以下の統計検定2級®︎対策動画で用いられているスライドの一部です。
統計検定®2級対策オリジナル問題であり、非公式です。
※統計検定®は一般財団法人統計質保証推進協会の登録商標です。
問題:データ尺度について
次の4つの変数(A~D)について、それぞれのデータ尺度(名義尺度、順序尺度、間隔尺度、比例尺度)の組み合わせとして、最も適切なものを以下の①~⑤のうちから一つ選べ。
A. アンケート調査における満足度(「満足」「やや満足」「どちらでもない」「やや不満」「不満」)
B. 顧客に割り振られた会員番号
C. スマートフォンの画面の大きさ(インチ)
D. 歴史上の出来事が起こった西暦年
① A: 順序尺度, B: 名義尺度, C: 比例尺度, D: 間隔尺度
② A: 名義尺度, B: 順序尺度, C: 間隔尺度, D: 比例尺度
③ A: 順序尺度, B: 比例尺度, C: 比例尺度, D: 名義尺度
④ A: 間隔尺度, B: 名義尺度, C: 順序尺度, D: 間隔尺度
⑤ A: 順序尺度, B: 名義尺度, C: 間隔尺度, D: 比例尺度
【正解】 ①
ポイント解説:データ尺度とは?
この問題は、統計学の基本である 「データ尺度」 についての理解を問うています。
- データ尺度とは、データが持つ性質を分類するためのものです。
- 尺度を正しく理解することは、適切な統計分析手法を選ぶための第一歩です。
- 尺度には、大きく分けて4つの種類があります。
- 名義尺度
- 順序尺度
- 間隔尺度
- 比例尺度
ポイント解説:名義尺度・順序尺度
-
名義尺度
- 概要: データを単に分類・識別するためのラベルです。「男性/女性」「血液型」「背番号」のように、カテゴリを区別するためだけのもので、順序や大小関係はありません。
- 例: 会員番号「101」は会員番号「100」より偉いわけではありません。
-
順序尺度
- 概要: データ間に順序や大小関係が存在する尺度です。しかし、その間隔が等しいとは限りません。
- 例: 「満足度(満足 > やや満足)」「ランキング(1位 > 2位)」など。
ポイント解説:間隔尺度・比例尺度
-
間隔尺度
- 概要: 順序関係があり、かつ目盛りの間隔が等しい尺度です。ただし、 「絶対的な原点(ゼロ)」 が存在しません。足し算や引き算はできますが、掛け算や割り算はできません。
- 例: 「摂氏温度」「西暦」。摂氏20℃は10℃の「2倍暖かい」とは言えません。
-
比例尺度
- 概要: 間隔尺度の性質に加え、 「絶対的な原点(ゼロ)」 が存在する尺度です。四則演算のすべてに意味があります。
- 例: 「身長」「体重」「価格」。身長180cmは90cmの「2倍の高さ」と言えます。
なぜデータ尺度の理解が重要なのか?
データ分析を行う際、 どの統計量を計算し、どの分析手法を用いるかは、データの尺度によって決まります 。
【補足:リッカート尺度と実務上の扱い】
本問の満足度のような段階評価は リッカート尺度 と呼ばれ、厳密には 順序尺度 です。しかし実務分析では、「満足=5点, ..., 不満=1点」のように数値を割り当て、各段階の間隔が等しいと仮定して 「間隔尺度とみなして」平均値を計算する ことが慣習的に行われます。
このように本来の尺度と異なる扱いをする際は、その前提を理解し、結果の解釈に注意を払う必要があります。
解答の根拠
-
A: アンケート調査における満足度
- 「満足」から「不満」に順序関係はありますが、間隔は等しくありません。
- したがって、 順序尺度 です。
-
B: 顧客に割り振られた会員番号
- 顧客を識別するための単なるラベルで、数値の大小に意味はありません。
- したがって、 名義尺度 です。
解答の根拠
-
C: スマートフォンの画面の大きさ(インチ)
- 0インチという 「絶対的な原点」 が存在し、「8インチは4インチの2倍」のように比率にも意味があります。
- したがって、 比例尺度 です。
-
D: 歴史上の出来事が起こった西暦年
- 年と年の間隔は等しいですが、西暦0年は恣意的な基準点です。
- したがって、 間隔尺度 です。
以上のことから、「A: 順序尺度, B: 名義尺度, C: 比例尺度, D: 間隔尺度」という組み合わせが正しく、選択肢 ① が正解となります。
問題:記述統計量について
あるクラスの生徒20人を対象に実施した英語の小テスト(100点満点)の結果は以下の表の通りであった。
| 生徒番号 | 得点 | 生徒番号 | 得点 |
|---|---|---|---|
| 1 | 85 | 11 | 91 |
| 2 | 72 | 12 | 74 |
| 3 | 65 | 13 | 90 |
| 4 | 98 | 14 | 58 |
| 5 | 75 | 15 | 80 |
| 6 | 88 | 16 | 83 |
| 7 | 52 | 17 | 70 |
| 8 | 95 | 18 | 66 |
| 9 | 75 | 19 | 89 |
| 10 | 69 | 20 | 78 |
次の記述Ⅰ~Ⅲについて、このテスト結果のデータに関する記述として最も適切なものを、以下の①~⑤のうちから一つ選べ。
I. 得点の平均値は78.0点である。
II. 得点の中央値は76.5点である。
III. 得点の範囲(レンジ)は46点である。
① Ⅰのみが正しい。
② Ⅱのみが正しい。
③ ⅠとⅡが正しい。
④ ⅡとⅢが正しい。
⑤ Ⅰ, Ⅱ, Ⅲすべて正しい。
【正解】 ④
ポイント解説:記述統計量とは?
この問題は、データセットの基本的な特徴を要約する 「記述統計量」 の計算と理解を問うています。
-
代表値: データの中心を示す値
- 平均値、中央値など
-
散布度: データのばらつきを示す値
- 範囲、標準偏差など
記述統計量は、大量のデータを少数の指標で表現し、その全体像を把握するために用いられます。
ポイント解説:代表値
-
平均値
- 概要: データをすべて足し合わせ、データの個数で割った値。
- 注意点: 外れ値(極端に大きい、または小さい値)の影響を強く受けます。
-
中央値
- 概要: データを大きさの順に並べたときに、ちょうど中央に位置する値。
- 特徴: 外れ値の影響を受けにくく頑健な性質を持ちます。データの分布に偏りがある場合に有効です。
ポイント解説:散布度
-
範囲
- 概要: データの最大値と最小値の差。データがどのくらいの幅に散らばっているかを示す最も単純な指標です。
- 注意点: 両極端の2つの値だけで計算されるため、データ全体のばらつきを十分に表現できないことがあります。
なぜ記述統計量の理解が重要なのか?
データ分析の第一歩は、手元にあるデータがどのような特徴を持っているのかを理解することです。
- 平均値や中央値で データの中心的な傾向 を掴む。
- 範囲や標準偏差で データのばらつき具合 を把握する。
基本的な記述統計量でデータを要約し、その性質を把握することが、データドリブンな意思決定の出発点となります。
解答の根拠 (I. 平均値)
全20名の得点を合計します。
$$
合計 = 85+72+65+98+75+88+52+95+75+69+91+74+90+58+80+83+70+66+89+78 = 1553
$$
平均値は合計をデータ数で割って求めます。
$$
平均値 = 1553 / 20 = 77.65点
$$
したがって、記述Ⅰ「得点の平均値は78.0点である」は 誤り です。
解答の根拠 (II. 中央値)
まず、20個のデータを小さい順に並べ替えます。
52, 58, 65, 66, 69, 70, 72, 74, 75, 75, 78, 80, 83, 85, 88, 89, 90, 91, 95, 98
データ数は20(偶数)なので、中央に位置する10番目と11番目の値の平均が中央値となります。
中央値 = (10番目の値 + 11番目の値) / 2
= (75 + 78) / 2 = 76.5点
したがって、記述Ⅱ「得点の中央値は76.5点である」は 正しい です。
解答の根拠 (III. 範囲と結論)
範囲は最大値と最小値の差で求めます。
- 最大値 = 98点
- 最小値 = 52点
範囲 = 98 - 52 = 46点
したがって、記述Ⅲ「得点の範囲は46点である」は 正しい です。
以上の結果から、正しい記述はⅡとⅢです。よって、選択肢 ④ が正解となります。
問題:箱ひげ図の解釈について
ある企業が、A支社とB支社の営業担当者の月間契約件数を比較するために、それぞれの支社から無作為抽出した50人ずつのデータを用いて箱ひげ図を作成した。
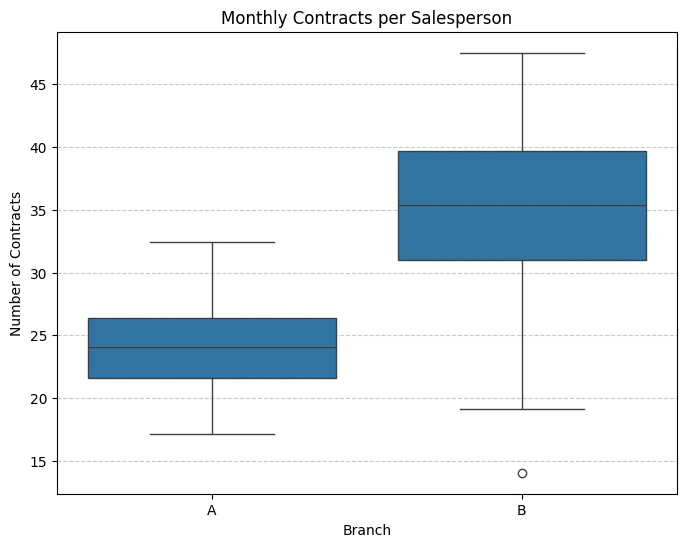
この箱ひげ図に関する次の記述Ⅰ~Ⅲについて、最も適切なものを以下の①~⑤のうちから一つ選べ。
I. 月間契約件数の中央値は、B支社の方がA支社よりも高い。
II. データのばらつきを四分位範囲で評価すると、A支社の方がB支社よりも大きい。
III. A支社のデータの上位25%(第3四分位数以上の値)は、すべてB支社の中央値を下回っている。
① Ⅰのみが正しい。
② Ⅱのみが正しい。
③ ⅠとⅢが正しい。
④ ⅡとⅢが正しい。
⑤ Ⅰ, Ⅱ, Ⅲすべて正しい。
【正解】 ③
ポイント解説:箱ひげ図とは?
この問題は、データの分布を視覚的に要約する 「箱ひげ図」 を正しく読み解く能力を問うています。
- 複数のデータグループの分布を簡潔に比較するのに非常に便利なグラフです。
- 以下の5つの要約統計量(五数要約)と関連指標を表現しています。
- 中央値
- 第1四分位数 (Q1)
- 第3四分位数 (Q3)
- 四分位範囲 (IQR)
- ひげ(データの広がり)
ポイント解説:箱ひげ図の構成要素
-
中央値
- 図での表現: 箱の中の横線。
- 意味: データの中心的な位置。
-
第1四分位数 (Q1)
- 図での表現: 箱の下辺。
- 意味: データの下から25%の位置。
-
第3四分位数 (Q3)
- 図での表現: 箱の上辺。
- 意味: データの上から25%の位置。
-
四分位範囲 (IQR)
- 図での表現: 箱の高さ (Q3 - Q1)。
- 意味: データの中央50%のばらつき。
なぜ箱ひげ図の理解が重要なのか?
箱ひげ図は、データ分析の現場で頻繁に用いられる基本的な可視化手法の一つです。一枚の図で多くの情報を得ることができます。
- データの中心はどこか( 中央値 )
- どのくらいばらついているか( 四分位範囲 )
- 分布は対称か、歪んでいるか
- 外れ値はあるか
特に、複数のグループのデータを比較する際に、それぞれの分布の特徴をひと目で比較できるため、データから洞察を得るための強力な武器となります。
解答の根拠 (I. 中央値)
- グラフの 箱の中の線 (中央値)の位置を比較します。
- B支社の箱の中の線は、A支社の線よりも高い位置(約35)にあります。
- これは、B支社の月間契約件数の中央値がA支社よりも高いことを示しています。
したがって、記述Ⅰは 正しい です。
解答の根拠 (II. ばらつき)
- データのばらつきは、 箱の高さ (四分位範囲)で比較します。
- A支社の箱の高さは、B支社の箱の高さよりも明らかに小さい(短い)です。
- これは、A支社のデータの方がばらつきが小さいことを意味します。
したがって、記述Ⅱ「A支社の方がB支社よりも大きい」は 誤り です。
解答の根拠 (III. 上位25%の比較)
- A支社の上位25%とは、第3四分位数(箱の上辺)から最大値(ひげの上端)までのデータ群を指します。
- グラフから、A支社のデータの最大値(ひげの上端)は 約32.5 の位置にあります。
- 一方、B支社の中央値(箱の中の線)は 約35 の位置にあります。
- A支社のデータの最大値ですらB支社の中央値を下回っています (
32.5 < 35)。
したがって、「A支社のデータの上位25%は、 すべて B支社の中央値を下回っている」という記述は 正しい です。
以上の検討から、正しい記述はⅠとⅢです。よって、選択肢 ③ が正解となります。
問題:ポアソン分布について
あるウェブサイトのサポート窓口には、1時間あたり平均して6件の問い合わせがポアソン分布に従って発生することが分かっている。
このとき、次の1時間に問い合わせがちょうど4件発生する確率として、最も近い値を以下の①~⑤のうちから一つ選べ。
ただし、$e^{-6} \approx 0.00248$ とする。
また、平均 $\lambda$ の事象が $k$ 回発生するポアソン分布の確率は、$P(X=k) = \frac{e^{-\lambda} \lambda^k}{k!}$ で与えられる。
① 0.054
② 0.089
③ 0.134
④ 0.156
⑤ 0.182
【正解】 ③
ポイント解説:ポアソン分布とは?
この問題は、代表的な離散確率分布の一つである 「ポアソン分布」 に関する理解と計算能力を問うています。
- ポアソン分布は、「 ある一定の期間や範囲において、ある事象が平均して何回起こるかが分かっているときに、実際にその事象が特定の回数(k回)起こる確率 」をモデル化する確率分布です。
- この「事象」は、互いに独立して、ランダムなタイミングで発生する必要があります。
ポイント解説:ポアソン分布の具体例
- 1時間にかかってくる電話の件数
- ウェブサイトへの1分間のアクセス数
- 1ページあたりの誤字の数
- 1日に特定の交差点で起こる交通事故の件数
など、現実世界の多くのランダムな現象をモデル化するために広く使われています。
ポイント解説:確率を計算する式
ポアソン分布に従う確率変数 $X$ が値 $k$ をとる確率 $P(X=k)$ は、以下の式で計算されます。
$$
P(X=k) = \frac{e^{-\lambda} \lambda^k}{k!}
$$
- $\lambda$ (ラムダ): 単位期間あたりの事象の 平均発生回数
- $k$: 実際に事象が発生する 回数 (求めたい確率の対象)
- $e$: ネイピア数(自然対数の底、約2.718)
- $k!$: $k$の階乗(例: $4! = 4 \times 3 \times 2 \times 1 = 24$)
なぜポアソン分布の理解が重要なのか?
ポアソン分布は、ビジネスの現場でリソース配分の最適化問題(待ち行列理論)などに応用されます。
例:コールセンターのオペレーターを何人配置すればよいか?
スーパーのレジをいくつ開ければ行列が長くなりすぎないか?
このように、ランダムに発生する事象の確率を定量的に評価するための強力なツールであり、データに基づいた予測や意思決定を行う上で非常に重要です。
解答の根拠 (1. パラメータの特定)
問題文の数値をポアソン分布の公式に当てはめます。
-
平均発生回数 $\lambda$
- 1時間あたりの平均問い合わせ件数は6件です。
- $\lambda = 6$
-
発生させたい回数 $k$
- 求めたいのは、「ちょうど4件」発生する確率です。
- $k = 4$
解答の根拠 (2. 計算の実行)
確率の公式に $\lambda=6$ と $k=4$ を代入します。
$$
P(X=4) = \frac{e^{-6} \cdot 6^4}{4!}
$$
各項を計算します。
- $e^{-6} \approx 0.00248$ (問題で与えられた近似値)
- $6^4 = 6 \times 6 \times 6 \times 6 = 1296$
- $4! = 4 \times 3 \times 2 \times 1 = 24$
解答の根拠 (3. 結論)
これらの値を式に戻して計算します。
$$
P(X=4) \approx \frac{0.00248 \times 1296}{24}
$$
$$
P(X=4) \approx \frac{3.21408}{24}
$$
$$
P(X=4) \approx 0.13392
$$
計算結果は約 0.134 となり、選択肢の中で最も近い値です。したがって、正解は ③ となります。