はじめに
昨今、Deeplearing熱の高まりからたくさんのPythonを使ったDeeplearningフレームワークが登場しています。現場で使うときに求められるのはフレキシビリティや実装のしやすさの他に、処理速度の速さなどが重要であると感じます。そこでQiitaではフレームワーク間の処理速度の比較に関する記事がないのでこの記事を執筆しました。また、これらの結果は環境に依存する話ですので、お手元で試せるようにソースコードを公開しております[Github(開発中)]。
環境
| ハード | AWS g2.2xlarge |
| OS | Ubuntu 16.04 |
| Python | 3.6.3 |
| CUDA | 8.0 |
| cuDNN | 6.0 |
| Chainer | 4.0.0b1 |
| CuPy | 4.0.0b1 |
| Pytorch | 0.4.0a0+5215640 |
| Tensorflow | 1.4.0 |
| mxnet | 0.12.1 |
その他の前提
- (3, 28, 28)のダミーデータを使用。
- CNN(6層CNN+3層FC)
- 反復回数1000
結果
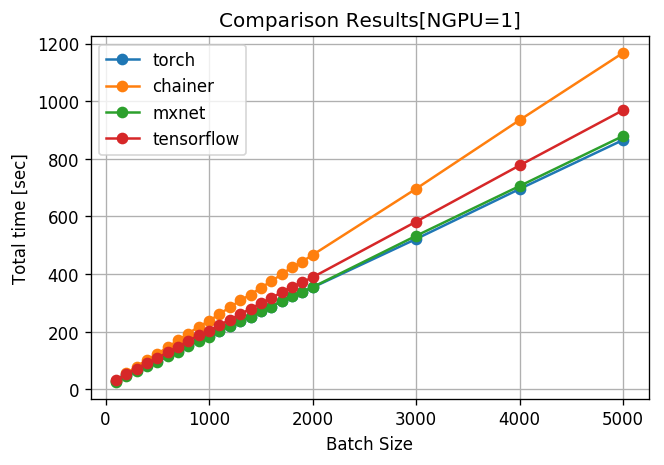
1. 計算を終了するまでの総時間
2. 1サンプルあたりの計算時間(=total_time/batch_size)
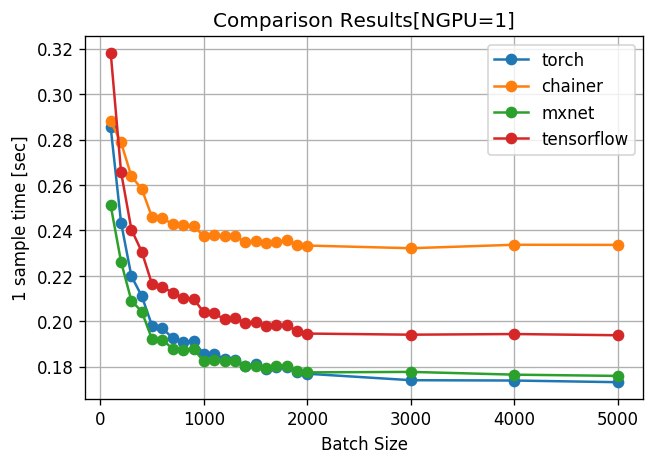
どのフレームワークもバッチサイズ2000あたりで計算時間が頭打ちし始めている。
3. 1バッチの計算時間
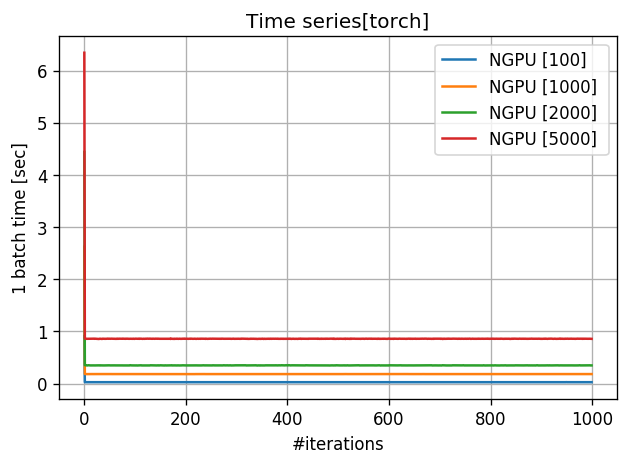
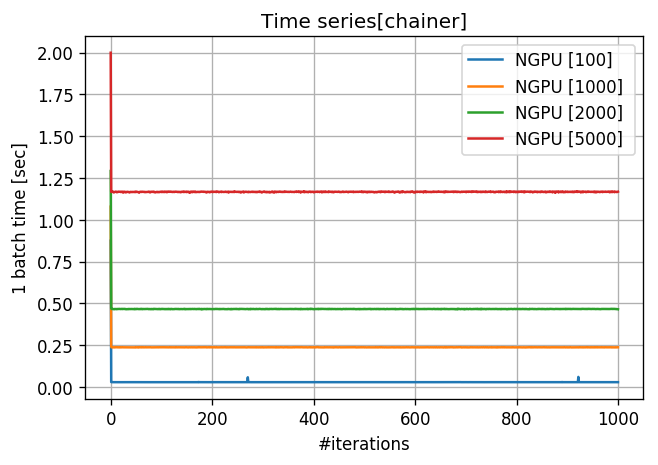
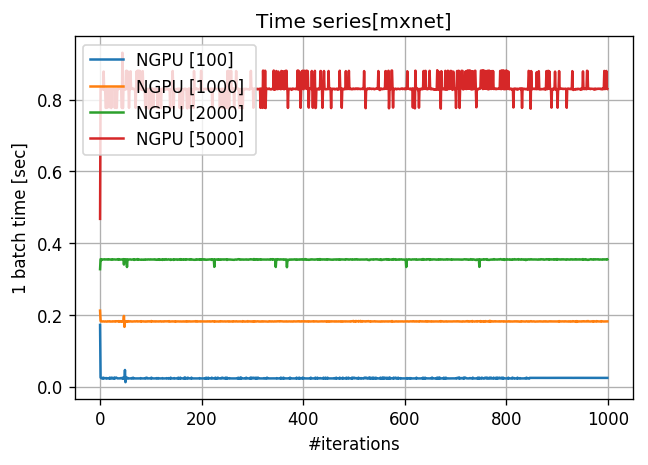
*tensorflowはバグがあり計測できませんでした。
4. 結果について
私の環境では結果として、小さいバッチサイズではmxnetが一番早く、大きなバッチサイズではPytorchが一番早いといった結果になりました。しかし、環境が異なればもちろん結果も異なります。また、マルチGPUを用いたときの結果は大きくことなります。Chainerが遅いように見えますが必ずしもそうとは言えません。
5. 大きいバッチサイズで実験する意味
一般的にバッチサイズを大きくすると精度が落ちると言われております。しかし、最近ではFacebookに始まり多くのチームが大きなバッチサイズで学習を成功させています。よって、これからは分散並列やマルチGPUを用いて大きなバッチサイズでスケールするフレームワークの需要が伸びるのではないでしょうか。
ソースコードについて[Github(開発中)]
1. pytorchのインストール
まず、pytorchをインストールして頂く必要があります。これはGPUを使った計算は非同期的に処理が行われるため、処理時間を適切に計測するためにcudaEventを使って適切に同期を取る必要があるからです。(CuPyやPyCUDAにも同様のメソッドがありますが、2017/11/23現在、PyCUDAはCUDA9.0に対応していません。)
2. 対応しているDeeplearingフレームワーク
| DL | CPU | Single GPU | MultiGPU |
|---|---|---|---|
| pytorch | ? | o | o |
| chainer | ? | o | o |
| mxnet | ? | o | o |
| tensrflow | ? | o | x |
| neon | ? | x | x |
| cntk | ? | x | x |
| caffe2 | ? | ? | ? |
3. 実行方法
$ git clone https://github.com/0h-n0/DL_benchmarks.git
$ cd DL_benchmarks
$ pip install -r requirements.txt
$ python -m benchmark.main ## default framework is pytorch
$
$ # You can change framework.
$ python -m benchmark.main with framework=chainer
$ # And also, change batch size.
$ python -m benchmark.main with framework=chainer batch_size=2000
$ # get info of command line options
$ python -m benchmark.main print_config
$
$ # check results
$ cd results/<your experiment id>
$ cat results.json