以下の統計検定2級®︎対策動画で用いられているスライドの一部です。
統計検定®2級対策オリジナル問題であり、非公式です。
※統計検定®は一般財団法人統計質保証推進協会の登録商標です。
問題
あるマーケティング会社が、利用者の年代と最も頻繁に利用するSNSプラットフォームの関係を調査するため、600人を対象にアンケートを実施し、以下の分割表を得た。
分割表: 年代別SNS利用状況
| 年代 | InstaVerse | ConnectSphere | ChitChat | 行和 |
|---|---|---|---|---|
| 10代 | 80 | 20 | 10 | 110 |
| 20-30代 | 100 | 70 | 30 | 200 |
| 40-50代 | 40 | 80 | 50 | 170 |
| 60代以上 | 10 | 30 | 80 | 120 |
| 列和 | 230 | 200 | 170 | 600 |
このデータを用いて、年代と利用するSNSプラットフォームの間に 関連がない(独立である) という帰無仮説を検定したい。
解答
[1] 帰無仮説が正しいと仮定した場合の「10代」かつ「InstaVerse」のセルの期待度数として、最も近い値を次の①~⑤のうちから一つ選べ。
① 38.3 ② 42.2 ③ 45.1 ④ 80.0 ⑤ 110.0
[2] この独立性の検定で用いる$\chi^2$(カイ二乗)統計量の自由度として、正しいものを次の①~⑤のうちから一つ選べ。
① 2 ② 3 ③ 4 ④ 6 ⑤ 12
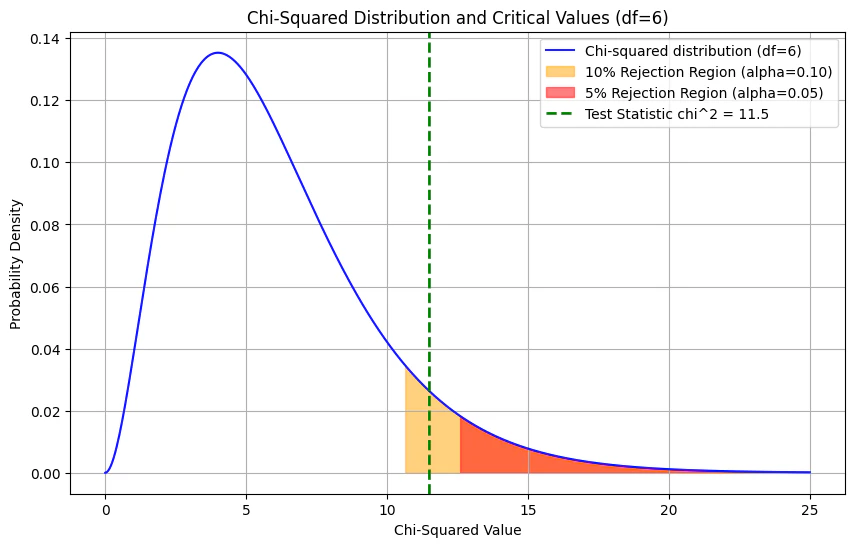
[3] 実際に$\chi^2$統計量を計算したところ、$\chi^2 = 11.50$ という値が得られた。自由度6のカイ二乗分布におけるパーセント点(上側確率α)は、$\chi^2_{0.10}(6) = 10.64$、$\chi^2_{0.05}(6) = 12.59$ である。この結果に関する解釈として、最も適切なものを次の①~⑤のうちから一つ選べ。
① 有意水準5%で有意であり、かつ有意水準10%でも有意である。
② 有意水準5%では有意であるが、有意水準10%では有意ではない。
③ 有意水準10%では有意であるが、有意水準5%では有意ではない。
④ 有意水準5%でも有意水準10%でも有意ではない。
⑤ 与えられた情報だけでは、有意性の判断はできない。
ポイント解説:カイ二乗検定(独立性の検定)
1. カイ二乗検定とは?
カイ二乗検定は、アンケート結果などで得られるカテゴリカルデータを扱うための統計手法です。
-
独立性の検定
- 2つのカテゴリカル変数に 関連があるか 、それとも 無関係(独立)か を判断するために使われます。
- 今回の問題では、「年代」と「利用SNS」が独立かどうか、つまり「年代によって利用するSNSに違いがあるのか、それとも偶然の差なのか」を検証します。
ポイント解説:カイ二乗検定(独立性の検定)
2. 「観測度数」と「期待度数」
検定の核心は、 観測度数 と 期待度数 の比較です。
-
観測度数
- 実際に調査して得られた、表の中の各セルの値です。
- 例: 10代でInstaVerseを使う人は80人。
-
期待度数
- 「もし2つの変数が完全に独立だったら、このセルには何人が入るはずか」という理論上の予測値です。
両者の ズレ が大きければ大きいほど、「独立だとは言えない、何か関連がある」と結論付けられます。
ポイント解説:カイ二乗検定(独立性の検定)
3. 期待度数と自由度の計算
-
期待度数の計算式
- 「全体の構成比が、各行・各列でも同じように現れるはずだ」という考えに基づきます。
$$
\text{期待度数} = \frac{(\text{その行の合計}) \times (\text{その列の合計})}{\text{全体の合計}}
$$
-
自由度の計算式
- 自由度とは、統計的な「自由さ」の度合いです。「自由に決められるセルの数」を意味します。
$$
\text{自由度} = (\text{行の数} - 1) \times (\text{列の数} - 1)
$$
ポイント解説:カイ二乗検定(独立性の検定)
4. 統計学における重要性
カイ二乗検定は、実社会の様々な場面で活用される非常に重要なツールです。
-
マーケティング
- 「広告Aと広告Bでは、購入率に差があるか?」
-
医療
- 「新薬とプラセボ(偽薬)では、回復率に差があるか?」
-
社会調査
- 「性別と支持政党に関連はあるか?」
カテゴリに分けられたデータ間の関連性を客観的な数値で評価し、それが 統計的に意味のある差なのか を判断する上で不可欠な手法です。
問題
あるマーケティング会社が、利用者の年代と最も頻繁に利用するSNSプラットフォームの関係を調査するため、600人を対象にアンケートを実施し、以下の分割表を得た。
分割表: 年代別SNS利用状況
| 年代 | InstaVerse | ConnectSphere | ChitChat | 行和 |
|---|---|---|---|---|
| 10代 | 80 | 20 | 10 | 110 |
| 20-30代 | 100 | 70 | 30 | 200 |
| 40-50代 | 40 | 80 | 50 | 170 |
| 60代以上 | 10 | 30 | 80 | 120 |
| 列和 | 230 | 200 | 170 | 600 |
このデータを用いて、年代と利用するSNSプラットフォームの間に 関連がない(独立である) という帰無仮説を検定したい。
解答の根拠 [1]
[1] 帰無仮説が正しいと仮定した場合の「10代」かつ「InstaVerse」のセルの期待度数として、最も近い値を次の①~⑤のうちから一つ選べ。
① 38.3 ② 42.2 ③ 45.1 ④ 80.0 ⑤ 110.0
期待度数は以下の式で計算します。
期待度数 = (行の合計 × 列の合計) / 全体の合計
- 「10代」の行の合計は 110
- 「InstaVerse」の列の合計は 230
- 全体の合計は 600
$$
\text{期待度数} = \frac{110 \times 230}{600} = \frac{25300}{600} = 42.166...
$$
最も近い値は 42.2 なので、正解は ② です。
解答の根拠 [2]
[2] この独立性の検定で用いる$\chi^2$(カイ二乗)統計量の自由度として、正しいものを次の①~⑤のうちから一つ選べ。
① 2 ② 3 ③ 4 ④ 6 ⑤ 12
自由度は以下の式で計算します。
自由度 = (行の数 - 1) × (列の数 - 1)
- この分割表は 4行3列 です。
$$
\text{自由度} = (4 - 1) \times (3 - 1) = 3 \times 2 = 6
$$
したがって、正解は ④ です。
解答の根拠 [3]
[3] 実際に$\chi^2$統計量を計算したところ、$\chi^2 = 11.50$ という値が得られた。自由度6のカイ二乗分布におけるパーセント点(上側確率α)は、$\chi^2_{0.10}(6) = 10.64$、$\chi^2_{0.05}(6) = 12.59$ である。この結果に関する解釈として、最も適切なものを次の①~⑤のうちから一つ選べ。
① 有意水準5%で有意であり、かつ有意水準10%でも有意である。
② 有意水準5%では有意であるが、有意水準10%では有意ではない。
③ 有意水準10%では有意であるが、有意水準5%では有意ではない。
④ 有意水準5%でも有意水準10%でも有意ではない。
⑤ 与えられた情報だけでは、有意性の判断はできない。
検定では、計算した統計量と臨界値(基準値)を比較します。
-
計算された$\chi^2$値: 11.50
-
有意水準10%の臨界値: 10.64
-
有意水準5%の臨界値: 12.59
-
有意水準10%での判断:
11.50 > 10.64→ 10%水準で有意差あり 。 -
有意水準5%での判断:
11.50 < 12.59→ 5%水準では有意とは言えない 。
結論として、「有意水準10%では有意であるが、有意水準5%では有意ではない」となります。正解は ③ です。
問題
ある製薬会社が開発した新薬の効果を調べるため、臨床試験を行った。母集団における有効率(比率)$p$ の推定を考える。
[1] 900人の患者に新薬を投与したところ、108人に効果が見られた。この結果から母有効率$p$に対する信頼係数99%の信頼区間を求めたい。信頼区間を以下の式で構成するとき、A, B, Cに当てはまる数値の組合せとして最も適切なものを、次の①~⑤のうちから一つ選べ。
① A = 1.96, B = 0.12, C = 900 ② A = 2.58, B = 0.12, C = 900
③ A = 2.58, B = 108, C = 900 ④ A = 1.65, B = 0.12, C = 108
⑤ A = 2.58, B = 0.12, C = 108
$$
B \pm A \times \sqrt{\frac{B(1-B)}{C}}
$$
[2] 今後、同様の臨床試験を行う計画がある。母有効率$p$に対する信頼係数95%の信頼区間の 幅 が0.06以下になるようにするためには、最低何人の患者を調査対象とする必要があるか。最も近い値を次の①~⑤のうちから一つ選べ。ただし、過去の知見から、この種の薬の有効率は高くても20%を超えないことがわかっているものとする。
① 450人 ② 550人 ③ 690人 ④ 820人 ⑤ 960人
解答
[1] 900人の患者に新薬を投与したところ、108人に効果が見られた。この結果から母有効率$p$に対する信頼係数99%の信頼区間を求めたい。信頼区間を以下の式で構成するとき、A, B, Cに当てはまる数値の組合せとして最も適切なものを、次の①~⑤のうちから一つ選べ。
① A = 1.96, B = 0.12, C = 900 ② A = 2.58, B = 0.12, C = 900
③ A = 2.58, B = 108, C = 900 ④ A = 1.65, B = 0.12, C = 108
⑤ A = 2.58, B = 0.12, C = 108
[2] 今後、同様の臨床試験を行う計画がある。母有効率$p$に対する信頼係数95%の信頼区間の 幅 が0.06以下になるようにするためには、最低何人の患者を調査対象とする必要があるか。最も近い値を次の①~⑤のうちから一つ選べ。ただし、過去の知見から、この種の薬の有効率は高くても20%を超えないことがわかっているものとする。
① 450人 ② 550人 ③ 690人 ④ 820人 ⑤ 960人
ポイント解説:母比率の信頼区間
1. 信頼区間とは?
選挙の出口調査の「支持率45%、誤差は±3%」のように、調査結果の不確実さを示すための区間です。
-
点推定
- サンプルの結果(標本比率)を、そのまま全体の推定値(母比率)とする方法。
-
区間推定
- 「 95%の確率で、真の母比率はこの範囲に入っているでしょう 」というように、幅を持たせた区間で推定する方法。この区間が 信頼区間 です。
私たちは一部の 標本 から全体( 母集団 )の様子を推測します。
ポイント解説:母比率の信頼区間
2. 信頼区間の構成要素
信頼区間は、標本比率 ± 誤差の許容範囲 という形で計算されます。
$$
\hat{p} \pm z_{\alpha/2} \sqrt{\frac{\hat{p}(1-\hat{p})}{n}}
$$
- $\hat{p}$: 標本比率 (有効だった人数 / 全体の人数)
- $n$: 標本の大きさ (サンプルサイズ)
- $z_{\alpha/2}$: 信頼係数 (信頼度によって決まる値)
- 信頼度95% → $z=1.96$
- 信頼度99% → $z=2.58$
- $\sqrt{\frac{\hat{p}(1-\hat{p})}{n}}$: 標準誤差 (標本比率のばらつき)
ポイント解説:母比率の信頼区間
3. 必要なサンプルサイズの設計
調査を始める前に、「目標とする精度(信頼区間の幅)」を達成するために必要なサンプルサイズを逆算できます。
信頼区間の幅を狭く(精度を高く)したい場合:
- サンプルサイズ $n$ を 大きくする
- 信頼度を 下げる (例: 99%→95%)
実用上は信頼度を固定し、必要なサンプルサイズを見積もることが多いです。
ポイント解説:母比率の信頼区間
4. 統計学における重要性
信頼区間は、統計的推定の根幹をなす概念です。
-
結果の信頼性評価
- 「内閣支持率40%」だけでなく、「信頼区間 [37%, 43%]」という情報で不確かさを客観的に伝えられます。
-
意思決定の支援
- 新製品の市場受容度調査で、信頼区間が十分に高ければ、発売に踏み切る判断材料になります。
-
効率的な調査計画
- 目標精度から必要なサンプルサイズを計算し、コストと精度のバランスをとることができます。
問題
ある製薬会社が開発した新薬の効果を調べるため、臨床試験を行った。母集団における有効率(比率)$p$ の推定を考える。
[1] 900人の患者に新薬を投与したところ、108人に効果が見られた。この結果から母有効率$p$に対する信頼係数99%の信頼区間を求めたい。信頼区間を以下の式で構成するとき、A, B, Cに当てはまる数値の組合せとして最も適切なものを、次の①~⑤のうちから一つ選べ。
① A = 1.96, B = 0.12, C = 900 ② A = 2.58, B = 0.12, C = 900
③ A = 2.58, B = 108, C = 900 ④ A = 1.65, B = 0.12, C = 108
⑤ A = 2.58, B = 0.12, C = 108
$$
B \pm A \times \sqrt{\frac{B(1-B)}{C}}
$$
[2] 今後、同様の臨床試験を行う計画がある。母有効率$p$に対する信頼係数95%の信頼区間の 幅 が0.06以下になるようにするためには、最低何人の患者を調査対象とする必要があるか。最も近い値を次の①~⑤のうちから一つ選べ。
① 450人 ② 550人 ③ 690人 ④ 820人 ⑤ 960人
解答の根拠 [1]
[1] 信頼区間を以下の式で構成するとき、A, B, Cに当てはまる数値の組合せとして最も適切なものを、次の①~⑤のうちから一つ選べ。
① A = 1.96, B = 0.12, C = 900 ② A = 2.58, B = 0.12, C = 900
③ A = 2.58, B = 108, C = 900 ④ A = 1.65, B = 0.12, C = 108
⑤ A = 2.58, B = 0.12, C = 108$$ B \pm A \times \sqrt{\frac{B(1-B)}{C}} $$
信頼区間の公式と比較します。
-
B: 標本比率 $\hat{p}$
-
A: 信頼係数 $z_{\alpha/2}$
-
C: 標本の大きさ $n$
-
C (標本の大きさ): 患者数は 900 人なので、$C=900$。
-
B (標本比率): 900人中108人に効果があったので、$B = \frac{108}{900} = 0.12$。
-
A (信頼係数): 信頼係数99%に対応する値は 2.58 なので、$A=2.58$。
これらの組合せは A=2.58, B=0.12, C=900 となり、正解は ② です。
解答の根拠 [2]
[2] 母有効率$p$に対する信頼係数95%の信頼区間の幅が0.06以下になるようにするためには、最低何人の患者を調査対象とする必要があるか。
① 450人 ② 550人 ③ 690人 ④ 820人 ⑤ 960人
必要なサンプルサイズ $n$ を求めます。まず、条件を整理します。
-
信頼区間の幅 $\le 0.06$
-
誤差の許容範囲$E \le 0.03$ となります。
-
-
信頼係数95%
- 対応する $z$ 値は 1.96 です。
-
母比率 $p$ の推定
- 「高くても20%を超えない」という情報から、最も安全(保守的)な $p=0.2$ を用います。
解答の根拠 [2] - 計算
必要なサンプルサイズ $n$ の公式に値を代入します。
$$
n \ge \left( \frac{z_{\alpha/2}}{E} \right)^2 p(1-p)
$$
$$
n \ge \left( \frac{1.96}{0.03} \right)^2 \times 0.2 \times (1-0.2)
$$
$$
n \ge (65.333...)^2 \times 0.16
$$
$$
n \ge 4268.44... \times 0.16
$$
$$
n \ge 682.95...
$$
この条件を満たすためには、最低でも683人の患者が必要です。選択肢の中で最も近い値は 690人 なので、正解は ③ です。