 第十夜は、ちょっと楽しいマルチタスク学習、すなわち方策ネットワークと価値ネットワークの同時学習について解説しようと思う。
第十夜は、ちょっと楽しいマルチタスク学習、すなわち方策ネットワークと価値ネットワークの同時学習について解説しようと思う。
解説したいこと
(1)方策ネットワークと価値ネットワークのマルチタスク学習
(2)マルチタスク学習する~コード説明
(3)収束状況を確認する~正規表現利用のログのグラフ出力
(1)方策ネットワークと価値ネットワークのマルチタスク学習
今回のマルチタスク学習で利用するネットワークは以下のとおりです。
from chainer import Chain
import chainer.functions as F
import chainer.links as L
from pydlshogi.common import *
ch = 192
fcl = 256
class PolicyValueNetwork(Chain):
def __init__(self):
super(PolicyValueNetwork, self).__init__()
with self.init_scope():
self.l1=L.Convolution2D(in_channels = 104, out_channels = ch, ksize = 3, pad = 1)
self.l2=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
self.l3=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
self.l4=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
self.l5=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
self.l6=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
self.l7=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
self.l8=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
self.l9=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
self.l10=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
self.l11=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
self.l12=L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1)
# policy network
self.l13=L.Convolution2D(in_channels = ch, out_channels = MOVE_DIRECTION_LABEL_NUM, ksize = 1, nobias = True)
self.l13_bias=L.Bias(shape=(9*9*MOVE_DIRECTION_LABEL_NUM))
# value network
self.l13_v=L.Convolution2D(in_channels = ch, out_channels = MOVE_DIRECTION_LABEL_NUM, ksize = 1)
self.l14_v=L.Linear(9*9*MOVE_DIRECTION_LABEL_NUM, fcl)
self.l15_v=L.Linear(fcl, 1)
def __call__(self, x):
h1 = F.relu(self.l1(x))
h2 = F.relu(self.l2(h1))
h3 = F.relu(self.l3(h2))
h4 = F.relu(self.l4(h3))
h5 = F.relu(self.l5(h4))
h6 = F.relu(self.l6(h5))
h7 = F.relu(self.l7(h6))
h8 = F.relu(self.l8(h7))
h9 = F.relu(self.l9(h8))
h10 = F.relu(self.l10(h9))
h11 = F.relu(self.l11(h10))
h12 = F.relu(self.l12(h11))
# policy network
h13 = self.l13(h12)
policy = self.l13_bias(F.reshape(h13, (-1, 9*9*MOVE_DIRECTION_LABEL_NUM)))
# value network
h13_v = F.relu(self.l13_v(h12))
h14_v = F.relu(self.l14_v(h13_v))
value = self.l15_v(h14_v)
return policy, value
これは、前回までで利用したpolicy.pyとvalue.pyを連結した構造になっています。
入力はxで出力は、return policy, valueになっています。
利用は、
y1, y2 = model(x)
というように使います。
(2)マルチタスク学習する~コード説明
学習のコードも前回までとほとんど同様です。
import numpy as np
import chainer
from chainer import cuda, Variable
from chainer import optimizers, serializers
import chainer.functions as F
from pydlshogi.common import *
from pydlshogi.network.policy_value import PolicyValueNetwork
from pydlshogi.features import *
from pydlshogi.read_kifu import *
import argparse
import random
import pickle
import os
import re
import logging
importするものも以前と同一です。
from pydlshogi.network.policy_value import PolicyValueNetwork```
だけ、上記policy_value.pyのマルチタスク学習のためのnetworkになっています。
```py
parser = argparse.ArgumentParser()
parser.add_argument('kifulist_train', type=str, help='train kifu list')
parser.add_argument('kifulist_test', type=str, help='test kifu list')
parser.add_argument('--batchsize', '-b', type=int, default=32, help='Number of positions in each mini-batch')
parser.add_argument('--test_batchsize', type=int, default=512, help='Number of positions in each test mini-batch')
parser.add_argument('--epoch', '-e', type=int, default=10, help='Number of epoch times')
parser.add_argument('--model', type=str, default='model/model_policy_value', help='model file name')
parser.add_argument('--state', type=str, default='model/state_policy_value', help='state file name')
parser.add_argument('--initmodel', '-m', default='', help='Initialize the model from given file')
parser.add_argument('--resume', '-r', default='', help='Resume the optimization from snapshot')
parser.add_argument('--log', default=None, help='log file path')
parser.add_argument('--lr', type=float, default=0.01, help='learning rate')
parser.add_argument('--eval_interval', '-i', type=int, default=1000, help='eval interval')
args = parser.parse_args()
パラメータ類も前回と同じです。
logging.basicConfig(format='%(asctime)s\t%(levelname)s\t%(message)s', datefmt='%Y/%m/%d %H:%M:%S', filename=args.log, level=logging.DEBUG)
また、ログ出力もほぼ同様です。
model = PolicyValueNetwork()
model.to_gpu()
optimizer = optimizers.SGD(lr=args.lr)
optimizer.setup(model)
model定義して、optimizerをセットします。
# Init/Resume
if args.initmodel:
logging.info('Load model from {}'.format(args.initmodel))
serializers.load_npz(args.initmodel, model)
if args.resume:
logging.info('Load optimizer state from {}'.format(args.resume))
serializers.load_npz(args.resume, optimizer)
保存してあるモデルをロードします。
logging.info('read kifu start')
# 保存済みのpickleファイルがある場合、pickleファイルを読み込む
# train date
train_pickle_filename = re.sub(r'\..*?$', '', args.kifulist_train) + '.pickle'
if os.path.exists(train_pickle_filename):
with open(train_pickle_filename, 'rb') as f:
positions_train = pickle.load(f)
logging.info('load train pickle')
else:
positions_train = read_kifu(args.kifulist_train)
# test data
test_pickle_filename = re.sub(r'\..*?$', '', args.kifulist_test) + '.pickle'
if os.path.exists(test_pickle_filename):
with open(test_pickle_filename, 'rb') as f:
positions_test = pickle.load(f)
logging.info('load test pickle')
else:
positions_test = read_kifu(args.kifulist_test)
棋譜データがpickleで保存されていれば、読み込みます。
# 保存済みのpickleがない場合、pickleファイルを保存する
if not os.path.exists(train_pickle_filename):
with open(train_pickle_filename, 'wb') as f:
pickle.dump(positions_train, f, pickle.HIGHEST_PROTOCOL)
logging.info('save train pickle')
if not os.path.exists(test_pickle_filename):
with open(test_pickle_filename, 'wb') as f:
pickle.dump(positions_test, f, pickle.HIGHEST_PROTOCOL)
logging.info('save test pickle')
logging.info('read kifu end')
読み込んだ棋譜をpickleデータで保存されていなけらば、保存します。
logging.info('train position num = {}'.format(len(positions_train)))
logging.info('test position num = {}'.format(len(positions_test)))
以下が出力されます。
line 2018/08/24 20:02:13 INFO train position num = 1892246
line 2018/08/24 20:02:13 INFO test position num = 208704
# mini batch
def mini_batch(positions, i, batchsize):
mini_batch_data = []
mini_batch_move = []
mini_batch_win = []
for b in range(batchsize):
features, move, win = make_features(positions[i + b])
mini_batch_data.append(features)
mini_batch_move.append(move)
mini_batch_win.append(win)
return (Variable(cuda.to_gpu(np.array(mini_batch_data, dtype=np.float32))),
Variable(cuda.to_gpu(np.array(mini_batch_move, dtype=np.int32))),
Variable(cuda.to_gpu(np.array(mini_batch_win, dtype=np.int32).reshape((-1, 1)))))
def mini_batch_for_test(positions, batchsize):
mini_batch_data = []
mini_batch_move = []
mini_batch_win = []
for b in range(batchsize):
features, move, win = make_features(random.choice(positions))
mini_batch_data.append(features)
mini_batch_move.append(move)
mini_batch_win.append(win)
return (Variable(cuda.to_gpu(np.array(mini_batch_data, dtype=np.float32))),
Variable(cuda.to_gpu(np.array(mini_batch_move, dtype=np.int32))),
Variable(cuda.to_gpu(np.array(mini_batch_win, dtype=np.int32).reshape((-1, 1)))))
今回は、data、 move、 winを読み込みます。
# train
logging.info('start training')
itr = 0
sum_loss = 0
for e in range(args.epoch):
positions_train_shuffled = random.sample(positions_train, len(positions_train))
itr_epoch = 0
sum_loss_epoch = 0
for i in range(0, len(positions_train_shuffled) - args.batchsize, args.batchsize):
x, t1, t2 = mini_batch(positions_train_shuffled, i, args.batchsize)
y1, y2 = model(x)
model.cleargrads()
loss = F.softmax_cross_entropy(y1, t1) + F.sigmoid_cross_entropy(y2, t2)
loss.backward()
optimizer.update()
itr += 1
sum_loss += loss.data
itr_epoch += 1
sum_loss_epoch += loss.data
# print train loss and test accuracy
if optimizer.t % args.eval_interval == 0:
x, t1, t2 = mini_batch_for_test(positions_test, args.test_batchsize)
y1, y2 = model(x)
logging.info('epoch = {}, iteration = {}, loss = {}, accuracy_pol = {},accuracy_val = {}'.format(
optimizer.epoch + 1, optimizer.t, sum_loss / itr,
F.accuracy(y1, t1).data, F.binary_accuracy(y2, t2).data))
itr = 0
sum_loss = 0
# validate test data
logging.info('validate test data')
itr_test = 0
sum_test_accuracy1 = 0
sum_test_accuracy2 = 0
for i in range(0, len(positions_test) - args.batchsize, args.batchsize):
x, t1, t2 = mini_batch(positions_test, i, args.batchsize)
y1, y2 = model(x)
itr_test += 1
sum_test_accuracy1 += F.accuracy(y1, t1).data
sum_test_accuracy2 += F.binary_accuracy(y2, t2).data
logging.info('epoch = {}, iteration = {}, train loss avr = {}, test accuracy_pol = {},test accuracy_val = {}'.format(
optimizer.epoch + 1, optimizer.t, sum_loss_epoch / itr_epoch,
sum_test_accuracy1 / itr_test, sum_test_accuracy2 / itr_test))
lossは以下のとおり、softmax_cross_entropy(policy用)とsigmoid_cross_entropy(value用)の和になっています。
loss = F.softmax_cross_entropy(y1, t1) + F.sigmoid_cross_entropy(y2, t2)
今回は途中の収束性のチェック毎にmodel等の保存を行いました。
logging.info('save the model')
serializers.save_npz(args.model+'{}'.format(optimizer.epoch + 1), model)
logging.info('save the optimizer')
serializers.save_npz(args.state+'{}'.format(optimizer.epoch + 1), optimizer)
optimizer.new_epoch()
(3)収束状況を確認する~正規表現利用のログのグラフ出力
今回は、lossは和ですが、accuracyはそれぞれ二種類のaccuracyを出力しています。
>python train_policy_value.py kifulist3000_train.txt kifulist3000_test.txt --eval_interval 1000
2018/08/29 23:22:44 INFO read kifu start
2018/08/29 23:23:04 INFO load train pickle
2018/08/29 23:23:07 INFO load test pickle
2018/08/29 23:23:07 INFO read kifu end
2018/08/29 23:23:07 INFO train position num = 1892246
2018/08/29 23:23:07 INFO test position num = 208704
2018/08/29 23:23:07 INFO start training
2018/08/29 23:23:39 INFO epoch = 1, iteration = 1000, loss = 7.463757, accuracy_pol = 0.01171875,accuracy_val = 0.49609375
2018/08/29 23:24:09 INFO epoch = 1, iteration = 2000, loss = 7.0174394, accuracy_pol = 0.015625,accuracy_val = 0.5214844
2018/08/29 23:24:38 INFO epoch = 1, iteration = 3000, loss = 6.834741, accuracy_pol = 0.044921875,accuracy_val = 0.5390625
accuracy_pol = 0.044921875,accuracy_val = 0.5390625を出力しているので、どちらも同じグラフ化したいということで、以下のようなコードにしました。
※この正規表現部分で苦労しました
import argparse
import re
import matplotlib.pyplot as plt
parser = argparse.ArgumentParser()
parser.add_argument('log', type=str)
args = parser.parse_args()
ptn = re.compile(r'iteration = ([0-9]+), loss = ([0-9.]+), accuracy_pol = ([0-9.]+),accuracy_val = ([0-9.]+)')
iteration_list = []
loss_list = []
accuracy_pol_list = []
accuracy_val_list = []
for line in open(args.log, 'r'):
m = ptn.search(line)
print("line",line,m)
if m:
iteration_list.append(int(m.group(1)))
loss_list.append(float(m.group(2)))
accuracy_pol_list.append(float(m.group(3)))
accuracy_val_list.append(float(m.group(4)))
fig, ax1 = plt.subplots()
p1, = ax1.plot(iteration_list, loss_list, 'r', label='loss')
ax1.set_xlabel('iterations')
ax2=ax1.twinx()
p2, = ax2.plot(iteration_list, accuracy_pol_list, 'g', label='accuracy_pol')
p3, = ax2.plot(iteration_list, accuracy_val_list, 'b', label='accuracy_val')
ax1.legend(handles=[p1, p2,p3])
plt.show()
ここで苦労したのは、ptn = re.compile(r'iteration = ([0-9]+), loss = ([0-9.]+), accuracy_pol = ([0-9.]+),accuracy_val = ([0-9.]+)')
ですね。
ということで、以下のようなグラフが得られました。
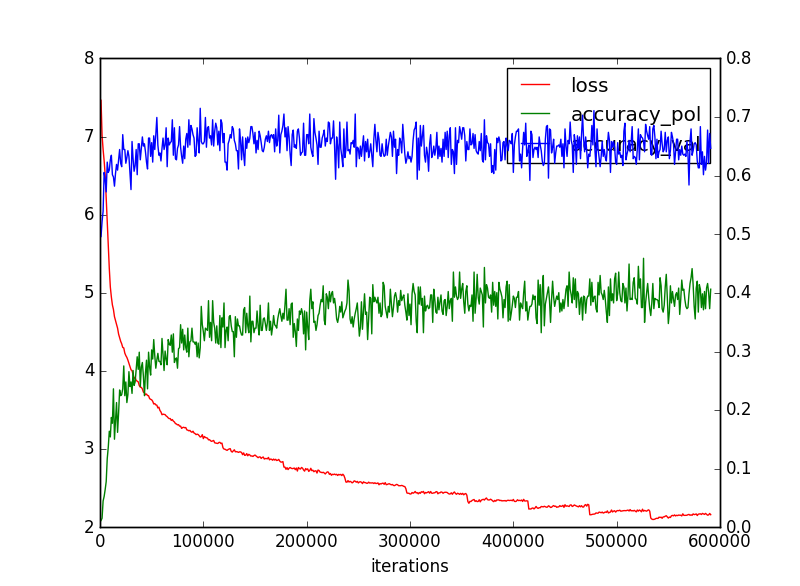
これを見ると収束状況はpolicyとvalueで異なることが分かります。
まとめ
・マルチタスク学習について説明した
・学習の収束性を見た
・これを利用して対戦したい