以下の統計検定2級対策動画で用いられているスライドの一部です。
はじめに: よくある混乱
統計学を学ぶと必ず出会う2つの用語。
- 標準偏差 (SD)
- 標準誤差 (SE)
名前も計算式も似ているため、非常に混同しやすい概念です。
しかし、これらが 何を表しているか は根本的に異なります。
本日のアプローチ
このスライドでは、 曖昧な比喩を避け 、具体的な例題から始めます。
-
ステップ1:具体例の提示
- 2つの異なるケーススタディを通して、SDとSEがそれぞれ どのような場面で 、 何を明らかにするために 使われるのかを直感的に理解します。
-
ステップ2:一般化と定義
- 具体例で得た理解を元に、一般的な定義と数式を整理します。
ステップ1:具体例の提示
ケーススタディで学ぶSDとSE
例題1: カフェチェーンの売上分析
<状況>
あるカフェチェーン10店舗の、先週日曜日のアイスコーヒー販売杯数を集計しました。
<知りたいこと>
店舗ごとの販売杯数は、全体として どのくらい「ばらついて」いるのだろうか?
<データ (単位: 杯)>
[52, 65, 48, 71, 55, 62, 75, 58, 60, 54]
計算 (1/3): まずは平均を求める
ばらつきを測るためには、まずデータの「中心」が必要です。
データの合計を個数で割って、 標本平均 $\bar{x}$ を計算します。
$$
\bar{x} = \frac{52+65+...+54}{10} = \frac{600}{10} = 60
$$
この10店舗の平均販売杯数は 60杯 でした。
計算 (2/3): 平均からの「ズレ」を計算する
次に、各店舗の販売数が平均(60杯)からどれだけズレているか(=偏差)を計算し、それらを2乗して合計します。
| データ($x_i$) | 偏差($x_i - \bar{x}$) | 偏差の2乗($(x_i - \bar{x})^2$) |
|---|---|---|
| 52 | -8 | 64 |
| 65 | 5 | 25 |
| 48 | -12 | 144 |
| ... | ... | ... |
| 54 | -6 | 36 |
| 合計 | 648 |
計算 (3/3): 「ばらつき」の大きさを算出する
最後に、先ほどの合計値(648)を「サンプルサイズ - 1」($10 - 1 = 9$)で割り、その平方根を求めます。
$$
s = \sqrt{\frac{648}{10-1}} = \sqrt{\frac{648}{9}} = \sqrt{72} \approx 8.49
$$
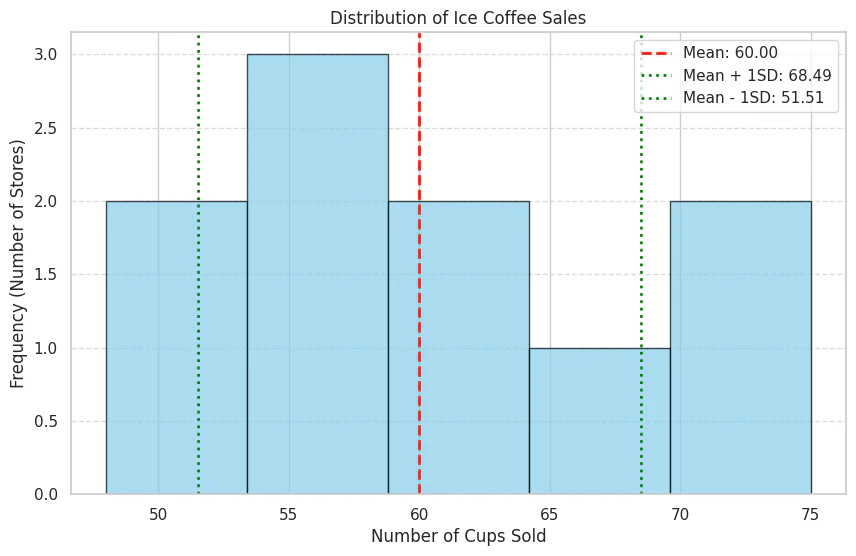
この 約8.49杯 という値が、今回のデータの「ばらつき」を表す指標です。
結論 (例題1): これが 標準偏差 (SD) です
- 計算で得られた 約8.49杯 が 標本標準偏差 です。
- これは、 「各店舗の販売杯数は、平均60杯を中心に、平均して約8.49杯ばらついている」 ことを意味します。
標準偏差 は、観測された データそのもの の散らばり具合を記述する指標です。
[可視化] データ分布と標準偏差
ヒストグラムでデータを見ると、ばらつきのイメージがより明確になります。
import numpy as np
import matplotlib.pyplot as plt
# Data
data = np.array([52, 65, 48, 71, 55, 62, 75, 58, 60, 54])
mean = np.mean(data)
sd = np.std(data, ddof=1)
# Plot
plt.figure(figsize=(10, 6))
plt.hist(data, bins=5, color='skyblue', edgecolor='black', alpha=0.7)
plt.axvline(mean, color='red', linestyle='dashed', linewidth=2, label=f'Mean: {mean:.2f}')
plt.axvline(mean + sd, color='green', linestyle='dotted', linewidth=2, label=f'Mean + 1SD: {mean+sd:.2f}')
plt.axvline(mean - sd, color='green', linestyle='dotted', linewidth=2, label=f'Mean - 1SD: {mean-sd:.2f}')
plt.title('Distribution of Ice Coffee Sales')
plt.xlabel('Number of Cups Sold')
plt.ylabel('Frequency (Number of Stores)')
plt.legend()
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.show()
例題2: 新薬の効果持続時間の推定
<状況>
製薬会社が新開発した鎮痛剤の効果を調べるため、25人の被験者に投与し、持続時間を測定しました。
<知りたいこと>
今回の調査で得られた「平均7.5時間」という結果は、 どのくらい「精度が高い」推定なのだろうか?
<データ>
- サンプルサイズ $n$: 25人
- 標本平均 $\bar{x}$: 7.5時間
- 標本標準偏差 $s$: 1.5時間
計算: 「推定の精度」を算出する
ここでは、先ほどとは異なる計算をします。
標本標準偏差 $s$ を サンプルサイズの平方根 $\sqrt{n}$ で割ります。
$$
SE = \frac{s}{\sqrt{n}} = \frac{1.5}{\sqrt{25}} = \frac{1.5}{5} = 0.3
$$
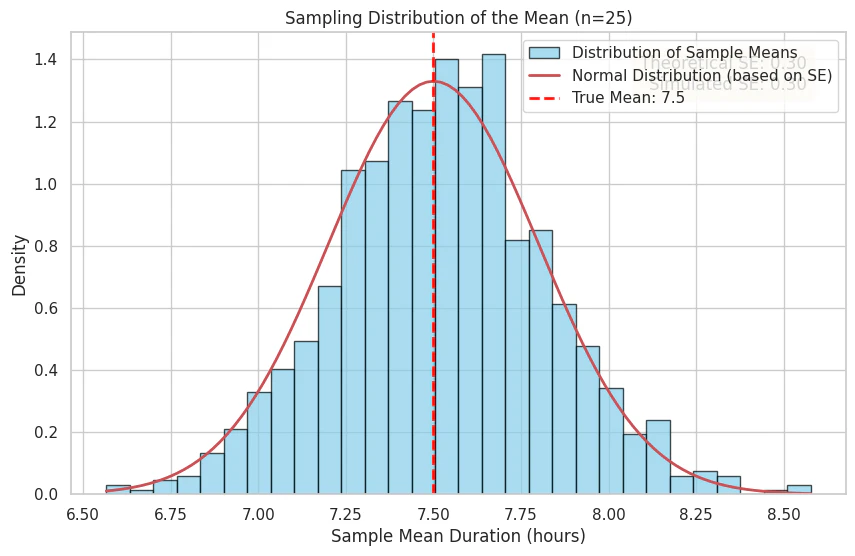
この 0.3時間 という値が、今回の「推定の精度」を表す指標です。
結論 (例題2): これが 標準誤差 (SE) です
- 計算で得られた 0.3時間 が 標準誤差 です。
- これは、 「今回得られた平均7.5時間という推定値は、真の平均値から平均的に0.3時間程度ずれているだろう」 ことを意味します。
標準誤差 は、標本から計算した 推定量(ここでは標本平均)の信頼性や精度 を表す指標です。
[可視化] 推定値のばらつきと標準誤差
もし同じ調査を何度も繰り返したら、その度に標本平均は少しずつ変動します。この 「標本平均のばらつき」 が標準誤差の正体です。
import numpy as np
import matplotlib.pyplot as plt
import scipy.stats as stats
# Assume true population parameters
true_mean = 7.5
true_sd = 1.5
sample_size = 25
# Simulate 1000 experiments
num_experiments = 1000
sample_means = [np.mean(np.random.normal(true_mean, true_sd, sample_size)) for _ in range(num_experiments)]
# Calculate theoretical SE and simulated SE
se_theoretical = true_sd / np.sqrt(sample_size)
se_simulated = np.std(sample_means, ddof=1)
# Plot
plt.figure(figsize=(10, 6))
plt.hist(sample_means, bins=30, density=True, color='skyblue', edgecolor='black', alpha=0.7, label='Distribution of Sample Means')
x = np.linspace(min(sample_means), max(sample_means), 100)
plt.plot(x, stats.norm.pdf(x, true_mean, se_theoretical), 'r-', lw=2, label='Normal Distribution (based on SE)')
plt.axvline(true_mean, color='red', linestyle='dashed', linewidth=2, label=f'True Mean: {true_mean}')
plt.title(f'Sampling Distribution of the Mean (n={sample_size})')
plt.xlabel('Sample Mean Duration (hours)')
plt.ylabel('Density')
plt.legend()
plt.text(0.95, 0.95, f'Theoretical SE: {se_theoretical:.2f}\nSimulated SE: {se_simulated:.2f}',
transform=plt.gca().transAxes, fontsize=12, verticalalignment='top', horizontalalignment='right',
bbox=dict(boxstyle='round,pad=0.5', fc='wheat', alpha=0.5))
plt.grid(True)
plt.show()
ステップ2:一般化と定義
例題から学ぶ定義と公式
標準偏差 (Standard Deviation: SD)
定義
データ そのもの の 「ばらつきの大きさ」 を示す指標。
個々のデータ点が、データセットの平均値から平均的にどれだけ離れているかを表します。
計算式(標本の場合)
$$
s = \sqrt{\frac{1}{n-1}\sum_{i=1}^{n}(x_i - \bar{x})^2}
$$
- $s$: 標本標準偏差
- $n$: サンプルサイズ
- $x_i$: 個々のデータの値
- $\bar{x}$: 標本平均
標準誤差 (Standard Error: SE)
定義
標本から計算された 推定量 (例:標本平均)の 「推定の精度」 を示す指標。
標本平均が、私たちが本当に知りたい母集団の平均(母平均)からどれくらいずれていると期待されるかを表します。
計算式(標本平均の場合)
$$
SE = \frac{s}{\sqrt{n}}
$$
- $SE$: 標本平均の標準誤差
- $s$: 標本標準偏差
- $n$: サンプルサイズ
決定的な違い: SD vs SE まとめ
| 項目 | 標準偏差 (SD) | 標準誤差 (SE) |
|---|---|---|
| 目的 | データの ばらつき を記述する | 推定の 精度 を評価する |
| 対象 | データそのもの | 標本平均などの推定量 |
| 解釈 | データ点が平均からどれだけ散らばっているか | 標本平均が母平均からどれだけ離れていると期待されるか |
| $n$との関係 | $n$が増えても値は安定する傾向 |
$n$が増えると値は小さくなる (精度が上がる) |
使い分けのポイント
-
標準偏差 (SD) を使う時
手元のデータの 分布特性を報告したい 場合
例: 「今回調査した30人の被験者の最高血圧は、平均130mmHg、 標準偏差15mmHg でした。」
→ 30人のデータがどのくらいばらついているかを記述。 -
標準誤差 (SE) を使う時
標本から 母集団の特性を推定し、その信頼性を示したい 場合
例: 「日本人男性の平均身長の推定値は171.0cmで、その 標準誤差は0.7cm です。」
→ 171.0cmという推定値の精度を報告。
結論
この違いを理解することが、正しい統計的解釈の第一歩です。