以下の統計検定2級®︎対策動画で用いられているスライドの一部です。
統計検定®2級対策オリジナル問題であり、非公式です。
※統計検定®は一般財団法人統計質保証推進協会の登録商標です。
問題
ある製薬会社が開発した新しい睡眠導入剤の効果を検証するため、25人の被験者にこの薬を投与し、入眠までにかかった時間を測定した。過去のデータから、この種の薬の入眠時間は正規分布に従うことが知られている。標本平均は30分、不偏分散は100であった。
この薬が従来の薬の平均入眠時間である35分よりも短いかを確かめるため、母平均 $\mu$ に関する仮説検定 $H_0: \mu = 35$ vs $H_1: \mu < 35$ を行う。このときの検定統計量 $t$ 値は -2.50 であった。この検定結果の解釈として最も適切なものを、次の①~⑤のうちから一つ選べ。
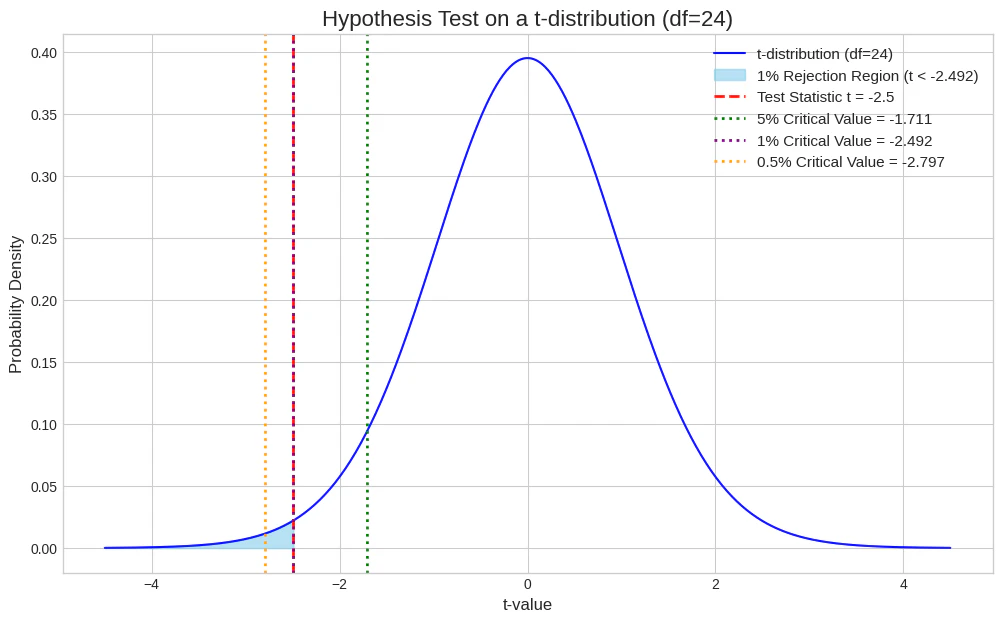
- 自由度24のt分布の上側5%点: $t_{0.05}(24) = 1.711$
- 自由度24のt分布の上側2.5%点: $t_{0.025}(24) = 2.064$
- 自由度24のt分布の上側1%点: $t_{0.01}(24) = 2.492$
- 自由度24のt分布の上側0.5%点: $t_{0.005}(24) = 2.797$
① 有意水準5%で帰無仮説は棄却されない。
② 有意水準5%で帰無仮説は棄却されるが、有意水準1%では棄却されない。
③ 有意水準1%で帰無仮説は棄却されるが、有意水準0.5%では棄却されない。
④ 有意水準0.5%で帰無仮説は棄却される。
⑤ 与えられた情報だけでは、有意水準1%で棄却されるか判断できない。
解答
③ 有意水準1%で帰無仮説は棄却されるが、有意水準0.5%では棄却されない。
この問題のポイント:t検定による仮説検定
1. 仮説検定とは何か?
統計学における 仮説検定 とは、「手元にあるデータ(標本)を使って、母集団に関する仮説が正しいと言えるか」を判断するための手法です。
主張したいことに対し、「その差は 偶然 によるものなのか、それとも 意味のある(有意な)差 なのか」を客観的に判断します。
- 帰無仮説 ($H_0$): 「差はない」「効果はない」という、否定したい仮説。
- 対立仮説 ($H_1$): 「差がある」「効果がある」という、主張したい仮説。
2. t検定の役割
t検定 は、仮説検定の中でも特に「母集団の平均値」について議論するときに用います。特に、母集団の分散が分かっていない場合に有効です。
-
検定統計量 t値: 標本平均が、帰無仮説の母平均からどれだけ離れているかを示した値。絶対値が大きいほど、「偶然とは考えにくい大きな差」があることを意味します。
-
有意水準 ($\alpha$): 「どれくらい珍しいことが起きたら、帰無仮説を棄却するか」という基準となる確率。一般的に、5% (0.05) や 1% (0.01) が使われます。
-
棄却域: 検定統計量t値がこの領域に入ると帰無仮説を棄却する、という範囲のことです。
3. なぜt検定は重要なのか?
t検定は、科学的な意思決定を行うための基本的なツールです。
-
製品開発: 新しい製品Aと従来品Bの性能を比較し、「AはBより統計的に有意に優れている」と結論付ける。
-
マーケティング: 新しい広告キャンペーンの前後で売上を比較し、「キャンペーンには売上を伸ばす効果があった」と判断する。
-
医療: 新薬の治療効果をプラセボ(偽薬)と比較し、「新薬は統計的に有意な効果を持つ」と証明する。
データに基づいた客観的な判断を下すことで、ビジネスや研究の質を高めることができます。
問題と解説(再掲)
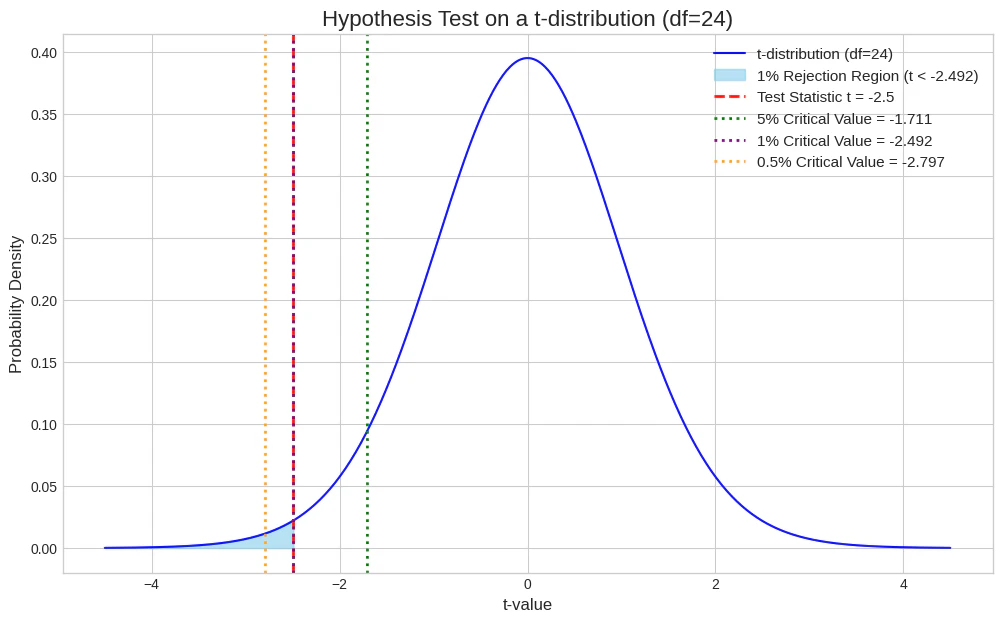
ある製薬会社が開発した新しい睡眠導入剤の効果を検証するため、25人の被験者にこの薬を投与し、入眠までにかかった時間を測定した。標本平均は30分、不偏分散は100であった。この薬が従来の薬の平均入眠時間である35分よりも短いかを確かめるため、母平均 $\mu$ に関する仮説検定 $H_0: \mu = 35$ vs $H_1: \mu < 35$ を行う。このときの検定統計量 $t$ 値は -2.50 であった。
- 自由度24のt分布の上側5%点: $t_{0.05}(24) = 1.711$
- 自由度24のt分布の上側2.5%点: $t_{0.025}(24) = 2.064$
- 自由度24のt分布の上側1%点: $t_{0.01}(24) = 2.492$
- 自由度24のt分布の上側0.5%点: $t_{0.005}(24) = 2.797$
解答の根拠
- 検定の種類と自由度の確認
- 対立仮説が $H_1: \mu < 35$ なので、これは 左片側検定 です。
- 標本の大きさ $n=25$ なので、t分布の自由度は $df = n-1 = 25-1 = 24$ です。
- 各有意水準での棄却限界値の特定
- 左片側検定なので、棄却域はt分布の負の側にあります。与えられた「上側パーセント点」にマイナスを付けた値が「棄却限界値」となります。
- 有意水準5%: 棄却限界値は $-t_{0.05}(24) = -1.711$
- 有意水準1%: 棄却限界値は $-t_{0.01}(24) = -2.492$
- 有意水準0.5%: 棄却限界値は $-t_{0.005}(24) = -2.797$
解答の根拠
- 検定統計量との比較
- 計算された検定統計量は $t = -2.50$ です。この値が、棄却限界値より小さい(より左側にある)かを判定します。
- 有意水準5%: $t = -2.50 < -1.711$ なので、帰無仮説は 棄却されます 。
- 有意水準1%: $t = -2.50 < -2.492$ なので、帰無仮説は 棄却されます 。
- 有意水準0.5%: $t = -2.50 > -2.797$ なので、帰無仮説は 棄却されません 。
-
結論
以上の結果から、「有意水準1%で帰無仮説は棄却されるが、有意水準0.5%では棄却されない」ことがわかります。これは選択肢 ③ の内容と一致します。
問題
ある大学で、オンライン授業の導入に対する学生の意見を調査するため、300名の学生を無作為抽出し、アンケートを実施した。その結果を学年(1・2年生/3・4年生)と意見(賛成/反対)でまとめたところ、以下の分割表が得られた。
| 賛成 | 反対 | 合計 | |
|---|---|---|---|
| 1・2年生 | 130 | 50 | 180 |
| 3・4年生 | 70 | 50 | 120 |
| 合計 | 200 | 100 | 300 |
[1] 学年と意見の独立性を検定するために、「3・4年生で反対と答える」というセルの期待度数を計算した。最も適切な値を、次の①~⑤の中から一つ選べ。
① 20.0, ② 40.0, ③ 50.0, ④ 60.0, ⑤ 80.0
[2] このデータを用いて独立性の検定を行う際のカイ二乗($χ^2$)統計量の計算式として、正しいものを次の①~⑤の中から一つ選べ。
① $χ^2 = \frac{(130-120)^2}{130} + \frac{(50-60)^2}{50} + \frac{(70-80)^2}{70} + \frac{(50-40)^2}{50}$
② $χ^2 = \frac{(130-120)}{120} + \frac{(50-60)}{60} + \frac{(70-80)}{80} + \frac{(50-40)}{40}$
③ $χ^2 = \frac{(130-120)^2 + (50-60)^2 + (70-80)^2 + (50-40)^2}{300}$
④ $χ^2 = \frac{(130-120)^2}{120} + \frac{(50-60)^2}{60} + \frac{(70-80)^2}{80} + \frac{(50-40)^2}{40}$
⑤ $χ^2 = \frac{(130-200)^2}{200} + \frac{(50-100)^2}{100} + \frac{(70-200)^2}{200} + \frac{(50-100)^2}{100}$
解答
[1] ②
[2] ④
この問題のポイント:独立性のカイ二乗検定
1. 独立性の検定とは何か?
独立性のカイ二乗検定 は、2つのカテゴリカル変数が互いに 関連しているか、それとも無関係(独立)か を調べるための統計手法です。
例えば、「性別と支持政党」「血液型と性格」「学年と意見」などの関連性を分析します。
- 帰無仮説 ($H_0$): 2つの変数は 独立である (関連がない)。
- 対立仮説 ($H_1$): 2つの変数は 独立ではない (関連がある)。
「観測された度数(実際のデータ)」と「もし変数が独立だったら期待される度数(期待度数)」の差を比較します。
2. 期待度数とカイ二乗統計量
-
期待度数: 「もし学年と意見が全く無関係だったら、このセルには何人のデータが入るはずか?」という理論値です。
$$
\text{期待度数} = \frac{(\text{そのセルの行合計}) \times (\text{そのセルの列合計})}{\text{全体の合計}}
$$ -
カイ二乗統計量 ($χ^2$): 観測度数と期待度数のズレの大きさを、すべてのセルについて合計したものです。この値が大きいほど、データは「変数が独立である」という仮説から離れていることを示します。
$$
\chi^2 = \sum_{\text{すべてのセル}} \frac{(\text{観測度数} - \text{期待度数})^2}{\text{期待度数}}
$$
3. なぜカイ二乗検定は重要なのか?
カイ二乗検定は、アンケート調査や市場調査などのカテゴリカルデータを分析する上で非常に強力なツールです。
-
マーケティング: 「顧客の年代によって、好まれる商品のジャンルに違いはあるか?」を分析し、ターゲット層に合わせた広告戦略を立てる。
-
社会調査: 「居住地域によって、政策への支持率に差はあるか?」を調べ、地域ごとの課題を明らかにする。
-
医療: 「ある生活習慣の有無と、特定の疾患の発症率に関連はあるか?」を検証する。
問題と解説(再掲)
[1] 学年と意見の独立性を検定するために、「3・4年生で反対と答える」というセルの期待度数を計算した。最も適切な値を、次の①~⑤の中から一つ選べ。
① 20.0
② 40.0
③ 50.0
④ 60.0
⑤ 80.0
解答の根拠
期待度数の計算式 (行合計 × 列合計) / 全体合計 を用います。
- 対象セル: 「3・4年生で反対」
- 行合計 (3・4年生の合計): 120
- 列合計 (反対の合計): 100
- 全体合計: 300
これを式に代入します。
$$
\text{期待度数} = \frac{120 \times 100}{300} = \frac{12000}{300} = 40.0
$$
よって、正解は ② です。
問題と解説(再掲)
[2] このデータを用いて独立性の検定を行う際のカイ二乗($χ^2$)統計量の計算式として、正しいものを次の①~⑤の中から一つ選べ。
① $χ^2 = \frac{(130-120)^2}{130} + \frac{(50-60)^2}{50} + \frac{(70-80)^2}{70} + \frac{(50-40)^2}{50}$
② $χ^2 = \frac{(130-120)}{120} + \frac{(50-60)}{60} + \frac{(70-80)}{80} + \frac{(50-40)}{40}$
③ $χ^2 = \frac{(130-120)^2 + (50-60)^2 + (70-80)^2 + (50-40)^2}{300}$
④ $χ^2 = \frac{(130-120)^2}{120} + \frac{(50-60)^2}{60} + \frac{(70-80)^2}{80} + \frac{(50-40)^2}{40}$
⑤ $χ^2 = \frac{(130-200)^2}{200} + \frac{(50-100)^2}{100} + \frac{(70-200)^2}{200} + \frac{(50-100)^2}{100}$
解答の根拠
-
カイ二乗統計量の公式を確認
$$
\chi^2 = \sum \frac{(\text{観測度数} - \text{期待度数})^2}{\text{期待度数}}
$$ -
各セルの期待度数を計算
- 1・2年生、賛成: $(180 \times 200) / 300 = 120$
- 1・2年生、反対: $(180 \times 100) / 300 = 60$
- 3・4年生、賛成: $(120 \times 200) / 300 = 80$
- 3・4年生、反対: $(120 \times 100) / 300 = 40$
解答の根拠
-
公式に当てはめて式を組み立てる
各セルの「(観測度数 - 期待度数)² / 期待度数」を計算し、足し合わせます。
- (観測130, 期待120) → $\frac{(130-120)^2}{120}$
- (観測50, 期待60) → $\frac{(50-60)^2}{60}$
- (観測70, 期待80) → $\frac{(70-80)^2}{80}$
- (観測50, 期待40) → $\frac{(50-40)^2}{40}$
これらをすべて足し合わせた式がカイ二乗統計量となり、選択肢 ④ と一致します。