このページは、以前投稿した「Hinemos ver.6.2をAWS上にインストールして監視するまで(初期設定編)の続きになります。
(だらだら書いてたら前回から1年近く経ってしまった。。。)
そちらでは、Hinemosの初期設定方法をまとめていますので、そちらも見てみてください。
Hinemos ver.6.2 をAWS上にインストールして監視するまで(初期設定編)
このページで実施すること
このページでは、主に下記の内容をまとめます。
- 監視対象マシンの登録
- リソース監視をするために必要な設定
- リソース監視とメール通知設定
前提知識として、SNMP(Simple Network Management Protocol)というプロトコルについて概要だけでも理解していた方が良いと思います。
また、メール通知をするために必要な設定は前の記事で解説しているので、そちらを参照してください。
設定をする前に
今回AWS上で監視対象とするマシン(Ubuntu)のNet-SNMPの設定をします。
AWS上で監視対象のインスタンスに対して、下記のインバウンド設定がされていないと、正常に設定ができないので注意してください。
| ポート番号 | TCP or UDP | 用途 | 備考 |
|---|---|---|---|
| 161 | UDP | リソース監視、プロセス監視、SNMP監視のため |
監視対象マシンの登録とリソース監視のための準備
今回は、監視対象マシンとしてUbuntuのEC2インスタンスを利用します。
とはいえ、RHEL系OSでもやることはほぼ同じ(ファイルパスは微妙に違うかも)なので、参考としてもらえればと思います。
Net-SNMPの設定
Hinemosは一部の監視でSNMPを利用します。
なので、監視対象のマシンにHinemosマネージャとSNMP通信ができる様に設定をあらかじめする必要があります。
SNMPとは?
SNMP(Sinmple Network Management Protocol)のめちゃくちゃ大雑把に概要を説明すると、主にNW機器のステータス(CPU使用率やプロセス稼働状況)などを管理するためのプロトコルです。OID(Object ID)をリクエストで渡すことで、そのOIDに対応した値を返却するものになります。
OIDは「どの機器に対しても共通で利用できるもの(標準MIB)」と「特定のベンダーの製品だけで利用できるもの(拡張MIB)」が存在します。
※本ページではMIB(Management Information Base)についての説明は省きます。詳細はこの辺を見ると分かりやすかもしれません
例えば、「CPU使用率」を求めるOID(.1.3.6.1.2.1.25.3.3.1.2)をリクエスト送信すると、リクエストを受け取ったマシンがCPU使用率をレスポンスで返してくれます。そのほかにも、起動中プロセスの一覧を取得することもできます。
Net-SNMPの設定例
SNMPでは、不特定多数のマシンからのアクセスを抑制するために、「コミュニティ名」を設定します(デフォルトは「public」)。
厳密には違いますが、コミュニティ名は相手のマシンの情報を取得するための簡易パスワードのようなものだと思えば良いかなと思います。
※SNMPv2cまでは通信時の認証機能はありませんでしたが、SNMPv3からちゃんとした認証機能が追加されています。
下記はSNMPバージョン「2c」、コミュニティ名「testCom」を設定する例です。
詳しくは、別の方がとても詳しく解説されているので、 そちらをご覧ください。
net-snmpの設定
# コミュニティ名「testCom」、SNMPバージョン2cでSNMP通信するための設定例
# これらを任意の場所に追記する
com2sec notConfigUser default testCom
group testGroup v2c notConfigUser
# リソース監視をするため、先頭.1.3.6.1(標準MIB)で始まるOIDのリクエストを許可
view systemview included .1.3.6.1
access testGroup "" v2c noauth exact systemview none none
上記の設定を追記したら、snmpdを再起動しましょう。
service snmpd restart
監視対象マシンの登録
監視対象マシンをHinemosマネージャ上に登録します。
監視対象のマシンを管理するのは、「リポジトリ」パースペクティブになるので、画面左上から「パースペクティブ」>「リポジトリ」の順番で選択しましょう。
なお、パースペクティブとは、Hinemosの機能ごとにまとめた画面を指します。
今回の場合、監視対象マシンを登録したりする「リポジトリ機能」を利用するため、「リポジトリ」パースペクティブを開きました。あとで、監視設定を行うため、「監視設定」パースペクティブを開きます。
また、似た言葉で「ビュー」という言葉が出ますが、これはパースペクティブ内の小画面のことを指します。
図にすると下の様な感じです。下の図の場合、パースペクティブの中に3つのビューが同時に表示されていることがわかります。
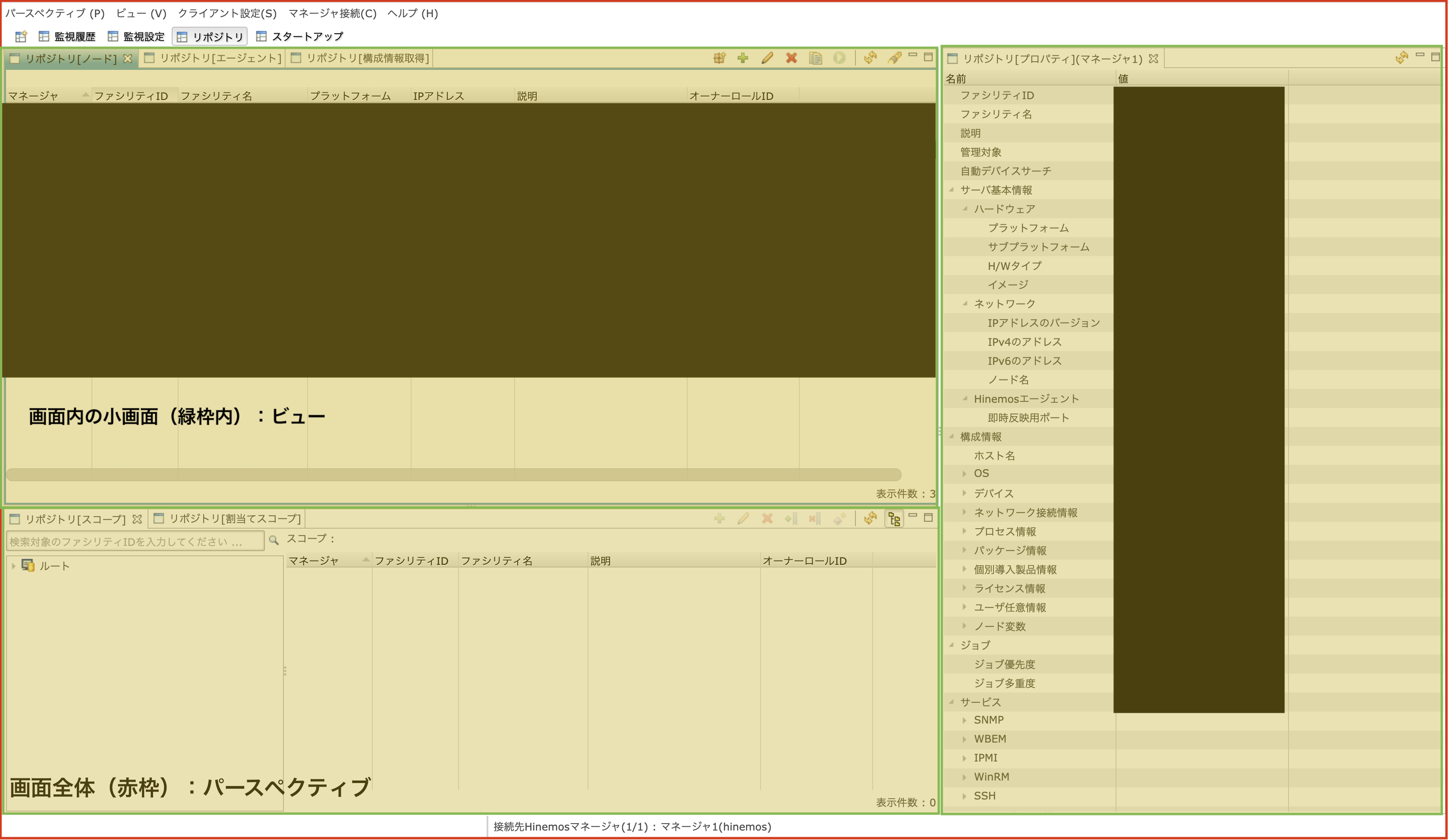
では、「リポジトリ(ノード)」ビューの右上にある「+」のアイコンをクリックして、実際に監視対象のマシンを追加してみましょう。

すると、下の様な監視対象のマシンを追加するためのダイアログが出力されます。ここで、少し便利な「デバイスサーチ機能」(下画像の上側の赤枠)を利用して、マシンを登録しましょう。
これは、SNNPリクエストを指定したIPアドレスのマシンに送信し、応答内容から登録に必要な情報を抽出して自動入力する機能です。監視対象マシンのIPアドレスとNet-SNMPで設定したコミュニティ名とバージョンを指定してSearchを押すと、登録に必要な情報を自動入力してくれます。
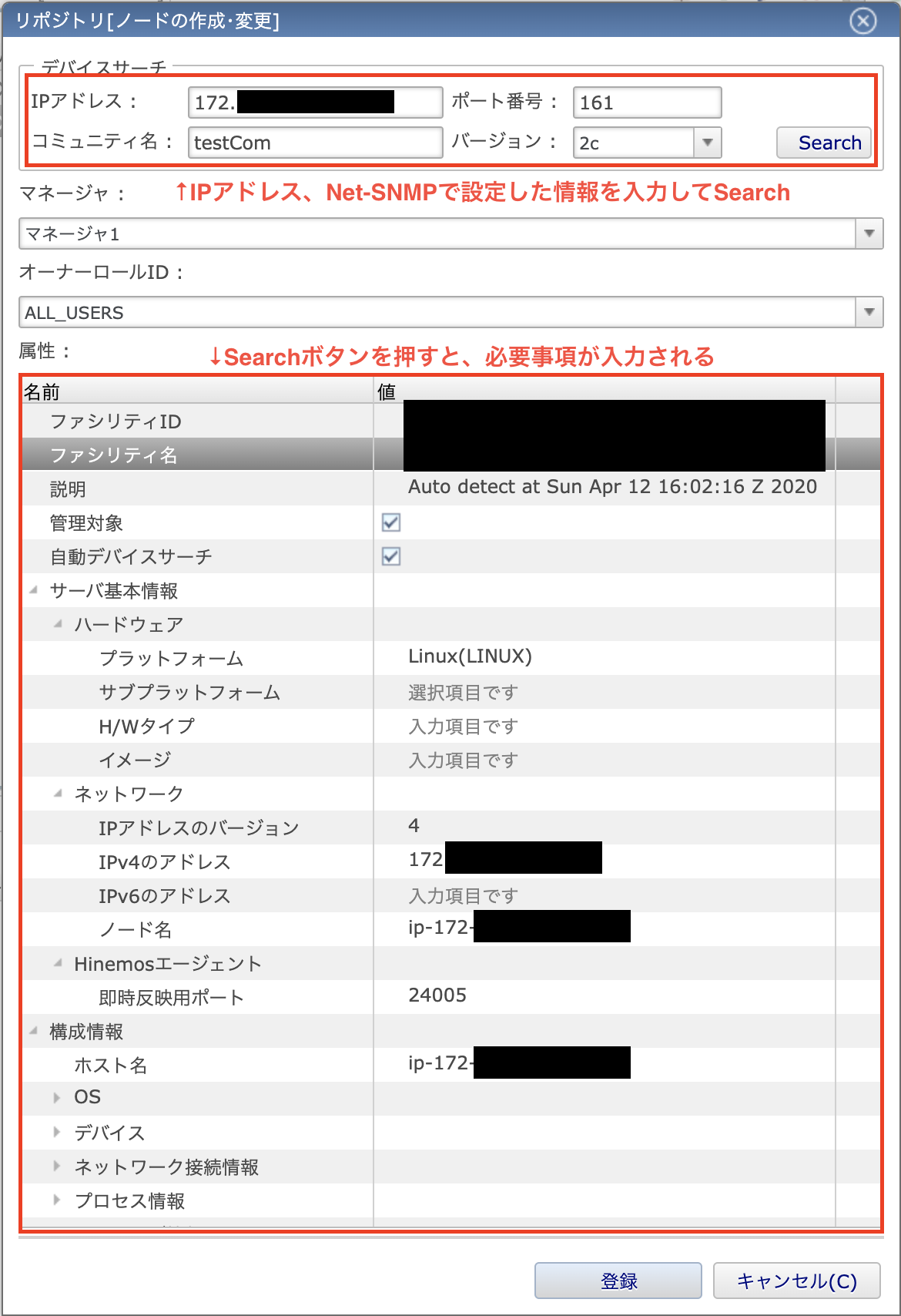
マシン登録の注意点(ファシリティID)
デバイスサーチ機能を使ってマシンを登録するとき、1点だけ注意する必要があります。
デバイスサーチ機能を使った場合、ファシリティID(Hinemosマネージャ内で一意の監視対象マシンのID)は「マシンのホスト名」になります。
ホスト名が同じマシンを複数登録する場合、2つ目以降のマシンはファシリティIDが重複するので登録ができません。その時は、ホスト名を変更するか、手動でファシリティIDを変更する必要があります。
スコープの設定
監視対象マシンの登録ができたら、今度はスコープの登録と割り当てを行いましょう。
スコープとは、監視を行う対象のグループのことを言います。
Hinemosではスコープは複数作成して、階層構造を持たせることができますし、監視対象のマシンも複数のスコープに所属することができます。
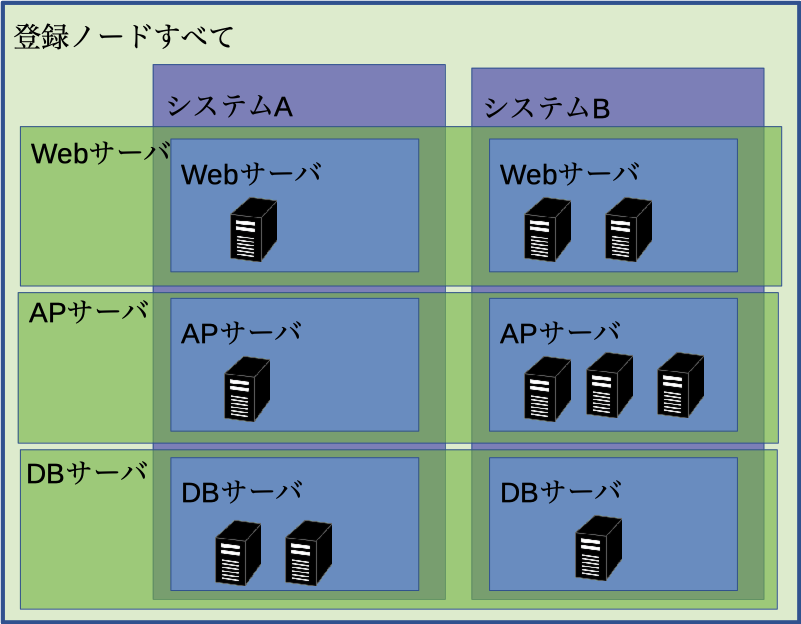
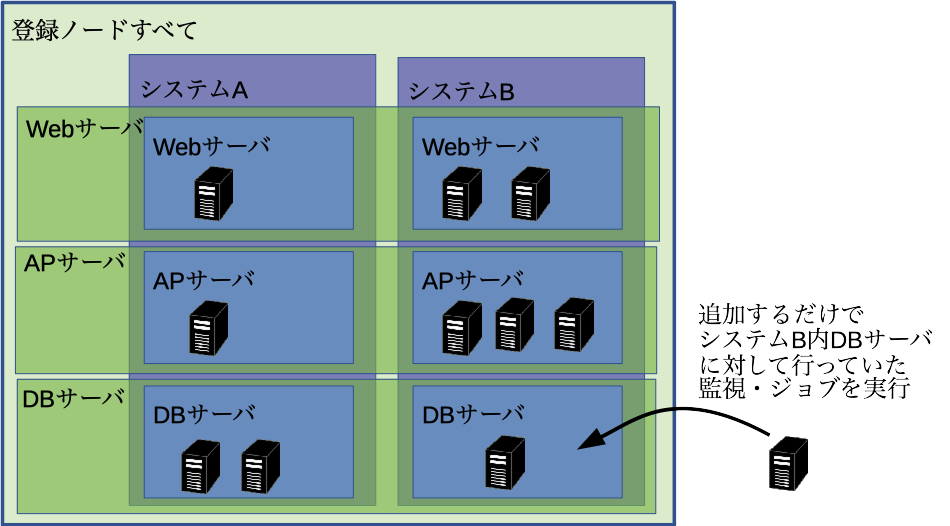
上記の図を例にすると、Hinemosに管理されている一番大きなスコープ「登録ノードすべて」があり、その中にHinemosが管理している「システムA(B)」スコープがあり、さらにその中にそれぞれ「Webサーバ」「APサーバ」「DBサーバ」といった感じで階層構造別にスコープを作成し、そこに該当するマシンを登録することができます。また、システムをまたいで監視やジョブを実行したい場合は、それに加えてシステムを跨ぐようなスコープ(上図だと、横に伸びている半透明緑色の四角)を定義することも可能です。
監視・ジョブはマシン単体を対象に指定することももちろんできますし、スコープを監視対象に選ぶことができます。あらかじめスコープを監視・ジョブ実行対象としておけば、同じ監視をさせたいマシンが増えた時に対象のスコープにマシンを追加するだけで、監視設定を変更することなく同じ監視を行うことができます。
スコープの設定は、リポジトリパースペクティブの(デフォルトでは)下部分に表示されている「スコープ」ビューで行います。
スコープを作成する際によく混乱するのですが、まずは左側のツリーからスコープを作成したい先の親スコープを選択しないと作成ボタン(+アイコン)が有効化しません。
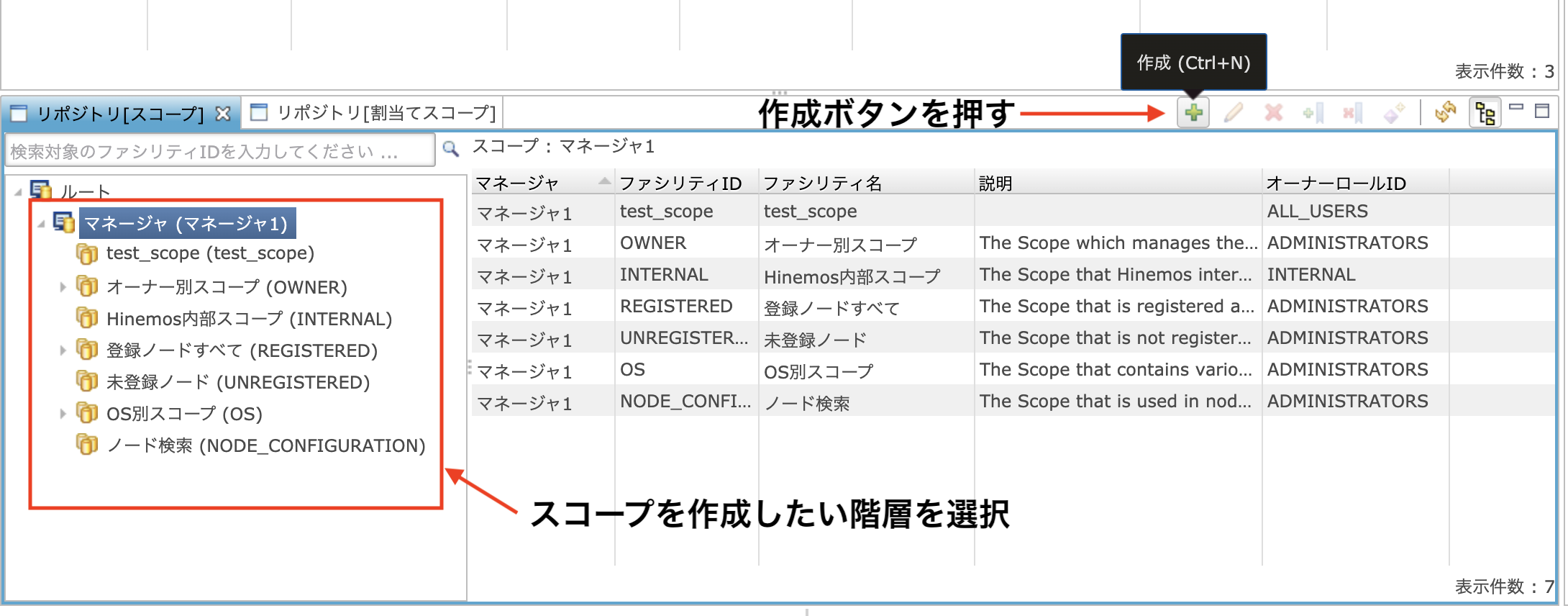
スコープのファシリティIDとスコープ名を決めて「OK」を押すと、スコープを作成することができます。
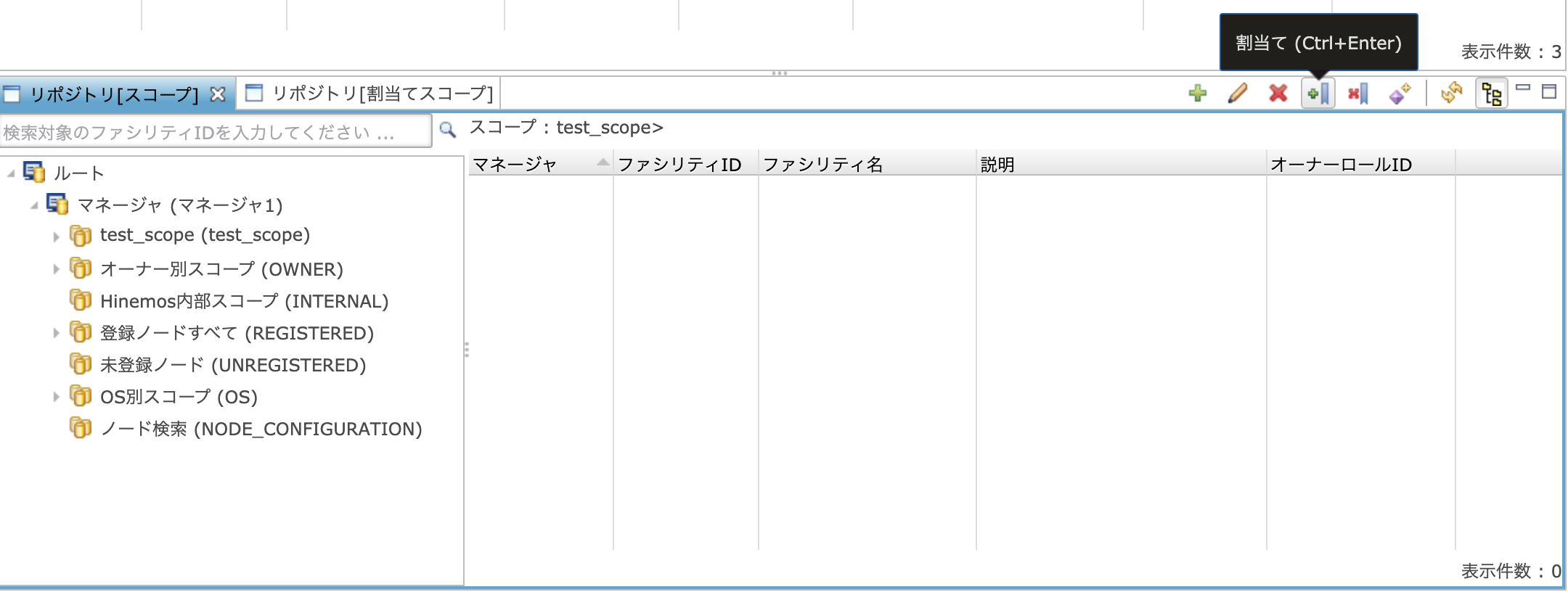
スコープを作成したら、次はそのスコープにマシンを割り当てます。
(これも左側のツリーから割り当てをしたいスコープを選択してから「割当て」ボタンをクリックします。
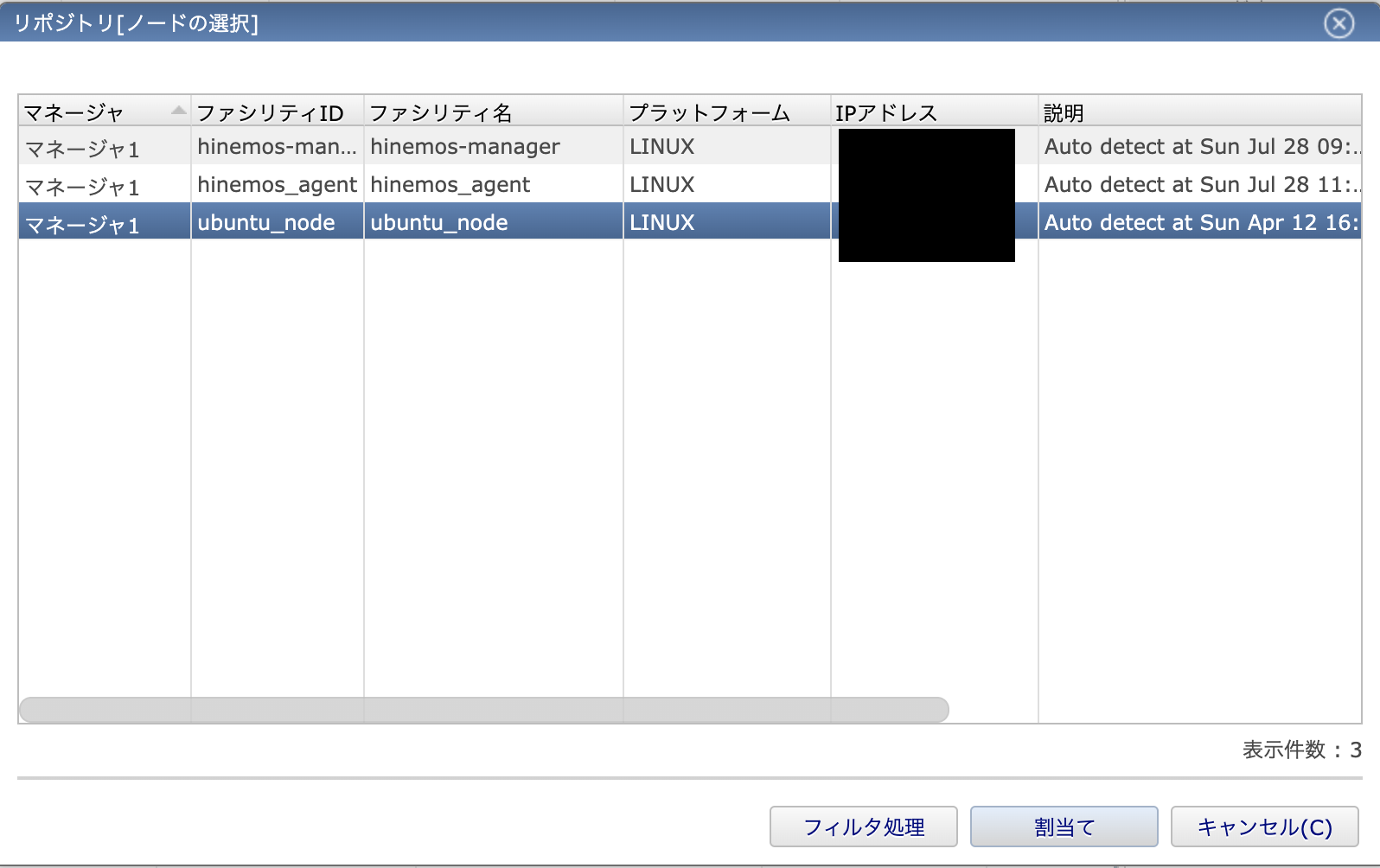
すると、割り当て可能なマシンの一覧が表示されるので割り当てたいマシンを選択(複数選択したい場合はCtrlキーを押しながら選択)して「割当て」ボタンをクリックして完了です。
リソース監視の設定
今回は例として、5分おきにファイルシステム使用率を監視し、ファイルシステム使用率が90%超えた時に1時間おきにメールで通知する仕組みを作ります。
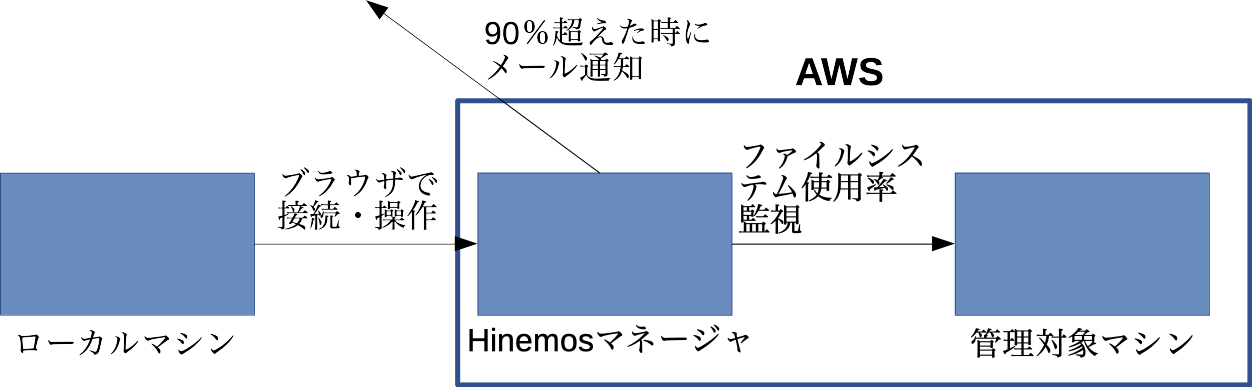
「1時間おきにメール通知する」という設定根拠ですが、あまりにも頻繁にメールが来ると、たとえものすごく重要なメッセージでも運用者は鬱陶しくなって通知を見なくなるからです。
メール通知するのはメール通知するに足る内容かつ適切な頻度であることが重要だと考えます。
上の仕組みを作るにあたって、行う作業は下記になります。
- メールテンプレートの作成
- メール通知の作成
- リソース監視(ファイルシステム使用率)の作成
メールテンプレートの作成
まずは、メール通知をするためのテンプレートを作成します。
テンプレートは、「ファイルシステム使用率がしきい値を超えた時に利用するもの」を作成します。
「監視設定」パースペクティブの「メールテンプレート」ビューを開き、右上の「+」アイコンをクリックして、メールテンプレート作成ダイアログを開きます。

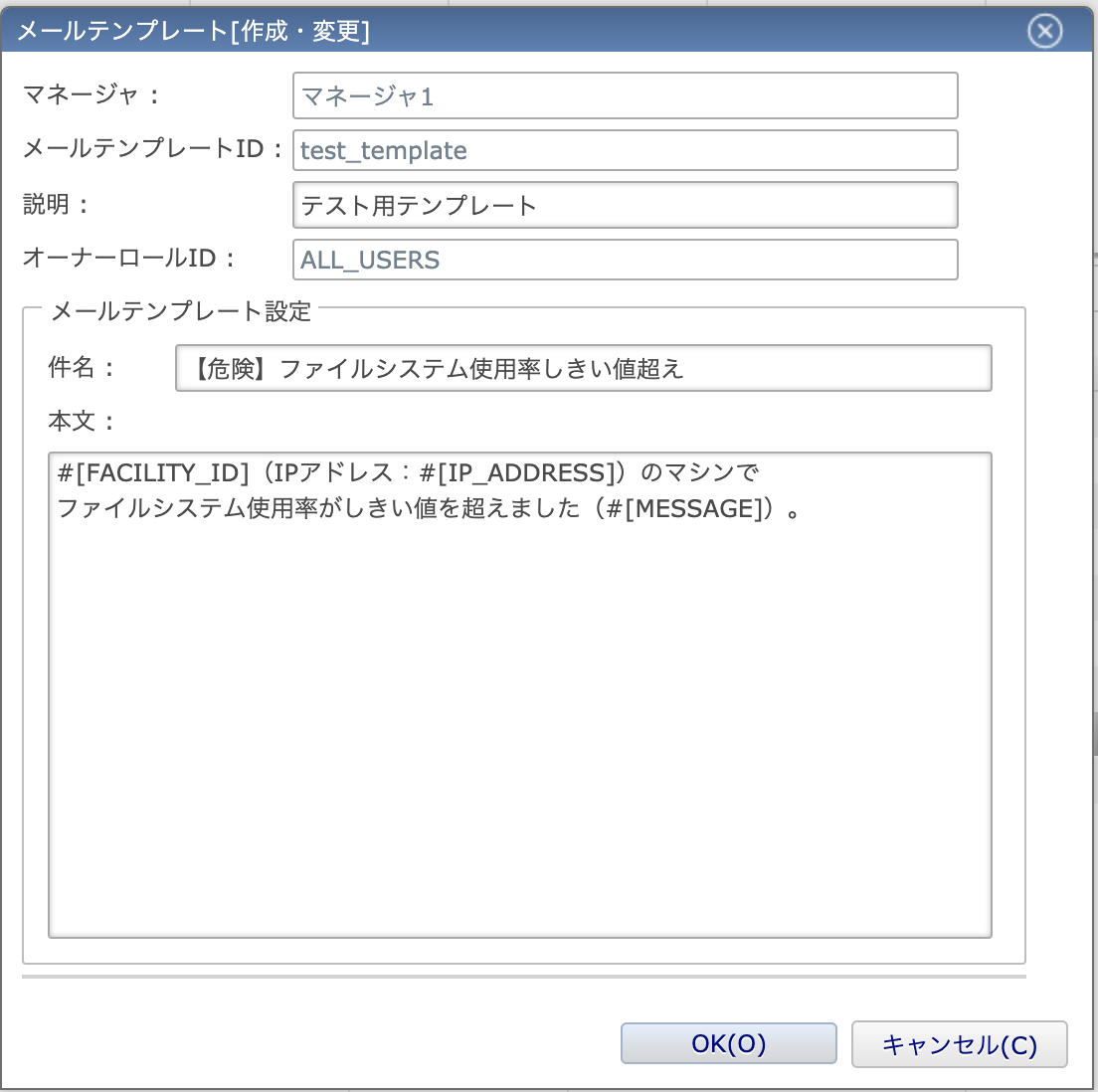
メールの本文はお試しで(1)どのマシンの(2)どのファイルシステムが(3)使用率何パーセントになっているのか、の3点がわかるような本文とします。
メール本文中には変数を使用することができ、変数は#[変数名]で呼び出すことができます。
下の画像の通り本文を設定することで、メール本文中にファシリティID(Hinemosマネージャ内で一意に決まる監視対象マシンのID)、IPアドレス、実際にしきい値を超えたファイルシステムと現在のファイルシステム使用率を埋め込むことができます。
どんな変数が利用できるかは、本文のところでマウスオーバーするとポップアップで一覧が出てきます。
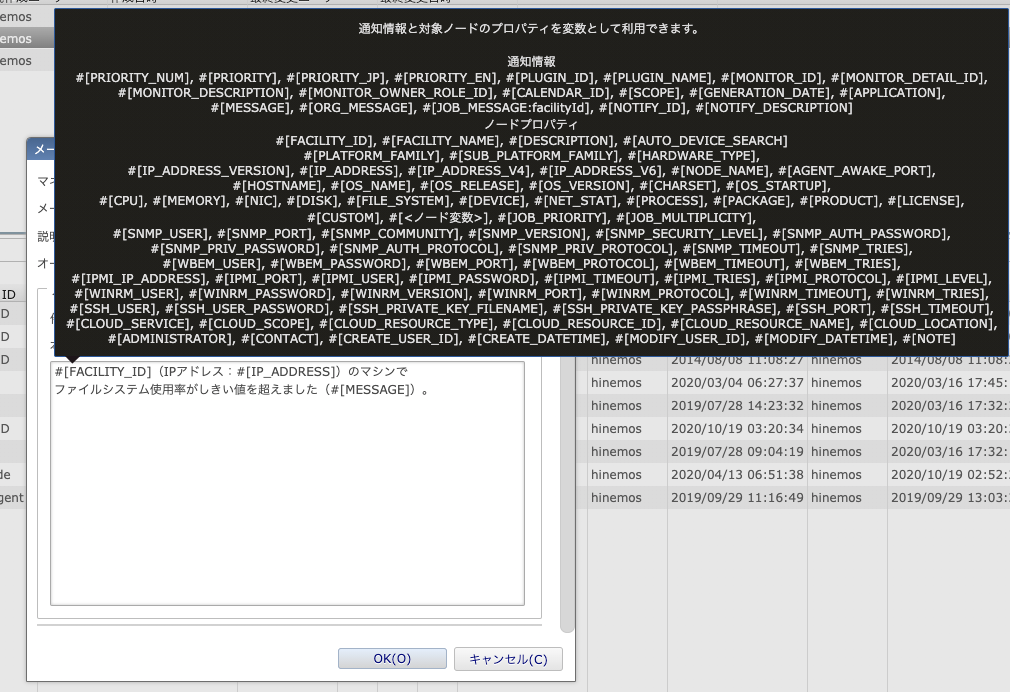
それぞれの変数や使い方はマニュアルを参照してください。
メール通知の設定
では次に、前節で設定したメールテンプレートを利用したメール通知の設定をします。今回は、監視結果が「危険」になった場合、メール通知するよう設定をします。
※監視の重要度については、重要度の種類と「不明」についてで解説します。
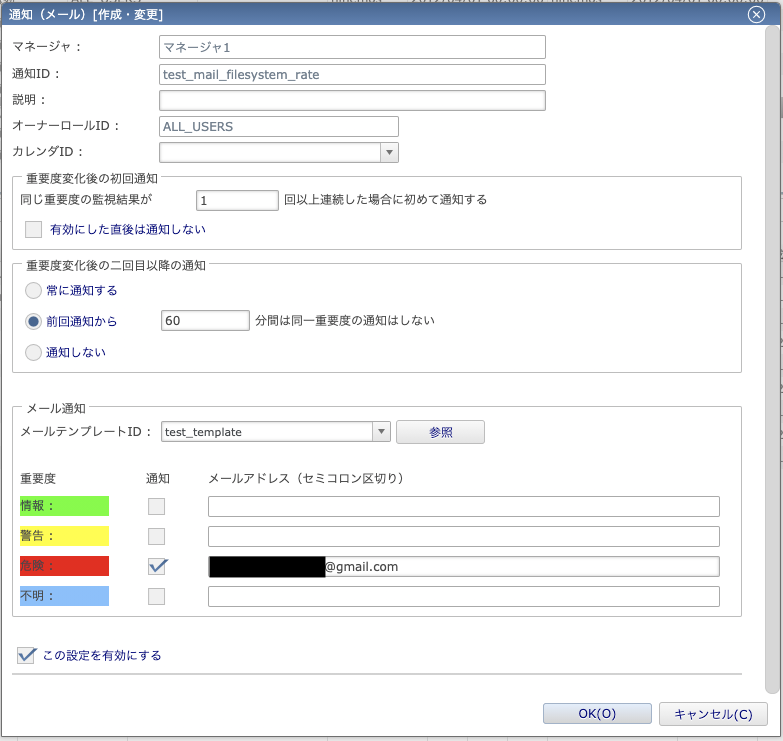
通知IDと説明は、何の通知なのかをわかりやすくしておくとあとで管理しやすいです。
ここで注目するべき内容は、「重要度変化後の初回通知」と「重要度変化後の二回目以降の通知」でしょうか。
重要度変化後の初回通知
ここは記載がある通り、同じ重要度の監視結果が指定回以上連続した場合にだけ通知をする(メール通知の場合は、メール送信をする)という設定になります。
CPU使用率やメモリ使用率のように、「瞬間的に100%になったりする」ことがある監視の場合に2以上の数値を指定します。
重要度変化後の二回目以降の通知
ここは、前述の初回通知の後に同じ監視結果が連続した場合にどう扱うか、という設定です。
下記の3種類が指定できます。
- 常に通知する:同じ監視結果が続く限りずっと通知し続ける
- 前回通知から●●分間は同一重要度の通知はしない:文字通り、指定した時間の間同じ監視結果が続いている限り通知しない(指定時間中に違う監視結果が発生した場合はリセットされる)
- 通知しない:前回通知した監視結果とは別の監視結果となるまで通知を一切しない
基本的には「常に通知する」でいいと思いますが、「メール通知」は頻繁にメールがきた場合、鬱陶しくて見なくなってしまいます。
なので、ある程度ここの設定でメール送信を抑制した方が良いと個人的に思います。
上記の通知抑止設定まで行ったら、あとは先ほど作成したメールテンプレートを「メールテンプレートID」のプルダウンメニューから選択し、重要度別に通知する or しない設定とメール送信先のメールアドレスを指定するだけで完了です。
ステータス通知の作成
メール通知の設定だけでは、正しく動作していた場合(ファイルシステム使用率がしきい値範囲内だった場合)に何も通知されず、正しく動いているのかわからないので、確認用にステータス通知も定義します。
ステータス通知は、各監視の最新結果だけをHinemosクライアント上に表示させる通知設定です。
最新結果だけを表示するので、過去の監視結果は常に最新に更新され、履歴は残りません。
先ほどメール通知の設定ダイアログを開いたのと同じ要領で、今度は「ステータス通知」を選択肢てダイアログを開きます。
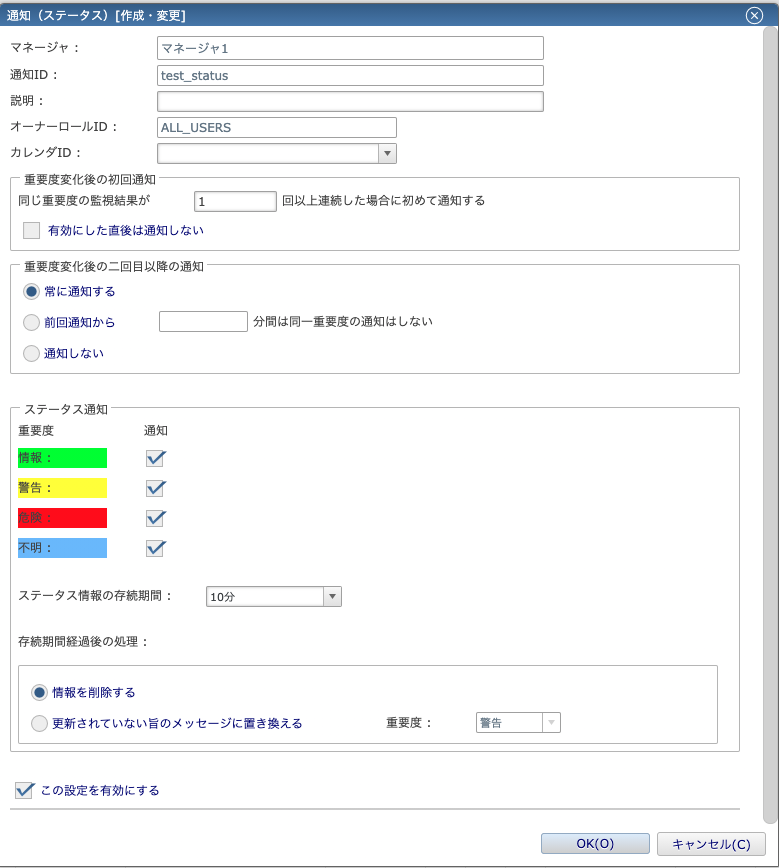
ステータス通知の設定ダイアログは、上半分の部分は上記で解説した内容と全く同じになります。
下半分は、どの重要度の時に通知する(画面に表示する)かと、画面に表示し続ける時間を設定します。
残りは画面に記載されている通りの設定内容なので、本記事では省略します。
リソース監視の設定
では本題のファイルシステム使用率を監視するためのリソース監視を設定します。
監視設定[一覧]ビューで作成ボタン(+アイコン)を押すと下のようなダイアログが出るので、その中から「リソース監視(数値)」を選択して「次へ」を押します。

リソース監視とは?
リソース監視は、名前の通り監視対象マシンのCPU、メモリ、ファイルシステム使用率などなどを監視することができます。
この監視はSNMPを利用するため、冒頭で行ったNet-SNMPの設定がされていないと利用できません。
下のキャプチャは「test-node」スコープに対して、「全てのファイルシステムを監視する」設定を行った例になります。
赤枠の上にある「監視項目」のプルダウンメニューから、この監視設定で監視したいリソース値を選択します。今回の場合は、ひとまず全部のパーティションを監視することとします。

いくつかテクニックなどの補足説明をしたいと思います
基本、未来予測、変化量タブについて
赤枠の部分ですが、Hinemosのリソース監視を含めた「数値を監視する系」の監視は「基本」、「将来予測」、「変化量」の観点で監視をすることができます。それぞれ下記のような意味があります。
- 基本:HinemosがSNMPリクエストを投げて受け取った瞬間の結果を監視する
- 将来予測:過去の監視結果をもとに、ユーザが指定した未来時間(分単位で指定)がどうなるかを監視
- 変化量:過去の監視結果をもとに変化量の標準偏差を導き出し、それをしきい値として監視
上記説明(特に変化量のところ)は少しわかりづらいと思うので、今回のファイルシステム使用率監視の例に例えると
- 基本:Hinemosが監視対象とSNMP通信をした瞬間のファイルシステム使用率を監視
- 将来予測:過去のファイルシステム使用率の値をもとに30日後のファイルシステム使用率を推測して監視
- 変化量:過去のファイルシステム使用率の増え方(例えば毎時だいたい○MB増えてる)から大きく逸脱したもの(いきなり1時間でXGB増えた or 1バイトも増えてない)がないかを監視
といったことができます。
ファイルシステム監視だとデータの取捨選択や最悪ディスクの交換など対応に時間がかかる(言い換えれば、「いつまでに対応しなきゃいけないのか」を教えて欲しい)内容の監視なので、もしかしたら「将来予測」を利用するのが一番いいかもしれませんね。
重要度の種類と「不明」について
Hinemosの数値系監視の結果の重要度は4種類あり、そのうち必ず3種類のしきい値を設定しなければいけません。
- 情報(緑背景で表示)
- 警告(黄背景で表示)
- 危険(赤背景で表示)
- 不明(青背景で表示)
ユーザが指定しなければいけないのは情報、警告、危険の3種類です。
じゃあ不明は?となりますが、なんらかの原因で監視できなかった場合に不明となります
今回の場合は、下記のような状況になった場合に不明の結果となります。
- SNMP通信に失敗した
- SNMP通信がタイムアウトした
しきい値の設定について
前節で、ユーザは3種類の重要度をしきい値で設定することを説明しました。でも往往にして、「3つも重要度いらないよ。情報と危険だけでいいよ」って思う時があるわけですよ。
実はしきい値の設定を下のようにすることでそれができます。

具体的には、情報と警告を全く同じしきい値設定をします。
そうすることで、上記の場合、ファイルシステム使用率が90%未満の場合は重要度「情報」、90%以上になったら「危険」で通知するように設定ができます。
通知の設定
最後に通知IDの「選択」ボタンを押して、このリソース監視に設定する通知を選択することができます。
今回は、上記で作成した「ステータス通知」と「メール通知」を指定しました。
では、設定も終わったので、しばらく様子を見てみましょう
監視結果の確認
上記で設定したリソース監視は、30秒間隔で監視するよう設定をしたので、適当に1〜2分待っていれば通知が上がっているはずです。
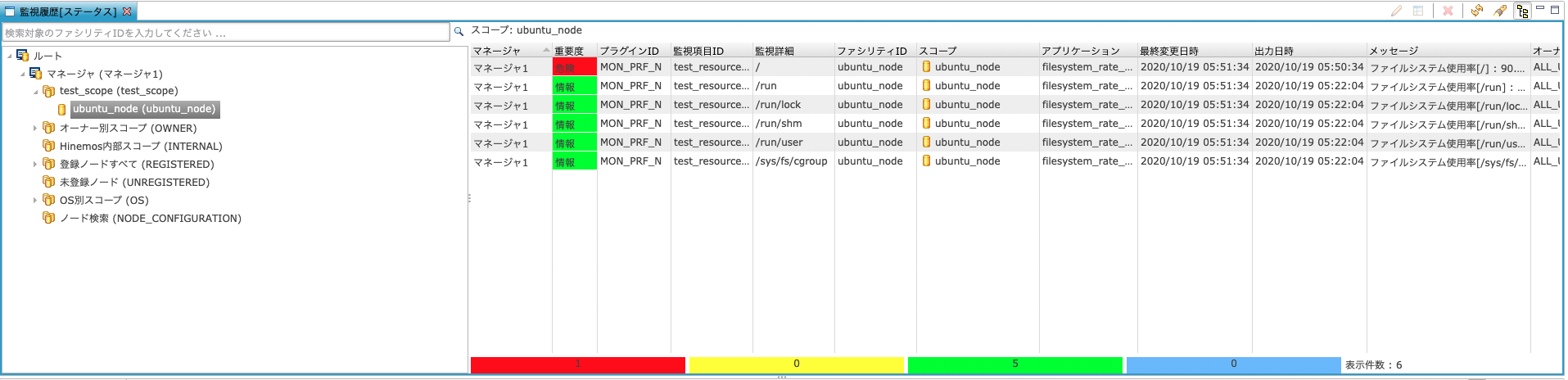
ステータス通知は、「監視履歴」パースペクティブの「監視履歴[ステータス]」ビューで確認できます。
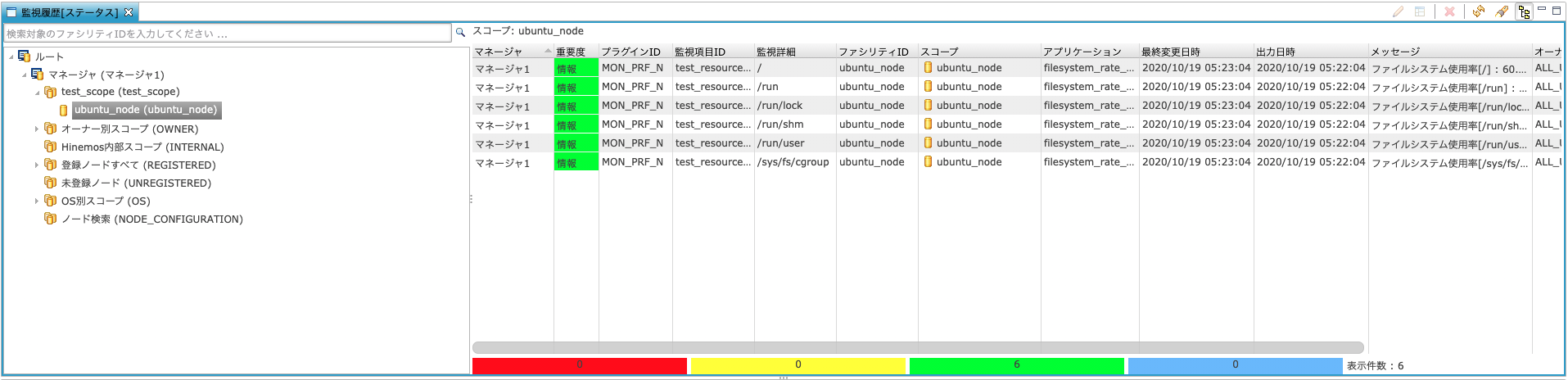
上記のように、パーティション別にファイルシステム使用率の結果が表示されます。
上の場合はすべて緑色(情報)なので、90%未満であることがわかります。
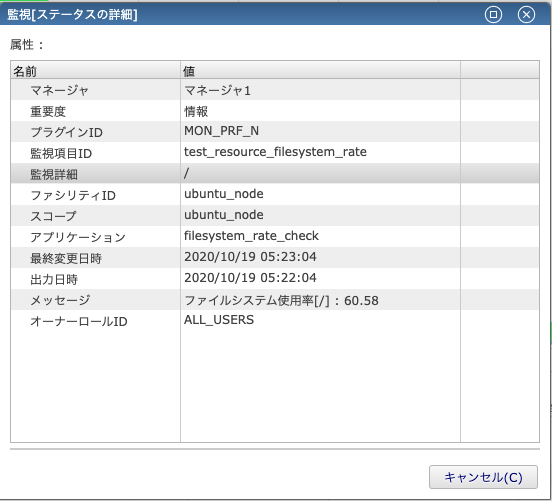
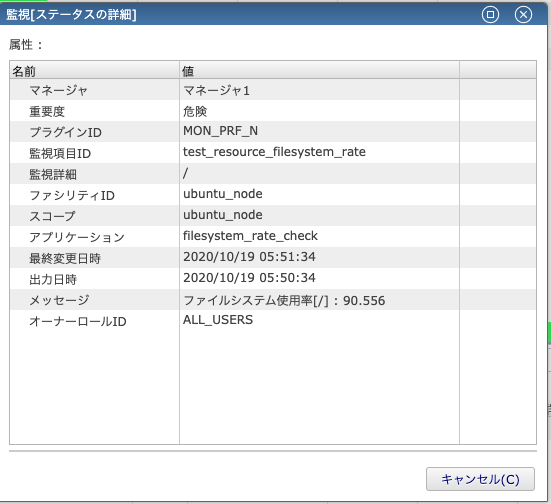
詳しく現在の使用率を知りたい場合は「メッセージ列」または気になる通知の行をダブルクリックすることで詳細ダイアログを開くことができます。
ファイルシステム90%超えた時の監視結果確認
今回は、ルート(/)パーティションのファイルシステム使用率が90%以上になるようなダミーファイルを作成して、ファイルシステム使用率が90%を超えた場合の動作も確認してみましょう。
具体的には、対象のマシンにSSHログインして下記のような操作を行います。
# 現状のファイルシステム使用率を確認
df -h
Filesystem Size Used Avail Use% Mounted on
udev 987M 12K 987M 1% /dev
tmpfs 201M 364K 200M 1% /run
/dev/xvda1 20G 12G 6.9G 64% /
none 4.0K 0 4.0K 0% /sys/fs/cgroup
none 5.0M 0 5.0M 0% /run/lock
none 1001M 0 1001M 0% /run/shm
none 100M 8.0K 100M 1% /run/user
# 上記の場合、ルート(/)パーティションに7GB弱の空き容量があるのがわかるので、6GBのダミーファイルを作成します
# 下記のcount=の部分は環境に合わせて変更してください
dd if=/dev/zero of=6G.dummy bs=1M count=6000
6000+0 records in
6000+0 records out
6291456000 bytes (6.3 GB) copied, 92.3561 s, 68.1 MB/s
上記操作を完了したらしばらく待ってみましょう。
そうすると、監視結果「危険」のステータス通知を確認できました。
また、メール通知に指定したメールアドレスにメールも届いていました。

また、リソース監視は30秒間隔で実施されていますが、メール通知の抑止制限により、60分間は同じ重要度の監視結果は通知されないため、30秒おきにメールが送られてくるということもありません。
・・・といった感じで、ファイルシステム使用率の監視設定がうまくできていることを確認できました。
まとめ
本記事では、前記事(Hinemos ver.6.2 をAWS上にインストールして監視するまで(初期設定編))で行った初期設定を元に、監視対象マシンに対して下記の監視を行うための準備および設定を行いました。
- ファイルシステム使用率を監視する
- 使用率が90%以上になった場合に限り、60分に1回メールで知らせる
- Hinemosクライアント上で監視結果を確認できるようにする
また需要がありそうなら、他のテクニック等についてもまとめてみようと思います。