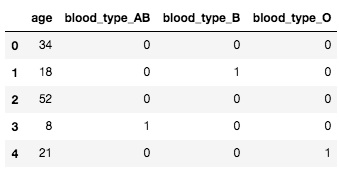
例えば次のような DataFrame があるとする。
import pandas as pd
df = pd.DataFrame(data={'age': [34, 18, 52, 8, 21], 'blood_type': ['A', 'B', 'A', 'AB', 'O']})
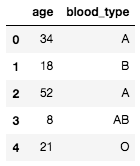
機械学習の特徴量として 'A' や 'B' などのカテゴリデータを表す文字列をそのまま与えることはできない。では、これらを整数値に置き換えればいいだろうか。カテゴリデータを整数値に置き換えるには pandas.factorize を使う。
df['blood_type'] = pd.factorize(df['blood_type'])[0]
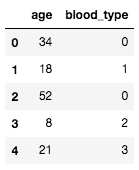
実はこれはよくない。この例では 'A' は 0 に、'B' は 1 に、そして 'O' は 3 に置き換えられている。ここで、例えば「A 型から O 型への距離は A 型から B 型への距離の 3 倍である」というような関係はない。しかし、機械学習アルゴリズムはそのような関係があると誤解してしまう恐れがある。
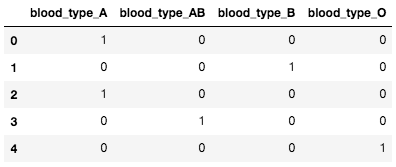
ではどうしたらよいか。ここで使えるのが ダミー変数 だ。ダミー変数に変換するとはカテゴリデータを one-hot 表現に変換することだ。そして one-hot 表現とはひとつの要素が 1 でその他が 0 のベクトルで表すことだ。ダミー変数に変換するには pandas.get_dummies を使う。
df2 = pd.get_dummies(df['blood_type'], prefix='blood_type')
ちなみに情報を失わずに 1 列だけ削減することができる。
df2 = pd.get_dummies(df['blood_type'], prefix='blood_type', drop_first=True)
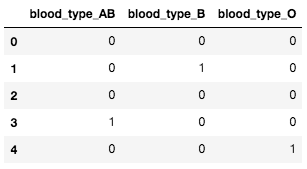
最終的に blood_type 列をダミー変数に置き換えた DataFrame は次の通り。
df3 = df.drop('blood_type', axis=1)
df4 = pd.merge(df3, df2, right_index=True, left_index=True)
df4