転移学習やFine-Tuningでは、比較的少ないデータ数でもカテゴライズできるという神話がある。
しかし、どの程度のデータ数ならある程度信頼できる識別器ができるのかというのは、なかなか記載がない。
前回の記事
「AKB2017総選挙ランキング上位者のFine-Tuning その2~顔抽出と少数データ」
https://qiita.com/MuAuan/items/4ab6c3d9c5ad6f5c98cc
で見たように、一応識別器はできるが、それはどこまでのデータに適用可能なのかは、正直よくわからない。
実験的な試行検証
ということで、ここでは以下のような実験的な試行を実施して、検証したいと思う。
①前回は全体データ数を減少させていったが、今回は同数データに対して、TrainデータとTestデータの割合を変更して、一致率の変化を見る
②Trainデータはどこまで減らせるのかをみるため、元データ数を可能な限り小さくして学習の収束性を見る
※ただし、Trainデータ5個以下のデータは、Augmentationして8倍に増やした
結果
①TrainデータとTestデータの比率を変える
結果は、立ち上がりはTrainデータの割合が減少すると徐々に遅くなるのは、前回と同じだが、test_accはかなり良い結果が得られ、【Train50%、Test50%】でも70%程度の精度が得られた。そして、【Train10%、Test90%】でさえ40%弱の精度が得られている。これは、ばらつきはあるが、Trainデータがそれぞれ10個程度あれば、40%程度の識別器ができることになる。
【注意】データは、前回の記事と異なり(本来同じデータでやりたいが、残念)、クレンジングされたカテゴリ毎に100個位から120個位までばらつきがあるデータを利用
【Train90%、Test10%】ResNet50【90層固定】
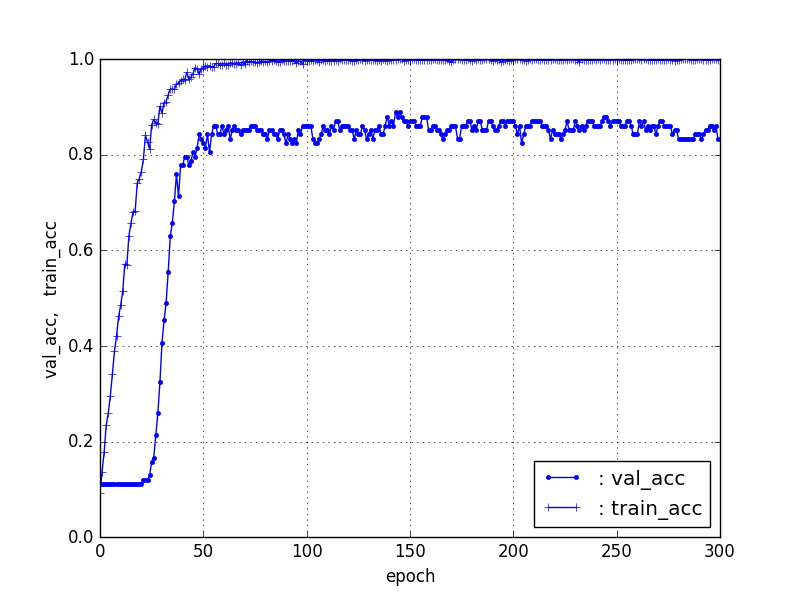
【Train80%、Test20%】ResNet50【90層固定】
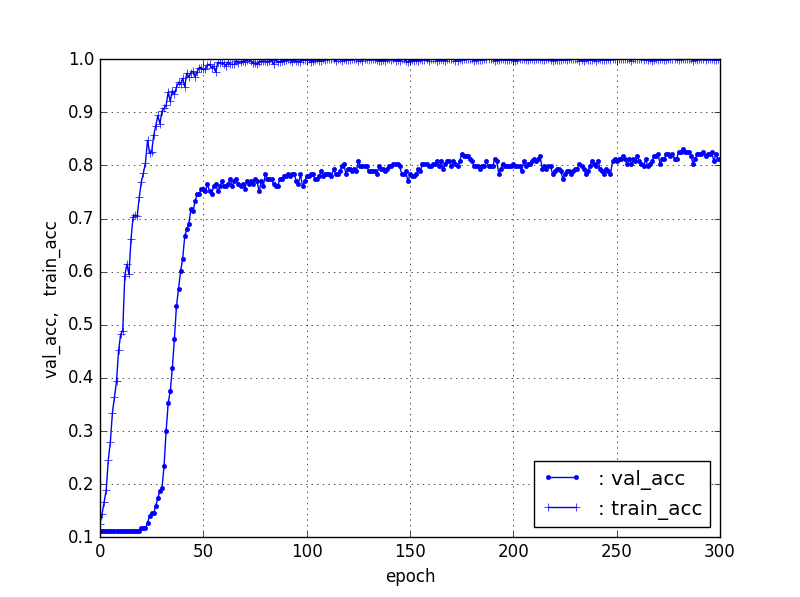
【Train50%、Test50%】ResNet50【90層固定】
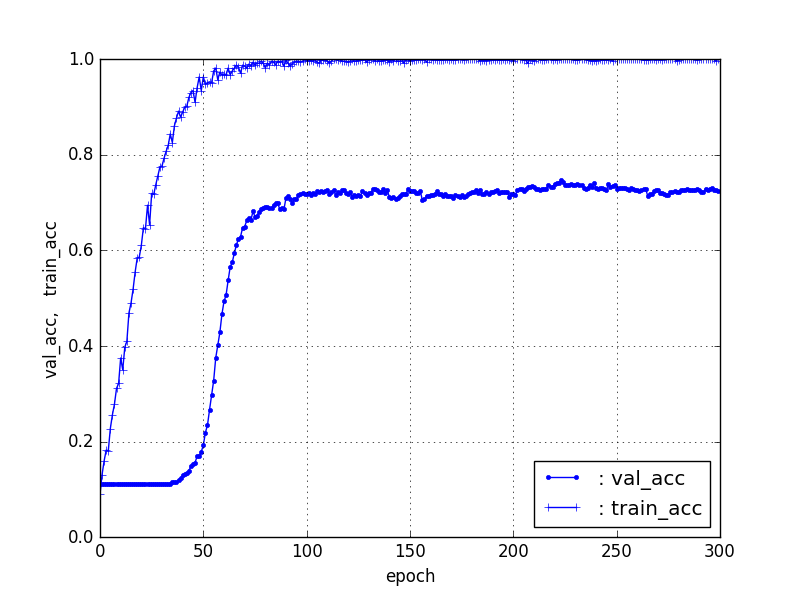
【Train20%、Test80%】ResNet50【90層固定】
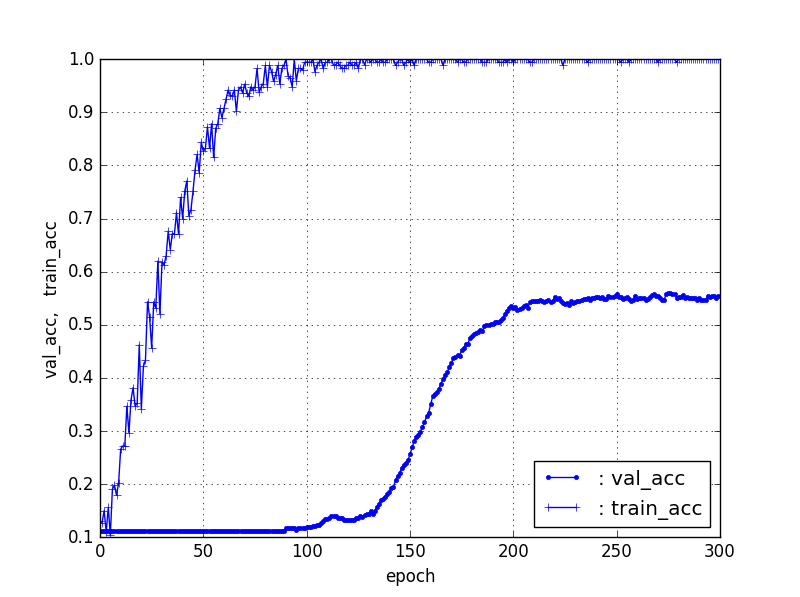
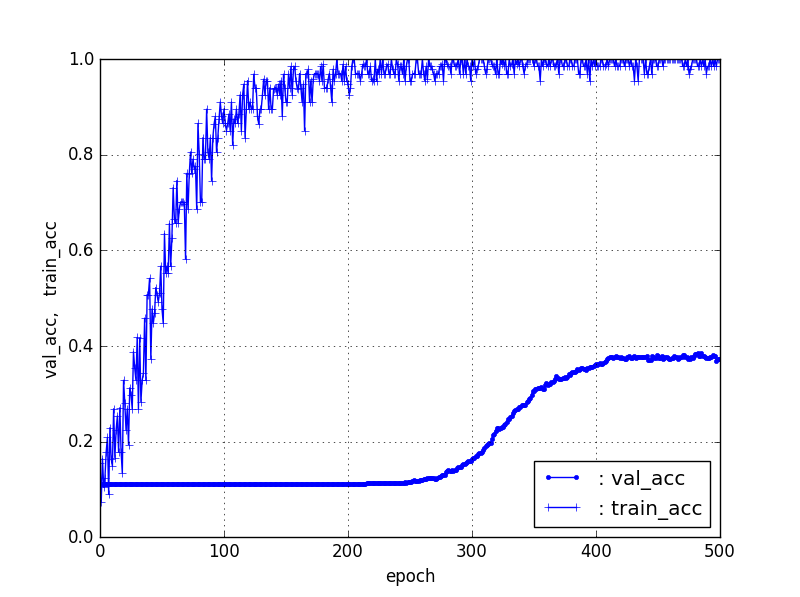
【Train10%、Test90%】ResNet50【90層固定】
| 条件 | val_acc | 立ち上がり/epoch |
|---|---|---|
| 90%, 10% | 85% | 20 |
| 80%, 20% | 82% | 20 |
| 50%, 50% | 73% | 35 |
| 20%, 80% | 55% | 85 |
| 10%, 90% | 37% | 220 |
②Trainデータはどこまで減らせるのか?
上記で見れば、普通の精度のいい識別器は少なくともTrainデータ割合70%程度でフィッティングすればいい気がするが、実際50%のデータでも70%の精度が出ており、かなり汎用性は高いと評価できる。
そして、10%の結果は、識別器が学習するという意味では、10個程度のデータがあれば、ある意味ちゃんとした識別器が作成できるということである。
さらに、Trainデータを削減しても収束するのか?
10%というのは10個程度ということを示すので、以下半分の5個、4個、3個、2個、そして元データ1個で識別器が収束するのか?そして、それでどこまで識別できるのかを見てみた。
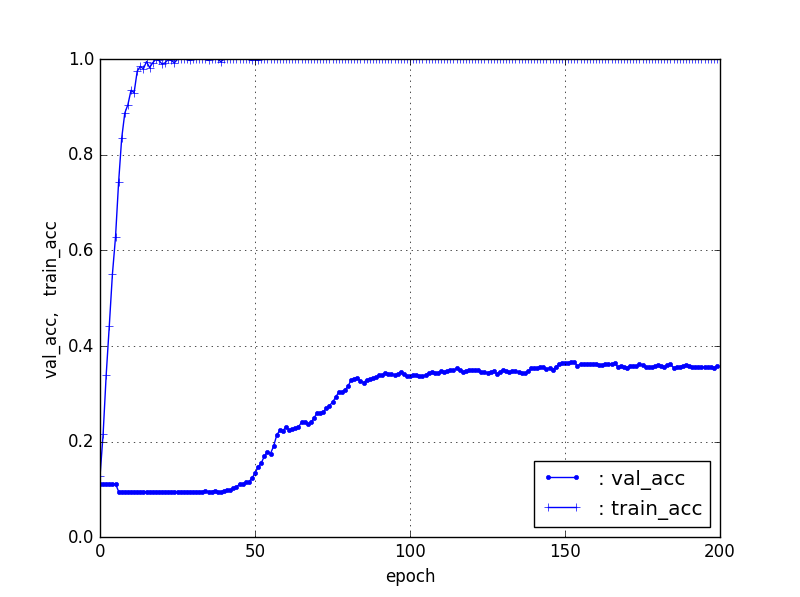
【Train5個、Test残り】ResNet50【90層固定】
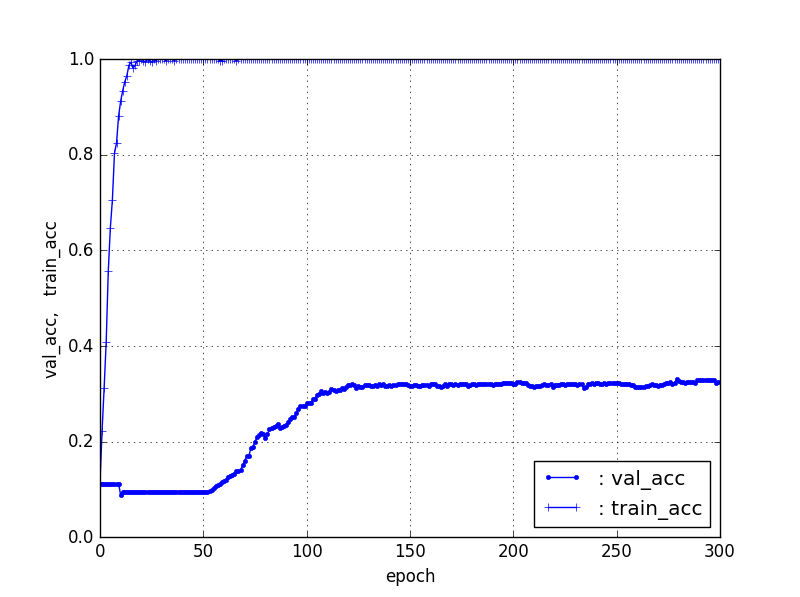
【Train4個、Test残り】ResNet50【90層固定】
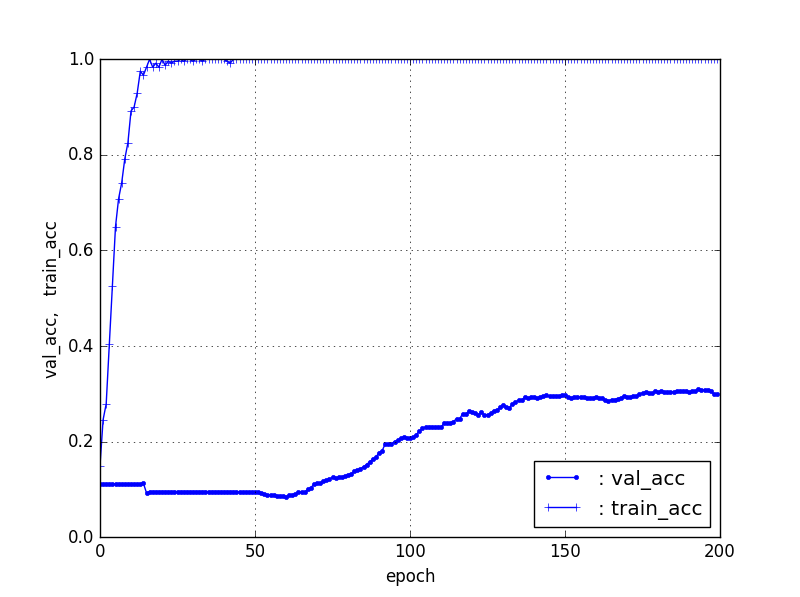
【Train3個、Test残り】ResNet50【90層固定】
【Train2個、Test残り】ResNet50【90層固定】
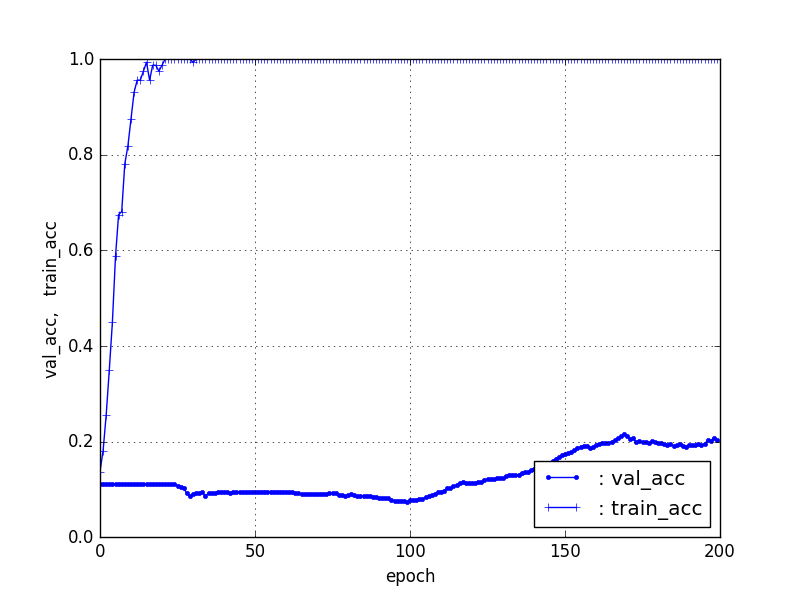
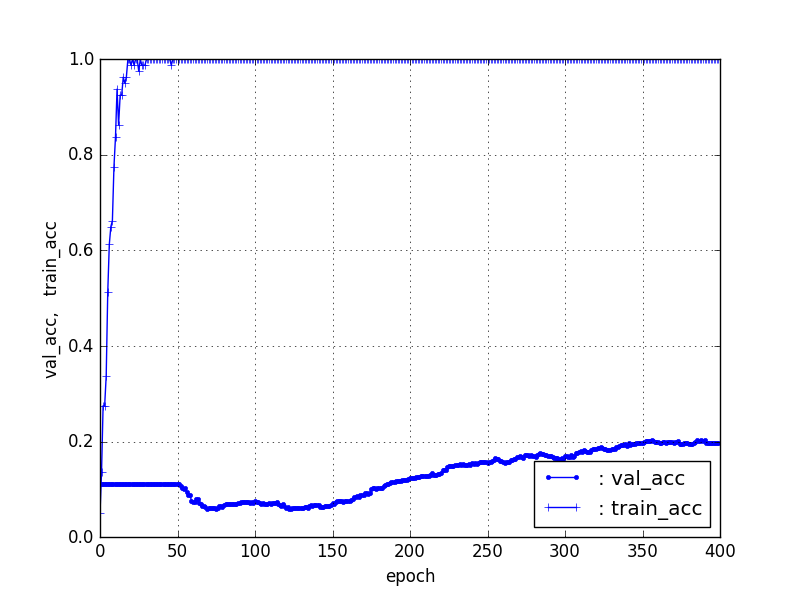
【Train1個、Test残り】ResNet50【90層固定】
| 条件 | val_acc | 立ち上がり/epoch |
|---|---|---|
| 5, res. | 37% | 30 |
| 4, res. | 34% | 52 |
| 3, res. | 32% | 60 |
| 2, res. | 23% | 95 |
| 1, res. | 22% | 150 |
上記の結果は、ある意味驚きである。特に1個のデータは立ち上がりこそずいぶん遅いし、だらだらであるが、train_acc20%程度つまり、各カテゴリ20個程度は識別できている。また、5個程度のTrainデータは35%程度の識別率でこれでも分野によっては、或いは当初データクレンジングするには有用な識別器になると思う。
もちろん少数データでの学習には過学習という問題は当然あるのだが、その影響を考慮すれば上記結果は予想以上の識別率だといえる。
上記の結果をグラフにすると以下のようになった。
5個以下のデータ数が小さいところではAugmentationを実施しており、ちょっと誤差もありそうだが、全体としてはほぼ一様な変化をしていると言える。
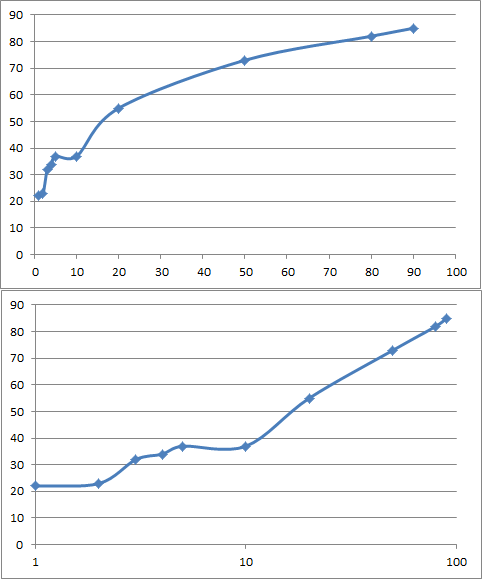
あまりにもきれいな直線に乗ったので、近似曲線
y = 21.324ln(x) - 10.761 , x>10
R² = 0.9963
y;Fitting_Ratio x;Fraction of Training data
まとめ
①データ割合が10-90%の範囲で、比較的簡単な関係があり、フィッティング率はデータ割合の対数に対してリニアな関係がある。
②データ割合を変更して、フィッティング率をみると、Trainデータ70%以上だと80%以上の十分な精度がえられた。
③Trainデータ50%でも70%程度の精度が得られ、十分なTestデータで検証されているので、ある意味汎用性のある識別器を作成できている。
④Trainデータは、1個でも8倍のAugmentationにより、それなりの識別器を作成できた。
【Augmentation】
画像の8倍水増しは以下のサイトより
「機械学習で乃木坂46を顏分類してみた」
http://blog.aidemy.net/entry/2017/12/17/214715
課題
過学習を考えたとき、Trainデータ1個でも、適切なAugmentationを実施すれば、さらに識別率を上げることができそうである。例えば最近のstarGANを利用すれば、笑顔や怒った顔、変顔など出力でき、かなり確実な精度向上を期待できそうである。
そもそも、データにいろいろな外部要因を付加して、バリエーションを持たせる技術というのを確立することは、今後のDeepLearningの発展が大量データ分析に依存している現状を打破する可能性があると考えられる。
【参考】
「Official PyTorch Implementation of StarGAN」
https://github.com/yunjey/StarGAN
「StarGANで顔イラストの表情変換」
https://qiita.com/mattya/items/e71ea1d203b110013753
以下は、ちょっと系統違うけど、少ないデータで識別器作っています。
「細胞種を機械学習で判別する!」
https://lp-tech.net/articles/e0mRJ