サクッと標準化したいけど、ごちゃごちゃした解説はいらないよ〜という人向けに、お手軽で実装できる標準化の方法を書いてみました。
#1. StandardScalerとは
機械学習によく使われるライブラリであるscikit-learnの中に入っている標準化のためのクラスです。
JupyterNotebookやGoogleCollaboratoryを使う場合にはscikit-learnをimportするだけで使えますが、ローカルな環境で機械学習を動かすときには事前にインストールしておきましょう。
$ pip install scikit-learn
#2. 標準化とは?【1分でわかるように解説】
機械学習モデルに食べさせるデータは、そのままだと大きさがバラバラすぎて上手に食べてくれません。そこで、標準化を行って機械学習が食べやすいサイズに加工してあげる必要があります。
たとえば、身長と体重のデータがあるとします。身長は150~185。体重は40~100くらいに収まるとします。
そのとき、機械はより見た目の数字が大きい身長の方が大事なデータだと勘違いして、体重を軽視して学習してしまいます。アホの子っぽくてかわいいですね。
なので、標準化を行って身長も体重も同じくらいの大きさに加工してあげる必要があります。
具体的には、標準偏差を1にしてデータのサイズ感を統一します。
#3. お手軽な標準化のやり方
###◎下準備編
これを読んでいる皆さんは、分析したいデータを放り込んでください。
私はscikit-learnにもともと含まれているデータセットiris(アヤメの花の品種)を読み込んで、pandasでデータフレームに変換します。
データセットの中にカテゴリ変数が含まれているとエラーを吐いてくるので、以下のサイトなどを参照してあらかじめダミー変数にしておきましょう。(例:[Yes, No, Yes]→[1, 0, 1])
【参考:『機械学習でのカテゴリデータの扱い方』 https://qiita.com/QUANON/items/08a65012366abd150172 】
import sklearn
import pandas as pd
from sklearn.datasets import load_iris
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df.describe()
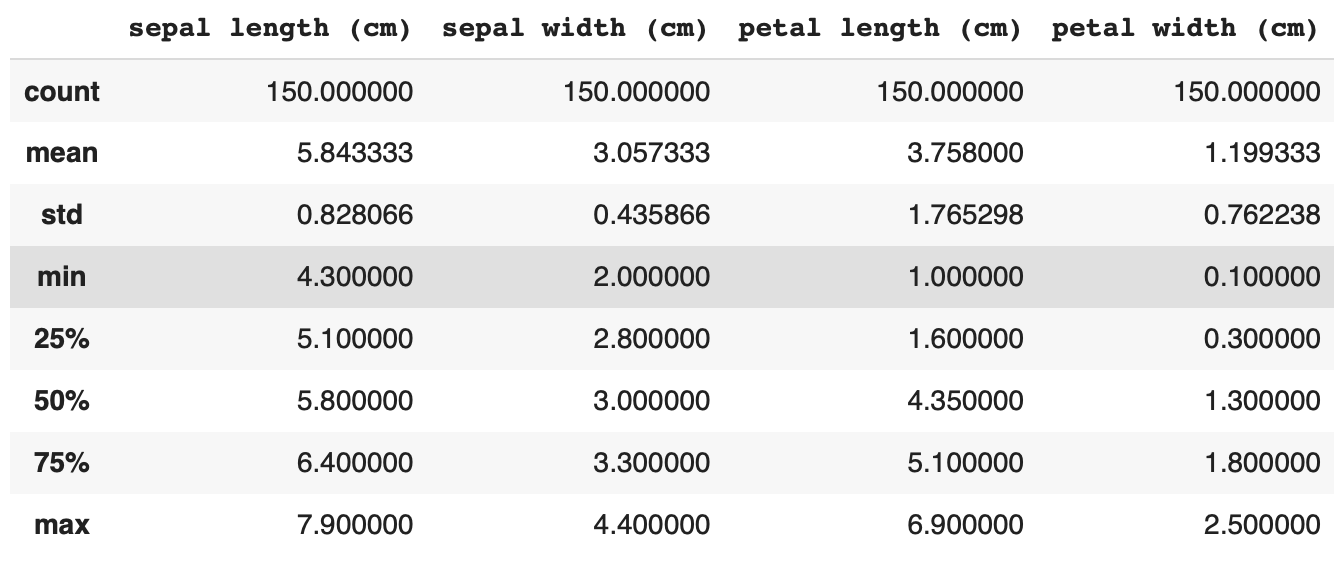
###◎実践編
いよいよ標準化です。
まず、scikit-learn(sklearn)のpreprocessingモジュールからStandardScalerをインポートします。
次に、std_scalerにStandardScalerインスタンスを生成。
std_scaler.fitでインスタンスがデータフレームを扱えるように適応してくれます。
最後にstd_scaler.transformで標準化して、pd.DataFrameでデータフレーム型にしてしまえば完成です!簡単!
from sklearn.preprocessing import StandardScaler
std_scaler = StandardScaler()
std_scaler.fit(df)
df_std = pd.DataFrame(std_scaler.transform(df), columns=df.columns)
df_std.describe()
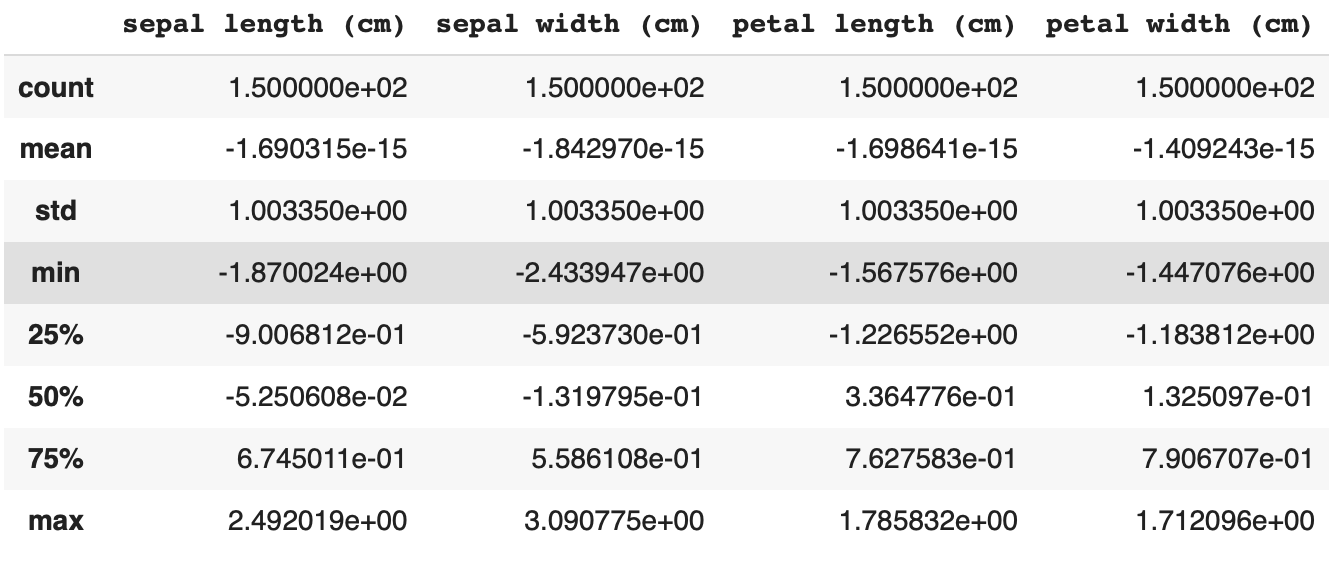
stdの行がすべて同じ数字になっているのを確認できたら標準化は完璧!!
説明がよくわからなかったら「df」と書いてある部分を全部ご自分のデータフレームが入った変数名に書き換えて使ってみましょう。
ね? 脳死で出来たでしょう?
##参考
この記事は以下のサイトを参考にして書きました。
非常に参考になる記事なので、ぜひこちらも見ていってください。
【1】…………『Scikit-learnで標準化をする時にStandardScalerを使ってみた話』, EnsekiTTTさん, https://ensekitt.hatenablog.com/entry/2018/08/08/200000
【2】…………『How and why to Standardize your data: A python tutorial』, Serafeim Loukas, https://towardsdatascience.com/how-and-why-to-standardize-your-data-996926c2c832