以下の統計検定2級対策動画で用いられているスライドの一部です。
はじめに:具体例から考えよう
ある工場で製造された製品が50個入ったロットがあります。このロットには、6個の不良品が含まれていることがわかっています。
品質検査のために、このロットから無作為に8個の製品を 非復元抽出 します。
このとき、抽出した8個の中に 不良品がちょうど2個含まれている確率 は、どのくらいになるでしょうか?
問題設定の整理
まずは、状況を整理しましょう。
- 母集団の総数 (ロット全体): 50個
- ある性質を持つ要素 (不良品): 6個
- 抽出する数: 8個
- 抽出方法: 非復元抽出 (一度取り出したら戻さない)
- 求めたい確率: 抽出した8個の中に、不良品が ちょうど2個 含まれる確率
確率計算の基本方針
このような場合の確率は、以下の基本的な考え方で計算できます。
確率 = (条件に合う場合の数) / (起こりうる全ての場合の数)
この方針に沿って、分母と分子をそれぞれ計算していきましょう。
Step 1: 起こりうる「全て」の場合の数を計算
まず、分母となる「起こりうる全ての場合の数」を計算します。
これは、「50個の製品全体から8個を選ぶ組み合わせ」の総数です。
$$
_{50} C_8 = \frac{50 \times 49 \times \dots \times 43}{8 \times 7 \times \dots \times 1}
$$
$$
= 536,878,650 \text{通り}
$$
これが、起こりうる全てのパターンです。
Step 2: 「条件に合う」場合の数を計算 (1/2)
次に、分子となる「不良品がちょうど2個含まれる」場合の数を計算します。
これは、2つのステップに分けられます。
-
1. 不良品を選ぶ
- 6個ある不良品の中から、 ちょうど2個 を選ぶ組み合わせを計算します。
$$
_6 C_2 = \frac{6 \times 5}{2 \times 1} = 15 \text{通り}
$$
Step 2: 「条件に合う」場合の数を計算 (2/2)
-
2. 良品を選ぶ
- 合計で8個抽出するので、残りの6個は良品でなければなりません。
- 良品は全部で $50 - 6 = 44$ 個あります。
- 44個の良品の中から、 残りの6個 を選ぶ組み合わせを計算します。
$$
_{44} C_6 = \frac{44 \times 43 \times \dots \times 39}{6 \times 5 \times \dots \times 1} = 7,059,052 \text{通り}
$$
「不良品2個」と「良品6個」を同時に選ぶので、これらを掛け合わせます。
$15 \times 7,059,052 = 105,885,780$ 通り
最終的な確率の計算
これで、分母と分子が揃いました。
- 分子 (条件に合う場合の数): 105,885,780
- 分母 (全ての場合の数): 536,878,650
最後に、これらを割り算して確率を求めます。
$$
P(\text{不良品が2個}) = \frac{105,885,780}{536,878,650} \approx 0.1972
$$
よって、不良品がちょうど2個含まれる確率は、 約19.72% となります。
期待値と分散も計算してみよう
この試行について、もう少し深く見てみましょう。
- 期待値: 平均して 何個 の不良品が抽出されると期待できるか?
- 分散: 抽出される不良品の数の ばらつき度合い はどのくらいか?
期待値 (平均値) の計算
期待値は、直感的に「抽出数」に「母集団の不良品率」を掛けることで計算できます。
- 抽出数: 8個
- 不良品率: 6 / 50
$$
E[X] = 8 \times \frac{6}{50} = \frac{48}{50} = 0.96
$$
8個抽出すると、平均して 0.96個 の不良品が含まれることが期待されます。
分散 (ばらつき) の計算
分散は、以下の式で計算します。
$$
V[X] = 8 \times \frac{6}{50} \left(1 - \frac{6}{50}\right) \frac{50-8}{50-1}
$$
$$
\approx 0.722
$$
式の最後にある $\frac{50-8}{50-1}$ は 有限母集団修正項 と呼ばれ、 非復元抽出 であることを考慮に入れるための重要な要素です。
重要な比較:二項分布との違い
今回の例のような「非復元抽出」を扱うのが 超幾何分布 です。
これとよく似た分布に 二項分布 がありますが、両者には明確な違いがあります。
違いは、 抽出方法 です。
比較:超幾何分布 vs 二項分布
| 項目 | 超幾何分布 (今回の例) | 二項分布 |
|---|---|---|
| 抽出方法 | 非復元抽出 | 復元抽出 |
| 各試行の独立性 | 独立ではない | 独立 |
| 成功確率 | 試行ごとに 変化する | 試行ごとに 一定 |
もし、引いた製品を毎回ロットに戻すなら (復元抽出)、それは二項分布の問題になります。
ここまでのまとめ:具体例から一般化へ
これまで見てきた具体例の計算方法を、一般的な数式や定義としてまとめたものが 超幾何分布 です。
ここからは、この超幾何分布の学術的な側面を見ていきましょう。
定義:超幾何分布とは?
超幾何分布とは、
- 2種類の結果を持つ 有限の母集団 から、
- 非復元抽出 (一度取り出したものを元に戻さない方法)で標本を抽出し、
- その標本に含まれる 特定の結果の個数 が従う確率分布
のことです。
超幾何分布が従う4つの条件
以下の条件を満たす試行が、超幾何分布に従います。
- 母集団は $N$ 個の要素からなる (例: 製品50個)
- 母集団は、ある性質を持つ要素 $M$ 個とその性質を持たない要素 $N-M$ 個に分けられる (例: 不良品6個、良品44個)
- 母集団から $n$ 個の要素を 非復元抽出 する (例: 8個抽出)
- 抽出された $n$ 個の中に、性質を持つ要素が $k$ 個含まれる (例: 不良品が2個)
確率質量関数 (確率を求める公式)
特定の性質を持つ要素が $k$ 個含まれる確率 $P(X=k)$ は、以下の公式で計算されます。
これは、先ほどの例題で行った計算の一般化です。
$$
P(X=k) = \frac{{M C_k} \times {{N-M} C_{n-k}}}{_N C_n}
$$
- $N$: 母集団の総数
- $M$: 特定の性質を持つ要素の総数
- $n$: 抽出する標本の大きさ
- $k$: 標本に含まれる、特定の性質を持つ要素の数
期待値と分散の公式
超幾何分布の期待値と分散は、以下の公式で与えられます。
-
期待値
$$
E[X] = n \frac{M}{N}
$$ -
分散
$$
V[X] = n \frac{M}{N} \left(1 - \frac{M}{N}\right) \frac{N-n}{N-1}
$$
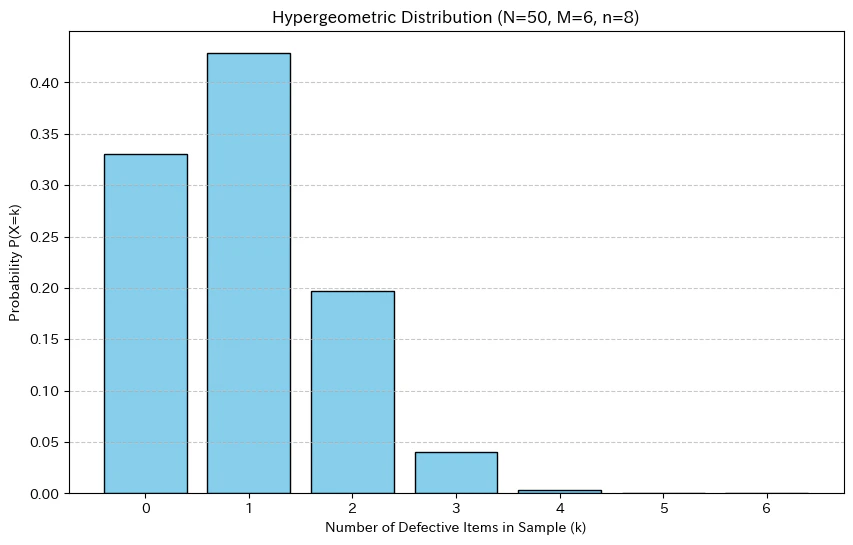
グラフによる可視化
例題のケース(N=50, M=6, n=8)で、抽出される不良品の個数ごとの確率をグラフにすると、以下のようになります。
import matplotlib.pyplot as plt
import numpy as np
from scipy.stats import hypergeom
# Parameters
N = 50 # Total number of items
M = 6 # Number of 'success' items (defective items)
n = 8 # Number of draws
# Possible values for k (number of defective items in the sample)
k_values = np.arange(0, M + 1)
# Calculate the probability mass function (PMF)
probabilities = hypergeom.pmf(k_values, N, M, n)
# Create the plot
plt.figure(figsize=(10, 6))
plt.bar(k_values, probabilities, color='skyblue', edgecolor='black')
# Add titles and labels
plt.title('Hypergeometric Distribution (N=50, M=6, n=8)')
plt.xlabel('Number of Defective Items in Sample (k)')
plt.ylabel('Probability P(X=k)')
plt.xticks(k_values)
plt.grid(axis='y', linestyle='--', alpha=0.7)
# Display the plot
plt.show()
まとめ
-
超幾何分布 は、有限母集団からの 非復元抽出 における確率分布です。
-
二項分布 との違いは、 抽出方法(復元か非復元か) と、それに伴う 各試行の独立性 です。
-
確率、期待値、分散は、それぞれ決まった公式で計算できます。
-
品質管理や生物の個体数調査など、実社会でも応用される重要な分布です。