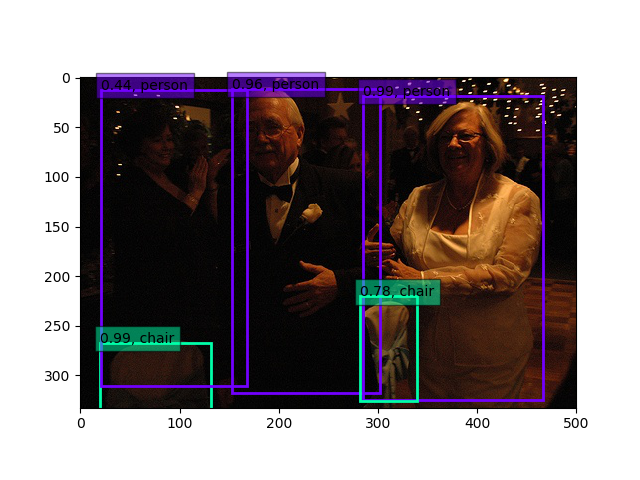
30epoch固定+全層15epoch後(weights.4.50-0.596.hdf5)
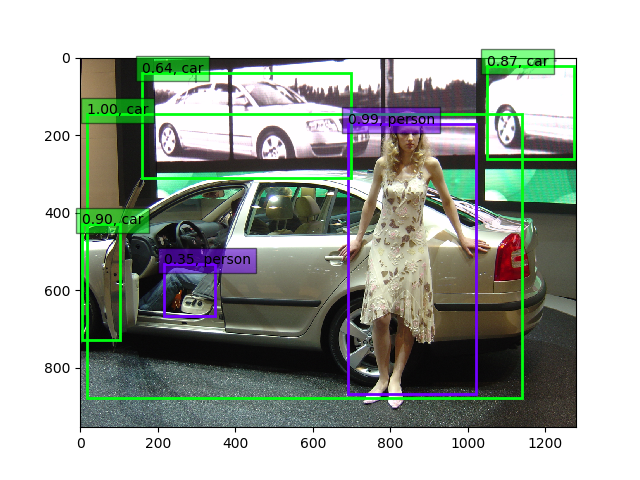
この車に乗っている人を一連の検出の中で、初めて認識出来ました‼
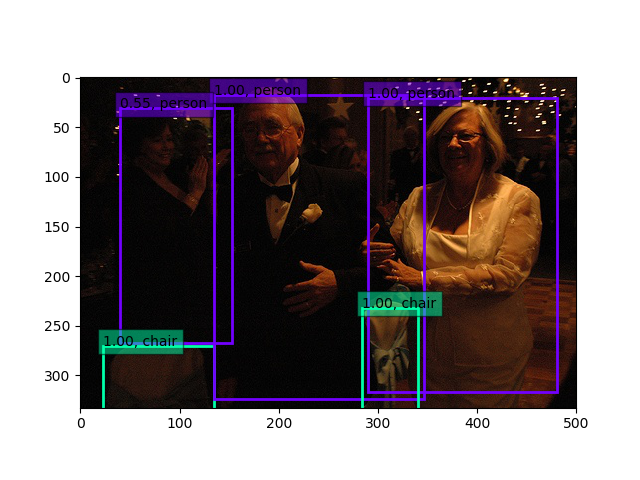
こちらも精度が上がっているのがわかります。
まとめ
・入力層にPreTrainなモデルを利用した転移学習の場合も、全層に対してWeightsの転移学習ができた。
・たとえ転移学習したとしても、検出のlossは低く、再学習が必要である。
・再学習はネットワークモデルが異なれば、それなりのコストがかかりそうであり、今回はVGG16モデルの検出部の転移学習であったために、VGG16以外のモデルでは全層学習が必要なほど効果は低かった。
・課題としてlossやaccの部分が理解できていないので、学習方法を確立する上でもキャッチアップする必要がある。
・VGG16ライクなモデルに適用する。