前回の記事でVGG16ベースのPreTrained_SSD300を作成した。
そこでは、単に世にあるVGG16ライクなSSD300モデルの前段にVGG16をInput_layerとして採用した。
ここでは、その入力を最適化するとともにその学習手法を考える。
また、VGG16のみでなく、他のPreTrainedなモデルを利用して、同様なSSD300モデルを作成しようと思う。
あくまでも仮説だが、メリットは少なくとも以下の二つがあると思う。
①大量なカテゴリーに対する物体認識としての精度がある程度保証される
②学習時間を大幅に削減できる可能性がある
少なくとも最初に物体認識でPre-Trainingする必要が無い
ということで、まず全体的な構造を見てみよう
PreTrained_SSD300の構造
1. SSDモデルの入力部分のコードは以下のとおり
# Block 1
input_shape = (input_shape[1], input_shape[0], 3)
input = Input(input_shape)
vgg16 = VGG16(input_shape=input_shape, include_top=False, weights='imagenet')
FeatureExtractor = Model(inputs=vgg16.input, outputs=vgg16.get_layer('block3_pool').output)
pool3 = FeatureExtractor(input)
# Block 4
conv4_1 = Conv2D(512, (3, 3),activation='relu',padding='same',name='conv4_1')(pool3)
2. この部分のmodel.summary()は以下のとおり
Layer (type) Output Shape Param # Connected to
=============================================================================================
input_2 (InputLayer) (None, 300, 300, 3) 0
_____________________________________________________________________________________________
model_1 (Model) multiple 1735488 input_2[0][0]
_____________________________________________________________________________________________
conv4_1 (Conv2D) (None, 37, 37, 512) 1180160 model_1[1][0]
_____________________________________________________________________________________________
3. 普通のSSD300の対応するmodel.summary()は以下のとおり
Layer (type) Output Shape Param # Connected to
=============================================================================================
input_1 (InputLayer) (None, 300, 300, 3) 0
_____________________________________________________________________________________________
conv1_1 (Conv2D) (None, 300, 300, 64) 1792 input_1[0][0]
_____________________________________________________________________________________________
conv1_2 (Conv2D) (None, 300, 300, 64) 36928 conv1_1[0][0]
_____________________________________________________________________________________________
pool1 (MaxPooling2D) (None, 150, 150, 64) 0 conv1_2[0][0]
_____________________________________________________________________________________________
conv2_1 (Conv2D) (None, 150, 150, 128 73856 pool1[0][0]
____________________________________________________________________________________________
conv2_2 (Conv2D) (None, 150, 150, 128 147584 conv2_1[0][0]
_____________________________________________________________________________________________
pool2 (MaxPooling2D) (None, 75, 75, 128) 0 conv2_2[0][0]
_____________________________________________________________________________________________
conv3_1 (Conv2D) (None, 75, 75, 256) 295168 pool2[0][0]
_____________________________________________________________________________________________
conv3_2 (Conv2D) (None, 75, 75, 256) 590080 conv3_1[0][0]
_____________________________________________________________________________________________
conv3_3 (Conv2D) (None, 75, 75, 256) 590080 conv3_2[0][0]
_____________________________________________________________________________________________
pool3 (MaxPooling2D) (None, 38, 38, 256) 0 conv3_3[0][0]
_____________________________________________________________________________________________
conv4_1 (Conv2D) (None, 38, 38, 512) 1180160 pool3[0][0]
_____________________________________________________________________________________________
4.VGG16.pyの構造と設計的考察
一つ目は、
conv4_1 (Conv2D) (None, 37, 37, 512) 1180160 model_1[1][0]
conv4_1 (Conv2D) (None, 38, 38, 512) 1180160 pool3[0][0]
の比較である。
わずかであるが、Tensorのサイズが異なる。PreTrainなモデルでは(None, 37, 37, 512)であり、通常のものは (None, 38, 38, 512)である。
どうせなら、ここは一致させておいた方が良い。
ということで、ここはあの1個まで調整できるUpsampling?であるDeconvolutionを使おう。
そのコードは以下のようなものになるが、次元はどうしようかな?
つまり、滑らかにつなげるなら254だし、元々のVGG16モデルを考えると512でも良さそう。
※こういうのは両方やってみていい方をとるべきなんだろね
conv4_0 = Conv2DTranspose(256, 2, 2, activation='relu', border_mode='valid', name='conv4_0')(pool3)
二つ目は以下のリンクを見てもらうと
FeatureExtractor = Model(inputs=vgg16.input, outputs=vgg16.get_layer('block3_pool').output)
この'block3_pool'の意味が分かると思う。この場合、この部分までのLayerを再利用している。それ以降のblock4,block5はSSDのモデルと被っているのでこの場合は、使っていない。
逆にいうと、物体認識としては半分しか使っていないから本来精度は出ない。
だから、実験的な意味ではblock5までしっかり使おうよというのがあると思う。
【参考】
keras / keras / applications / vgg16.py
三つめは、とにかく
conv4_1 (Conv2D) (None, 38, 38, 512) 1180160 model_1[1][0]
になりさえすれば、上はどんなモデルが乗っていてもとりあえず動くということです。
そして、できればVGG16のようにFeature Blockの一部をDetection部分に入れて準備するのがいいのでしょう。
ここでは、複雑なこと考えたくないので(時間がかかりすぎるので)簡単に上に乗せるだけにしようと思います。
簡単な4つのモデル
ここでは以下4つのモデルを作成してみました。
※以下はいずれも物体認識でFineTuningの記事とコーディングしたモデルです。
今回は上記の考察を考慮して、以下のようなモデルになると思います。
4つのモデルの変更箇所を以下に記載します。
ssd300VGG16_alt.py
# Block 1
input_shape = (input_shape[1], input_shape[0], 3)
input = Input(input_shape)
vgg16 = VGG16(input_shape=input_shape, include_top=False, weights='imagenet')
FeatureExtractor = Model(inputs=vgg16.input, outputs=vgg16.get_layer('block3_pool').output)
pool3 = FeatureExtractor(input)
conv4_0 = Conv2DTranspose(512, (2, 2), name='conv4_0', activation='relu', border_mode='valid')(pool3)
vgg19 = VGG19(input_shape=input_shape, include_top=False, weights='imagenet')
FeatureExtractor = Model(inputs=vgg19.input, outputs=vgg19.get_layer('block3_pool').output)
resnet50 = ResNet50(input_shape=input_shape,include_top=False, weights='imagenet')
FeatureExtractor = Model(inputs=resnet50.input, outputs=resnet50.get_layer('add_7').output)
ssd300InceptionV3_alt.py
上記と比較すると、出力が異なるのでDecovolutionが異なりますが、基本はほぼ同じです。
inceptionV3 = InceptionV3(input_shape=input_shape, include_top=False, weights='imagenet')
FeatureExtractor = Model(inputs=inceptionV3.input, outputs=inceptionV3.get_layer('mixed2').output)
pool3 = FeatureExtractor(input)
conv4_0 = Conv2DTranspose(512, (4, 4), name='conv4_inceptionv3', activation='relu', border_mode='valid')(pool3) #for inceptionV3
学習
・物体認識部分はPreTrainだから、再学習は必要なく物体認識精度が保証される
「再学習は必要ない」は、どうも思惑が外れた
つまり、PreTrain部分を固定して学習しようとすると、非常に小さなaccからスタートして一向に上がってこないという現象が発生。その結果、やはり全部を学習するということとした。
それでも、PreTrain部分が一定のパラメータになっているので、学習は進みやすいように感じる。
比較のために、SSD300_smallなるもの:これは以前「ぶっちゃけ変なモデル。。。^^;」でベースにした、比較的小さいけど、検出精度の高いVGG16ライクなモデルを使って学習してみた。
※これ、実はオリジナルのSSD300と比較するとconv3_3が無いことと、MaxPoolingをAveragePoolingを使っていること、そしてBatchNormalizationを使っていることがことなるが、ほぼ似たような構成だとわかる
ssd300small_alt.py
「物体認識精度が保証される」も、どうも思惑が外れたようだ
よく見ると、PreTrainで利用しているネットワークが案外小さい部分しか使っていない。
これでは、全体としてパラメータフィッティングされているのだから、保証というところまでは言えないようだ。
もちろん、学習当初の発散みたいな現象はあまり(固定すると発生した)なかったが。
・学習時間を大幅に削減できる可能性
上の書いたように、ほとんどPreTrainなWeightsの効果が今一つということで、結局全体を学習した方が精度もよく、早いという結論。
つまり、パラメータフィッティングはしないが、結局Tensorの計算を実施する必要がある。まあ、一応バックプロパゲーションの計算はその部分はしていないはずだが、それでも20%程度の削減にしかなっていない。(1060で1200s⇒1000s位)
実は物体検出のPGを大きく物体認識部と検出部と考えれると、実はあるモデルで物体検出全体のパラメータが決まっていて、かつ入力部分の物体認識部をPreTrainなモデルに変更した場合、やり方によっては全くTraining無しに正しく物体検出してくれる可能性が大いにあると思うが、今のところそのアイディアを実現していない。
※Layer毎にパラメータを反映するということができるといいなぁ~
※model.load_weights('weights_SSD300.hdf5', by_name=True)でやれるのかと思ったら、Weights数が異なると怒られて、已矣哉!
結果
合計5つのモデルのパラメータフィッティングを実施しているが、一番いいのがVGG19でvaccで55%程度のところ、そのほかはやっと45%に到達するかというところでこれはほんとに時間がかかる。
VGG19はよく見るとBlock3までのところは、VGG16と変わらないので、実際フィッティングできたとしてもあまり面白くない。
ということで、ここではInceptionV3とsmallの結果を示したいと思う。
まず、smallから、これはVGG16と似ていると思いましたが、45%程度でaccが飽和してしまって、上がりません。Base_IrなどのパラメータやそもそもAdamでなくてSGDとかでやれば変わるかもしれませんが、現状は以下の通りです。

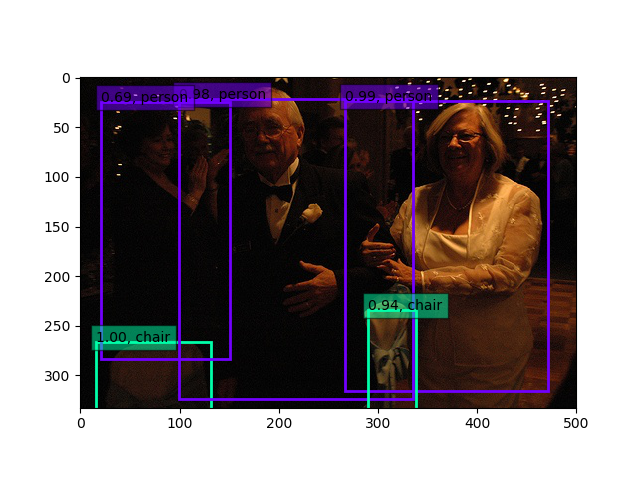
そこから、30epoch(10時間位)回すとどうにかこうにか(もうほとんど上がりませんが)50.5%になりました。そして、上記よりは少しマシかな??
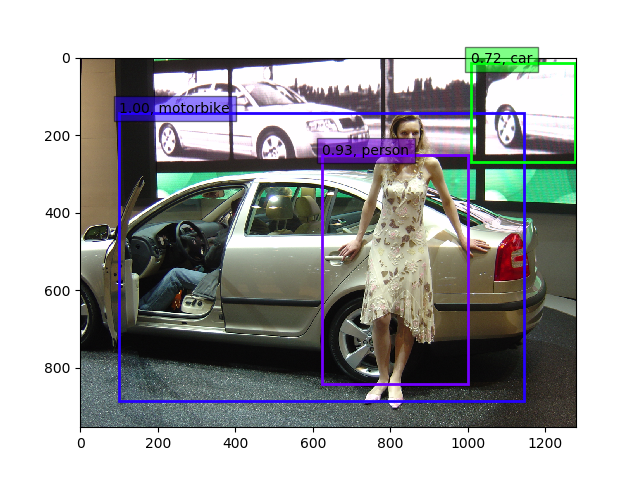
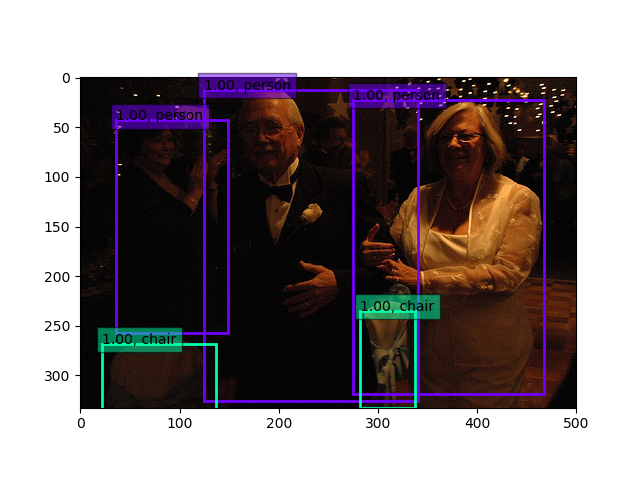
一方、InceptionV3では50%超えたところ(51%辺り)で、足踏みしていますが、もう少し上がるような気がしますが、12時間以上回したので、このあたりで一度上げておきます。
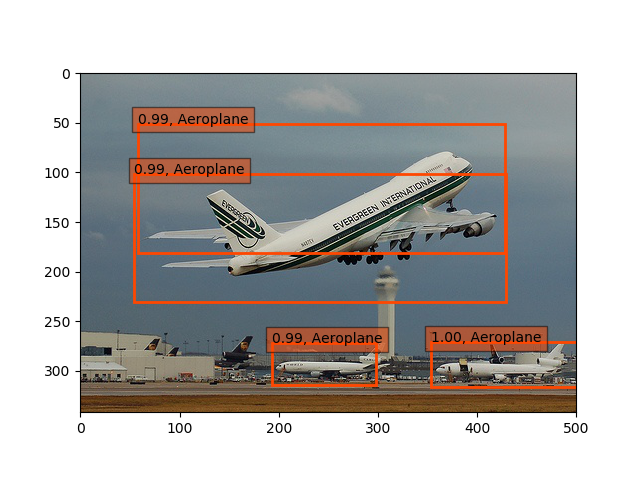
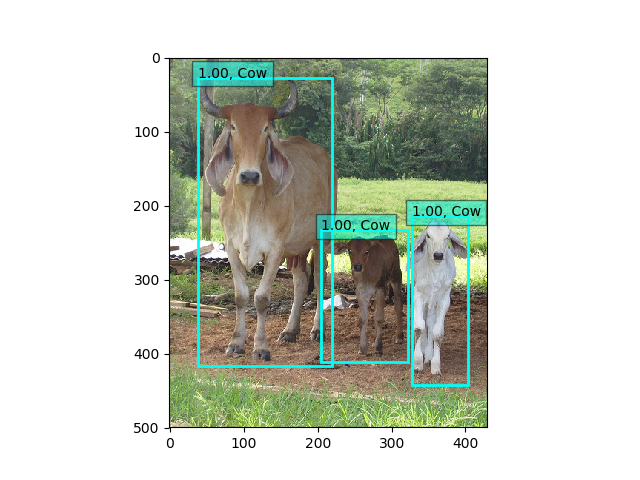

こちらもさらに35epoch(10時間位)回すと、64%超えしましたが、物体検出は以下のようにまだまだです。
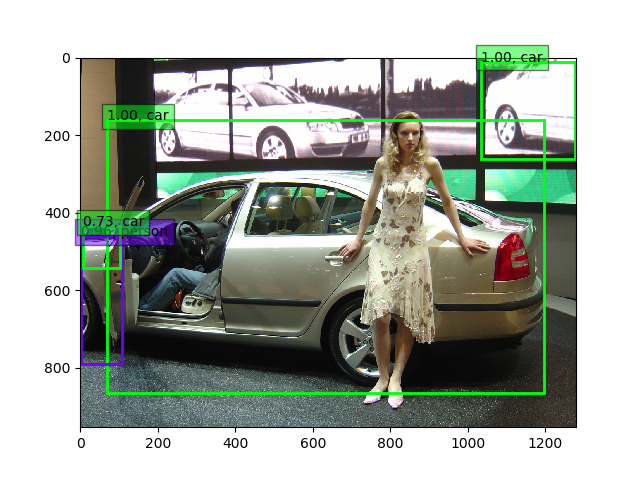
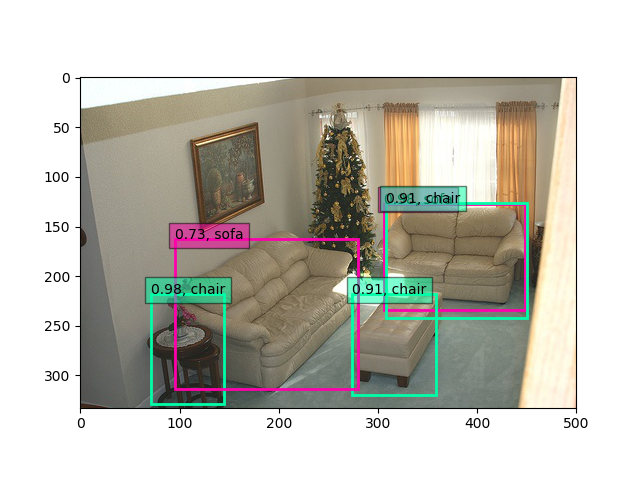
まとめ
・まだまだ精度はいまいちだが、5つのモデルについてPretrainなモデルや既知のネットワークを利用したSSD300モデルを構築した。
・学習の仕方(既知のWeightの使い方)やネットワークの構築はまだまだ改良の余地がありそうである
・mAP vs fptについては計測したいと思う